方案分享 | 高手云集 共同探索重口音AI语音识别

7月6日及14日,“Magichub重口音对话ASR挑战赛”线上颁奖暨获奖方案分享直播活动圆满结束。两场技术干货的直播分享活动共吸引到AI算法工程师600+,互动次数超5000+。
直播活动中,除了获奖团队代表的方案分享,也邀请Magic Data创始人兼CEO张晴晴、小米科技新一代Kaldi团队也在线带来精彩的主题分享,共同探索AI语音识别领域的技术及趋势。
RAMC开源数据集
MagicData-RAMC开源数据集介绍
首先,Magic Data创始人兼CEO张晴晴 带来《MagicData-RAMC开源数据集介绍》的主题分享。随着人工智能行业的飞速发展,自然对话语音识别的需求量日益增长,近年来对话式语音识别研究面临诸多挑战。本次比赛基于Magic Data开源的180小时MagicData-RAMC数据集,数据均在真实场景环境录制,采集人与人之间的自发式对话,捕捉自然语言现象。同时,交谈内容无脚本预设,话题自然且丰富,共351组多轮对话,每组对话仅围绕一个主题。此外,采集人的性别与地域分布均衡,适用于带口音的语音识别研究。

针对该数据集的论文经过重重审核,已被语音顶级大会INTERSPEECH 2022收录。今年9月Magic Data 也将作为银级赞助商参与活动,加强工业界和学术界协作,支持会议顺利进行。

数据下载 : MagicData-RAMC Conversational Speech Dataset - MagicHub
论文 : https://arxiv.org/abs/2203.16844
基线 : https://github.com/MagicHub-io/MagicData-RAMC-Challenge
Magichub开源社区探索更多 : MagicHub - Datasets Download | Open-Source Datasets
冠军团队:小米科技
基于Conformer端到端模型重口音普通话语音识别
MITC团队由小米AI实验室的陈俊杰进行分享。该团队使用了与目前小米线上语音服务相同的基于Hybrid CTC/attention结构的conformer端到端建模方法。团队针对比赛数据进行了全面分析,并针对数据特点针对性的数据扩充,使用了基于kalid的数据増广方式,并对个性化语音合成的方式进行了尝试。由于这次比赛的数据属于口语对话领域,所以借鉴了在过往产品上使用的算法优化的经验,在短时间内实现了较好的实验结果。另外在最终模型解码中,使用k2提供的TLG和attention rescore的解码方式,为团队最终获得第一名提供了重要保证。

二等奖团队:同花顺&天津大学
RoyalFlush-CCA重口音对话ASR方案介绍
由同花顺和天津大学组成的RoyalFlush-CCA团队由天津大学的宋彤彤进行分享。该团队使用WeNet进行模型搭建,采用Conformer及Bi-Decoder模型结构。数据上进行了速度扰动和噪声扰动。解码上采用Decoder重打分的方法,此外加入Transformer语言模型进行Shallow Fusion来辅助解码。由于涉及到低资源模型自适应,使用低资源数据微调整个模型容易产生过拟合导致模型泛化能力下降,因此我们引入Adapter技术[1]来解决这个问题。首先将整个模型在普通话和带口音数据上进行训练,微调阶段只训练Adapter参数,模型表现提升的同时微调阶段所需训练时间大幅度降低。最终将多个不同的模型采用ROVER技术进行系统融合得到最终结果。

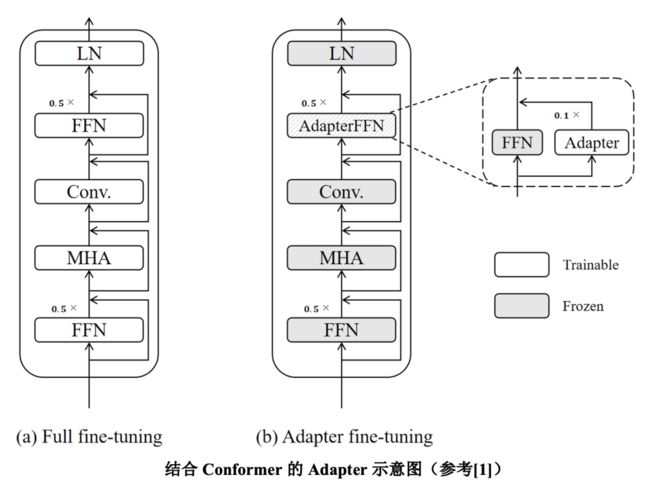
[1] Chen, S., Ge, C., Tong, Z., Wang, J., Song, Y., Wang, J., & Luo, P. (2022). AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition. ArXiv, abs/2205.13535.
三等奖团队:网易有道
基于ESPNet的重口音识别任务技术总结
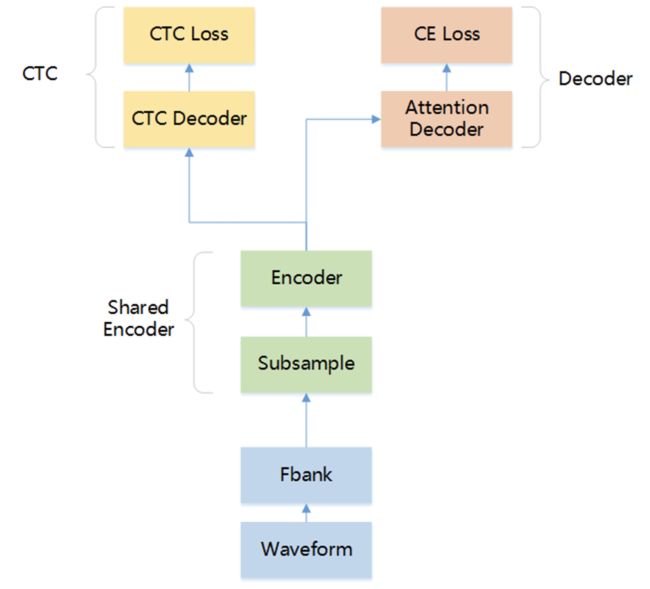
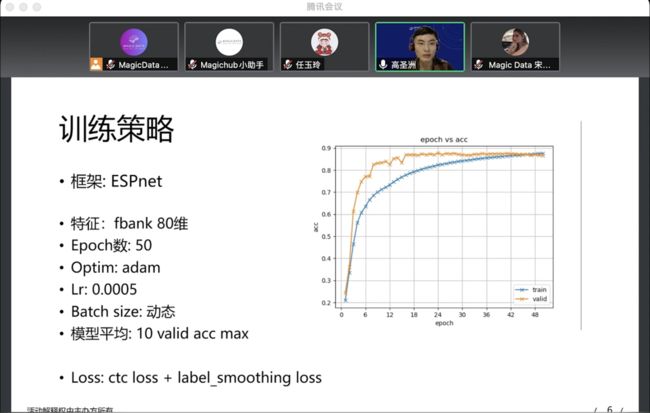
网易有道DAO团队由团队代表高圣洲进行分享。该团队主要基于Hybrid CTC/Attention框架,采用将普通话数据跟重口音数据合并训练的方式完成这次任务。采用CTC Attention Joint Decoding的解码方式,将decoder attention score加入到CTC Prefix Beam Search中。同时结合数据增强,模型平均等方法进一步提升模型的鲁棒性和准确率。
三等奖团队:中移在线
基于wenet端到端技术在重口音识别中的应用
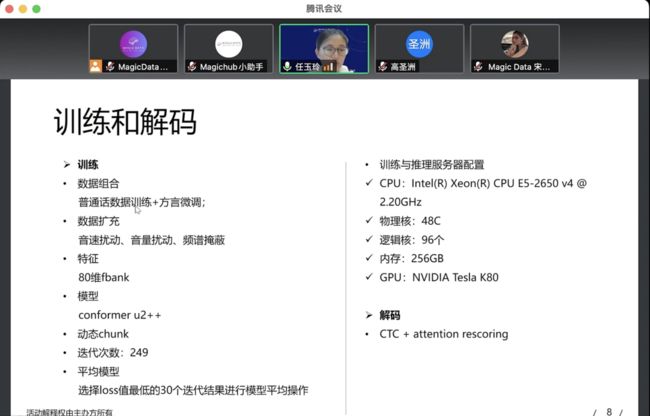
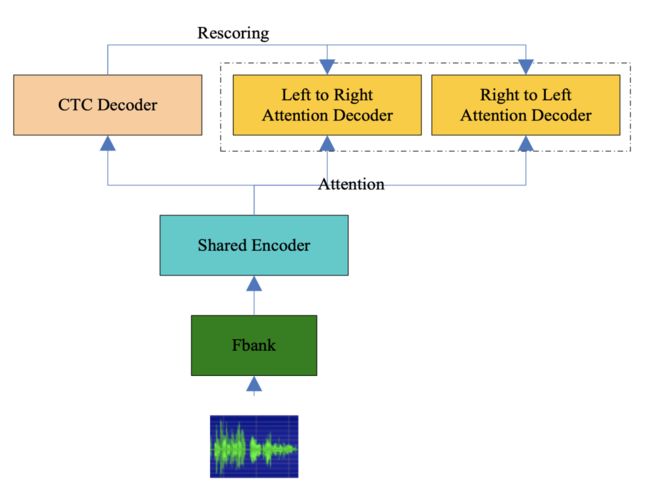
中移在线的AIzyzx团队由团队代表任玉玲进行分享。该团队重口音语音识别方案基于wenet设计,模型主要包括含三个部分,分别为共享的Encoder、CTC解码器、Attention Decoder。其中,Attention Decoder采用U2++结构。为了丰富训练数据语音特征和语音识别抗噪能力,数据预处理加入音速、音量扰动和频谱掩蔽。字典根据常见汉字及英文单词整理5967行,分词时未登录词标记
k2分享:小米AI实验室
k2的核心算法及其应用分享
直播活动中,我们还邀请到小米AI实验室的康魏进行《k2中核心算法——可微分有限状态自动机的原理及应用》主题分享,并对团队在RNN-T模型上的研究进展进行介绍。
第一部分,康魏详细介绍了k2中FSA的特点及其作用,并且通过一个简单的CTC建模的例子阐明了使用可微分有限状态自动机进行序列建模的原理,最后讲解了使用k2框架进行高效解码的方法。第二部分,主要围绕团队在RNN-T训练和解码上做的优化和改进,例如团队提出的Pruned RNN-T损失函数,使RNN-T模型的训练速度得到了极大的提升,同时,团队自研的基于GPU的RNN-T并行解码方法也让RNN-T类模型的部署更加高效。最后,康魏分享了团队在RNN-T模型上做的一系列探索演进,实验结果表明,RNN-T模型在各大开源数据集上都取得了业内最好效果。
