插件扩充,血缘耦合系统,生产环境优化,提高Apache DolphinScheduler易用性的应用改造...

Apache DolphineScheduler作为新一代的大数据任务调度系统,是为了让调度变得更加容易。为了更好的满足用户使用平台,Apache DolphineScheduler Contributor 张柏强 针对一些现有的易用性及优化问题,比如任务扩展、任务血缘耦合、任务日志优化等,提供了一些解决方案,并在 Apache DolphineScheduler 4月线上Meetup上,以题为《Apache DolphinScheduler的应用实践》的演讲,详细讲解了其针对Apache DolphinScheduler的一些应用实践和优化。
分享主要内容如下:
基于Apache DolphinScheduler的二次改造
Apache DolphinScheduler的插件扩充分享
Apache DolphinScheduler耦合血缘系统
Apache DolphinScheduler的生产基本优化
张柏强 大数据基础平台开发
从事大数据基础平台开发以及底层组件运维
01
基于Apache DolphinScheduler的二次改造
1
元数据和任务多环境执行改造
不论3.x版本还是之前2.x版本,目前Apache DolphinScheduler在元数据和任务多环境执行是存在短板的,而且目前社区并没有做这些功能点,短板内容为:
1. 任务上线无法编辑
2. 任务无法动态切换Pro/Test环境
3. 同一个ProcessWorkflow无法设置多个调度
1.1
元数据分离改造
针对元数据和任务多环境执行的问题,我们对Apache DolphinScheduler进行了一个基本的改造。
首先是任务上线后无法编辑会导致用户使用体验不够友好,其根本也是因为如果随便更改的话可能会影响到线上的调度。通常任务彻底开发完成之后,才能修改任务,如果任务没有开发完成,那任务就无法上线,因为可能就会影响到下游的依赖。所以我们对Apache DolphinScheduler的元数据进行了改造,把用户编辑的任务和调度的任务拆分为不同的两部分,当用户点击任务发布,则触发调度依赖的任务信息表修改,而用户本地执行和修改都不会去触发调度依赖的任务信息表。

如上图,当用户点击执行任务以及修改任务时,操作都是针对于 Dev的元数据。当用户点击发布任务,通过Dev发布到Apache DolphinScheduler,即调度的元数据,那执行的就是调度的元数据。这可以帮助我们解决任务上线后无法编辑的问题。在不发布任务的情况下,我们的任务不会影响到线上的任务。这相当于进行了任务的多态化改造,即测试化和生产化。
1.2
多环境执行改造
针对第二个问题的改造:任务动态切换环境。基于最新版本的Apache DolphinScheduler 2.x.x版本支持多环境的基础,我们给出了一个部署配置 scheduler.executor.environment.name。该参数的作用是当任务通多调度执行时应该使用哪个环境。例如调度a时使用测试环境,调度b时使用生产环境,通过参数配置自动化做任务执行的改造。
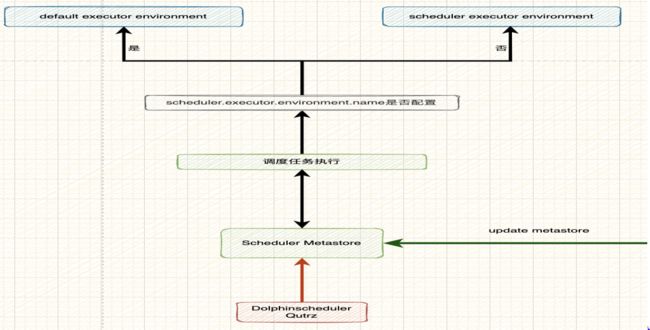
2
任务信息清单增加
为了增强UI页面的可用性,我们特意增加了任务清单功能,以减少用户的操作量,支持一页多信息。在原生Apache DolphinScheduler中,我们每次查找任务执行记录需要再次点击or多次点击,同时一些任务的明细信息也不是很全面,包括任务最近执行状态等。同时,我们也改造了任务上下线的模块,单独进行任务展示,页面内容包括与版本挂钩的任务版本、任务历程、最近10次的执行实例、任务名称以及编辑任务流、任务版本管理、定时管理和任务下载等。最新UI页面如下图所示:
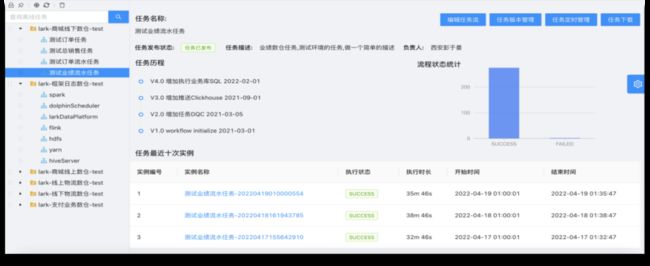
3
项目文件夹功能扩充和工作流UI改造
在原生Apache DolphinScheduler中,当创建了一个调度之后是无法创建第二个调度的。目前,我们将UI进行了改造,支持调度任务支持多个调度设置。
详细来说,Apache DolphinScheduler提供了以project为基础的最大单位,每个project里会包含数百上千的workflow单位,workflow下是task。虽然其本身包含了分页的功能,但是从使用场景来说,如果一个project中包含的workflow过多,会导致用户不知道任务下有哪些task,无法根据当前项目的业务线去划分任务。为了用户更方便地操作,我们提供一个业务线文件夹的单位,单位划分为 project -> workflow dir -> dir,同时针对Workflow定义UI的界面样式进行了改造,如下图所示:

02
Apache DolphinScheduler的插件扩充构建
我们目前做了很多种类型的task,但常用的有三种,分别是Spark/Hive ClientSQL Task、DQC Task和SSH Task。
1
Spark/Hive ClientSQL Task
Apache DolphinScheduler提供的开箱即用的task中只提供了通过jdbc的方式执行sql任务的形式,但对于某些数仓场景,这些任务类型明显是不满足需求的,于是我们提供了基于模板配置的hive/spark sql task。可能有人选择通过shell执行任务,但这可能对其他系统造成影响,因此我们做成了模板化。该模板支持多SQL,包含高级参数,也就是把Spark所有的参数以及Hive所有的参数做了一个列表供用户搜索和配置,其他功能则和原生功能保持一致。这些改造最重要的作用是能够让用户快速开发离线任务,同时将当前的task绑定血缘系统,在任务执行时能够包含完整的可追溯血缘。

2
DQC Task
DQC Task在当前已经release的2.x版本中还没有得到支持,我们基于已有的一套规则完善了第一版本的DQC task,提供了空值检查、最大值检查、最小值检查、重复数据检查以及数据量检查,支持多集群、多表对比和用户自定义功能。以上功能实现相对较容易,相当于把规则包装成Spark SQL,通过Spark SQL或者其他方式执行。
在优化方面,针对统计数据量,我们专门编写程序实现了直接读取ORC文件中的数据量以提升资源的使用率。目前,我们已经完成集成的功能包括任务检测、DQC告警和自定义规则,但DQC还未包涵盖所有大数据场景。
3
SSH Task
SSH task实际上就是提供了一个任务模板,在某些场景下,如果Apache DolphinScheduler的worker不在机器上,我们需要自己定时执行任务,比如每天定时清理日志,定时operate某些bash,为了统一管理,我们提供了一个冗余的task,用于快速开发。
03
Apache DolphinScheduler耦合血缘系统
耦合血缘一直是社区呼声比较高的需求之一,借着这次机会,我来讲一下我们针对这一部分功能所做的改进,供大家参考。
1
任务表血缘绑定
首先是任务表的血缘绑定。任务血缘构建的流程是,当Apache DolphinScheduler执行任务时,我们会根据type获取到如下几种类型,并将这几种类型的task content、task name、workflow name写入lineage server,再通过lineage server构建成血缘,之后写入 graph db或者Hbase中,最后通过API将数据查询出来进行展示。

任务类型包括SeaTunnel、Spark、MySQL、Hive和Sqoop。那我们如何获取数据抽取的血缘呢?
首先是数据抽取也就是血缘的源头,我们通过SeaTunnel和Sqoop本身包含的配置文件进行血缘节点构建,把配置文件发送到lineageServer。lineageServer相当于一个client,作用是把接收到的配置文件和一些变量数据进行解析后发送到MQ中。
其次,数仓Spark的实现包括Spark的listener以及SparkSql的SparkSessionExtensions
再者,MySQL是自定义的解析规则,采用的是antlr4工具,大家也可以根据自己的需要使用Druid or其他解析工具。
最后,数仓Hive类型使用的是hive的hook,hook有SQL执行前触发,SQL执行后触发,会将执行的信息发送给下游。
血缘的具体实现是将所有的用户定义进行一个解析,其具体的实现是包含数据抽取以及目标数据,LineageSource是解析Seatunnel和Sqoop的配置文件,把配置发送到下游的血缘服务中,血缘服务会把它解析成一个大的json str,将其发送到MQ,而且我们解析时会将其绑定WorkflowName以及TaskName,格式是workflow.task.database.table。在这个过程中,如何拿到workflow和task的名称?在Apache DolphinScheduler执行中,最终会将用户的任务封装成shell去执行。再把workflow name和task name导入到进程级别的环境变量中,或者使用 process API设置环境变量,下游会触发hook,当触发hook时,在同一个进程下,环境变量还是存在的,所以在hook、spark listener或者血缘服务触发时,会读取环境变量,拿到workflow名称和task名称,拼接成一个血缘里的大json。封装成一个大json之后,json里就包含了一整套的血缘信息,再把血缘的json数据发送到mq,由lineage的下游读取写入到图库、Hbase或MySQL,最后通过API server展示。
若想深入的做血缘服务,需要了解常见的SQL解析工具,主要有:
antlr4,可以编写规则,生成规则类文件,之后直接使用解析。当前Apache Spark就采用了这个工具。
Calcite,当前采用此工具的有Apache Flink。
Druid,已完整封装了一套API,可以解析Hive、MySQL。
解析包,Hive-exec.jar和Spark-sql.jar。原生的解析包会提供解析的公共API来直接调用,也可以解析SQL再封装血缘。
2
血缘存储设计建议
Hbase存储
我们使用Hbase存储将血缘存储在Atlas中。Neo4j原生是支持血缘关系的,那我们为什么要用Hbase做血缘存储?个人认为相较于使用Neo4j数据库,我们不需要再进行额外的学习。
复杂的是血缘的设计,首先我们先展开血缘表结构为例,最简单的设计为
tableName lineage_table (split[])
rowkey
column family s t第一行:给Hbase定义表名 lineage_table
第二行:设计rowkey,rowkey就是当前你要搜索的表名,Hive的hook的机制会在任务SQL执行完之后,把信息发送到下游,此时会有一个DDL监控,当用户触发DDL时,比如用户新建表,那就会推送或在Hbase中插入一条数据,数据包括创建时间和表名,这就是它的rowkey。
第三行:列簇。列簇设计有2个,包括source和target。比如表a对应的是上游和下游的任务表血缘,上游相当于source,下游相当于target,就是两个列簇,把解析下来的血缘写入到source和target。在应用层查询时,可以直接根据rowkey把source和target全部查出来进行展示。这只是一个简单的构思,虽然我们有应用过,但最终因各种原因没有使用。若对Hbase比较了解或应用较多的小伙伴,建议可以深入研究。当数据写入之后,我们每次只展开最近的血缘关系,并根据最近的血缘关系依次展开,同时更新task时需要发送一个事件来删除旧的血缘等操作。
Neo4j
如果会用Neo4j,存储血缘信息比用Hbase更简单,其天然支持血缘关系,无需自己设计。
04
Apache DolphinScheduler的生产基本优化
1
任务日志存储优化
对于服务于用户和开发者的调度系统来说,任务排错是必不可少的。一般情况下,任务排错从 demo、debug和log入手,所以对于使用者来说,针对task
执行日志进行排错是必不可少的一步,这也从侧面证明了log对于调度系统的重要性。但是随之任务增加和时间递增,日志会越来越多。然而,企业中的服务器往往是存储磁盘和应用磁盘分开的,所以我们需要做的第一步,就是更改Apache DolphinScheduler的execution log存储位置。

如上图所示,应用部署的目录挂载在1T的磁盘上,执行日志写入的目录挂载的是5T的磁盘,用来做可拔插的数据磁盘。这就是做了一个划分。
写入时需要修改conf下面的logback-worker,修改log base和file标签中的内容,并写入到相应的位置就可以,不需要做其他操作,就可以做到日志、执行日志和应用划分开,减少服务器的压力,同时有利于进行日志监控和日志清洗。
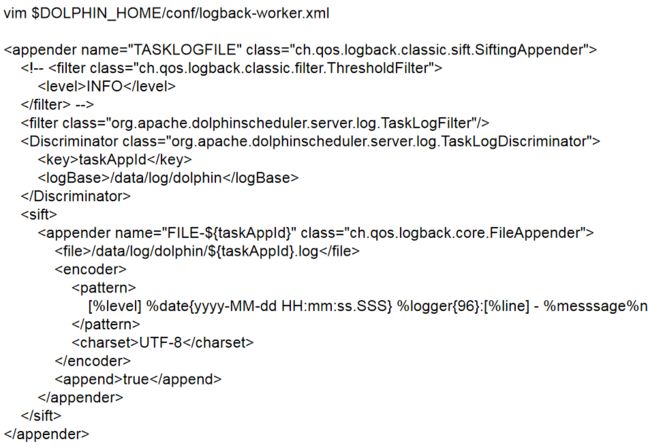
2
经验分享
在改造Apache DolphinScheduler的过程中,我们也积累了一些经验分享给大家。
1. 实例数据如何管理?
随着系统上线持续运行,实例的数据会随着时间逐渐递曾,但大量实例数据不适合删除,保留又会造成读写速度过慢。对此,常见的解决方法有分库分表,以及将数据写入HDFS,交由HIVE管理,只将历史统计数据写入MySQL。第二种方式是改造Apache DolphinScheduler的查询,需要增加一些聚合,如Hive聚合的结果、历史数据的聚合。
2. Shell 结果获取失败原因?
shell的执行机制是,这行代码报错后,如果下一行还有代码依然会执行,如果下一行代码执行正常则返回0,我们可以设置 set -e。
3. 如何扩充新的管理员用户?
修改原生Apache DolphinScheduler的t_Apache DolphinScheduler_user表中的user_type为0。
4. 在原生Apache DolphinScheduler中如何使用双环境执行?
为了保证Apache DolphinScheduler能够在两套集群中运行,最简单的方法就是部署worker到测试环境中,这种情况下,我们在任务执行时可动态选择执行的worker;如果不想部署过多worker,可以set两套不同的execution env,之后将测试环境的包部署到worker的某个位置,不启动服务,甚至可以将服务的jar剔除,只依赖client及其配置文件。如果需要保证数据一致性,就需要借助于一些外部工具,如DQC工具和自定义开发的工具。
以上就是我的分享,谢谢!
05
Q&A
1. Hbase血缘能够分析Hive构建数据仓库的血缘图吗?
答:可以的。血缘关系是通过工具把血缘解析成血缘的json。比如数仓,工具用的是Hive,Hive本身支持血缘服务,可以直接用来解析成一套血缘的json,发送给kafka让下游去解析。Hbase并不负责血缘解析,只是负责血缘存储。
2. 基于两套容器环境中部署worker,其中一套环境部署master,如何保证master和另一套环境的互通呢?
答:网络互通即可。部署时要沟通好网络互通情况,比如防火墙等。
3. Worker的部署方式是怎样的?是部署在Spark的集群中,还是Spark的jar方式呢?
答:不一定非要部署到执行环境中。可以单独部署一套调度集群专门做调度,Spark客户端部署到调度集群中,保证客户端能通信到yarn等服务即可。Worker也可以部署到执行环境中,因为Spark执行时会读取配置文件,把任务发送到调度集群执行,只要保证网络通信正常。
4. 血缘有具体应用场景吗?
答:在表达到一定的规模,比如上万张表或者更多时,血缘能方便查找,其次,数据的链路追踪可以了解到表的价值体现在哪里。
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。
![]()
参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:
![]()
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/docs/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
活动推荐
当数据资源成为生产发展乃至于生存过程中必不可少的要素,企业该如何通过数据集成帮助企业数据服务全生命周期落地呢?5月14日,数据集成框架 Apache SeaTunnel(Incubating)将邀请一站式数据集成平台 Apache InLong(Incubating)的技术专家与开源贡献者们,一同来到直播间,与大家畅谈使用Apache SeaTunnel(Incubating)与Apache InLong(Incubating)后的实践经历与心得体会。
本次活动受疫情影响仍以线上直播的形式开展,活动现已开放免费报名,欢迎扫描下图二维码,或点击“阅读原文”免费报名!

扫码观看直播

扫码入直播群
更多精彩推荐
☞中国联通改造 Apache DolphinScheduler 资源中心,实现计费环境跨集群调用与数据脚本一站式访问
☞达人专栏 | 还不会用 Apache Dolphinscheduler?大佬用时一个月写出的最全入门教程
☞全面拥抱 K8s,ApacheDolphinScheduler 应用与支持 K8s 任务的探索
☞杭州思科对 Apache DolphinScheduler Alert 模块的改造
☞日均处理 10000+ 工作流实例,Apache DolphinScheduler 在 360 数科的实践
点击阅读原文,免费报名!