《云南虫谷》爆火播放中,Python抓取3.6万条评论!评论太搞笑了吧!
最近鬼吹灯系列网剧《云南虫谷》上线,作为鬼吹灯系列作品,承接上部《龙岭迷窟》内容,且还是铁三角原班人马主演,网友直呼非常好看! 今天,我们就用Python爬取目前全部剧集的评论(含预告片),并做数据统计与可视化展示分析,一起跟着网友看看这部剧吧!
本文将详细讲解爬虫与数据处理可视化,寓教于乐!
需要完整代码的童鞋“点这里获取”
1. 网页分析
本次评论全部来自腾讯视频(毕竟独播)
打开《云南虫谷》播放页面,F12进入到开发者模式,我们下滑点击"查看更多评论",可以发现评论的真实请求地址。

我们找几个评论接口地址进行对比分析,找规律
https://video.coral.qq.com/varticle/7313247714/comment/v2?callback=_varticle7313247714commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6838089132036599025&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1630752996851 https://video.coral.qq.com/varticle/7313247714/comment/v2?callback=_varticle7313247714commentv2&orinum=100&oriorder=o&pageflag=1&cursor=6838127093335586287&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1630752996850 https://video.coral.qq.com/varticle/7313258351/comment/v2?callback=_varticle7313258351commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6838101562707822837&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1630753165406
最后,我们发现这个地址可以简化成以下部分、
url = f'https://video.coral.qq.com/varticle/{comment_id}/comment/v2?'
params = {
'orinum': 30,
'cursor': cursor,
'oriorder': 't'
}
这其中四个参数含义如下:
orinum是每次请求的评论数量,默认是10个,我通过尝试发现最多支持30个,所以这里我设置值为 30cursor是每次请求初始的评论id,变化规律上可以初始值设为0,下一次请求用上一次请求得到的评论列表中最后一个评论的id即可
oriorder是请求的评论排序(t是指按照时间顺序,默认是另外一个最热)- 除了上面三个参数外,其实还有一个
comment_id,每集都有一个id用于采集对应评论的,所以我们还需要研究这个id在哪获取
刚才提到我们需要获取每集的评论id数据,很巧我们发现请求每集的页面数据就可以获取。
这里需要注意的是,我们直接用requests请求每集页面的数据和实际网页端的不太一样,但是相关数据都有,我们可以找找发现。
比如,剧集的ID列表如下:

剧集的评论id所在位置:

接着,我们就用re正则表达式进行数据解析即可获取。
2. 爬虫过程
通过网页分析和我们的采集需求,整个过程可以分为以下几部分:
- 爬取剧集页面数据
- 解析得到剧集ID和剧集评论ID
- 采集全部剧集评论
- 保存数据到本地
2.1. 引入需要的库
import requests import re import pandas as pd import os
2.2. 爬取剧集页面数据 # 用于爬取剧集页面数据
# 用于爬取剧集页面数据
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36",
}
r = requests.get(url, headers=headers)
# 乱码修正
r.encoding = r.apparent_encoding
text = r.text
# 去掉非字符数据
html = re.sub('\s', '', text)
return html
2.3. 解析剧集ID和剧集评论ID
# 传入电视剧等的id,用于爬取剧集id和评论id
def get_comment_ids(video_id):
# 剧目地址
url = f'https://v.qq.com/x/cover/{video_id}.html'
html = get_html(url)
data_list = eval(re.findall(r'"vip_ids":(\[.*?\])', html)[0])
data_df = pd.DataFrame(data_list)
comment_ids = []
for tid in data_df.V:
# 每集地址
url = f'https://v.qq.com/x/cover/{video_id}/{tid}.html'
html = get_html(url)
comment_id = eval(re.findall(r'"comment_id":"(\d+)"', html)[0])
comment_ids.append(comment_id)
data_df['comment_id'] = comment_ids
data_df['剧集'] = range(1,len(comment_ids)+1)
return data_df

2.4. 采集全部剧集评论
# 获取全部剧集评论
def get_comment_content(data_df):
for i, comment_id in enumerate(data_df.comment_id):
i = i+1
# 初始 cursor
cursor = 0
num = 0
while True:
url = f'https://video.coral.qq.com/varticle/{comment_id}/comment/v2?'
params = {
'orinum': 30,
'cursor': cursor,
'oriorder': 't'
}
r = requests.get(url, params=params)
data = r.json()
data = data['data']
if len(data['oriCommList'])==0:
break
# 评论数据
data_content = pd.DataFrame(data['oriCommList'])
data_content = data_content[['id', 'targetid', 'parent', 'time', 'userid', 'content', 'up']]
# 评论员信息
userinfo = pd.DataFrame(data['userList']).T
userinfo = userinfo[['userid', 'nick', 'head', 'gender', 'hwlevel']].reset_index(drop=True)
# 合并评论信息与评论员信息
data_content = data_content.merge(userinfo, how='left')
data_content.time = pd.to_datetime(data_content.time, unit='s') + pd.Timedelta(days=8/24)
data_content['剧集'] = i
data_content.id = data_content.id.astype('string')
save_csv(data_content)
# 下一个 cursor
cursor = data['last']
num =num + 1
pages = data['oritotal']//30 + 1
print(f'第{i}集的第{num}/{pages}页评论已经采集!')

2.5. 保存数据到本地
# 将评论数据保存本地
def save_csv(df):
file_name = '评论数据.csv'
if os.path.exists(file_name):
df.to_csv(file_name, mode='a', header=False,
index=None, encoding='utf_8_sig')
else:
df.to_csv(file_name, index=None, encoding='utf_8_sig')
print('数据保存完成!')
3. 数据统计与可视化展示
本次的数据统计与可视化展示方法可以参考此前推文《》和《》等
3.1. 数据预览
抽样5条看看
df.sample(5)

看看数据信息
df.info()
RangeIndex: 35758 entries, 0 to 35757 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 id 35758 non-null int64 1 targetid 35758 non-null int64 2 parent 35758 non-null int64 3 time 35758 non-null object 4 userid 35758 non-null int64 5 content 35735 non-null object 6 up 35758 non-null int64 7 nick 35758 non-null object 8 head 35758 non-null object 9 gender 35758 non-null int64 10 hwlevel 35758 non-null int64 11 剧集 35758 non-null int64 dtypes: int64(8), object(4) memory usage: 3.3+ MB
才哥也进行了评论,我们看看是不是采集到了

才哥的userid为1296690233,我们查询一下,发现才哥VIP等级居然6级啦
df.query('userid==1296690233')

head字段是头像,我们看看是不是才哥头像

对上了,对上了!! 3.2. 分集评论数 绘图参考《》,所以我们这里是Pandas绘制带交互的可视化图,引入环境:
import pandas as pd
import pandas_bokeh
pandas_bokeh.output_notebook()
pd.set_option('plotting.backend', 'pandas_bokeh')
接下来,正式的数据统计与可视化展示开始
from bokeh.transform import linear_cmap
from bokeh.palettes import Spectral
from bokeh.io import curdoc
# curdoc().theme = 'caliber'
episode_comment_num = df.groupby('剧集')['id'].nunique().to_frame('评论数')
y = episode_comment_num['评论数']
mapper = linear_cmap(field_name='评论数', palette=Spectral[11] ,low=min(y) ,high=max(y))
episode_bar = episode_comment_num.plot_bokeh.bar(
ylabel="评论数量",
title="分集评论数",
color=mapper,
alpha=0.8,
legend=False
)

我们可以看到,第一集评论数最高,高达1.7万,占了全部评论的一半;其次是第7集的评论数,主要是本周播到了第7集哈!
3.3. 分日期评论数
df['日期'] = pd.to_datetime(df.time).dt.date
date_comment_num = df.groupby('日期')['id'].nunique().to_frame('评论数')
date_comment_num.index = date_comment_num.index.astype('string')
y = date_comment_num['评论数']
mapper = linear_cmap(field_name='评论数', palette=Spectral[11] ,low=min(y) ,high=max(y))
date_bar = date_comment_num.plot_bokeh.bar(
ylabel="评论数量",
title="分日期评论数",
color=mapper,
alpha=0.8,
legend=False
)

3.4. 分时评论数
df['时间'] = pd.to_datetime(df.time).dt.hour
date_comment_num = pd.pivot_table(df,
values='id',
index=['时间'],
columns=['日期'],
aggfunc='count'
)
time_line = date_comment_num.plot_bokeh(kind="line",
legend="top_left",
title="分时评论数"
)

![]()
通过分时评论数曲线,我们发现在首播当日8点的小时评论数冲击到最高,此后比较符合电视剧观看行为:中午、晚上及午夜较高。
3.5. 评论员VIP等级分布
vip_comment_num = df.groupby('hwlevel').agg(用户数=('userid','nunique'),
评论数=('id','nunique')
)
vip_comment_num['人均评论数'] = round(vip_comment_num['评论数']/vip_comment_num['用户数'],2)
usernum_pie = vip_comment_num.plot_bokeh.pie(
y="用户数",
colormap=Spectral[9],
title="评论员VIP等级分布",
)

不得不说,评论的人大部分都是VIP用户,难怪腾讯视频要搞什么超前点播弄所谓VIP上的VIP。。。
不同VIP用户人均评论数会有不同吗?
y = vip_comment_num['人均评论数']
mapper = linear_cmap(field_name='人均评论数', palette=Spectral[11] ,low=min(y) ,high=max(y))
vipmean_bar = vip_comment_num.plot_bokeh.bar(
y = '人均评论数',
ylabel="人均评论数",
title="不同VIP用户人均评论数",
color=mapper,
alpha=0.8,
legend=False
)

基本呈现一个VIP等级越高 评价意愿越高!但是为什么呢?
3.6. 评论长度
写评论的网友大部分都是666,好看之类的词汇,比如才哥就是等更新三个字,那么一般都会评价多少个字符呢?
import numpy as np
df['评论长度'] = df['content'].str.len()
df['评论长度'] = df['评论长度'].fillna(0).astype('int')
contentlen_hist = df.plot_bokeh.hist(
y='评论长度',
ylabel="评论数",
bins=np.linspace(0, 100, 26),
vertical_xlabel=True,
hovertool=False,
title="评论点赞数直方图",
color='red',
line_color="white",
legend=False,
# normed=100,
)

我们找几个评论内容老长的看看
(df.sort_values(by='评论长度',ascending=False) [['剧集','content','评论长度','nick','hwlevel']].head(3) .style.hide_index() )

我想说,这评论是在那抄袭的,还是真有才啊?
3.7. 评论点赞数
咱们就看看被点赞最多的几条吧
# pd.set_option('display.max_colwidth',1000)
(df.sort_values(by='up',ascending=False)
[['剧集','content','up','nick','hwlevel']].head()
.style.hide_index()
)

看地图 别迷路!是有什么梗吗?超8000的点赞~~ 3.8. 评论最多的用户
user_comment_num = df.groupby('userid').agg(评论数=('id','nunique'),
vip等级=('hwlevel','max')
).reset_index()
user_comment_num.sort_values(by='评论数',ascending=False).head()
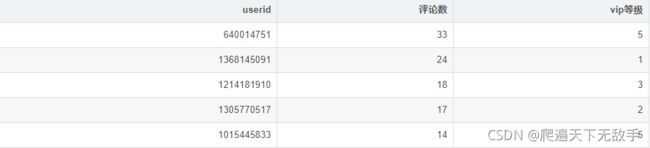
![]() 评价
评价33条,这用户也是很牛!!我们看看他都评啥了:
df.query('userid==640014751')[['nick','剧集','time','content']].sort_values(by='time')

有点无聊,是来刷好评的吧!!我们还是看看评价第二多的小伙伴吧!
df.query('userid==1368145091')[['nick','剧集','time','content']].sort_values(by='time')

不得不说,看着正常一些。。不过,感觉有点话唠,哈哈! 这两位都是啥头像,感兴趣的看看:
from skimage import io
# 显示头像
img_url = df.query('userid==640014751')['head'].iloc[0]
image = io.imread(img_url)
io.imshow(image)

from skimage import io
# 显示头像
img_url = df.query('userid==1368145091')['head'].iloc[0]
image = io.imread(img_url)
io.imshow(image)

咳咳,我就不做评价了,毕竟我的头像和昵称也都很…
3.9. 评论词云
这部分参考《》,我们将从整体词云和主角词云几部分展开
先看看咱们三个主角提及次数
df.fillna('',inplace=True)
hu = ['老胡','胡八一','潘粤明','胡','潘']
yang = ['张雨绮','Shirley','杨']
wang = ['姜超','胖子']
df_hu = df[df['content'].str.contains('|'.join(hu))]
df_yang = df[df['content'].str.contains('|'.join(yang))]
df_wang = df[df['content'].str.contains('|'.join(wang))]
df_star = pd.DataFrame({'角色':['胡八一','Shirley杨','王胖子'],
'权重':[len(df_hu),len(df_yang),len(df_wang)]
})
y = df_star['权重']
mapper = linear_cmap(field_name='权重', palette=Spectral[11] ,low=min(y) ,high=max(y))
df_star_bar = df_star.plot_bokeh.bar(
x = '角色',
y = '权重',
ylabel="提及权重",
title="主要角色提及权重",
color=mapper,
alpha=0.8,
legend=False
)

王胖子是笑点担当,不得不说出镜次数真高!!!
整体词云

胡八一词云

Shirley杨词云

王胖子词云

词云核心代码
import os
import stylecloud
from PIL import Image
import jieba
import jieba.analyse
import pandas as pd
from wordcloud import STOPWORDS
def ciYun(data,addWords,stopWords):
print('正在作图...')
comment_data = data
for addWord in addWords:
jieba.add_word(addWord)
comment_after_split = jieba.cut(str(comment_data), cut_all=False)
words = ' '.join(comment_after_split)
# 词云停用词
stopwords = STOPWORDS.copy()
for stopWord in stopWords:
stopwords.add(stopWord)
# 就下面代码,即可获取满足类型要求的参数
stylecloud.gen_stylecloud(
text=words,
size = 800,
palette='tableau.BlueRed_6', # 设置配色方案
icon_name='fas fa-mountain',# paper-plane mountain thumbs-up male fa-cloud
custom_stopwords = stopwords,
font_path='FZZJ-YGYTKJW.TTF'
# bg = bg,
# font_path=font_path, # 词云图 字体(中文需要设定为本机有的中文字体)
)
print('词云已生成~')
pic_path = os.getcwd()
print(f'词云图文件已保存在 {pic_path}')
data = df.content.to_list()
addWords = ['潘老师','云南虫谷','还原度',
'老胡','胡八一','潘粤明',
'张雨绮','Shirley','Shirley杨','杨参谋',
'王胖子','胖子']
# 添加停用词
stoptxt = pd.read_table(r'stop.txt',encoding='utf-8',header=None)
stoptxt.drop_duplicates(inplace=True)
stopWords = stoptxt[0].to_list()
words = ['说','年','VIP','真','这是','没','干','好像']
stopWords.extend(words)
# 运行~
ciYun(data,addWords,stopWords)
以上就是本次全部内容,如果你感兴趣,可以点赞+在看,需要完整代码的童鞋“点这里获取”