mysql慢查询优化
前言
在应用开发的早期,数据量少,开发人员开发功能时更重视功能上的实现,随着生产数据的增长,很多 SQL 语句开始暴露出性能问题,对生产的影响也越来越大,有时可能这些有问题的 SQL 就是整个系统性能的瓶颈。
提示:以下是本篇文章正文内容,下面案例可供参考
一、sql语句执行顺序
-
FROM(form)
先确定从哪个表中取数据,所以最先执行from tab。存在多表连接,from tab1,tab2。可以对表加别名,方便后面的引用。 -
ON(on)
连接多张表的附加条件
-
JOIN(join)
连接多张表的关键字
-
WHERE(where)
where语句是对条件加以限定,如果没有需要限定的,那就写成where 1=1,表示总为true,无附加条件。 -
GROUP BY(group by)
分组语句,比如按照员工姓名分组,要就行分组的字段,必须出现在select中,否则就会报错 -
聚合函数
常用的聚合函数有max(),min(), count(),sum(),聚合函数的执行在group by之后,having之前。如果在where中写聚合函数,就会出错
-
HAVING(having)
having是和group by配合使用的,用来作条件限定 -
SELECT(select)
选出要查找的字段,如果全选可以select *
-
DISTINCT(distinct)
去除数据中重复内容 -
ORDER BY(order by)
排序语句,**默认为升序(asc)**排列。如果要降序排列,就写成order by [XX] desc。order by语句在最后执行,只有select选出要查找的字段,才能进行排序。 -
LIMIT(limit)
分页关键字
二、sql优化手段
1.explain 分析SQL的执行计划
EXPLAIN是MySQl必不可少的一个分析工具,主要用来测试sql语句的性能及对sql语句的优化,或者说模拟优化器执行SQL语句。在select语句之前增加explain关键字,执行后MySQL就会返回执行计划的信息,而不是执行sql
- 需要重点关注 type、rows、extra。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FOSdRjXz-1650004751129)(D:\JAVA\javabasic81\博客\img\image-20220414112811348.png)]
- type由上至下,效率越来越高
- ALL 全表扫描
- index 索引全扫描
- range 索引范围扫描,常用语<,<=,>=,between,in 等操作
- ref 使用非唯一索引扫描或唯一索引前缀扫描,返回单条记录,常出现在关联查询中
- eq_ref 类似 ref,区别在于使用的是唯一索引,使用主键的关联查询
- const/system 单条记录,系统会把匹配行中的其他列作为常数处理,如主键或唯一索引查询
- null MySQL 不访问任何表或索引,直接返回结果
- 虽然上至下,效率越来越高,但是根据 cost 模型,假设有两个索引 idx1(a, b, c),idx2(a, c),SQL 为"select * from t where a = 1 and b in (1, 2) order by c";如果走 idx1,那么是 type 为 range,如果走 idx2,那么 type 是 ref;当需要扫描的行数,使用 idx2 大约是 idx1 的 5 倍以上时,会用 idx1,否则会用 idx2
- Extra
- Using filesort : MySQL 需要额外的一次传递,以找出如何按排序顺序检索行。通过根据联接类型浏览所有行并为所有匹配 WHERE 子句的行保存排序关键字和行的指针来完成排序。然后关键字被排序,并按排序顺序检索行;
- Using temporary:使用了临时表保存中间结果,性能特别差,需要重点优化;
- Using index:表示相应的 select 操作中使用了覆盖索引(Coveing Index),避免访问了表的数据行,效率不错!如果同时出现 using where,意味着无法直接通过索引查找来查询到符合条件的数据;
- Using index condition:MySQL5.6 之后新增的 ICP,using index condtion 就是使用了 ICP(索引下推),在存储引擎层进行数据过滤,而不是在服务层过滤,利用索引现有的数据减少回表的数据。
- Using where:限制要返回的select结果
2.show profile 分析
作用:了解 SQL 执行的线程的状态及消耗的时间。
show profile: 展示最近一条语句执行的详细资源占用信息,默认显示 Status和Duration两列
- 可以先select @@profiling 查看是否开启
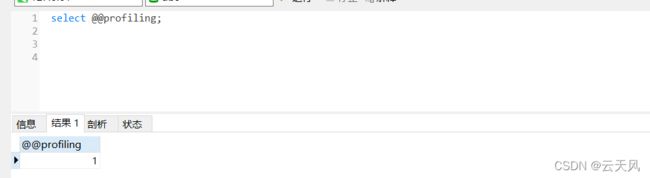
默认是关闭的,开启语句“set profiling = 1;”
- show profiles 查看
这个执行语句的剖析信息存储在这个会话中。使用SHOW PROFILES进行查 看。
show profiles :列表,显示最近发送到服务器上执行的语句的资源使用情况.
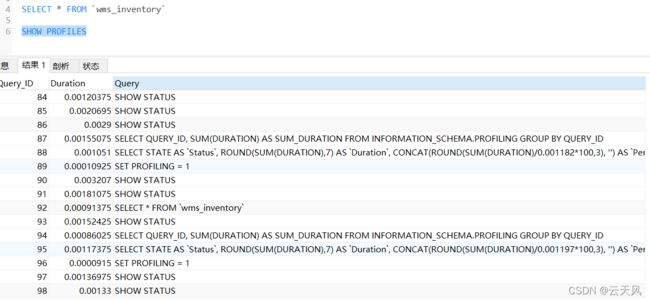
- show profile: 展示最近一条语句执行的详细资源占用信息,默认显示 Status和Duration两列

- 然后就能很容易的看到各环节的执行耗时,并且做出针对优化
三、sql优化的场景分析
1.limit语句
- 经典面试题,limit(n,m) 和 limit n 有什么区别
-- limit n,m是怎么回事,首先它要获取到第一个参数游标n的位置,那么它就必须得扫描到n的位置,接着从此位置起往后取m条数据,不足m条的返回实际的数量。那么这就会有一个性能的问题
-- 耗时0.006s
SELECT * FROM `wms_inventory` limit 1000
-- 耗时0.006s
SELECT * FROM `wms_inventory` limit 1,1000
-- 耗时0.009s
SELECT * FROM `wms_inventory` limit 1000,1000
- 总结:确定查询结果只有一条时,使用limit 1,可以避免全盘扫描,增加查询性能
2.最左匹配
- 索引
KEY `idx_shopid_orderno` (`shop_id`,`order_no`)
- sql语句
select * from _t where orderno=''
查询匹配从左往右匹配,要使用 order_no 走索引,必须查询条件携带 shop_id 或者索引(shop_id,order_no)调换前后顺序
3.隐式转换
- 索引
KEY `idx_phone` (`phone`)
- sql语句
select * from _user where phone=12345678901
隐式转换相当于在索引上做运算,会让索引失效。mobile 是字符类型,使用了数字,应该使用字符串匹配,否则 MySQL 会用到隐式替换,导致索引失效。
4.混合排序
MySQL 不能利用索引进行混合排序。但在某些场景,还是有机会使用特殊方法提升性能的。
例如:
SELECT *
FROM my_order o
INNER JOIN my_appraise a ON a.orderid = o.id
ORDER BY a.is_reply ASC,
a.appraise_time DESC
LIMIT 0, 20
explain 执行计划分析显示a表为全表扫描
+----+-------------+-------+--------+-------------+---------+---------+---------------+---------+-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra
+----+-------------+-------+--------+-------------+---------+---------+---------------+---------+-+
| 1 | SIMPLE | a | ALL | idx_orderid | NULL | NULL | NULL | 1967647 | Using filesort |
| 1 | SIMPLE | o | eq_ref | PRIMARY | PRIMARY | 122 | a.orderid | 1 | NULL |
+----+-------------+-------+--------+---------+---------+---------+-----------------+---------+-+
由于 is_reply 只有0和1两种状态,我们按照下面的方法重写后,执行时间从1.58秒降低到2毫秒。
SELECT *
FROM ((SELECT *
FROM my_order o
INNER JOIN my_appraise a
ON a.orderid = o.id
AND is_reply = 0
ORDER BY appraise_time DESC
LIMIT 0, 20)
UNION ALL
(SELECT *
FROM my_order o
INNER JOIN my_appraise a
ON a.orderid = o.id
AND is_reply = 1
ORDER BY appraise_time DESC
LIMIT 0, 20)) t
ORDER BY is_reply ASC,
appraisetime DESC
LIMIT 20;
总结:有些时候不能用索引进行混合排序,但是可以根据字段的特殊值进行变相优化。
5.in + order by 混合使用时
- 索引
KEY `idx_shopid_status_created` (`shop_id`, `order_status`, `created_at`)
- sql语句
select * from _order where shop_id = 1 and order_status in (1, 2, 3) order by created_at desc limit 10
in 查询在 MySQL 底层是通过 n*m 的方式去搜索,类似 union,但是效率比 union 高。
in 查询在进行 cost 代价计算时(代价 = 元组数 * IO 平均值),是通过将 in 包含的数值,一条条去查询获取元组数的,因此这个计算过程会比较的慢。
所以 MySQL 设置了个临界值(eq_range_index_dive_limit),5.6 之后超过这个临界值后该列的 cost 就不参与计算了。因此会导致执行计划选择不准确。
默认是 200,即 in 条件超过了 200 个数据,会导致 in 的代价计算存在问题,可能会导致 MySQL 选择的索引不准确。
处理方式:可以(order_status,created_at)互换前后顺序,并且调整 SQL 为延迟关联。
总结:在使用索引查询和in的语法时,尽量把索引字段放在最前面。
6.范围查询阻断,后续字段不能走索引
- 索引
KEY `idx_shopid_created_status` (`shop_id`, `created_at`, `order_status`)
- sql语句
select * from _order where shop_id = 1 and created_at > '2021-01-01 00:00:00' and order_status = 10
范围查询还有“IN、between”。
7.不等于、不包含不能用到索引的快速搜索
在索引上,避免使用 NOT、!=、<>、!<、!>、NOT EXISTS、NOT IN、NOT LIKE等。
8.asc 和 desc 混用
select * from _t where a=1 order by b desc, c asc
总结:desc 和 asc 混用时会导致索引失效
9.优化器选择不使用索引的情况
如果要求访问的数据量很小,则优化器还是会选择辅助索引,但是当访问的数据占整个表中数据的蛮大一部分时(一般是 20% 左右),优化器会选择通过聚集索引来查找数据。
select * from _order where order_status = 1
查询出所有未支付的订单,一般这种订单是很少的,即使建了索引,也没法使用索引。
10.大分页
- 索引
KEY `idx_a_b_c` (`a`, `b`, `c`)
- sql语句
select * from _t where a = 1 and b = 2 order by c desc limit 10000, 10;
对于大分页的场景,可以优先让产品优化需求,如果没有优化的,有如下两种优化方式:
- 一种是把上一次的最后一条数据,也即上面的 c 传过来,然后做“c < xxx”处理,但是这种一般需要改接口协议,并不一定可行
- 另一种是采用延迟关联的方式进行处理,减少 SQL 回表,但是要记得索引需要完全覆盖才有效果。
- 优化后sql
select t1.* from _t t1, (select id from _t where a = 1 and b = 2 order by c desc limit 10000, 10) t2 where t1.id = t2.id;
11.永远为每张表设置一个ID
我们应该为数据库里的每张表都设置一个ID做为其主键,而且最好的是一个INT型的(推荐使用UNSIGNED),并设置上自动增加的 AUTO_INCREMENT标志。
就算是你 users 表有一个主键叫 “email”的字段,你也别让它成为主键。使用 VARCHAR 类型来当主键会使用得性能下降。
12.越小的列会越快
对于大多数的数据库引擎来说,硬盘操作可能是最重大的瓶颈。所以,把你的数据变得紧凑会对这种情况非常有帮助,因为这减少了对硬盘的访问。
参看 MySQL 的文档 Storage Requirements 查看所有的数据类型。
如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理由使用 INT 来做主键,使用 MEDIUMINT, SMALLINT 或是更小的 TINYINT 会更经济一些。如果你不需要记录时间,使用 DATE 要比 DATETIME 好得多。
13.在Join表的时候使用相当类型的列,并将其索引
如果你的应用程序有很多 JOIN 查询,你应该确认两个表中Join的字段是被建过索引的。这样,MySQL内部会启动为你优化Join的SQL语句的机制。
而且,这些被用来Join的字段,应该是相同的类型的。例如:如果你要把 DECIMAL 字段和一个 INT 字段Join在一起,MySQL就无法使用它们的索引。对于那些STRING类型,还需要有相同的字符集才行。(两个表的字符集有可能不一样)
// 在state中查找company
SELECT company_name FROM users
LEFT JOIN companies ON (users.state = companies.state)
WHERE users.id = $user_id
// 两个 state 字段应该是被建过索引的,而且应该是相当的类型,相同的字符集。
总结
-
explain有sql分析性能
-
show profile分析性能
-
当只有一行数据时使用 LIMIT 1
-
为搜索字段建索引
-
索引并不一定就是给主键或是唯一的字段。如果在你的表中,有某个字段你总要会经常用来做搜索,那么,请为其建立索引吧。
-
索引失效的情况:
-
1.如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因),要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
-
2.对于多列索引,不是使用的第一部分,则不会使用索引最左匹配原则
-
3.like查询以%开头
-
4.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引(隐式转换)
-
5.如果mysql估计使用全表扫描要比使用索引快,则不使用索引
-
6.desc 和 asc 混用时会导致索引失效
-
-
-
在索引上,避免使用 NOT、!=、<>、!<、!>、NOT EXISTS、NOT IN、NOT LIKE等。
-
如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引(隐式转换)
-
如果mysql估计使用全表扫描要比使用索引快,则不使用索引
-
desc 和 asc 混用时会导致索引失效
-
在索引上,避免使用 NOT、!=、<>、!<、!>、NOT EXISTS、NOT IN、NOT LIKE等。
-
在Join表的时候使用相当类型的列,并将其索引
-
永远为每张表设置一个ID
-
越小的列会越快
-
采用延迟关联的方式进行处理,减少 SQL 回表
-
在使用索引查询和in的语法时,尽量把索引字段放在最前面
温馨提示:
总结内容均可在优化场景分析和手段中找到啊!!!!!!!!!!!!!