学习目标
自考重点、期末考试必过指南,这篇文章让你理解什么是栈、什么是队列、什么是数组
掌握栈、队列的顺序存储结构和链式存储结构
掌握栈、队列的基本操作在顺序存储结构和链式存储结构上的实现
掌握矩阵的压缩存储
今天核心咱们先把栈搞清楚
栈和队列可以看做是特殊的线性表 。它们的特殊性表现在它们的基本运算是线性表运算的子集,它们是运算受限的线性表
栈
栈(Stack)是运算受限的线性表,这种线性表上的插入和删除操作限定在表的一端进行
基本概念
栈顶:允许插入和删除的一端 栈尾:另一端 空栈:不含任何数据元素的栈 栈顶元素:处于栈顶位置的数据元素
书中的例子比较形象
洗盘子,放盘子,每次只能从这一摞盘子的最上面拿走,这就是栈的基本操作
看重点:栈---> ==后进先出(Last In First Out) LIFO 原则 ==
所以栈被称作 后进先出线性表 (后进先出表)
栈的插入和删除运算 分为成为 进栈和 出栈
栈的基本运算
- 初始化 InitStack(S) 构造一个空栈 S
- 判断栈空 EmptyStack(S) 若栈为空,返回 1,否则返回 0
- 进栈 Push(S,x) 将元素 x 插入栈 S 中
- 出栈 Pop(S) 删除栈顶元素
- 取栈顶 GetTop(S) 返回栈顶元素
栈的顺序实现
这里面有两个小知识点在写代码之前需要掌握
空栈做出栈操作,会出现问题,叫做“下溢” 满栈做进栈操作,会出现问题,叫做“上溢”
接下来我们就用 C 语言实现一下
初始化一个空栈
#include#include // 声明顺序栈的容量 const int maxsize = 6; struct seqtack{ int *data; //存储栈中元素的数组 int top; // 栈顶下标 }; typedef struct seqtack Seq; // 初始化操作 Seq init(Seq s){ printf("初始化函数运行\n"); s.data = (int*)malloc(maxsize*sizeof(int));//动态分配存储空间 if(!s.data){ printf("初始化失败"); exit(0); } s.top = 0; return s; }
注意事项
初始化需要动态分配空间,并且需要让 top 值等于 0
判断栈空
//判断栈空
int empty(Seq s){
printf("判断栈空\n");
if(s.top == 0){
return 1;
}
return 0;
}
这个比较简单了,只需要判断 s.top 值就可以了
进栈操作
//进栈操作
Seq push(Seq s,int x){
printf("进栈操作\n");
// 判断栈是否满了
if(s.top==maxsize-1){
printf("栈满");
return s;
}
else{
printf("正在插入数据%d\n",x);
s.data[s.top] = x;
s.top++;
return s;
}
}
出栈操作
//出栈操作
Seq pop(Seq s,int *e){
if(empty(s)){
printf("栈空\n");
exit(0);
}
else{
*e = s.data[s.top-1];
s.top--;
return s;
}
}
进栈和出栈,这部分内容一定要好好的理解,其实也是比较简单的,就是添加元素和删除元素
打印栈中元素与获取栈顶元素
// 打印栈中元素
void display(Seq s){
if(empty(s)){
printf("栈空\n");
exit(0);
}
else{
printf("开始打印\n");
int num = 0;
while(num < s.top){
printf("现在的元素是:%d\n",s.data[num++]);
}
}
}
// 获取栈顶元素
int gettop(Seq s){
if(empty(s)){
exit("栈空\n");
}
else{
return s.data[s.top-1];
}
}
主函数测试代码
int main()
{
printf("代码运行中\n");
Seq s ;
s = init(s);
//插入两个元素
s = push(s,1);
s = push(s,2);
display(s);
int e;
s = pop(s,&e);
printf("删除的元素是:%d\n",e);
display(s);
return 0;
}
双栈
书中还提到了双栈,不过这个不是重点了,你要知道的是,双栈的两个栈底分别设置在数组的两端,栈顶分为是 top1,top2
两个栈顶在中间相遇,条件为 (top1+1=top2)发生上溢
判断栈空条件呢? 一个是 top=0 另一个是 top = maxsize -1 这个要注意一下即可
栈的链接实现
栈的链接实现称为==链栈==。链栈 可以用带头结点的单链表来实现,链栈不用预先考虑容量的大小
链栈将链表头部作为栈顶的一端,可以避免在实现数据“入栈”和“出栈”操作时做大量遍历链表的耗时操作
链表的头部作为栈顶,有如下的好处
- 入栈 操作时,只需要将数据从链表的头部插入即可
- 出栈 操作时,只需要删除链表头部的首结点即可
结论:链表实际上就是一个只能采用头插法插入或删除的链表
例子:将元素 1,2,3,4 依次入栈,等价于将各元素采用头插法依次添加到链表中

图片来源网络
完整代码如下
由于比较简单,直接贴上了
#include#include typedef struct node{ int data; //数据域 struct node *next; //链域 } LkStk; //初始化 void init(LkStk *ls){ printf("初始化操作\n"); ls = (LkStk *)malloc(sizeof(LkStk)); ls->next = NULL; } // 进栈 void push(LkStk *ls,int x){ printf("进栈操作\n"); LkStk *temp; temp = (LkStk*)malloc(sizeof(LkStk));//给temp新申请一块空间 temp->data = x; temp->next = ls->next; ls->next = temp; printf("%d进栈成功\n",x); } int empty(LkStk *ls){ if(ls->next ==NULL){ return 1; } else return 0; } // 出栈 int pop(LkStk *ls){ LkStk *temp; //判断栈是否为空 if(!empty(ls)){ temp= ls->next; // 准备出栈的元素指向ls的下一结点 ls->next = temp->next; // 原栈顶的下一个结点称为新的栈顶 printf("栈顶元素:%d\n",temp->data); free(temp); //释放原栈顶的结点空间 return 1; } return 0; } int main() { LkStk ls; init(&ls); push(&ls,1); push(&ls,2); pop(&ls); pop(&ls); return 0; }
这就是链栈的基本进栈和出栈了,当然,我们还可以获取一下栈顶元素
考试要点
在自考或者期末考试中,容易出现的一种题是手写入栈和出栈 例如
设一个链栈的输入序列为 A、B、C,试写出所得到的所有可能的输出序列,即输出出栈操作的数据元素序列
写答案的时候,记住先进后出原则
从 A 开始写 A 进,A 出,B 进,B 出,C 进,C 出 A 进,B 进,B 出,C 进,C 出,A 出 ... ... 继续写下去就可以了,一定不要出现 A 进,B 进,B 出,C 进,==A 出== 注意,A 出不去,A 前面有 C 呢
在来一个例题
如图所示,在栈的输入端元素的输入顺序为 A,B,C,D,进栈过程中可以退栈,写出在栈的输出端以 A 开头和以 B 开头的所有输出序列。
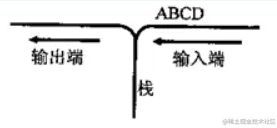
这个就是把 A 开头和 B 开头的都写出来
- ABCD、ABDC、ACBD、ACDB、ADCB
- BACD、BADC、BCAD、BCDA、BDCA
主要仔细,就能写对,套路就是,先进后出
小结
栈是只能在一端(栈顶)进行插入和删除运算的线性表,具有后进先出特征。
以顺序存储结构实现的栈称为顺序栈,以链式存储结构实现的栈称为链栈。
顺序栈需要预先定义栈的大小,在难以估计栈的大小时,可以采用链栈,链栈是用单链表实现。一般地,将栈顶设在链表的表头一端,栈底设置在链表的表尾。栈适合与具有后进先出特征的问题。
到此这篇关于C语言数据结构不挂科指南之栈&队列&数组详解的文章就介绍到这了,更多相关C语言栈 队列 数组内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!