YOLOv4学习总结
YOLOv4改进优化部分学习总结
- YOLOv4
-
- 一. 整体模型结构
- 二. 检测效果
- 三. 重点部分详细介绍
-
- 1. CSPDarknet53
-
- (1)优点
- (2)思路与结构
- 2. SPP(Spatial Pyramid Pooling)
-
- (1)优点
- (2)结构与作用
- 3. PAN(Path Aggregation Network)
-
- (1)优点
- (2)结构与作用
- 4. Mosaic 数据增强
-
- 优点
- 具体过程
- 5. IOU threshold
-
- 极限预测框的问题
- 激活函数改进过程
- 6. CIOU
-
- (1)IOU
- (2)GIOU
- (3)DIOU
- (4)CIOU
YOLOv4
这里记录个人yolov4的学习,基于yolov4创新点展开,侵删。
一. 整体模型结构

BackBone:CSPDarknet53
Neck:SPP,PAN
Head:YOLOv4
二. 检测效果
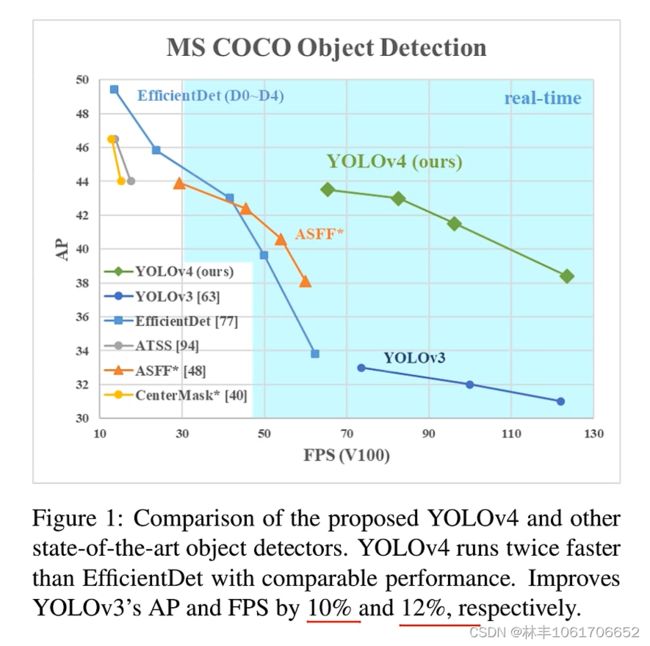
三. 重点部分详细介绍
1. CSPDarknet53

图中蓝色框的部分就是CSPDarknet53
(1)优点
- 增强CNN学习能力
- 解决计算瓶颈
- 减少内存开销
(2)思路与结构

CSPX块。其实就是将特征图层在通道上分成两部分,如128通道直接切分成64通道和64通道,一个支路(Part1)直接传递到后面,一个支路(Part2)进行卷积特征提取等处理(Dense Block),转换(Transition)后与另一个支路融合(Transition)到一起。
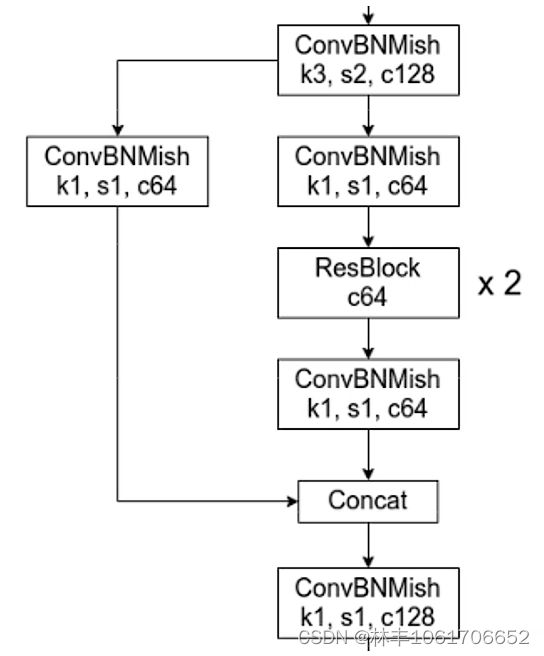
yolov4 的 CSPDarkNet 就是将 CSPNet 的思想和 DarkNet 融合到一起,如上图,通过两次64个128通道的卷积核将特征图层分成两个64通道的特征图层(个人理解的话,也可以直接切分成两个64通道的特征图层),左边支路不处理,右边支路通过 DarkNet 的 ResBlock 进行处理,然后通过 1*1 的卷积来进行转换后,和左边支路直接 concat 到一起。
其中激活函数是 Mish。
2. SPP(Spatial Pyramid Pooling)

SPP就是图中蓝色粗框的那个部分
(1)优点
解决了多尺度检测的问题
(2)结构与作用
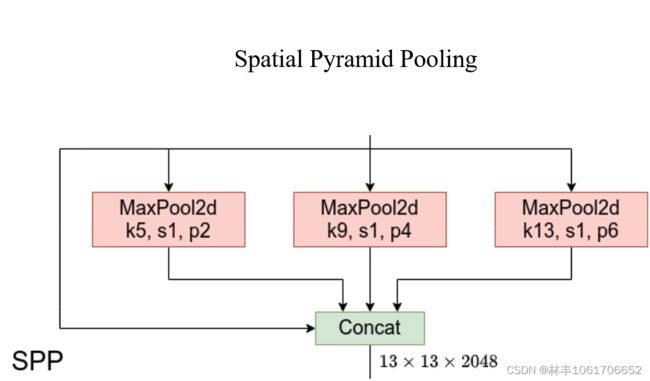
就是将多个尺度的特征图层进行concat融合到一起,从而让特征图层拥有在不同尺度下的特征。
每个分支的 MaxPooling 就是为了将同一个特征图层变成不同尺度的特征图层(这里可以用不同感受野的卷积或者其他方法代替,但是 MaxPooling 的计算更小)。
3. PAN(Path Aggregation Network)
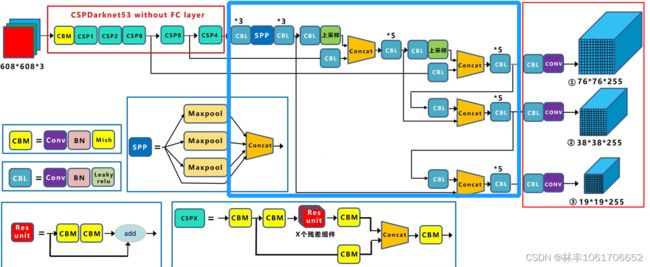
图中蓝色粗框部分就是PAN
(1)优点
让浅层特征图层有深层特征图的语义信息;让深层特征图层有浅层特征图层的细节信息。
(2)结构与作用

PAN(红色框部分)。红色框左半部分是 FPN,就是将深层特征图(图中 P2 P3 P4 P5 越往上越深)与浅层特征图进行融合(这里的融合一般是将深层特征图进行上采样,然后与浅层特征图直接相加或者在通道维度 concat 的方式融合,yolov4是通过 concat 的方式融合),就是让浅层特征图层也能有深层特征图的语义信息;红色框右半部分是相反的思想,将浅层的特征图(图中N2 N3 N4 N5 越往下越浅)与深层特征图进行融合(这里就是将浅层特征图进行下采样,然后和深层的融合)。
其中激活函数是 LeakyReLU。
4. Mosaic 数据增强
优点
丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
减少GPU:很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
具体过程
(1)首先随机取四张图片
(2)分别对四张图片进行数据增广操作,并分别粘贴至与最终输出图像大小相等掩模的对应位置。
操作包括:
1、翻转(对原始图片进行左右的翻转);
2、缩放(对原始图片进行大小的缩放);
3、色域变化(对原始图片的明亮度、饱和度、色调进行改变)等操作。
(3)进行图片的组合和框的组合
完成四张图片的摆放之后,我们利用矩阵的方式将四张图片它固定的区域截取下来,然后将它们拼接起来,拼接成一 张新的图片,新的图片上含有框框等一系列的内容。

5. IOU threshold
极限预测框的问题

如图预测框是由卷积计算出来的,bx、by 表示预测框的中心点,bw、bh 表示预测框的宽高,cx、cy 表示中心点所在像素的左上角的坐标。
而卷积后面会有一个激活函数sigmoid(如下图),计算公式为


这样的话,如果预测框的在交点(上图红点),就需要满足 σ(tx)=0,σ(ty)=0,然而由于sogmoid激活函数是只有在无限大的时候才能是0,因此不能满足条件。
激活函数改进过程
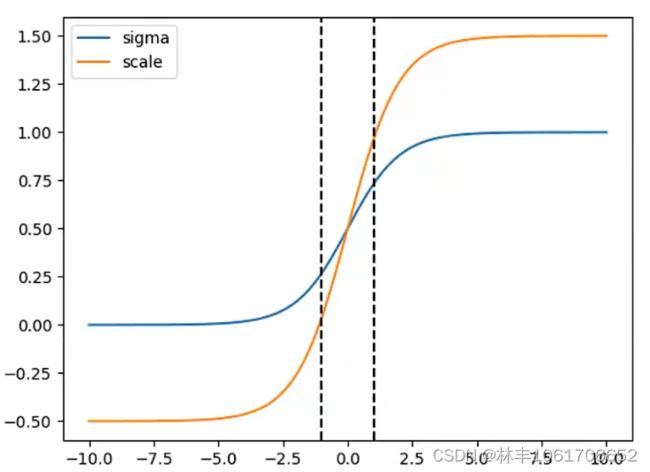
因此,可以对激活函数进行缩放(如下图),让它能包含 y=0 和 y=1,从而能实现 σ(tx)=0,σ(ty)=0。
- 原来的

- 改进计算:

- 主流计算(就是将 scalexy 设定为 2)
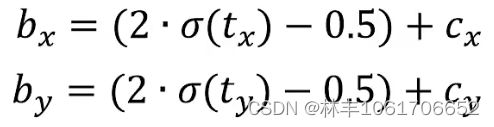
结果图示:
6. CIOU
CIOU是由IOU基于实际应用情况一步步改进而来的,IOU->GIOU->DIOU->CIOU
(1)IOU


(2)GIOU
问题
Predict 和 Ground Truth 没有相交时IOU均为0,但是我们更需要和 Ground Truth 距离更近的 Predict 框(如下图,我们更需要右边的预测框,但是这两个预测框的 IOU 都是 0)。

解决方法
引进了一个 Predict 和 Ground Truth 的最小外接矩(下图把Predict 和 Ground Truth 包围起来的蓝色框)

AC就是最小外接矩的大小,U是 Predict 和 Ground Truth 的并集,这样最小外接矩越小说明他们的距离越近,GIOU就越大。
(3)DIOU
问题
GIOU在下图这两种情况的分数都是一样的,但是很明显,我们更需要的是右边的预测框。
解决方法
基于此,GIOU通过引进Predict 和 Ground Truth之间中心点距离的计算来解决这个问题。

式子中,b 表示 Predict 的中心点,bgt表示Ground Truth的中心点,ρ(b, bgt)表示计算b和bgt的欧式距离,c表示最小外接矩的对角线长度。这样,Predict的中心点越接近Ground Truth的中心点,DIOU就越大。

(4)CIOU
终于到了CIOU,CIOU也是在DIOU的基础上改进的。
问题
如下图,这两种情况的DIOU数值是一样的,但是我们显然更倾向于让左边这种情况的评价分数更大,右边的评价分数更小。基于这个需求,CIOU诞生。

解决方法
因此,我们可以引入一个长宽比来计算。

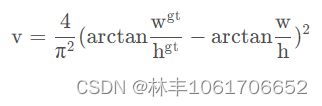

先放公式。
①我们可以看到CIOU的左边部分其实就是DIOU的改进计算部分,就不多说了;
②第二个式子:CIOU的右边部分的 v 就是计算 Predict 和 Ground Truth 对角线的角度之差,其中 arctan(wgt/hgt) 表示Ground Truth 的对角线角度, arctan(w/h) 表示 Predict 的对角线角度,两者之差就直接相减,去除正负值的影响就平方一下,左边的(4/pai^2) 个人理解就是将右边的差平方变成一个0~1之间的参数。
③第三个式子:就是一个参数,没理解它,不懂。
以上就是个人YOLOv4的学习情况。
有什么建议、问题,欢迎补充。