第02章 前馈神经网络
序言
1. 内容介绍
本章介绍第一个深度学习算法-前馈神经网络,主要介绍前馈神经网络 (FNN) 模型的算法模型、数学推理、模型实现以及主流框架的实现。并能够把它应用于现实世界的数据集实现分类效果。
2. 理论目标
- 前馈神经网络的理论基础
- 前馈神经网络的基础模型架构
- 前馈神经网络的数学推理
3. 实践目标
- 掌握PyTorch,Tensorflow框架下FNN的实现
- 掌握使用FNN处理分类问题
- 掌握FNN算法的优劣
4. 实践数据集
- MNIST 数据集分类
- Fasion-MNIST 数据集分类
5. 内容目录
- 1.前馈神经网络简介
- 2.前馈神经网络模型详解
- 3.前馈神经网络传播详解
- 4.前馈神经网络代码实现
- 5.PyTorch 实践
第1节 前馈神经网络简介
前馈神经网络是一种最简单的神经网络,各神经元分层排列。每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层.各层间没有反馈。是目前应用最广泛、发展最迅速的人工神经网络之一。研究从 20 世纪 60 年代开始,目前理论研究和实际应用达到了很高的水平。
人工智能领域中,最早发明的简单人工神经网络类型。在它内部,参数从输入层向输出层单向传播。
它本身是经典感知机 (Preceptron) 算法的进化版本。感知机是非线性回归,前馈神经网络一层层堆叠多个感知器层。多层感知机 (MLP),是多层的全连接的前馈网络。
前馈神经网络结构简单,应用广泛,能够以任意精度逼近任意连续函数及平方可积函数.而且可以精确实现任意有限训练样本集。从系统的观点看,前馈网络是一种静态非线性映射.通过简单非线性处理单元的复合映射,可获得复杂的非线性处理能力。
第2节 前馈神经网络模型详解
前馈神经网络包括三类节点:
- 输入节点(Input Layers):外界信息输入,不进行任何计算,仅向下一层节点传递信息
- 隐藏节点(Hidden Layers):接收上一层节点的输入,进行计算,并将信息传到下一层节点
- 输出节点(Output Layers):接收上一层节点的输入,进行计算,并将结果输出
通常FNN有 N + 1 层(N − 1 个隐藏层)的神经网络。浅层网络架构仅使用一个隐藏层。深度学习需要使用多个隐藏层,通常包含同样数量的隐藏神经元。数量大约是输入和输出变量数量的平均值。
FNN 由一个输入层、一个(浅层网络)或多个(深层网络,因此叫作深度学习)隐藏层,和一个输出层构成。每个层(除输出层以外)与下一层连接。这种连接是 FNN 架构的关键,具有两个主要特征:加权平均和激活函数。
2.1 加权平均
FNN 很重要的一个概念就是加权平均过程,即将前一层给神经元的激励值和对应的权重矩阵相乘而得出后一个神经元的输入值,换而言之,前一层神经元的加权和就是作为后一层神经元的输入。
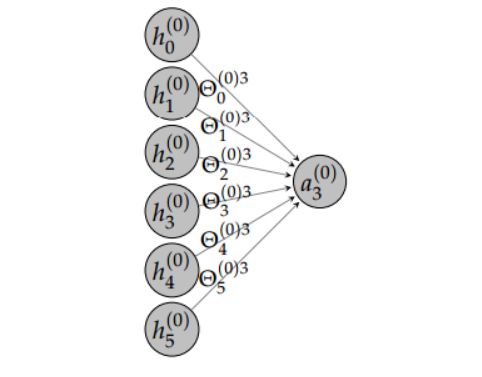
正式地,加权平均的过程可以使用如下方程式表达:
a^{(t)(v)}_f=\Sigma^{F_v-1+\epsilon}_{f'=0}\Theta^{(v)f}_{f'}h^{(t)(v)}_{f'}af(t)(v)=Σf′=0Fv−1+ϵΘf′(v)fhf′(t)(v)
其中 v∈[0,N−1]、f∈[0,F_{v+1} - 1Fv+1−1]、t∈[0,T_mb - 1Tmb−1]。\epsilonϵ代表包括或排除一个偏置项,因为实践中我们经常使用批量归一化,所以\epsilonϵ可以设为 0。
2.2 激活函数
每一层的隐藏神经元可以定义为:
h^{(t)(v+1)}_f= g(a^{(t)(v)}_f)hf(t)(v+1)=g(af(t)(v))
其中 v∈[0,N−1]、f∈[0,F_{v+1} - 1Fv+1−1]、t∈[0,T_mb - 1Tmb−1]。在这里 g 为激活函数,FNN 另外一个十分重要的元素,因为激活函数的非线性属性,所以它允许预测任意的输出数据。在实践中,g 通常采取以下描述的非线性函数作为激活函数。
- Sigmoid 函数
- Tanh 函数
- ReLu 函数
- Leaky ReLu 函数
- ELu 函数
2.3 FNN层级
- 输入层
输入层是 FNN 的第一层神经元,它需要将输入数据传入 FNN 中。在全连接神经网络中,输入层的神经元数量但与特征向量的长度相等,比如说 MNIST 数据集的图像为 28×28,那么特征向量的长度就为 764。
- 全连接层
全连接操作即运算层级之间的加权平均值和激活函数,即前一层的神经元输出值加权和为后一层的输入值,并将该输入值投入激活函数中以产生该层级的输出值。
- 输出层
FNN 的输出层可以表示为:
h^{(t)(N)}_f = o(a^{(t)(N-1)}_f)hf(t)(N)=o(af(t)(N−1))
其中 o 为输出函数。
第3节 前馈神经网络传播详解
此章涉及到的神经网络基础概念:
- 反向传播
- 梯度下降
- 损失函数
- 正规化
- 学习率
作为初代人工神经网络模型,前馈神经网络(FNN)不考虑输入数据可能具备的任何特定结构。尽管如此,它仍是非常强大的机器学习工具,尤其是与先进的正规化技术一起使用时。这些技术帮助解决人们处理「深度」网络时遇到的训练问题:神经网络有大量隐藏层,隐藏层非常难以训练(梯度消失和过拟合问题)。
3.1 前向传播
为了描述神经网络,需从最简单的神经网络讲起。这个神经网络仅由一个“神经元”构成,神经网络的每个单元如下:
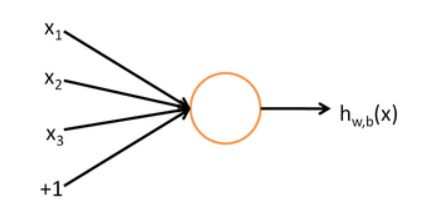
这个“神经元”是一个以 x_1,x_2,x_3x1,x2,x3 及截距 +1 为输入值的运算单元,其输出对应的公式为:
h_{w,b}(x) = f(W^Tx) = f(\sum^3_{i=1}W_ix_i+b)hw,b(x)=f(WTx)=f(∑i=13Wixi+b)
函数 f = \Re \to \Ref=ℜ→ℜ 被称为激活函数。
其中,该单元也可以被称作是Logistic回归模型。当将多个单元组合起来并具有分层结构时,就形成了神经网络模型。下图展示了一个具有一个隐含层的前馈神经网络。
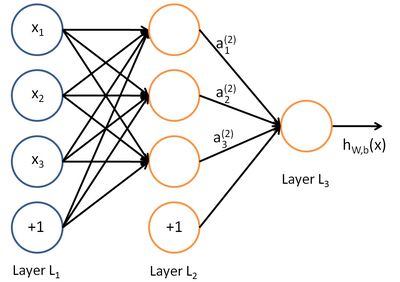
前馈神经网络就是将许多个单一“神经元”联结在一起,这样,一个“神经元”的输出就可以是另一个“神经元”的输入。同时可以看到,以上神经网络的例子中有3个输入单元(偏置单元不计在内),3个隐藏单元及一个输出单元。
n_lnl 来表示网络的层数,本例中 n_lnl = 3 ,我们将第 1 层记为 L_1L1 ,于是 L_1L1 是输入层,输出层是 L_{n1}Ln1。本例神经网络参数为
(W,b)=(W^{(1)},b^{(1)},W^{(2)},b^{(2)})(W,b)=(W(1),b(1),W(2),b(2)) ,
其中 W_{ij}^{(l)}Wij(l) 是第 11 层第 jj 单元与第 l+1l+1 层第 ii 单元之间的联接参数(连接线上的权重),b_i^{(l)}bi(l) 是第 l+1l+1 层第 ii 单元的偏置项。因此在本例中,W^{(1)} \in \Re^{3 \times 3}W(1)∈ℜ3×3 , W^{(2)} \in \Re^{1 \times 3}W(2)∈ℜ1×3 。注意,没有其他单元连向偏置单元,因为它们总是输出+1+1。同时,我们用 s_1s1 表示第 l 层的节点数(偏置单元不计在内)。
我们用 a_i^{(l)}ai(l) 表示第 l 层第 i 单元的"激活值"(输出值)。当 l = 1l=1 时,a_i^{(1)} = x_iai(1)=xi ,也就是第 ii 个输入值(输入值的第 ii 个特征)。对于给定参数集合 W,bW,b ,我们的神经网络就可以按照函数 h_{W,b}(x)hW,b(x) 来计算输出结果。本例神经网络的计算步骤如下:
a^{(2)}_1 = f(W_{11}^{(1)}x_1 + W_{12}^{(1)}x_2 + W_{13}^{(1)}x_3 + b^{(1)}_1)a1(2)=f(W11(1)x1+W12(1)x2+W13(1)x3+b1(1))
a^{(2)}_2 = f(W_{21}^{(1)}x_1 + W_{22}^{(1)}x_2 + W_{23}^{(1)}x_3 + b^{(1)}_2)a2(2)=f(W21(1)x1+W22(1)x2+W23(1)x3+b2(1))
a^{(2)}_3 = f(W_{31}^{(1)}x_1 + W_{32}^{(1)}x_2 + W_{33}^{(1)}x_3 + b^{(1)}_3)a3(2)=f(W31(1)x1+W32(1)x2+W33(1)x3+b3(1))
h_{W,b}(x) = a_1^{(3)} = f(W_{11}^{(2)}a_1^{(2)} + W_{12}^{(2)}a_2^{(2)} + W_{13}^{(2)}a_3^{(2)} + b^{(2)}_1)hW,b(x)=a1(3)=f(W11(2)a1(2)+W12(2)a2(2)+W13(2)a3(2)+b1(2))
我们用 z_i^{(l)}zi(l) 表示第 ll 层第 ii 单元输入加权和(包括偏置单元),比如,z_i^{(2)} = \sum^n_{j=1}W^{(1)}_{ij}x_j+b^{(1)}_izi(2)=∑j=1nWij(1)xj+bi(1),则a^{(l)}_i = f(z^{(l)}_i)ai(l)=f(zi(l))。
这样我们就可以得到一种更简洁的表示法。这里我们将激活函数 f(x)f(x) 扩展为用向量(分量的形式)来表示,即 f([z_1,z_2,z_3])=[f(z_1),f(z_2),f(z_3)])f([z1,z2,z3])=[f(z1),f(z2),f(z3)]),那么,上面的等式可以更简洁地表示为:
z^{(2)} = W^{(1)}x + b^{(1)}z(2)=W(1)x+b(1)
a^{(2)} = f(z^{(2)})a(2)=f(z(2))
z^{(3)} = W^{(2)}a^{(2)} + b^{(2)}z(3)=W(2)a(2)+b(2)
h_{W,b}(x) = a^{(3)} = f(z^{(3)})hW,b(x)=a(3)=f(z(3))
我们将上面的计算步骤叫作前向传播。回想一下,之前用 a^{(1)} = xa(1)=x 表示输入层的激活值,那么给定第 ll 层的激活值 a^{(l)}a(l) 后,第 l+1l+1 层的激活值 a^{(l+1)}a(l+1) 就可以按照下面步骤计算得到:
z^{(l+1)} = W^{(l)}a^{(l)} + b^{(l)}z(l+1)=W(l)a(l)+b(l)
a^{(l+1)} = f(z^{(l+1)})a(l+1)=f(z(l+1))
将参数矩阵化,使用矩阵 \to→ 向量运算方式,就可以利用线性代数的优势对神经网络进行快速求解。这是一个前馈神经网络的例子,因为这种联接图没有闭环或回路。
3.2 损失函数
损失函数评估了 FNN 在估计数据并执行预测时的误差,通常是我们判断模型在一定权重下执行任务好坏的依据。损失函数一般是计算真实值和预测值之间的距离而判断误差。对于回归问题来说,简单地使用均方误差(MSE)就可以评估预测值与真实值之间的距离:
J(\Theta) = \frac{1}{2T_{mb}}\sum^{T_{mb}-1}_{t=0}\sum^{F_N-1}_{f=0}(y_f^{(t)} - h_f^{(t)(N)})^2J(Θ)=2Tmb1∑t=0Tmb−1∑f=0FN−1(yf(t)−hf(t)(N))2
对于分类任务来说,损失函数一般可以使用交叉熵函数。针对预测分布最小化交叉熵函数就等价于 KL 散度,所以它评估了预测分布和真实分布之间的距离:
J(\Theta) = - \frac{1}{T_{mb}}\sum^{T_{mb}-1}_{t=0}\sum^{F_N-1}_{f=0}\delta^f_{y^{(t)}}\ln h^{(t)(N)}_fJ(Θ)=−Tmb1∑t=0Tmb−1∑f=0FN−1δy(t)flnhf(t)(N)
3.3 反向传播
反向传播是减少损失函数错误的标准技术,只要准确地预测需要哪一个就行。就像名字所示,在 FNN 网络中反向传播输出层的错误,以便于更新权重。在实际中,我们需要计算大量的梯度,这是一项冗长的计算任务。然而,如果表现准确,这也是 FN 中最有用、最重要的任务。
3.4 梯度优化
共有三种从数据中进行采样的方法:
- Full-bath
- 随机梯度下降
- 小批量梯度下降
一旦在反向传播过程中计算了梯度,那么接下来就需要考虑如何使用这些梯度更新权重了。可能最自然和直观的方法就是直接使用梯度下降更新权重,梯度下降的更新表达式为:
\Theta^{(v)f}_{f'} = \Theta^{(v)f}_{f'} - \eta\triangle^{\Theta(i)f}_{f'}Θf′(v)f=Θf′(v)f−η△f′Θ(i)f
其中 \etaη 为超参数学习率,确定 \etaη 最好的方法是在下降点执行直线搜索而求得,不过这样的计算成本非常高,所以一般可以根据经验或交叉验证等方法确定该超参数。同时学习率还可以使用指数衰减更进一步加快收敛速度。在使用小批量梯度下降时,根据损失函数而更新的权重很容易陷入局部极小值,因此有一些方法可以避免这种风险。可选用的优化函数为:
- Momentum
- Nesterov accelerated gradient
- Adagrad
- RMSprop
- Adam
3.5 权重初始化
在没有任何正则化的情况下,训练神经网络令人望而却步,因为要对权重初始化条件进行微调。这也是为什么神经网络经历过寒冬的一个原因。因为 dropout 与批规范化技术,该问题有所改进,但同样不能用对称的方式初始化权重(例如都是 0),也不能把它们初始化的太大。一个好的 heuristic 是:
\begin{bmatrix}\Theta^{(v)f'}_f\end{bmatrix}_{init} = \sqrt{\frac{6}{F_i+F_{i+1}}} \times N(0,1)[Θf(v)f′]init=Fi+Fi+16×N(0,1)
第4节 前馈神经网络代码复现
4.1 Pytorch
- 输入层与输出层采用 torch.nn.Linear 线性关系
- 隐藏层采用 torch.nn.ReLU 激活函数
- build_fnn 函数预设置参照MNIST数据集
- 图片格式为 1\times28\times281×28×28 ,即输入层采用784个特征
- 图片标签为10个数字,即输出层生成10个标签
# %load ffn.py import torch import torch.nn as nn class FeedForwardNetwork(nn.Module): def __init__(self,input_size,hidden_size,num_classes): super(FeedForwardNetwork, self).__init__() self.fc1 = nn.Linear(input_size,hidden_size) self.relu = nn.ReLU(inplace=True) self.fc2 = nn.Linear(hidden_size,num_classes) def forward(self,x): out = self.fc1(x) out = self.relu(out) out = self.fc2(out) return out def build_fnn(phase, input_size=784, hidden_size=500,num_classes=10): if phase != "test" and phase != "train": print("ERROR: Phase: " + phase + " not recognized") return return FeedForwardNetwork(input_size, hidden_size, num_classes)
from torchsummary import summary net = build_fnn('train') net.cuda() summary(net,(1,784))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Linear-1 [-1, 1, 500] 392,500
ReLU-2 [-1, 1, 500] 0
Linear-3 [-1, 1, 10] 5,010
================================================================
Total params: 397,510
Trainable params: 397,510
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.01
Params size (MB): 1.52
Estimated Total Size (MB): 1.53
----------------------------------------------------------------
4.2 Tensorflow
- 输入层与输出层采用 tensorflow.nn.xw_plus_b 线性函数
- 隐藏层采用 tensorflow.nn.relu 激活函数
import tensorflow as tf def fcLayer(x, input_size, output_size, reluFlag, name): with tf.variable_scope(name) as scope: w = tf.get_variable("w", shape = [input_size, output_size], dtype = "float") b = tf.get_variable("b", [output_size], dtype = "float") out = tf.nn.xw_plus_b(x, w, b, name = scope.name) if reluFlag: return tf.nn.relu(out) else: return out class FFN_TF(object): def __init__(self, x, input_size, hidden_size, num_classes): self.X = x self.input_size = input_size self.hidden_size = hidden_size self.num_classes = num_classes self.buildFFN() def buildFFN(self): fc1 = fcLayer(self.X, self.input_size, self.hidden_size, True, "fc1") fc2 = fcLayer(fc1, self.hidden_size, self.num_classes, False, "fc2")
第5节 PyTorch 实践
5.1 模型训练代码
加载同级目录下 train.py 程序代码
# %load train.py import os os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" import time import argparse import sys import torch import torch.nn as nn import torch.optim as optim import torch.backends.cudnn as cudnn from torchvision import transforms from torch.autograd import Variable import matplotlib as mpl import matplotlib.pyplot as plt mpl.rc('axes', labelsize = 14) mpl.rc('xtick', labelsize = 12) mpl.rc('ytick', labelsize = 12) sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))) from ffn import build_fnn from datasets.MNIST.mnist import MNIST_ROOT,MNIST from datasets.FASHION_MNIST.fashion_mnist import FASHION_MNIST_ROOT,FASHION_MNIST def str2bool(v): return v.lower() in ("yes", "true", "t", "1") parser = argparse.ArgumentParser( description='FeedForward Neural Network Training With Pytorch') train_set = parser.add_mutually_exclusive_group() parser.add_argument('--dataset', default='MNIST', choices=['MNIST', 'FASHION_MNIST'], type=str, help='MNIST or FASHION_MNIST') parser.add_argument('--dataset_root', default=MNIST_ROOT, help='Dataset root directory path') parser.add_argument('--hidden_size', default=500, type=int, help='Hidden layer size') parser.add_argument('--batch_size', default=32, type=int, help='Batch size for training') parser.add_argument('--num_workers', default=0, type=int, help='Number of workers used in dataloading') parser.add_argument('--epoch_size', default=30, type=int, help='Number of Epoches for training') parser.add_argument('--cuda', default=True, type=str2bool, help='Use CUDA to train model') parser.add_argument('--lr', '--learning-rate', default=1e-3, type=float, help='initial learning rate') parser.add_argument('--save_folder', default='weights/', help='Directory for saving checkpoint models') args = parser.parse_args() if not os.path.exists(args.save_folder): os.mkdir(args.save_folder) def train(): if args.dataset == 'MNIST': if args.dataset_root == MNIST_ROOT: if not os.path.exists(MNIST_ROOT): parser.error('Must specify dataset_root if specifying dataset') args.dataset_root = MNIST_ROOT dataset = MNIST(root=args.dataset_root,folder='train', transform=transforms.ToTensor()) elif args.dataset == 'FASHION_MNIST': if args.dataset_root == MNIST_ROOT: print("Using default FASHION_MNIST dataset_root") args.dataset_root = FASHION_MNIST_ROOT dataset = FASHION_MNIST(root=args.dataset_root,folder='train', transform=transforms.ToTensor()) net = build_fnn(phase='train',hidden_size=args.hidden_size) if args.cuda and torch.cuda.is_available(): net = torch.nn.DataParallel(net) cudnn.benchmark = True net.cuda() optimizer = optim.Adam(net.parameters(), lr=args.lr) criterion = nn.CrossEntropyLoss() epoch_size = args.epoch_size print('Loading the dataset...') data_loader = torch.utils.data.DataLoader(dataset, args.batch_size, num_workers=args.num_workers, shuffle=True, pin_memory=True) print('Training FFN on:', dataset.name) print('Using the specified args:') print(args) loss_list = [] acc_list = [] for epoch in range(epoch_size): net.train() train_loss = 0.0 correct = 0 total = len(dataset) t0 = time.perf_counter() for step, data in enumerate(data_loader, start=0): images, labels = data if args.cuda: images = Variable(images.view(-1,28*28).cuda()) labels = Variable(labels.cuda()) else: images = Variable(images.view(-1,28*28)) labels = Variable(labels) # forward outputs = net(images) # backprop optimizer.zero_grad() loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics train_loss += loss.item() _, predicted = outputs.max(1) correct += predicted.eq(labels).sum().item() # print train process rate = (step + 1) / len(data_loader) a = "*" * int(rate * 50) b = "." * int((1 - rate) * 50) print("\rEpoch {}: {:^3.0f}%[{}->{}]{:.3f}".format(epoch+1, int(rate * 100), a, b, loss), end="") print(' Running time: %.3f' % (time.perf_counter() - t0)) acc = 100.*correct/ total loss = train_loss / step print('train loss: %.6f, acc: %.3f%% (%d/%d)' % (loss, acc, correct, total)) loss_list.append(loss) acc_list.append(acc/100) torch.save(net.state_dict(),args.save_folder + '' + args.dataset + '.pth') plt.plot(range(epoch_size), loss_list, range(epoch_size), acc_list) plt.xlabel('Epoches') plt.ylabel('Sparse CrossEntropy Loss | Accuracy') plt.savefig(os.path.join( os.path.dirname( os.path.abspath(__file__)), "photos", args.dataset + "_train_details.png")) if __name__ == '__main__': train()
程序输入参数说明
- dataset:
训练采用的数据集,目前提供MNIST ,FASHION_MNIST供选择。 点击查看数据集加载Demo
- dataset_root:
数据集读取地址, default已设置为数据集相对路径,部署在云端可能需要修改
- hidden_size:
FFN网络隐藏层个数, default为500层
- batch_size:
单次训练所抓取的数据样本数量,default为32,MNIST数据集推荐参考为128
- num_workers:
加载数据所使用线程个数,default为0,n\in (2,4,8,12\dots)n∈(2,4,8,12…)
- epoch_size:
训练次数, default为30
- cuda:
是否调用GPU训练
- lr:
超参数学习率,FNN采用Adam优化函数,default为 0.0010.001
- save_folder:
模型权重保存地址
程序输出文件说明
- 训练细节
print 于 python console, 包括单个epoch训练时间、训练集损失值、准确率
- 模型权重
模型保存路径为 ./weight/%.pth
- 损失函数与正确率
图片保存路径为 ./photos/%_train_details.png
5.2 模型测试代码
加载同级目录下 test.py 程序代码
# %load test.py import sys import os os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" import argparse import torch import torch.nn as nn import torch.backends.cudnn as cudnn import torchvision.transforms as transforms from torch.autograd import Variable import itertools import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt mpl.rc('axes', labelsize = 14) mpl.rc('xtick', labelsize = 12) mpl.rc('ytick', labelsize = 12) sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))) from ffn import build_fnn from datasets.MNIST.mnist import MNIST_ROOT,MNIST from datasets.FASHION_MNIST.fashion_mnist import FASHION_MNIST_ROOT,FASHION_MNIST parser = argparse.ArgumentParser( description='FeedForward Neural Network Testing With Pytorch') parser.add_argument('--dataset', default='MNIST', choices=['MNIST', 'FASHION_MNIST'], type=str, help='MNIST or FASHION_MNIST') parser.add_argument('--dataset_root', default=MNIST_ROOT, help='Location of MNIST root directory') parser.add_argument('--hidden_size', default=500, type=int, help='Hidden layer size') parser.add_argument('--batch_size', default=32, type=int, help='Batch size for training') parser.add_argument('--num_workers', default=0, type=int, help='Number of workers used in dataloading') parser.add_argument('--trained_model', default='weights/{}.pth', type=str, help='Trained state_dict file path to open') parser.add_argument('--cuda', default=True, type=bool, help='Use cuda to train model') parser.add_argument('-f', default=None, type=str, help="Dummy arg so we can load in Jupyter Notebooks") args = parser.parse_args() args.trained_model = args.trained_model.format(args.dataset) def confusion_matrix(preds, labels, conf_matrix): for p, t in zip(preds, labels): conf_matrix[p, t] += 1 return conf_matrix def save_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cmap=plt.cm.Blues): plt.imshow(cm, interpolation='nearest', cmap=cmap) plt.title(title) plt.colorbar() tick_marks = np.arange(len(classes)) plt.xticks(tick_marks, classes, rotation=90) plt.yticks(tick_marks, classes) plt.axis("equal") ax = plt.gca() left, right = plt.xlim() ax.spines['left'].set_position(('data', left)) ax.spines['right'].set_position(('data', right)) for edge_i in ['top', 'bottom', 'right', 'left']: ax.spines[edge_i].set_edgecolor("white") thresh = cm.max() / 2. for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])): num = '{:.2f}'.format(cm[i, j]) if normalize else int(cm[i, j]) plt.text(j, i, num, verticalalignment='center', horizontalalignment="center", color="white" if num > thresh else "black") plt.ylabel('True label') plt.xlabel('Predicted label') plt.savefig(os.path.join( os.path.dirname( os.path.abspath(__file__)), "photos", args.dataset + "_confusion_matrix.png")) def test(): # load data if args.dataset == 'MNIST': if args.dataset_root == MNIST_ROOT: if not os.path.exists(MNIST_ROOT): parser.error('Must specify dataset_root if specifying dataset') args.dataset_root = MNIST_ROOT dataset = MNIST(root=args.dataset_root,folder='test', transform=transforms.ToTensor()) elif args.dataset == 'FASHION_MNIST': if args.dataset_root == MNIST_ROOT: print("Using default FASHION_MNIST dataset_root") args.dataset_root = FASHION_MNIST_ROOT dataset = FASHION_MNIST(root=args.dataset_root,folder='test', transform=transforms.ToTensor()) data_loader = torch.utils.data.DataLoader(dataset, args.batch_size, num_workers=args.num_workers, shuffle=True, pin_memory=True) # load net net = build_fnn(phase='test',hidden_size=args.hidden_size) if args.cuda and torch.cuda.is_available(): net = torch.nn.DataParallel(net) cudnn.benchmark = True net.cuda() net.load_state_dict(torch.load(args.trained_model)) print('Finish loading model: ', args.trained_model) net.eval() print('Training FFN on:', dataset.name) print('Using the specified args:') print(args) # evaluation criterion = nn.CrossEntropyLoss() test_loss = 0 correct = 0 total = 0 conf_matrix = torch.zeros(10, 10) class_correct = list(0 for i in range(10)) class_total = list(0 for i in range(10)) with torch.no_grad(): for step, data in enumerate(data_loader): images, labels = data if args.cuda: images = Variable(images.view(-1,28*28).cuda()) labels = Variable(labels.cuda()) else: images = Variable(images.view(-1,28*28)) labels = Variable(labels) # forward outputs = net(images) loss = criterion(outputs, labels) test_loss += loss.item() _, predicted = outputs.max(1) conf_matrix = confusion_matrix(predicted, labels=labels, conf_matrix=conf_matrix) total += labels.size(0) correct += predicted.eq(labels).sum().item() c = (predicted.eq(labels)).squeeze() for i in range(c.size(0)): label = labels[i] class_correct[label] += c[i].item() class_total[label] += 1 acc = 100.* correct / total loss = test_loss / step print('test loss: %.6f, acc: %.3f%% (%d/%d)' % (loss, acc, correct, total)) for i in range(10): print('accuracy of %s : %.3f%% (%d/%d)' % ( str(dataset.classes[i]), 100 * class_correct[i] / class_total[i], class_correct[i], class_total[i])) save_confusion_matrix(conf_matrix.numpy(), classes=dataset.classes, normalize=False, title = 'Normalized confusion matrix') if __name__ == '__main__': test()
程序输入参数说明
- dataset:
训练采用的数据集,目前提供 MNIST, FASHION_MNIST 供选择。 点击查看数据集加载Demo
- dataset_root:
数据集读取地址, default已设置为数据集相对路径,部署在云端可能需要修改
- hidden_size:
FFN网络隐藏层个数, default为500层
- batch_size:
单次训练所抓取的数据样本数量,default为32,MNIST数据集推荐参考为128
- num_workers:
加载数据所使用线程个数,default为0,n\in (2,4,8,12\dots)n∈(2,4,8,12…)
- trained_model:
模型权重保存路径,default为 train.py 生成的ptb文件路径
- cuda:
是否调用GPU训练
程序输出文件说明
- 测试集损失值与准确率
print 于 python console 第一行
- 各类别准确率
print 于 python console 后续列表
- 混淆矩阵
图片保存路径为 ./photos/%_confusion_matrix.png
5.3 MNIST数据集
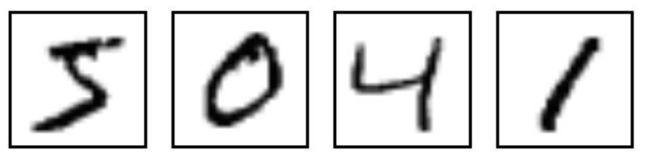
-
MNIST 来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员,测试集(test set) 也是同样比例的手写数字数据
-
MNIST 是机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张 28\times2828×28 像素的灰度手写数字图片
-
MNIST 已经是一个被”嚼烂”了的数据集, 作为机器学习在视觉领域的hello world,很多教程都会对它”下手”, 几乎成为一个 “典范”
%run train.py --batch_size=128 --epoch_size=20
Loading the dataset...
Training FFN on: MNIST
Using the specified args:
Namespace(batch_size=128, cuda=True, dataset='MNIST', dataset_root='C:\\Users\\sbzy\\Documents\\GitHub\\dl_algorithm\\datasets\\MNIST', epoch_size=20, hidden_size=500, lr=0.001, num_workers=0, save_folder='weights/')
Epoch 1: 4 %[**->...............................................]0.645
C:\ProgramData\Anaconda3\lib\site-packages\torchvision\transforms\functional.py:114: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at ..\torch\csrc\utils\tensor_numpy.cpp:180.)
img = torch.from_numpy(pic.transpose((2, 0, 1))).contiguous()
Epoch 1: 100%[**************************************************->]0.172 Running time: 1.920
train loss: 0.316545, acc: 91.398% (54839/60000)
Epoch 2: 100%[**************************************************->]0.172 Running time: 1.788
train loss: 0.130430, acc: 96.182% (57709/60000)
Epoch 3: 100%[**************************************************->]0.029 Running time: 1.792
train loss: 0.085377, acc: 97.525% (58515/60000)
Epoch 4: 100%[**************************************************->]0.088 Running time: 1.850
train loss: 0.061032, acc: 98.232% (58939/60000)
Epoch 5: 100%[**************************************************->]0.030 Running time: 1.795
train loss: 0.045669, acc: 98.642% (59185/60000)
Epoch 6: 100%[**************************************************->]0.030 Running time: 1.781
train loss: 0.034931, acc: 98.985% (59391/60000)
Epoch 7: 100%[**************************************************->]0.027 Running time: 1.801
train loss: 0.025758, acc: 99.290% (59574/60000)
Epoch 8: 100%[**************************************************->]0.015 Running time: 1.833
train loss: 0.021855, acc: 99.400% (59640/60000)
Epoch 9: 100%[**************************************************->]0.021 Running time: 1.808
train loss: 0.016011, acc: 99.578% (59747/60000)
Epoch 10: 100%[**************************************************->]0.004 Running time: 1.855
train loss: 0.012006, acc: 99.705% (59823/60000)
Epoch 11: 100%[**************************************************->]0.008 Running time: 1.797
train loss: 0.009323, acc: 99.798% (59879/60000)
Epoch 12: 100%[**************************************************->]0.027 Running time: 1.792
train loss: 0.008455, acc: 99.772% (59863/60000)
Epoch 13: 100%[**************************************************->]0.004 Running time: 1.801
train loss: 0.005930, acc: 99.888% (59933/60000)
Epoch 14: 100%[**************************************************->]0.001 Running time: 1.847
train loss: 0.007958, acc: 99.775% (59865/60000)
Epoch 15: 100%[**************************************************->]0.014 Running time: 1.815
train loss: 0.005799, acc: 99.858% (59915/60000)
Epoch 16: 100%[**************************************************->]0.002 Running time: 1.836
train loss: 0.004902, acc: 99.892% (59935/60000)
Epoch 17: 100%[**************************************************->]0.002 Running time: 1.827
train loss: 0.004979, acc: 99.875% (59925/60000)
Epoch 18: 100%[**************************************************->]0.001 Running time: 1.813
train loss: 0.004698, acc: 99.868% (59921/60000)
Epoch 19: 100%[**************************************************->]0.000 Running time: 1.812
train loss: 0.001051, acc: 99.995% (59997/60000)
Epoch 20: 100%[**************************************************->]0.000 Running time: 1.846
train loss: 0.000483, acc: 100.000% (60000/60000)
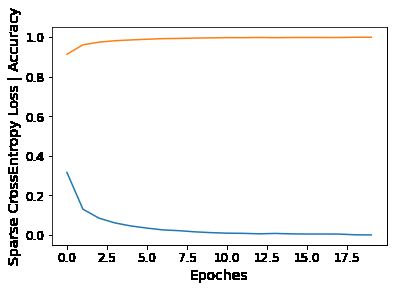
%run test.py --batch_size=128
Finish loading model: weights/MNIST.pth
Training FFN on: MNIST
Using the specified args:
Namespace(batch_size=128, cuda=True, dataset='MNIST', dataset_root='C:\\Users\\sbzy\\Documents\\GitHub\\dl_algorithm\\datasets\\MNIST', f=None, hidden_size=500, num_workers=0, trained_model='weights/MNIST.pth')
test loss: 0.071845, acc: 98.290% (9829/10000)
accuracy of 0 : 99.082% (971/980)
accuracy of 1 : 99.295% (1127/1135)
accuracy of 2 : 98.256% (1014/1032)
accuracy of 3 : 98.812% (998/1010)
accuracy of 4 : 98.982% (972/982)
accuracy of 5 : 97.870% (873/892)
accuracy of 6 : 98.539% (944/958)
accuracy of 7 : 97.471% (1002/1028)
accuracy of 8 : 97.536% (950/974)
accuracy of 9 : 96.928% (978/1009)

5.4 FASHION-MNIST数据集

-
Fashion-MNIST 的大小、格式和训练集/测试集划分与原始的 MNIST 完全一致。60000/10000 的训练测试数据划分,28\times2828×28 的灰度图片。
-
Fashion-MNIST 的目的是要成为 MNIST 数据集的一个直接替代品。MNIST 太简单了,只需要一个像素就可以区分开,很多算法在测试集上的性能已经达到 99.6%。MNIST 数字识别的任务不代表现代机器学习。Fashion-MNIST 迁移到真正的机器视觉图像分类问题。
%run train.py --dataset=FASHION_MNIST --batch_size=128 --epoch_size=30
Using default FASHION_MNIST dataset_root
Loading the dataset...
Training FFN on: FASHION_MNIST
Using the specified args:
Namespace(batch_size=128, cuda=True, dataset='FASHION_MNIST', dataset_root='C:\\Users\\sbzy\\Documents\\GitHub\\dl_algorithm\\datasets\\FASHION_MNIST', epoch_size=30, hidden_size=500, lr=0.001, num_workers=0, save_folder='weights/')
Epoch 1: 100%[**************************************************->]0.460 Running time: 1.878
train loss: 0.531764, acc: 81.763% (49058/60000)
Epoch 2: 100%[**************************************************->]0.402 Running time: 1.815
train loss: 0.385030, acc: 86.283% (51770/60000)
Epoch 3: 100%[**************************************************->]0.324 Running time: 1.800
train loss: 0.340654, acc: 87.810% (52686/60000)
Epoch 4: 100%[**************************************************->]0.256 Running time: 1.817
train loss: 0.318387, acc: 88.392% (53035/60000)
Epoch 5: 100%[**************************************************->]0.303 Running time: 1.814
train loss: 0.296618, acc: 89.220% (53532/60000)
Epoch 6: 100%[**************************************************->]0.401 Running time: 1.870
train loss: 0.281099, acc: 89.665% (53799/60000)
Epoch 7: 100%[**************************************************->]0.265 Running time: 1.899
train loss: 0.267958, acc: 90.108% (54065/60000)
Epoch 8: 100%[**************************************************->]0.286 Running time: 1.811
train loss: 0.254263, acc: 90.638% (54383/60000)
Epoch 9: 100%[**************************************************->]0.238 Running time: 1.833
train loss: 0.243190, acc: 91.043% (54626/60000)
Epoch 10: 100%[**************************************************->]0.223 Running time: 1.852
train loss: 0.234547, acc: 91.215% (54729/60000)
Epoch 11: 100%[**************************************************->]0.229 Running time: 1.891
train loss: 0.225576, acc: 91.625% (54975/60000)
Epoch 12: 100%[**************************************************->]0.153 Running time: 1.836
train loss: 0.216060, acc: 91.892% (55135/60000)
Epoch 13: 100%[**************************************************->]0.251 Running time: 1.842
train loss: 0.209209, acc: 92.213% (55328/60000)
Epoch 14: 100%[**************************************************->]0.161 Running time: 1.828
train loss: 0.202756, acc: 92.543% (55526/60000)
Epoch 15: 100%[**************************************************->]0.159 Running time: 1.888
train loss: 0.193430, acc: 92.903% (55742/60000)
Epoch 16: 100%[**************************************************->]0.314 Running time: 1.808
train loss: 0.186699, acc: 93.060% (55836/60000)
Epoch 17: 100%[**************************************************->]0.230 Running time: 1.822
train loss: 0.179851, acc: 93.273% (55964/60000)
Epoch 18: 100%[**************************************************->]0.178 Running time: 1.882
train loss: 0.172105, acc: 93.582% (56149/60000)
Epoch 19: 100%[**************************************************->]0.083 Running time: 1.871
train loss: 0.167652, acc: 93.803% (56282/60000)
Epoch 20: 100%[**************************************************->]0.126 Running time: 1.847
train loss: 0.161755, acc: 94.037% (56422/60000)
Epoch 21: 100%[**************************************************->]0.199 Running time: 1.849
train loss: 0.159146, acc: 94.033% (56420/60000)
Epoch 22: 100%[**************************************************->]0.112 Running time: 1.830
train loss: 0.151899, acc: 94.535% (56721/60000)
Epoch 23: 100%[**************************************************->]0.190 Running time: 1.900
train loss: 0.147988, acc: 94.450% (56670/60000)
Epoch 24: 100%[**************************************************->]0.161 Running time: 1.884
train loss: 0.147933, acc: 94.493% (56696/60000)
Epoch 25: 100%[**************************************************->]0.108 Running time: 1.845
train loss: 0.137695, acc: 94.892% (56935/60000)
Epoch 26: 100%[**************************************************->]0.150 Running time: 1.842
train loss: 0.133490, acc: 95.072% (57043/60000)
Epoch 27: 100%[**************************************************->]0.140 Running time: 1.871
train loss: 0.129848, acc: 95.162% (57097/60000)
Epoch 28: 100%[**************************************************->]0.093 Running time: 1.853
train loss: 0.125107, acc: 95.365% (57219/60000)
Epoch 29: 100%[**************************************************->]0.101 Running time: 1.843
train loss: 0.121888, acc: 95.508% (57305/60000)
Epoch 30: 100%[**************************************************->]0.139 Running time: 1.855
train loss: 0.118569, acc: 95.640% (57384/60000)
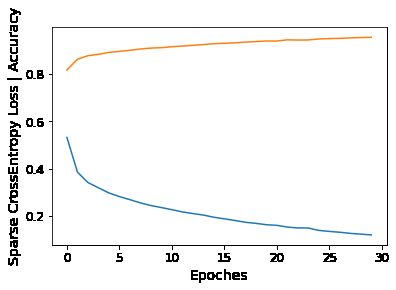
%run test.py --dataset=FASHION_MNIST --batch_size=128
Using default FASHION_MNIST dataset_root
Finish loading model: weights/FASHION_MNIST.pth
Training FFN on: FASHION_MNIST
Using the specified args:
Namespace(batch_size=128, cuda=True, dataset='FASHION_MNIST', dataset_root='C:\\Users\\sbzy\\Documents\\GitHub\\dl_algorithm\\datasets\\FASHION_MNIST', f=None, hidden_size=500, num_workers=0, trained_model='weights/FASHION_MNIST.pth')
test loss: 0.358458, acc: 89.370% (8937/10000)
accuracy of T-shirt/top : 88.100% (881/1000)
accuracy of Trouser : 97.900% (979/1000)
accuracy of Pullover : 81.200% (812/1000)
accuracy of Dress : 91.700% (917/1000)
accuracy of Coat : 77.800% (778/1000)
accuracy of Sandal : 97.500% (975/1000)
accuracy of Shirt : 70.700% (707/1000)
accuracy of Sneaker : 97.500% (975/1000)
accuracy of Bag : 96.800% (968/1000)
accuracy of Ankle boot : 94.500% (945/1000)
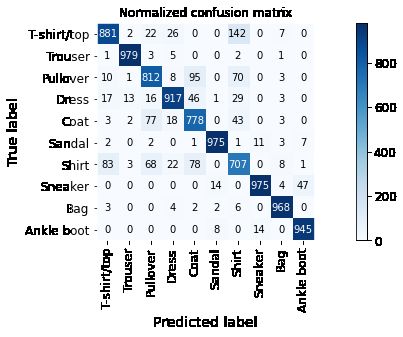
5.5 结果评估
Shirt、T-shirt、Dress、Coat同为上衣,从混淆矩阵中可知,FFN模型难以辨别相似度高的类群。
作为初代深层学习网络,FFN,或称为MLP,在80年代的时候曾是相当流行的机器学习方法,拥有广泛的应用场景,譬如语音识别、图像识别、机器翻译,但受限于电子技术与硬件束缚,难以处理复杂多样的分类任务。
前馈神经网络模型优点
- 最基础的深度学习网络,克服了感知器不能对线性不可分数据进行识别的弱点
- 高度的并行处理、非线性全局作用
- 非常强的自适应、自学习功能,简单的模型结构就能达到89%准确率
前馈神经网络模型缺点
- 依赖全连接层导致无法处理大尺寸的图片输入
- 容易过拟合,随着数据集复杂化,细粒度分类任务欠佳
- 网络的隐藏层数、学习率选取非常难,遇到更为简单的SVM的强劲竞争
开始实验