检测网络框架越来越多
搬运工又来了 之前也发过相关 在汇总说一下啊~~ yolo也不在孤单了~~ 出了一大堆了~~
之前都一一发过 今天在来个大汇总
目标检测是现在最热门的研究课题,也一直是工业界重点研究的对象,最近几年内,也出现了各种各样的检测框架,所属于YOLO系列是最经典也是目前被大家认可使用的检测框架。
由于现在越来越多的需求迁移到边缘端,所以对轻量级网络的要求越来越重,那我们先和大家介绍Yolo-Fastest框架。
链接:Yolo-Fastest:轻量级yolo系列网络在各硬件实现工业级检测效果
模型非常小、目前最快的YOLO算法——大小只有1.4MB,单核每秒148帧,在一些移动设备上部署特别容易。具体测试效果如下:
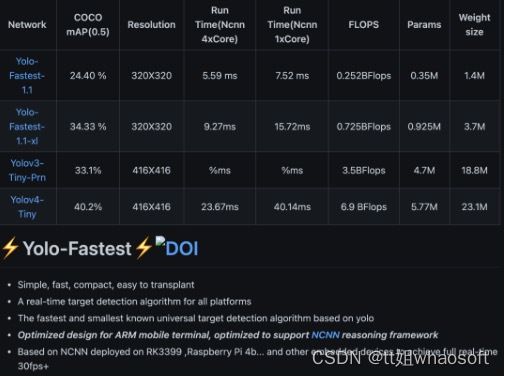
Yolo-Fastest开源代码:https://github.com/dog-qiuqiu/Yolo-Fastest
最近“计算机视觉研究院”也分享了一个视频中,利用Yolo框架进行实时目标检测:
论文地址: https://arxiv.org/pdf/2208.09686.pdf
代码地址: https://github.com/YuHengsss/YOLOV
链接:YoloV:视频中目标实时检测依然很棒(附源代码下载)
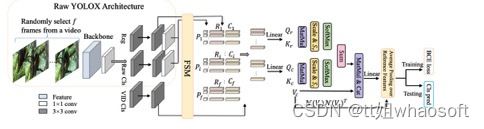
由于两阶段的性质,此类检测器通常在计算上很耗时。今天分享的研究者提出了一种简单而有效的策略来解决上述问题,该策略花费了边际开销,并显著提高了准确性。具体来说,与传统的两阶段流水线不同,研究者主张将区域级候选放在一阶段检测之后,以避免处理大量低质量候选。此外,构建了一个新的模块来评估目标框架与其参考框架之间的关系,并指导聚合。
前段时间最火的应该就是Yolov7,其实我们不久前推送了Yolov6以及打假Yolov7框架的吹嘘:
论文地址:https://arxiv.org/pdf/2207.02696.pdf
代码地址:https://github.com/WongKinYiu/yolov7
链接:Yolov7:最新最快的实时检测框架,最详细分析解释(附源代码)
7月份又出来一个Yolov7,在5 FPS到160 FPS范围内的速度和精度达到了新的高度,并在GPU V100上具有30 FPS或更高的所有已知实时目标检测器中具有最高的精度56.8%AP。YOLOv7-E6目标检测器(56 FPS V100,55.9% AP)比基于Transform的检测器SWINL Cascade-Mask R-CNN(9.2 FPS A100,53.9% AP)的速度和准确度分别高出509%和2%,以及基于卷积的检测器ConvNeXt-XL Cascade-Mask R-CNN (8.6 FPS A100, 55.2% AP) 速度提高551%,准确率提高0.7%。
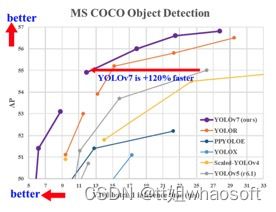
以及YOLOv7的表现优于:YOLOR、YOLOX、Scaled-YOLOv4、YOLOv5、DETR、Deformable DETR , DINO-5scale-R50, ViT-Adapter-B和许多其他目标检测器在速度和准确度上。
Yolov7的打假简介如下:
-
eval的时候NMS是有trick的,multi_label表示一个框是否可以赋予两个类别,但是我们实际部署的时候就是一个框对应一个类别,所以再把multi_label设为False

测试结果好像又掉了0.2....

这种YOLO系列测速都是没有比对nms的耗时的,所以为了精度可以对nms大作文章。进nms前的max_nm设置到了30000,实际部署的时候,进入nms的Tensor如果很大会很耗时,一般都不会设置到这么大,1000足够了,改max_nms=1000。同时还有max_det=300表示每张图最多几个框,真的有必要300这么多吗? cocoapi评测工具虽然是max_det=100,但是改300真的也会涨点。

max_nms=30000,max_det=300这种操作不仅eval过程变慢,生成json的时候更慢,而且如果是训练早期还没训的很好的时候去eval,肯定会很慢。
具体详细内容见:打假Yolov7的精度,不是所有的论文都是真实可信
今年比较火的应该不能缺少Transform吧,“计算机视觉研究院”也陆陆续续给大家分享了:
论文地址:https://arxiv.org/pdf/2102.12122.pdf
源代码地址:https://github.com/whai362/PVT
链接:无卷积骨干网络:金字塔Transformer,提升目标检测/分割等任务精度(附源代码)
与最近提出的专为图像分类设计的Vision Transformer(ViT)不同,研究者引入了Pyramid Vision Transformer(PVT),它克服了将Transformer移植到各种密集预测任务的困难。与当前的技术状态相比,PVT 有几个优点:
-
与通常产生低分辨率输出并导致高计算和内存成本的ViT不同,PVT不仅可以在图像的密集分区上进行训练以获得对密集预测很重要的高输出分辨率,而且还使用渐进式收缩金字塔以减少大型特征图的计算;
-
PVT继承了CNN和Transformer的优点,使其成为各种视觉任务的统一主干,无需卷积,可以直接替代CNN主干;
-
通过大量实验验证了PVT,表明它提高了许多下游任务的性能,包括对象检测、实例和语义分割。
还有Transformer 之前文章去看把 不重复发了
whaosoft aiot http://143ai.com
-
论文地址:https://arxiv.org/pdf/2111.05297.pdf
-
代码和模型:https://github.com/szq0214/SReT