深度学习笔记(四)——循环神经网络(Recurrent Neural Network, RNN)
目录
一、RNN简介
(一)、简介
(二)、RNN处理任务示例——以NER为例
二、模型提出
(一)、基本RNN结构
(二)、RNN展开结构
三、RNN的结构变化
(一)、N to N结构RNN模型
(二)、N to 1结构RNN模型
(三)、1 to N结构RNN模型
(四)、N to M结构RNN模型(encoder-decoder模型、seq2seq模型)
四、梯度消失及梯度爆炸
(一)、什么是RNN的梯度爆炸和梯度消失
(二)、如何解决RNN的梯度爆炸或梯度消失
一、RNN简介
(一)、简介
循环神经网络(Recurrent Neural Network, RNN),指的是一类以序列数据为输入的神经网络模型。与经典的前馈网络不同之处在于,RNN模型处理序列数据能够获取到更多的语义信息、时序信息等。通常,序列数据指的是一条数据内部的元素有顺序关系的数据,如文本、如文章、语句;时序数据,如一周的天气、三个月的股市指数等。通常可用于语音识别、语言模型、机器翻译及时序分析等。
(二)、RNN处理任务示例——以NER为例
NER(Named Entity Recognize,命名实体识别)任务,表示从自然语言文本中,识别出表示真实世界实体的实体名及其类别,如:
句子(1): I like eating apple! 中的 apple 指的是 苹果(食物)
句子(2): The Apple is a great company! 中的 Apple 指的是 苹果(公司)
一般的DNN网络中,输入方式为逐元素输入,即句子内的词单独独立地输入模型进行处理,这将导致上下文信息丢失,这样的结果会导致每个词的输入仅会输出单一结果,与上下文语义无关。如上图示例,若训练集中的苹果一词大部分标记为苹果(食物),则测试阶段所有的苹果也将标记为食物;反之则测试阶段将都标记为公司。
二、模型提出
(一)、基本RNN结构
为了解决普通DNN无法有效获取上下文信息的缺点,RNN最基本的改良点在于增加一个“模块”用于存储上下文信息。以下图(a)为一个典型RNN的结构示意图:

图(a)是一个典型的RNN结构图,初看可能会不太理解。理解首先不看右侧的矩阵![]() ,只看左侧的顺序网络,即图(b),表示的就是一个普通的前馈神经网络。 接下来回头看图(a),RNN相比于一般前馈网络,增加了一个保存上下文信息的权重矩阵
,只看左侧的顺序网络,即图(b),表示的就是一个普通的前馈神经网络。 接下来回头看图(a),RNN相比于一般前馈网络,增加了一个保存上下文信息的权重矩阵![]() ,也即每次计算输出不仅要考虑当前输入数据,还要考虑序列数据的上下文信息。
,也即每次计算输出不仅要考虑当前输入数据,还要考虑序列数据的上下文信息。
(二)、RNN展开结构
我们知道了RNN模型增加了一个权重矩阵![]() 用于存储输入序列的上下文信息,接下来我们来介绍RNN结构如何进行模型计算以及上下文信息如何应用到RNN结构。为了更好地理解RNN计算方式,下图是一个序列展开的RNN示意图(即上图a的时序展开图):
用于存储输入序列的上下文信息,接下来我们来介绍RNN结构如何进行模型计算以及上下文信息如何应用到RNN结构。为了更好地理解RNN计算方式,下图是一个序列展开的RNN示意图(即上图a的时序展开图):

其中 表示
表示 时刻的模型输入,
时刻的模型输入, 表示对应的输入结果。RNN模型计算公式如下:
表示对应的输入结果。RNN模型计算公式如下:
![]()
由计算公式可以看出,隐藏层的输出隐变量 在RNN中既与当前时刻输入有关,又与上一时刻的隐变量
在RNN中既与当前时刻输入有关,又与上一时刻的隐变量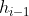 有关。因此可以认为包含了影响当前输入信息的“上下文”信息,而可学习的参数矩阵
有关。因此可以认为包含了影响当前输入信息的“上下文”信息,而可学习的参数矩阵 决定了上下文信息对当前影响程度。 值得注意的是,在整个模型处理期间,参数矩阵是使用的同一个矩阵。
决定了上下文信息对当前影响程度。 值得注意的是,在整个模型处理期间,参数矩阵是使用的同一个矩阵。
三、RNN的结构变化
根据输入长度与输出序列长度的不同,可以将RNN模型结构分为N to N,N to 1, 1 to N,及 N to M。
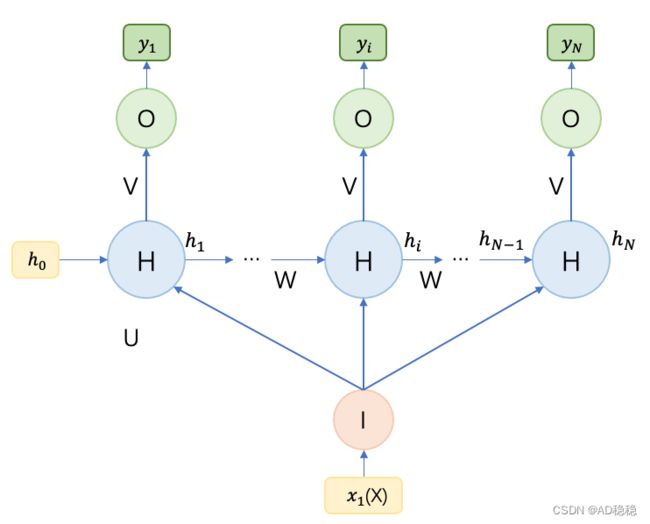
(一)、N to N结构RNN模型
第一种是常见的输入长度与输出长度相同的RNN结构,也就表示每一个输入数据都有对应的一个输出值,可以用于逐序列判断或分类任务,如序列标注、视频帧分类、NER及分词等任务。其结构图如下:
 , 计算:
, 计算:![]()
(二)、N to 1结构RNN模型
N to 1结构RNN,表示输入一个序列只生成一个输出值(通常用尾数据对应输出值)。其意义是序列的输出结果蕴含整条序列数据的语义信息及上下文信息。
 , 计算:
, 计算:![]()
N to 1结构RNN模型的常见应用:文字分类、文章分类及图像分类等任务。
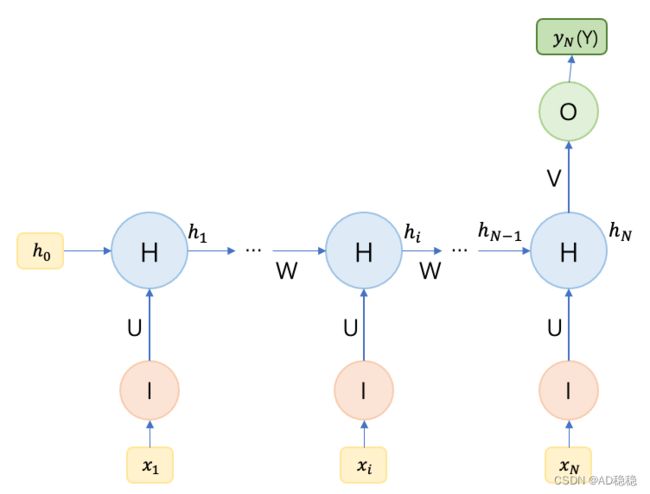
(三)、1 to N结构RNN模型
1 to N 结构RNN,表示一个输入数据对应输出一个序列的模型。其意义表示一个起始状态或者种子数据,生成一个序列的输出结果。

1 to N结构RNN模型根据输入只有一个向量,输入位置的不同,可以分为只在首个时刻输入(上左图)和在每个时刻均输入(上右图)两种结构。其中第一种结构计算方法如下:

类似地,第二种结构计算方法如下:
![]()
1 to N结构RNN模型的常见应用包括由图像生成文章,由类别生成音乐、文章及代码等,由种子数据生成序列的任务。
(四)、N to M结构RNN模型(encoder-decoder模型、seq2seq模型)
最后,是N to M结构RNN模型,即输入及输出序列不等长的结构。N和M分别为输入序列长度及输出序列长度,该结构我们采用一个N to 1结构RNN及一个1 to M结构组合来实现,详细结构如下图:

由上图可以看出,将两个不同长度的RNN进行组合,能够控制模型的输出序列长度。在两个模型之间,增加了一个上下文向量![]() ,由第一个RNN模型的输出计算得来,向量
,由第一个RNN模型的输出计算得来,向量![]() 包含着输入序列的语义信息与序列信息。在上图中是将上下文向量
包含着输入序列的语义信息与序列信息。在上图中是将上下文向量![]() 作为了第二个RNN模型的输入数据,并在第二个RNN模型对于初始隐藏变量
作为了第二个RNN模型的输入数据,并在第二个RNN模型对于初始隐藏变量![]() 进行随机初始化。通常将第一个RNN称为encoder(编码器),第二个RNN称为decoder(解码器)此外,还可以利用上下文向量
进行随机初始化。通常将第一个RNN称为encoder(编码器),第二个RNN称为decoder(解码器)此外,还可以利用上下文向量![]() 对第二个RNN模型的隐藏变量进行初始化,结构如下:
对第二个RNN模型的隐藏变量进行初始化,结构如下:
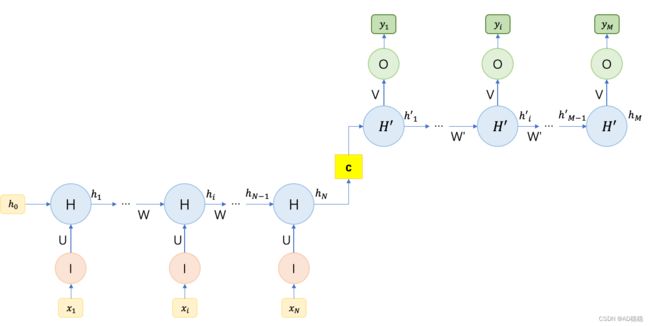
通过N to M结构RNN模型,可以适应各类序列处理任务,常见的如机器翻译、语音识别、文本摘要及阅读理解等任务。由于输入输出都是序列,该模型也称为seq2seq模型。常用的上下文向量![]() 的计算方法包含如下三种:
的计算方法包含如下三种:
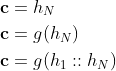
其中,第一种计算方法为直接将encoder的输出作为上下文向量![]() ;第二种计算方法为通过变化encoder的输出计算得到;第三种计算方法为利用一个encoder的输出序列计算得到。此外,由于encoder的输出只变换成 上下文向量
;第二种计算方法为通过变化encoder的输出计算得到;第三种计算方法为利用一个encoder的输出序列计算得到。此外,由于encoder的输出只变换成 上下文向量![]() 传入decoder进行了计算,难免造成decoder计算序列加长导致的上下文信息衰减。由此,人们引入了注意力机制(Attention)来增强数据信息,我们在attention机制部分进行详解。
传入decoder进行了计算,难免造成decoder计算序列加长导致的上下文信息衰减。由此,人们引入了注意力机制(Attention)来增强数据信息,我们在attention机制部分进行详解。
四、梯度消失及梯度爆炸
(一)、什么是RNN的梯度爆炸和梯度消失
由于RNN中的上下文参数矩阵是权重共享的,即当进行梯度更新时,对该矩阵求偏导数时需要加入时序影响,将导致存在基于时序数量的权重“连乘”。若某一阶段权重值过小,结合“连乘”将导致最终权重趋于“无穷小”(即等于0),此现象称为“梯度消失”。相反地,若权重值过大,经连乘后将导致权重值变得过大,称为“梯度爆炸”。
与普通NN的梯度消失及梯度爆炸不同,RNN的梯度爆炸(或消失)是根本原因是“连乘”,是在反向传播的某一阶段出现的,在此之前的反向传播不受影响。
(二)、如何解决RNN的梯度爆炸或梯度消失
1. 梯度爆炸的解决
1)梯度裁剪
梯度裁剪即为梯度更新时的梯度设置上限,当超过阈值将强制裁剪,避免出现过高阈值。
2. 梯度消失的解决
1)使用Relu激活函数
使用Relu激活函数解决梯度消失的原理是,Relu函数在自变量大于0是,因变量恒为1,由此避免梯度过小。
2)变更RNN结构
改用变种版本的RNN结构,常见的包括LSTM模型及GRU模型。将在后续文章介绍。