UnrealText: Synthesizing Realistic Scene Text Images from the Unreal World(译)
UnrealText:合成来自虚幻世界的真实场景文本图像
仅供参考,如翻译不到的请指出,侵权删
来源: CVPR2020,旷视
code 链接: https://jyouhou.github.io/UnrealText/.
原文下载链接: arXiv:2003.10608v1.
Abstract
Synthetic data has been a critical tool for training scene text detection and recognition models. On the one hand,synthetic word images have proven to be a successful substitute for real images in training scene text recognizers. On the other hand, however, scene text detectors still heavily rely on a large amount of manually annotated real-world images, which are expensive. In this paper, we introduce UnrealText, an efficient image synthesis method that renders realistic images via a 3D graphics engine. 3D synthetic engine provides realistic appearance by rendering scene and text as a whole, and allows for better text region proposals with access to precise scene information, e.g. normal and even object meshes. The comprehensive experiments verify its effectiveness on both scene text detection and recognition. We also generate a multilingual version for future research into multilingual scene text detection and recognition. The code and the generated datasets are released at: https://jyouhou.github.io/UnrealText/.
摘要:
合成数据已经成为训练场景文本检测和识别模型的关键工具。一方面,在训练场景文本识别器中,合成词图像已被证明是真实图像的成功替代品。但是,另一方面,场景文本检测器仍然严重依赖大量手动注释的真实世界图像,这很昂贵。在本文中,我们介绍了UnrealText,这是一种有效的图像合成方法,可通过3D图形引擎渲染逼真的图像。3D合成引擎通过整体渲染场景和文本来提供逼真的外观,并允许通过访问精确的场景信息(例如法线甚至对象网格)获得更好的文本区域建议。综合实验验证了其在场景文本检测和识别方面的有效性。我们还将生成多语言版本,以供将来对多语言场景文本检测和识别进行研究
1 引言:
With the resurgence of neural networks, the past few years have witnessed significant progress in the field of scene text detection and recognition. However, these models are data-thirsty, and it is expensive and sometimes difficult, if not impossible, to collect enough data. Moreover, the various applications, from traffic sign reading in autonomous vehicles to instant translation, require a large amount of data specifically for each domain, further escalating this issue. Therefore, synthetic data and synthesis algorithms are important for scene text tasks. Furthermore, synthetic data can provide detailed annotations, such as character-level or even pixel-level ground truths that are rare for real images due to high cost.
随着神经网络的兴起,过去几年见证了场景文本检测和识别领域的重大进步。 但是,这些模型需要数据,并且价格昂贵,有时甚至很难收集足够的数据。 此外,从自动驾驶汽车的交通标志读取到即时翻译的各种应用都需要针对每个域的大量数据,从而进一步加剧了这一问题。 因此,合成数据和合成算法对于场景文本任务很重要。 此外,合成数据可以提供详细的注释,例如字符级甚至像素级的基本事实,由于成本高昂,因此对于真实图像而言是罕见的。
Currently, there exist several synthesis algorithms [45,10, 6, 49] that have proven beneficial. Especially, in scene text recognition, training on synthetic data [10, 6] alone has become a widely accepted standard practice. Some researchers that attempt training on both synthetic and real data only report marginal improvements [15, 19] on most datasets. Mixing synthetic and real data is only improving performance on a few difficult cases that are not yet well covered by existing synthetic datasets, such as seriously blurred or curved text. This is reasonable, since cropped text images have much simpler background, and synthetic data enjoys advantages in larger vocabulary size and diversity of backgrounds, fonts, and lighting conditions, as well as thousands of times more data samples.
当前,存在几种已证明是有益的合成算法[45,10,6,49]。 特别是在场景文本识别中,仅对合成数据进行训练[10,6]已成为一种广泛接受的标准做法。 一些尝试对合成数据和真实数据进行训练的研究人员仅报告了大多数数据集的边际改进[15,19]。 混合合成数据和真实数据只会提高在某些难以被现有合成数据集覆盖的困难情况下的性能,例如严重模糊或弯曲的文本。 这是合理的,因为裁剪后的文本图像的背景要简单得多,并且合成数据在较大的词汇量和背景,字体和光照条件的多样性方面具有优势,并且数据样本的数量要多数千倍。
On the contrary, however, scene text detection is still heavily dependent on real-world data. Synthetic data [6, 49] plays a less significant role, and only brings marginal improvements. Existing synthesizers for scene text detection follow the same paradigm. First, they analyze background images, e.g. by performing semantic segmentation and depth estimation using off-the-shelf models. Then, potential locations for text embedding are extracted from the segmented regions. Finally, text images (foregrounds) are blended into the background images, with perceptive transformation inferred from estimated depth. However, the analysis of background images with off-the-shelf models may be rough and imprecise. The errors further propagate to text proposal modules and result in text being embedded onto unsuitable locations. Moreover, the text embedding process is ignorant of the overall image conditions such as illumination and occlusions of the scene. These two factors make text instances outstanding from backgrounds, leading to a gap between synthetic and real images.
相反,场景文本检测仍然在很大程度上依赖于实际数据。综合数据[6,49]的作用不那么重要,仅带来了很小的改善。现有的用于场景文本检测的合成器遵循相同的范例。首先,他们分析背景图片,例如通过使用现成的模型执行语义分割和深度估计。然后,从分割的区域中提取潜在的文本嵌入位置。最后,将文本图像(前景)混合到背景图像中,并根据估计的深度推断出感知变换。但是,使用现成的模型对背景图像进行分析可能是粗略且不准确的。错误进一步传播到文本建议模块,并导致文本被嵌入到不合适的位置。而且,文本嵌入过程不了解整个图像条件,例如场景的照明和遮挡。这两个因素使文本实例的背景突出,从而导致合成图像和真实图像之间的差距。
In this paper, we propose a synthetic engine that syn thesizes scene text images from 3D virtual world. The proposed engine is based on the famous Unreal Engine 4(UE4), and is therefore named as UnrealText. Specifically, text instances are regarded as planar polygon meshes with text foregrounds loaded as texture. These meshes are placed in suitable positions in 3D world, and rendered together with the scene as a whole
在本文中,我们提出了一种合成引擎,用于合成3D虚拟世界中场景文本图像的大小。 提出的引擎基于著名的虚幻引擎4(UE4),因此被命名为UnrealText。 具体来说,将文本实例视为平面多边形网格,并将文本前景加载为纹理。 将这些网格放置在3D世界中的适当位置,并与整个场景一起渲染。

As shown in Fig. 1, the proposed synthesis engine, by its very nature, enjoys the following advantages over previous methods: (1) Text and scenes are rendered together, achieving realistic visual effects, e.g. illumination, occlusion, and perspective transformation. (2) The method has access to precise scene information, e.g. normal, depth, and object meshes, and therefore can generate better text region proposals. These aspects are crucial in training detectors
如图1所示,所提出的合成引擎就其本质而言,与以前的方法相比具有以下优点:(1)文本和场景一起呈现,实现了逼真的视觉效果,例如 照明,遮挡和透视变换。 (2)该方法可以访问精确的场景信息,例如 法线,深度和对象网格,因此可以生成更好的文本区域建议。 这些方面对于训练探测器至关重要。
To further exploit the potential of UnrealText, we design three key components: (1) A view finding algorithm that explores the virtual scenes and generates camera viewpoints to obtain more diverse and natural backgrounds. (2) An environment randomization module that changes the lighting conditions regularly, to simulate real-world variations. (3) A mesh-based text region generation method that finds suitable positions for text by probing the 3D meshes.
为了进一步利用UnrealText的潜力,我们设计了三个关键组件:(1)一种探视图算法,该算法探索虚拟场景并生成相机视点以获得更多样化和自然的背景。 (2)环境随机化模块,可定期更改照明条件,以模拟现实世界的变化。 (3)一种基于网格的文本区域生成方法,该方法通过探测3D网格为文本找到合适的位置。
The contributions of this paper are summarized as follows: (1) We propose a brand-new scene text image synthesis engine that renders images from 3D world, which is entirely different from previous approaches that embed text on 2D background images, termed as UnrealText. The proposed engine achieves realistic rendering effects and high scalability. (2) With the proposed techniques, the synthesis engine improves the performance of detectors and reognizers significantly. (3) We also generate a large scale multilingual scene text dataset that will aid further research
本文的贡献概括如下:(1)我们提出了一种全新的场景文本图像合成引擎,该引擎可渲染3D世界中的图像,这与之前将文本嵌入2D背景图像的方法完全不同,称为 UnrealText。 所提出的引擎实现了逼真的渲染效果和高可伸缩性。 (2)利用提出的技术,综合引擎可显着提高检测器和识别器的性能。 (3)我们还会生成大规模的多语言场景文本数据集,这将有助于进一步的研究
2 相关工作
2.1 Synthetic Images
The synthesis of photo-realistic datasets has been a popular topic, since they provide detailed ground-truth annotations at multiple granularity, and cost less than manual annotations. In scene text detection and recognition, the use of synthetic datasets has become a standard practice. For scene text recognition, where images contain only one word, synthetic images are rendered through several steps [45, 10],including font rendering, coloring, homography transformation, and background blending. Later, GANs [5] are incorporated to maintain style consistency for implanted text [50], but it is only for single-word images. As a result of these progresses, synthetic data alone are enough to train state-of-the-art recognizers.
2.1合成图像
逼真的数据集的合成一直是一个热门话题,因为它们提供了多种粒度的详细的地面真相注释,并且其成本低于手动注释。 在场景文本检测和识别中,使用合成数据集已成为一种标准做法。 对于场景文本识别,其中图像仅包含一个单词,合成图像通过几个步骤[45、10]进行渲染,包括字体渲染,着色,单应变换和背景混合。 后来,合并了GAN [5]来维护植入文本[50]的样式一致性,但仅适用于单个单词的图像。 这些进展的结果是,仅合成数据就足以训练最先进的识别器。
To train scene text detectors, SynthText [6] proposes to generate synthetic data by printing text on background images. It first analyzes images with off-the-shelf models, and search suitable text regions on semantically consistent regions. Text are implanted with perspective transformation based on estimated depth. To maintain semantic coherency,VISD [49] proposes to use semantic segmentation to filter out unreasonable surfaces such as human faces. They also adopt an adaptive coloring scheme to fit the text into the artistic style of backgrounds. However, without considering the scene as a whole, these methods fail to render text instances in a photo-realistic way, and text instances are too outstanding from backgrounds. So far, the training of detectors still relies heavily on real images.
为了训练场景文本检测器,SynthText [6]建议通过在背景图像上打印文本来生成合成数据。 它首先使用现成的模型分析图像,并在语义一致的区域上搜索合适的文本区域。 根据估计的深度将文本植入透视转换。 为了保持语义上的一致性,VISD [49]提出使用语义分割来过滤掉不合理的表面,例如人脸。 他们还采用了自适应着色方案,以使文本适合背景的艺术风格。 但是,如果不考虑整个场景,这些方法将无法以真实照片的方式渲染文本实例,并且文本实例与背景之间的距离太远了。 到目前为止,检测器的训练仍然严重依赖真实图像。
Although GANs and other learning-based methods have also shown great potential in generating realistic images [47, 16, 12], the generation of scene text images still require a large amount of manually labeled data [50]. Furthermore, such data are sometimes not easy to collect, especially for cases such as low resource languages. More recently, synthesizing images with 3D graphics engine has become popular in several fields, including human pose estimation[42], scene understanding/segmentation [27, 23, 32, 34, 36], and object detection [28, 41, 8]. However, these methods either consider simplistic cases, e.g. rendering 3D objects on top of static background images [28, 42] and randomly arranging scenes filled with objects [27, 23, 34, 8], or passively use off-theshelf 3D scenes without further changing it [32]. In contrast to these researches, our proposed synthesis engine implements active and regular interaction with 3D scenes, to generate realistic and diverse scene text images.
尽管GAN和其他基于学习的方法在生成逼真的图像方面也显示出了巨大的潜力[47、16、12],但场景文本图像的生成仍然需要大量的手动标记数据[50]。 此外,此类数据有时不容易收集,尤其是对于诸如资源不足语言的情况。 最近,使用3D图形引擎合成图像已在多个领域中流行,包括人体姿势估计[42],场景理解/分割[27、23、32、34、36]和对象检测[28、41、8] 。 但是,这些方法都考虑了简单的情况,例如 在静态背景图像[28、42]上渲染3D对象,并随机排列填充有对象的场景[27、23、34、8],或被动使用现成的3D场景而无需进一步更改[32]。 与这些研究相反,我们提出的综合引擎实现了与3D场景的主动和常规交互,以生成逼真的多样的场景文本图像。
2.2. Scene Text Detection and Recognition
Scene text detection and recognition, possibly as the most human-centric computer vision task, has been a popular research topic for many years [48, 20]. In scene text detection, there are mainly two branches of methodologies: Top-down methods that inherit the idea of region proposal networks from general object detectors that detect text instances as rotated rectangles and polygons [18, 52, 11,51, 46]; Bottom-up approaches that predict local segments and local geometric attributes, and compose them into individual text instances [37, 21, 2, 39]. Despite significant improvements on individual datasets, those most widely used benchmark datasets are usually very small, with only around 500 to 1000 images in test sets, and are therefore prone to over-fitting. The generalization ability across different domains remains an open question, and is not studied yet. The reason lies in the very limited real data and that synthetic data are not effective enough. Therefore, one important motivation of our synthesis engine is to serve as a stepping stone towards general scene text detection
2.2 场景文字检测与识别
场景文本检测和识别,可能是最以人为中心的计算机视觉任务,多年来一直是热门的研究主题[48,20]。在场景文本检测中,主要有两个方法分支:自上而下的方法,其继承了将对象实例检测为旋转的矩形和多边形的通用对象检测器中的区域提议网络的概念; [18,52,11,51,46];自下而上的方法可以预测局部线段和局部几何属性,并将它们组合成单独的文本实例[37、21、2、39]。尽管对单个数据集进行了重大改进,但那些使用最广泛的基准数据集通常非常小,测试集中只有大约500至1000张图像,因此容易出现过拟合现象。跨领域的泛化能力仍然是一个悬而未决的问题,尚未进行研究。原因在于真实数据非常有限,并且综合数据不够有效。因此,我们的综合引擎的一个重要动机就是充当通向一般场景文本检测的垫脚石。
Most scene text recognition models consist of CNNbased image feature extractors and attentional LSTM [9] or transformer [43]-based encoder-decoder to predict the textual content [3, 38, 15, 22]. Since the encoder-decoder module is a language model in essence, scene text recognizers have a high demand for training data with a large vocabulary, which is extremely difficult for real-world data. Besides, scene text recognizers work on image crops that have simple backgrounds, which are easy to synthesize. Therefore, synthetic data are necessary for scene text recognizers, and synthetic data alone are usually enough to achieve state-of-the-art performance. Moreover, since the recognition modules require a large amount of data, synthetic data are also necessary in training end-to-end text spotting systems [17, 7, 29].
大多数场景文本识别模型由基于CNN的图像特征提取器和基于注意力的LSTM [9]或基于变换器[43]的编码器/解码器组成,以预测文本内容[3、38、15、22]。 由于编码器-解码器模块本质上是一种语言模型,因此场景文本识别器对具有大词汇量的训练数据有很高的要求,这对于现实世界的数据而言极为困难。 此外,场景文本识别器可用于背景简单,易于合成的图像裁剪。 因此,合成数据对于场景文本识别器是必需的,仅合成数据通常就足以实现最新的性能。 此外,由于识别模块需要大量数据,因此在训练端到端文本点播系统时也需要合成数据[17、7、29]。
3. Scene Text in 3D Virtual World
3.1. Overview
In this section, we give a detailed introduction to our scene text image synthesis engine,UnrealText, which is developed upon UE4 and the UnrealCV plugin [30]. The synthesis engine: (1) produces photo-realistic images, (2) is efficient, taking about only 1-1.5 second to render and generate a new scene text image and, (3) is general and compatible to off-the-shelf 3D scene models. As shown in Fig.2, the pipeline mainly consists of a Viewfinder module (section 3.2), an Environment Randomization module (section3.3), a Text Region Generation module (section 3.4), and a Text Rendering module (section 3.5).
在本节中,我们将对场景文本图像合成引擎UnrealText进行详细介绍,该引擎是基于UE4和UnrealCV插件[30]开发的。 综合引擎:(1)生成照片级逼真的图像,(2)高效,仅花费1-1.5秒即可渲染和生成新的场景文本图像,并且(3)通用且与现成兼容 3D场景模型。 如图2所示,管道主要由取景器模块(第3.2节),环境随机化模块(第3.3节),文本区域生成模块(第3.4节)和文本渲染模块(第3.5节)组成。
Firstly, the viewfinder module explores around the 3D scene with the camera, generating camera viewpoints. Then, the environment lighting is randomly adjusted. Next, the text regions are proposed based on 2D scene information and refined with 3D mesh information in the graphics engine. After that, text foregrounds are generated with randomly sampled fonts, colors, and text content, and are loaded as planar meshes. Finally, we retrieve the RGB image and corresponding text locations as well as text content to make the synthetic dataset.
首先,取景器模块使用相机探索3D场景,生成相机视点。 然后,随机调整环境照明。 接下来,基于2D场景信息提出文本区域,并在图形引擎中使用3D网格信息完善文本区域。 之后,将使用随机采样的字体,颜色和文本内容生成文本前景,并将其作为平面网格加载。 最后,我们检索RGB图像和相应的文本位置以及文本内容,以创建合成数据集。
3.2. Viewfinder
The aim of the viewfinder module is to automatically determine a set of camera locations and rotations from the whole space of 3D scenes that are reasonable and nontrivial, getting rid of unsuitable viewpoints such as from inside object meshes (e.g. Fig. 3 bottom right).
Learning-based methods such as navigation and exploration algorithms may require extra training data and are not guaranteed to generalize to different 3D scenes. Therefore, we turn to rule-based methods and design a physically-constrained 3D random walk (Fig. 3 first row) equipped with auxiliary camera anchors.
3.2. 取景器
取景器模块的目的是从合理且平凡的3D场景的整个空间中自动确定一组相机位置和旋转,以摆脱不适当的视点,例如从内部对象网格中获取视点(例如,图3右下角)。
基于学习的方法(例如导航和探索算法)可能需要额外的训练数据,并且不能保证将其推广到不同的3D场景。 因此,我们转向基于规则的方法,并设计一个配备有辅助摄像机锚点的受物理约束的3D随机行走(图3第一行)。


3.2.1 Physically-Constrained 3D Random Walk
Starting from a valid location, the physically-constrained 3D random walk aims to find the next valid and non-trivial location. In contrast to being valid, locations are invalid if they are inside object meshes or far away from the scene boundary, for example. A non-trivial location should be not too close to the current location. Otherwise, the new viewpoint will be similar to the current one. The proposed 3D random walk uses ray-casting [35], which is constrained by physically, to inspect the physical environment to determine valid and non-trivial locations.
3.2.1物理约束的3D随机游动
从有效位置开始,受身体限制的3D随机行走旨在查找下一个有效且不平凡的位置。 与有效位置相反,例如,如果位置在对象网格内或远离场景边界,则位置无效。 一个重要的位置应该不太靠近当前位置。 否则,新观点将与当前观点相似。 提出的3D随机行走使用光线投射[35](受物理限制)来检查物理环境,以确定有效和非平凡的位置。
In each step, we first randomly change the pitch and yaw values of the camera rotation, making the camera pointing to a new direction. Then, we cast a ray from the camera location towards the direction of the viewpoint. The ray stops when it hits any object meshes or reaches a fixed maximum length. By design, the path from the current location to the stopping position is free of any barrier, i.e. not inside of any object meshes. Therefore, points along this ray path are all valid. Finally, we randomly sample one point betweenthe 13-th and 23-th of this path, and set it as the new location of the camera, which is non-trivial. The proposed random walk algorithm can generate diverse camera viewpoints
在每个步骤中,我们首先随机更改摄像机旋转的俯仰和偏航值,使摄像机指向新的方向。 然后,我们从相机位置向视点方向投射光线。 当射线击中任何物体网格或达到固定的最大长度时,射线停止。 通过设计,从当前位置到停止位置的路径没有任何障碍,即不在任何对象网格的内部。 因此,沿着该光线路径的点都是有效的。 最后,我们对该路径的第13和23之间的一个点进行随机采样,并将其设置为相机的新位置,这是不平凡的。 提出的随机游走算法可以产生不同的相机视点
3.2.2 Auxiliary Camera Anchors
The proposed random walk algorithm, however, is inefficient in terms of exploration. Therefore, we manually select a set of N camera anchors across the 3D scenes as starting points. After every T steps, we reset the location of the camera to a randomly sampled camera anchor. We set N = 150-200 and T = 100. Note that the selection of camera anchors requires only little carefulness. We only need to ensure coverage over the space. It takes around 20 to 30 seconds for each scene, which is trivial and not a bottleneck of scalability. The manual but efficient selection of camera is compatible with the proposed random walk algorithm that generates diverse viewpoints.
3.2.2辅助摄像机锚点
但是,提出的随机游走算法在探索方面效率低下。 因此,我们手动选择3D场景中的N个摄影机锚点作为起点。 每执行T步后,我们会将摄像机的位置重置为随机采样的摄像机锚点。 我们将N = 150-200和T =100。请注意,选择摄像机锚点只需要很少的注意。 我们只需要确保覆盖整个空间即可。 每个场景大约需要20到30秒,这是微不足道的,而不是可伸缩性的瓶颈。 手动但有效的摄像机选择与所提出的产生不同视点的随机行走算法兼容。
3.3. Environment Randomization
To produce real-world variations such as lighting conditions, we randomly change the intensity, color, and direction of all light sources in the scene. In addition to illuminations,we also add fog conditions and randomly adjust its intensity. The environment randomization proves to increase the diversity of the generated images and results in stronger detector performance. The proposed randomization can also benefit sim-to-real domain adaptation [40].
3.3. 环境随机化
为了产生现实世界中的变化,例如照明条件,我们随机更改场景中所有光源的强度,颜色和方向。 除照明外,我们还添加雾条件并随机调整其强度。 环境随机化证明可以增加生成图像的多样性,并具有更强的检测器性能。 所提出的随机化也可以使模拟到真实域适应受益[40]。
3.4. Text Region Generation
In real-world, text instances are usually embedded on well-defined surfaces, e.g. traffic signs, to maintain good legibility. Previous works find suitable regions by using estimated scene information, such as gPb-UCM [1] in SynthText [6] or saliency map in VISD [49] for approximation. However, these methods are imprecise and often fail to find appropriate regions. Therefore, we propose to find text regions by probing around object meshes in 3D world.Since inspecting all object meshes is time-consuming, we
propose a 2-staged pipeline: (1) We retrieve ground truth surface normal map to generate initial text region proposals; (2) Initial proposals are then projected to and refined in the 3D world using object meshes. Finally, we sample a subset from the refined proposals to render. To avoid occlusion among proposals, we project them back to screen space, and discard regions that overlap with each other one by one in a shuffled order until occlusion is eliminated.
3.4. 文字区域产生
在现实世界中,文本实例通常嵌入在定义良好的表面上,例如 交通标志,保持良好的可读性。 先前的工作通过使用估计的场景信息来找到合适的区域,例如SynthText [6]中的gPb-UCM [1]或VISD [49]中的显着性图进行近似。 但是,这些方法不精确,通常无法找到合适的区域。 因此,我们建议通过探测3D世界中的对象网格来查找文本区域。由于检查所有对象网格非常耗时,因此我们
提出一个两阶段的管道:(1)检索地面真面法线图以生成初始文本区域提议; (2)然后使用对象网格在3D世界中投影和完善初始建议。 最后,我们从改进的提案中抽取一个子集进行渲染。 为避免提案之间出现遮挡,我们将它们投影回屏幕空间,并按随机顺序丢弃彼此重叠的区域,直到消除遮挡为止。
3.4.1 Initial Proposals from Normal Maps
In computer graphics, normal values are unit vectors that are perpendicular to a surface. Therefore, when projected to 2D screen space, a region with similar normal values
tends to be a well-defined region to embed text on. We find valid image regions by applying sliding windows of 64×64 pixels across the surface normal map, and retrieve those with smooth surface normal: the minimum cosine similarity value between any two pixels is larger than a threshold t. We set t to 0.95, which proves to produce reasonable results. We randomly sample at most 10 non-overlapping valid image regions to make the initial proposals. Making proposals from normal maps is an efficient way to find potential and visible regions.
3.4.1法线贴图的初始建议
在计算机图形学中,法线值是垂直于曲面的单位向量。 因此,当投影到2D屏幕空间时,法线值相似的区域往往是一个很好的嵌入文本的区域。 我们通过在表面法线贴图上应用64×64像素的滑动窗口来找到有效的图像区域,并检索具有平滑表面法线的图像窗口:任意两个像素之间的最小余弦相似度值都大于阈值t。 我们将t设置为0.95,这证明可以产生合理的结果。 我们随机抽取最多10个不重叠的有效图像区域以提出初始建议。 从法线地图提出建议是找到潜在和可见区域的有效方法。
3.4.2 Refining Proposals in 3D Worlds
As shown in Fig. 4, rectangular initial proposals in 2D screen space will be distorted when projected into 3D world. Thus, we need to first rectify the proposals in 3D world.We project the center point of the initial proposals into 3D space, and re-initialize orthogonal squares on the corresponding mesh surfaces around the center points: the
horizontal sides are orthogonal to the gravity direction. The side lengths are set to the shortest sides of the quadrilaterals created by projecting the four corners of initial proposals into the 3D space. Then we enlarge the widths and heights along the horizontal and vertical sides alternatively. The expansion of one direction stops when the sides of that direction get off the surface1, hit other meshes, or reach the preset maximum expansion ratio. The proposed refining algorithm works in 3D world space, and is able to produce natural homography transformation in 2D screen space.
3.4.2. 3D世界中的优化提案
如图4所示,当投影到3D世界中时,二维屏幕空间中的矩形初始提议将变形。 因此,我们需要首先在3D世界中对提案进行校正,将初始提案的中心点投影到3D空间中,然后在围绕该中心点的相应网格表面上重新初始化正交正方形:
水平边与重力方向正交。 边长设置为通过将初始投标的四个角投影到3D空间中而创建的四边形的最短边。 然后,我们沿水平和垂直方向交替增大宽度和高度。 当某个方向的边脱离表面1,撞击其他网格或达到预设的最大扩展率时,该方向的扩展就会停止。 提出的优化算法可在3D世界空间中工作,并且能够在2D屏幕空间中产生自然的单应变换。

3.5. Text Rendering
Generating Text Images: Given text regions as proposed and refined in section 3.4, the text generation module samples text content and renders text images with certain fonts and text colors. The numbers of lines and characters per line are determined by the font size and the size of refined proposals in 2D space to make sure the characters are not too small and ensure legibility. For a fairer comparison, we also use the same font set from Google Fonts 2 as SynthText does. We also use the same text corpus, Newsgroup20. The generated text images have zero alpha values on non-stroke pixels, and non zero for others.
3.5. 文字渲染
**生成文本图像:**给定文本区域(如第3.4节中所建议和完善的),文本生成模块会采样文本内容并使用某些字体和文本颜色渲染文本图像。 行数和每行的字符数由字体大小和2D空间中经过改进的建议的大小确定,以确保字符不会太小并确保可读性。 为了更公平地进行比较,我们还使用了与SynthText相同的Google Fonts 2字体集。 我们还使用相同的文本语料库Newsgroup20。 生成的文本图像在非笔划像素上的alpha值为零,其他像素的alpha值不为零。
Rendering Text in 3D World: We first perform triangulation for the refined proposals to generate planar triangular meshes that are closely attached to the underlying surface.Then we load the text images as texture onto the generated meshes. We also randomly sample the texture attributes,such as the ratio of diffuse and specular reflection
**在3D世界中渲染文本:**我们首先对经过改进的提案进行三角剖分,以生成紧密附着在基础表面上的平面三角形网格,然后将文本图像作为纹理加载到生成的网格上。 我们还随机采样纹理属性,例如漫反射和镜面反射的比率
3.6. Implementation Details
The proposed synthesis engine is implemented based on UE4.22 and the UnrealCV plugin. On an ubuntu workstation with an 8-core Intel CPU, an NVIDIA GeForce RTX 2070 GPU, and 16G RAM, the synthesis speed is 0.7-1.5seconds per image with a resolution of 1080×720, depending on the complexity of the scene model. We collect 30 scene models from the official UE4 marketplace. The engine is used to generate 600K scene text images with English words. With the same configuration, we also generate a multilingual version, making it the largest multilingual scene text dataset.
3.6. 实施细节
所提出的综合引擎是基于UE4.22和UnrealCV插件实现的。 在配备8核Intel CPU,NVIDIA GeForce RTX 2070 GPU和16G RAM的Ubuntu工作站上,根据场景的复杂程度,合成速度为每张图像0.7-1.5秒,分辨率为1080×720 模型。 我们从官方的UE4市场收集了30种场景模型。 该引擎用于生成带有英文单词的600K场景文本图像。 使用相同的配置,我们还将生成一个多语言版本,使其成为最大的多语言场景文本数据集。
4. Experiments on Scene Text Detection
4.1. Settings
We first verify the effectiveness of the proposed engine by training detectors on the synthesized images and evaluating them on real image datasets. We use a previous yet timetested state-of-the-art model, EAST [52], which is fast and accurate. EAST also forms the basis of several widely recognized end-to-end text spotting models [17, 7]. We adopt an opensource implementation3. In all experiments, models are trained on 4 GPU with a batch size of 56. During the evaluation, the test images are resized to match a short side length of 800 pixels.
Benchmark Datasets We use the following scene text detection datasets for evaluation: (1) ICDAR 2013 Focused Scene Text (IC13) [14] containing horizontal text with zoomed-in views. (2) ICDAR 2015 Incidental Scene Text (IC15) [13] consisting of images taken without carefulnesswith Google Glass. Images are blurred and text are small.(3) MLT 2017 [26] for multilingual scene text detection, which is composed of scene text images of 9 languages.
4.场景文本检测实验
4.1.设定值
我们首先通过在合成图像上训练检测器并在真实图像数据集上对其进行评估来验证所提出引擎的有效性。我们使用先前尚未经过时间考验的最新模型EAST [52],该模型快速,准确。 EAST还构成了几种广泛认可的端到端文本发现模型的基础[17,7]。我们采用开源实施3。在所有实验中,模型都在4个GPU上进行训练,批处理大小为56。在评估期间,调整测试图像的大小以匹配800像素的短边长度。
基准数据集我们使用以下场景文本检测数据集进行评估:(1)ICDAR 2013聚焦场景文本(IC13)[14]包含具有放大视图的水平文本。 (2)ICDAR 2015偶然场景文本(IC15)[13],其中包含使用Google Glass拍摄时不加注意的图像。图像模糊且文本很小。(3)MLT 2017 [26]用于多语言场景文本检测,它由9种语言的场景文本图像组成。
4.2. Experiments Results
Pure Synthetic Data We first train the EAST models on different synthetic datasets alone, to compare our method with previous ones in a direct and quantitative way. Note
that ours, SynthText, and VISD have different numbers of images, so we also need to control the number of images used in experiments. Results are summarized in Tab. 1.
Firstly, we control the total number of images to 10K, which is also the full size of the smallest synthetic dataset,VISD. We observe a considerable improvement on IC15 over previous state-of-the-art by +0.9% in F1-score, and significant improvements on IC13 (+3.5%) and MLT 2017 (+2.8%). Secondly, we also train models on the full set of SynthText and ours, since scalability is also an impor tant factor for synthetic data, especially when considering the demand to train recognizers. Extra training images fur ther improve F1 scores on IC15, IC13, and MLT by +2.6%, +2.3%, and +2.1%. Models trained with our UnrealText data outperform all other synthetic datasets. Besides, the subset of 10K images with our method even surpasses 800K SynthText images significantly on all datasets. The experiment results demonstrate the effectiveness of our pro posed synthetic engine and datasets.
4.2. 实验结果
纯合成数据我们首先在单独的不同合成数据集上训练EAST模型,以直接和定量的方式将我们的方法与以前的方法进行比较。注意
我们的SynthText和VISD的图片数量不同,因此我们还需要控制实验中使用的图片数量。结果总结在Tab. 1.。
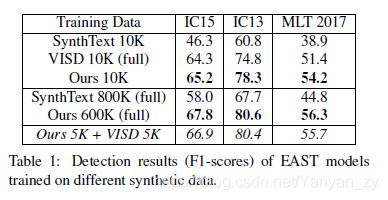
首先,我们将图片总数控制为10K,这也是最小的合成数据集VISD的完整大小。我们观察到IC15在F1评分上比之前的最新技术有了显着提高+ 0.9%,在IC13(+ 3.5%)和MLT 2017(+ 2.8%)上有了显着改进。其次,由于可伸缩性也是合成数据的重要因素,尤其是在考虑培训识别器的需求时,我们还基于SynthText和我们的全套模型来训练模型。额外的训练图像进一步提高了IC15,IC13和MLT的F1得分+2.6%,+ 2.3%和+ 2.1%。使用我们的UnrealText数据训练的模型优于所有其他综合数据集。此外,在我们的方法中,所有数据集上的10K图像子集甚至大大超过了800K SynthText图像。实验结果证明了我们提出的合成引擎和数据集的有效性。
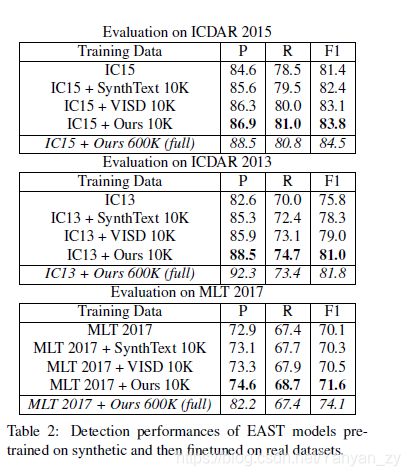
Complementary Synthetic Data One unique characteristic of the proposed UnrealText is that, the images are generated from 3D scene models, instead of real background images, resulting in potential domain gap due to different artistic styles. We conduct experiments by training on bothUnrealText data (5K) and VISD (5K), as also shown in Tab. 1 (last row, marked with italics), which achieves better performance than other 10K synthetic datasets. This result demonstrates that, our UnrealText is complementary to existing synthetic datasets that use real images as backgrounds. While UnrealText simulates photo-realistic effects, synthetic data with real background images can help adapt to real-world datasets.
Combining Synthetic and Real Data One important role of synthetic data is to serve as data for pretraining, and to further improve the performance on domain specific real datasets. We first pretrain the EAST models with different synthetic data, and then use domain data to finetune the models. The results are summarized in Tab. 2. On all domain-specific datasets, models pretrained with our synthetic dataset surpasses others by considerable margins, verifying the effectiveness of our synthesis method in the context of boosting performance on domain specific datasets
互补的合成数据拟议的UnrealText的一个独特特征是,图像是从3D场景模型生成的,而不是真实的背景图像,由于不同的艺术风格而导致潜在的域间隙。我们通过对UnrealText数据(5K)和VISD(5K)进行培训来进行实验,如表所示。Tab. 1(最后一行,用斜体标记),其性能比其他10K合成数据集更好。该结果表明,我们的UnrealText是对使用真实图像作为背景的现有合成数据集的补充。尽管UnrealText模拟逼真的效果,但具有真实背景图像的合成数据可以帮助适应现实世界的数据集。
合成数据和真实数据的组合合成数据的重要作用之一是用作预训练的数据,并进一步提高特定领域的真实数据集的性能。我们首先使用不同的综合数据对EAST模型进行预训练,然后使用领域数据对模型进行微调。结果汇总在Tab. 2. 在所有特定领域的数据集上,使用我们的综合数据集进行预训练的模型在很大程度上超越了其他模型,从而证明了在提高特定领域的数据集性能的背景下我们的综合方法的有效性
Pretraining on Full Dataset As shown in the last rows of Tab. 2, when we pretrain the detector models with our full dataset, the performances are improved significantly, demonstrating the advantage of the scalability of our engine. Especially, The EAST model achieves an F1 score of 74.1 on MLT17, which is even better than recent state-of-the-art results, including 73.9 by CRAFT[2] and 73.1 by LOMO [51]. Although the margin is not great, it suffices to claim that the EAST model revives and reclaims state-of-the-art performance with the help of our synthetic dataset.
在完整数据集上进行预训练如Tab. 2的最后几行所示,当我们使用完整的数据集对检测器模型进行预训练时,性能得到了显着改善,这证明了引擎可伸缩性的优势。 特别是,EAST模型在MLT17上获得的F1分数为74.1,甚至比最近的最新结果更好,包括CRAFT [2]的73.9和LOMO [51]的73.1。 尽管余量不是很大,但可以说EAST模型在我们的综合数据集的帮助下可以恢复并收回最先进的性能。
4.3. Module Level Ablation Analysis
One reasonable concern about synthesizing from 3D virtual scenes lies in the scene diversity. In this section, we address the importance of the proposed view finding module and the environment randomization module in increasing the diversity of synthetic images.
4.3. 模块级消融分析
从3D虚拟场景进行合成的合理考虑之一是场景多样性。 在本节中,我们解决了建议的视图查找模块和环境随机化模块在增加合成图像多样性方面的重要性。
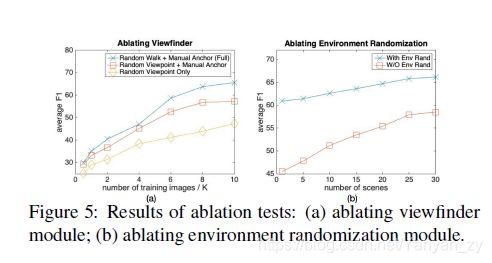
Ablating Viewfinder Module We derive two baselines from the proposed viewfinder module: (1) Random Viewpoint + Manual Anchor that randomly samples camera locations and rotations from the norm-ball spaces centered around auxiliary camera anchors. (2) Random Viewpoint Only that randomly samples camera locations and rotations from the whole scene space, without checking their quality. For experiments, we fix the number of scenes to 10 to control scene diversity and generate different numbers of images, and compare their performance curve. By fixing the number of scenes, we compare how well different view finding methods can exploit the scenes.
消融取景器模块我们从提出的取景器模块中得出两个基线:(1)随机视点+手动锚,它从以辅助摄像机锚点为中心的标准球空间中随机采样摄像机的位置和旋转。 (2)随机视点仅从整个场景空间中随机采样相机位置和旋转,而不检查其质量。 对于实验,我们将场景数量固定为10,以控制场景多样性并生成不同数量的图像,并比较它们的性能曲线。 通过固定场景数量,我们比较了不同的视图发现方法可以利用场景的程度。
Ablating Environment Randomization We remove the environment randomization module, and keep the scene models unchanged during synthesis. For experiments, we fix the total number of images to 10K and use different number of scenes. In this way, we can compare the diversity of images generated with different methods.
消除环境随机化我们删除了环境随机化模块,并在合成期间保持场景模型不变。 对于实验,我们将图像总数固定为10K,并使用不同数量的场景。 这样,我们可以比较使用不同方法生成的图像的多样性
We train the EAST models with different numbers of images or scenes, evaluate them on the 3 real datasets, and compute the arithmetic mean of the F1-scores. As shown in Fig. 5 (a), we observe that the proposed combination,i.e. Random Walk + Manual Anchor, achieves significantly higher F1-scores consistently for different numbers of images. Especially, larger sizes of training sets result in greater performance gaps. We also inspect the images generated with these methods respectively. When starting from the same anchor point, the proposed random walk can generate more diverse viewpoints and can traverse much larger area. In contrast, the Random Viewpoint + Manual Anchor method degenerates either into random rotation only when we set a small norm ball size for random location, or into Random Viewpoint Only when we set a large norm ball size. As a result, the Random Viewpoint + Manual Anchor method requires careful manual selection of anchors, and we also need to manually tune the norm ball sizes for different scenes, which restricts the scalability of the synthesis engine. Meanwhile, our proposed random walk based method is more flexible and robust to the selection of manual anchors. As for the Random Viewpoint Only method, a large proportion of generated viewpoints are invalid, e.g.inside other object meshes, which is out-of-distribution for real images. This explains why it results in the worst performances.
我们用不同数量的图像或场景训练EAST模型,在3个真实数据集上对其进行评估,并计算F1分数的算术平均值。如图5(a)所示,我们观察到所提出的组合,即随机游动+手动锚点可针对不同数量的图像始终如一地获得更高的F1-scores。特别是,较大的训练集会导致更大的性能差距。我们还将分别检查用这些方法生成的图像。当从相同的锚点开始时,建议的随机游走可以产生更多不同的视点,并且可以穿越更大的区域。相反,仅当我们为随机位置设置较小的标准球尺寸时,“随机视点+手动锚点”方法会退化为随机旋转,或者仅当我们设置较大的标准球尺寸时,退化为“随机视点”。结果,“随机视点+手动锚点”方法需要仔细手动选择锚点,并且我们还需要手动调整不同场景的标准球大小,这限制了合成引擎的可伸缩性。同时,我们提出的基于随机游走的方法对于手动锚点的选择更加灵活和健壮。至于仅随机视点方法,很大一部分生成的视点是无效的,例如在其他对象网格内,这对于真实图像而言是分布不全的。这解释了为什么会导致最差的性能。
From Fig. 5 (b), the major observation is that environment randomization module improves performances over different scene numbers consistently. Besides, the improvement is more significant as we use fewer scenes. Therefore,we can draw a conclusion that, the environment randomization helps increase image diversity and at the same time,can reduce the number of scenes needed. Furthermore, the random lighting conditions realize different real-world variations, which we also attribute as a key factor.
从图5(b)中,主要观察到环境随机化模块在不同场景编号上持续提高性能。 此外,由于我们使用较少的场景,因此改善更为显着。 因此,我们可以得出一个结论,环境随机化有助于增加图像多样性,同时可以减少所需的场景数量。 此外,随机照明条件会实现不同的现实世界变化,我们也将其归为关键因素。
5. Experiments on Scene Text Recognition
In addition to the superior performances in training scene text detection models, we also verify its effectiveness in the task of scene text recognition.
5.场景文本识别实验
除了在训练场景文本检测模型方面的出色表现外,我们还验证了其在场景文本识别任务中的有效性。
5.1. Recognizing Latin Scene Text
5.1.1 Settings
Model We select a widely accepted baseline method,ASTER [38], and adopt the implementation4 that ranks top-1 on the ICDAR 2019 ArT competition on curved scene text recognition (Latin) by [19]. The models are trained with a batch size of 512. A total of 95 symbols are recognized, including an End-of-Sentence mark, 52 case sensitive alphabets, 10 digits, and 32 printable punctuation symbols.
5.1。 识别拉丁场景文字
5.1.1设置
模型我们选择一种被广泛接受的基准方法ASTER [38],并采用[19]将在ICDAR 2019 ArT弯曲场景文本识别(拉丁)竞赛中排名第一的实现方法4。 这些模型以512的批量大小进行训练。总共识别出95个符号,包括句子结尾标记,52个区分大小写的字母,10个数字和32个可打印的标点符号。
Training Datasets From the 600K English synthetic images, we obtain a total number of 12M word-level image regions to make our training dataset. Also note that, our synthetic dataset provide character level annotations, which will be useful in some recognition algorithms.
训练数据集从60万个英语合成图像中,我们获得了总数为1200万个字级图像区域,以构成训练数据集。 另请注意,我们的综合数据集提供了字符级注释,这在某些识别算法中将很有用。
Evaluation Datasets We evaluate models trained on different synthetic datasets on several widely used real image datasets: IIIT [24], SVT [44], ICDAR 2015 (IC15) [13],SVTP [31], CUTE [33], and Total-Text[4].
评估数据集我们评估在多个广泛使用的真实图像数据集上的不同合成数据集上训练的模型:IIIT [24],SVT [44],ICDAR 2015(IC15)[13],SVTP [31],CUTE [33]和评估数据集我们评估在多个广泛使用的真实图像数据集上的不同合成数据集上训练的模型:IIIT [24],SVT [44],ICDAR 2015(IC15)[13],SVTP [31],CUTE [33]和Total- 文字[4]。
Some of these datasets, however, have incomplete annotations, including IIIT, SVT, SVTP, CUTE. While these datasets contain punctuation symbols, digits, upper-case and lower-case characters, the aforementioned datasets only provide case-insensitive annotations and ignore all punctuation symbols. In order for more comprehensive evaluation of scene text recognition, we re-annotate these 4 datasets in
a case-sensitive way and also include punctuation symbols.We also publish the new annotations and we believe that they will become better benchmarks for scene text recognition in the future.
但是,其中一些数据集的注释不完整,包括IIIT,SVT,SVTP,CUTE。 虽然这些数据集包含标点符号,数字,大写和小写字符,但上述数据集仅提供不区分大小写的注释,并忽略所有标点符号。 为了对场景文本识别进行更全面的评估,我们在这4个数据集中重新注释了我们还发布了新的注释,我们相信它们将成为将来场景文本识别的更好基准。
5.1.2 Experiment Results
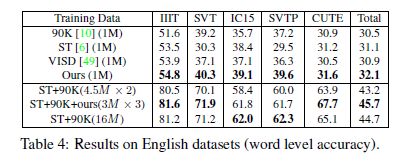
Experiment results are summarized in Tab. 6. First, we compare our method with previous synthetic datasets. We have to limit the size of training datasets to 1M since
VISD only publishes 1M word images. Our synthetic data achieves consistent improvements on all datasets. Especially, it surpasses other synthetic datasets by a considerable margin on datasets with diverse text styles and complex backgrounds such as SVTP (+2.4%). The experiments verify the effectiveness of our synthesis method in scene text recognition especially in the complex cases.
5.1.2实验结果
表中总结了实验结果Tab. 6 首先,我们将我们的方法与以前的综合数据集进行比较。 自从我们将训练数据集的大小限制为1M ,VISD仅发布100万个单词图像。 我们的综合数据在所有数据集上均实现了持续改进。 特别是,在具有多种文本样式和复杂背景的数据集(例如SVTP)上,它远远超过了其他合成数据集(+ 2.4%)。 实验证明了我们的综合方法在场景文本识别中的有效性,特别是在复杂情况下。

Since small scale experiments are not very helpful in how researchers should utilize these datasets, we further train models on combinations of Synth90K, SynthText, and
ours. We first limit the total number of training images to 9M. When we train on a combination of all 3 synthetic datasets, with 3M each, the model performs better than the model trained on 4.5M × 2 datasets only. We further observe that training on 3M × 3 synthetic datasets is comparable to training on the whole Synth90K and SynthText,
while using much fewer training data. This result suggests that the best practice is to combine the proposed synthetic dataset with previous ones.
由于小规模实验对研究人员如何利用这些数据集不是很有帮助,因此我们进一步在Synth90K,SynthText和我们的组合上训练模型。 我们首先将训练图像的总数限制为9M。 当我们训练所有3个综合数据集的组合(每个3M)时,该模型的性能比仅对4.5M×2数据集训练的模型更好。 我们进一步观察到,在3M×3合成数据集上的训练与在整个Synth90K和SynthText上的训练相当,同时使用更少的训练数据。 该结果表明,最佳实践是将拟议的综合数据集与先前的综合数据集相结合。
5.2. Recognizing Multilingual Scene Text
5.2.1 Settings
Although MLT 2017 has been widely used as a benchmark for detection, the task of recognizing multilingual scene text still remains largely untouched, mainly due to lack of a proper training dataset. To pave the way for future research, we also generate a multilingual version with 600K images containing 10 languages as included in MLT 2019 [25]: Arabic, Bangla, Chinese, English, French, German, Hindi, Italian, Japanese, and Korean. Text contents are sampled from corpus extracted from the Wikimedia dump5
5.2. 识别多语言场景文本
5.2.1设置
尽管MLT 2017已被广泛用作检测基准,但主要由于缺少适当的训练数据集,因此仍然无法识别多语言场景文本。 为了为将来的研究铺平道路,我们还生成了包含600,000张图像的多语言版本,其中包含10种语言(包括MLT 2019 [25]):阿拉伯语,孟加拉语,中文,英语,法语,德语,印地语,意大利语,日语和韩语。 文本内容是从Wikimedia dump5提取的语料库中采样的
Model We use the same model and implementation as Section 5.1, except that the symbols to recognize are expanded to all characters that appear in the generated dataset.
模型我们使用与第5.1节相同的模型和实现,除了将要识别的符号扩展为生成的数据集中出现的所有字符。
Training and Evaluation Data We crop from the proposed multilingual dataset. We discard images with widths shorter than 32 pixels as they are too blurry, and obtain 4.1M word images in total. We compare with the multilingual version of SynthText provided by MLT 2019 competition that contains a total number 1.2M images. For evaluation, we randomly split 1500 images for each language (including symbols and mixed) from the training set of MLT 2019. The rest of the training set is used for training.
训练和评估数据我们从建议的多语言数据集中进行裁剪。 我们丢弃宽度小于32像素的图像,因为它们太模糊了,总共获得了410万个文字图像。 我们将与MLT 2019竞赛提供的多语言版本的Sy nthText进行比较,该版本包含总共120万张图像。 为了进行评估,我们从MLT 2019训练集中为每种语言(包括符号和混合符号)随机分割了1500张图像。其余训练集用于训练。
5.2.2 Experiment Results
Experiment results are shown in Tab. 3. When we only use synthetic data and control the number of images to 1.2M ours result in a considerable improvement of 1.6% in overall accuracy, and significant improvements on some scripts,e.g. Latin (+7.6%) and Mixed (+21.6%). Using the whole training set of 4.1M images further improves overall accuracy to 39.5%. When we train models on combinations of synthetic data and our training split of MLT19, as shown in the bottom of Tab. 3, we can still observe a considerable margin of our method over SynthText by 3.2% in overall accuracy. The experiment results demonstrate that our method is also superior in multilingual scene text recognition, and we believe this result will become a stepping stone to further research.
5.2.2实验结果
实验结果显示在Tab. 3,当我们仅使用合成数据并将图像数量控制为120万张时,我们的整体准确度将显着提高1.6%,某些脚本(例如, 拉丁(+ 7.6%)和混合(+ 21.6%)。 使用整个训练集的4.1M图像可将整体准确性进一步提高到39.5%。 当我们使用综合数据和MLT19的训练拆分组合训练模型时,如表底部所示。 3,我们仍然可以看到我们的方法在SynthText上的整体精度有3.2%的可观幅度。 实验结果表明,我们的方法在多语言场景文本识别方面也具有优势,我们相信这一结果将成为进一步研究的垫脚石。
6. Limitation and Future Work
There are several aspects that are worth diving deeper into: (1) Overall, the engine is based on rules and humanselected parameters. The automation of the selection and search for these parameters can save human efforts and help adapt to different scenarios. (2) While rendering small text can help training detectors, the low image quality of the small text makes recognizers harder to train and harms the performance. Designing a method to mark the illegible ones as difficult and excluding them from loss calculation may help mitigate this problem. (3) For multilingual scene text,scripts except Latin have much fewer available fonts that we have easy access to. To improve performance on more languages, researchers may consider learning-based methods to transfer Latin fonts to other scripts.
6.局限性和未来的工作
有几个方面值得深入研究:(1)总体而言,引擎基于规则和人工选择的参数。 选择和搜索这些参数的自动化可以节省人工,并有助于适应不同的情况。 (2)虽然渲染小文本可以帮助训练检测器,但是小文本的低图像质量使识别器更难以训练并损害性能。 设计一种方法来将难以辨认的标记为困难并将其从损失计算中排除可能会减轻此问题。 (3)对于多语言场景文本,除拉丁语外的脚本可用的字体要少得多,我们可以轻松访问这些字体。 为了提高在更多语言上的性能,研究人员可能会考虑基于学习的方法来将拉丁字体转换为其他脚本。
7. Conclusion
In this paper, we introduce a scene text image synthesis engine that renders images with 3D graphics engines, where text instances and scenes are rendered as a whole. In experiments, we verify the effectiveness of the proposed engine in both scene text detection and recognition models. We also study key components of the proposed engine. We believe our work will be a solid stepping stone towards better synthesis algorithms.
7.结论
在本文中,我们介绍了一种场景文本图像合成引擎,该引擎使用3D图形引擎渲染图像,其中文本实例和场景作为整体渲染。 在实验中,我们在场景文本检测和识别模型中验证了提出的引擎的有效性。 我们还将研究拟议发动机的关键组件。 我们相信我们的工作将是迈向更好的综合算法的坚实基础。