Multi-Scale Attention Network for Crowd Counting:用于人群计数的多尺度注意网络
Multi-Scale Attention Network for Crowd Counting:用于人群计数的多尺度注意网络
- Multi-Scale Attention Network for Crowd Counting
-
- Abstract(摘要)
- 1. Introduction
- 2. Ralated Work
- 3. Our approach
-
- 3.1 Baseline network for crowd counting
- 3.2. Scale-aware soft attention masks(尺度感知的软注意力掩膜)
- 3.2. Scale-aware loss regularization(Scale-aware损失正规化)
- 3.4 Estimating the size of each head: η(hp)
- 4. Experiment
-
- 4.1 评价指标
- 4.2 数据集
- 4.3 Implementation details
- 4.4. Analysis of our method
- 4.5 消融实验
- 4.6. Comparison to other crowd counting methods
- 5.Conclusion
Multi-Scale Attention Network for Crowd Counting
论文地址:
https://arxiv.org/pdf/1901.06026.pdf
Abstract(摘要)
在人群计数数据集中,根据人们与摄像机的距离,人们会出现在不同的尺度上。为了解决这个问题,我们提出了一种新的多分支尺度感知注意力网络,该网络利用卷积神经网络的层次结构,并在一次前向传递中产生来自不同层次的多尺度密度预测。为了将这些图整合到我们的最终预测中,我们提出了一种新的软注意机制,它可以学习一组门罩。此外,我们引入一个尺度感知的损失函数来规范不同分支的训练,并引导它们在特定的尺度上专业化。由于这种新的训练需要对每个头部的大小进行标注,我们也提出了一种简单而有效的技术来自动估计它们。最后,我们提出了对这些成分的消融研究,并将我们的方法与4个人群计数数据集的文献进行比较:UCF-QNRF、shanghai Tech A & B和UCF_CC_50。我们的方法在所有这些方面都达到了最先进的水平,在UCF-QNRF(+25%的误差减少)上有了显著的改进。
1. Introduction
人群计数是预测图像中出现的人数的任务。近年来,它吸引了学术研究界越来越多的兴趣。计算机视觉界已经通过多种方式解决了这一任务:早期的工作要么基于身体或头部检测器的输出进行计数[Detection of multiple, partially occluded humans in a single image by bayesian combination of edgelet part detectors、Automatic adaptation of a generic pedestrian detector to a specific traffic scene、Density-aware person detection and tracking in crowds],要么学习从图像的全局或局部特征到预测计数的映射[Privacy preserving crowd monitoring: Counting people without people models or tracking.、Bayesian poisison regression for crowd counting、Crowd counting using multiple local features.]。最近,由于卷积神经网络具有学习局部模式的能力,人们已经开始学习密度图,不仅可以预测计数,还可以预测人群的空间范围[MCNN、 A deep convolutional network for dense crowd counting、Towards perspective-free object counting with deep learning、Switching convolutional neural network for crowd counting.、 Crowd counting via scale-adaptive convolutional neural network.、Divide and grow: Capturing huge diversity in crowd images with incrementally growing cnn、 Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes.、Decidenet: Counting varying density crowds through attention guided detection and density estimation、 Crowd counting via adversarial cross-scale consistency pursuite、 Composition loss for counting, density map estimation and localization in dense crowds.、Scale aggregation network for accurate and efficient crowd counting]。
尽管取得了这些进展,但由于背景杂波、严重遮挡和尺度变化,人群计数仍然是一项具有挑战性的任务。其中,规模是近期文献中关注最多的问题[7 - 14,18]。
在本文中,我们处理尺度的概念,处理视觉变化的人相对于他们与摄像机的距离的外观。如图1a-b所示,两个相似的个体可以根据他们在场景中的相对位置出现非常不同的情况。为了解决这一问题,我们提出了一种新的尺度感知深度卷积神经网络。卷积神经网络的层次结构逐步扩展网络特征图的接受域,隐式捕获不同尺度的信息。受FCN[19]和SSD[20]中跳跃分支的启发,我们提出直接从这些中间特征映射生成多个密度映射。由于最后一层卷积生成的特征图具有最大的接受域,它携带了高级语义信息,可用于定位大型头部;另一方面,由中间层生成的特征图在计算极小的头部(即人群)时更加准确和稳健,它们包含了关于人的空间布局的重要细节和低级的纹理模式。

为了聚合网络不同层生成的密度图,我们提出了一种新的软注意机制,该机制可以学习一组gating masks,每个mask对应一个密度图。我们的mask从最后一层卷积层预测的密度图中学习处理较大的头部,以及从早期层预测的较小的头部。虽然这可以通过对最终密度估计提供监督而得到训练,但我们发现,通过监督中间密度估计也可以提高性能。我们提出了一种新的尺度感知损失函数,以进一步规范我们的多尺度估计,并指导他们专门针对特定的头大小。此外,由于人头大小信息在任何人群计数数据中都不存在,我们还提出了一种新的自动估计人头大小的方法。我们的方法结合了[7]的几何自适应技术和一种新的边界盒自适应技术。
在我们的实验中,我们的方法在四个主要的人群计数数据集上取得了最先进的结果:UCF- qnrf [17], shanghai Tech A & B[7]和UCF CC 50[21],在UCFQNRF上有很大的改进(误差减少超过25%)。此外,在我们的消融研究中,我们分析了由我们网络的不同层生成的密度图,并显示每个层都有不同的尺度变化。
综上所述,我们做出了以下贡献:
1.一种新的网络架构,从其中间层生成多尺度密度图(第3节);
2. 一种新的尺度感知注意机制将这些map聚合到我们的最终预测中(第3.2节);
3.一个新的尺度感知的损失函数,进一步帮助在训练期间规范这些地图(第3.3节);
4. 这是一种简单而有效的技术,可以完全自动地估计图像中每个头部的大小(第3.4节)。
2. Ralated Work
人群计数的多尺度模型。在人群计数图像中,由于场景中巨大的视角变化以及不同的图像分辨率,人们以不同的尺寸出现。为了解决这一问题,最近许多关于人群计数的工作都集中在学习多尺度模型上。
以前的大多数作品使用多列架构[7-11,13,22]。Zhang等人用三个CNN列训练了一个自定义网络,每个列都有不同的接受域来捕捉特定的头部大小范围(MCNN[7])。然而,运行三个CNN栏目太慢了,Sam等人提出对于每个输入图像预测运行哪个列的CNN(Switch-CNN[10])。后来,Sam等人进一步扩展了他们之前的工作,以一种逐步增长的方式培训了一批experts(每个 equivalent相当于一列)(IG-CNN[13])。此外,Sindagi等人提出了一种新的架构,在MCNN中添加了两个额外的列,捕获全局和局部的背景(CP-CNN[11])。Boominathan等人提出使用不同深度的列来代替每个列设计不同的接受域,其中深度CNN捕获大量人群,而浅层CNN捕获较小的人群(CrowdNet[8])。最后,Onoro-Rubio等人(Hydra CNN[9])和Kang等人(AFS-FCN[22])在多个尺度(前者)的图像patch上以金字塔级别表示列,或在以不同分辨率多次馈入同一网络的完整图像(后者)上以金字塔级别表示列。虽然所有这些多列结构都显示出了很好的结果,但它们也存在一些缺点:它们有大量的模型参数,这往往会导致训练过程中的困难,而且它们的推理速度较慢,因为需要运行多个cnn。
为了克服这些限制,最近的研究集中在多尺度、单柱结构上[12,14,18]。Zhang等人提出了一种架构,通过跳跃连接(saCNN[12])将两层的两个特征映射组合在一起。Cao等人提出了一种编码器-解码器网络,其中编码器通过使用组合不同大小的过滤器(SANet[18])的聚合模块来学习尺度多样性的特征。最后,Li等用不同速率的膨胀卷积滤波器替换了CNN中的一些池化层,在不损失空间分辨率(CSRNet[14])的情况下扩大了feature maps的接受域。
在本文中,我们提出了一种通过预测网络不同层的多尺度密度图来模拟多列的单列网络体系结构。我们的体系结构利用了多列方法预测多尺度密度图的能力,但它的计算速度要快得多,需要的参数也少得多。此外,与以前的多列方法不同的是,我们的架构使用了一种新的基于注意力的机制来聚合预测,该机制根据图像中每个头部的大小来选择每一列。
引起机制。注意模型已经被广泛应用于许多计算机视觉任务,如图像分类[23,24],目标检测[25,26],语义分割[27,28],显著性检测[29],以及最近的人群计数[22]。这些模型的工作原理是通过学习中间注意图来选择最相关的信息进行视觉分析。与我们最相似的作品是Chen et al.[27]和Kang et al.[22]。这两种方法都从多个调整大小的输入图像中提取多尺度特征,并使用注意机制对每个特征图的每个像素的重要性进行加权。这些方法的一个明显缺点是,它们的推理速度较慢,因为每个测试图像都需要重新调整大小,并多次输入CNN模型。相反,我们的方法要快得多:它需要一幅输入图像和一次通过模型,因为我们的多尺度特征是通过汇集来自同一个网络的不同层的信息而不是通过同一个网络的多次传递生成的。
3. Our approach
在第3.1节中,我们展示了估算密度图和训练损失的基线网络。在第3.2节中,我们描述了如何通过(i)我们的新多分支密度预测架构和(ii)我们在这些分支之间选择的注意机制来扩展这个基线。在sec3.3中,我们描述了我们的新的尺度感知损失函数,它指导每个密度预测分支专门针对特定的头大小。这种损失需要在训练期间估计头部大小。由于头部大小信息在任何公共数据集中都无法用于人群计数,在第3.4节中,我们提出了一种新的自动估计头部大小的方法。
3.1 Baseline network for crowd counting

像其他基于密度的人群计数方法[7-18]一样,给定一张图像,我们将其输入一个完全卷积网络,并估算出一张密度图(图2,DF)。然后,我们将该密度图中的所有值相加,以获得最终的计数。
我们的基线网络由三部分组成:骨干网络、回归头和上采样层。图像被输入到主干网络中,主干网络逐渐向下采样空间分辨率,以产生一个具有较大接受场但只有图像分辨率的1/16的特征图。这些特征被输入回归头以产生密度图。然后使用双线性上采样将密度估计数恢复到原始图像分辨率。
在训练期间,我们在密度图输出上使用像素级欧几里德损失:
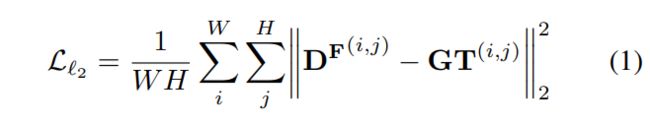
其中DF(i,j)为像素点(i,j)处估计的密度图,GT(i,j)为其对应的地面真值。我们采用MCNN[7]方法生成地面真实密度图(GT),并对高斯核(σ)图像中的每个头部点hp= (x, y)进行模糊处理。
3.2. Scale-aware soft attention masks(尺度感知的软注意力掩膜)
我们的方法用C个密度估计D = [D1,…Dc]丰富主干网络,想法是,每个map都将被专门用于表现一个特定的头部大小范围。我们的网络通过分支我们的主干网络中间层的特征并将每个特征发送到它自己的回归头,在一次向前传递中估计所有的密度图。然后,为了聚合这些密度估计并产生一个单一的密度估计DF,我们使用一个软注意机制,学习一组具有C个gating masks 的对应于每个分支的M = [M1, . . . ,MC]。每个掩模对其相应密度估计值的像素重新加权,产生最终密度估计值DF,如下所示:
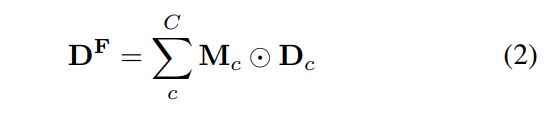
![]()
C个注意力掩膜是由注意力块产生的,注意块将骨干网的最后一个特征映射作为输入,通过注意头进行传递,生成c通道logit地图Z = [Z1, . . . ,ZC],然后这些被输入到一个softmax层来生产遮罩:


softmax确保注意图作为密度预测的加权平均值。
我们用3.1节中使用的相同损耗对该网络进行端到端的训练,仅用于最终密度估计(DF)。直觉告诉我们,注意力掩膜(M)将从最后一个分支(DC)所预测的密度图中学习注意大的头部,因为它来自一个具有较大接受域的特征图。相反,较小的头部会被早期分支([D1,···,DC−1])的密度估计数所关注,因为这些分支有更小的接受野和更高的空间分辨率,因此它们在图像中捕捉到更精细的细节。
3.2. Scale-aware loss regularization(Scale-aware损失正规化)
在eq. 2中,传播回第C个分支的误差信号被注意力掩模Mc调制,即:

这些掩膜迫使每个分支只专注于提高某些选定区域的人群计数精度,而不是将整个错误信号传播回每个分支。虽然图3显示,注意掩码主要关注不同大小的头部,正如预期的那样,网络没有明确的正则化来强制这种情况发生。
在此,我们提出了一个新的尺度感知损失函数,以进一步规范每个分支估计,并指导它们专门针对特定的头大小。为了实现这一点,我们为每个分支添加一个尺度感知的Lsc loss,它仅在该密度图的目标尺寸范围内的头部图像区域测量分支的预测密度图和我们的ground-truth密度图之间的距离。这样,每个分支只需要在其规模上表现良好。
对于每个ground-truth头点,我们估计头大小为η(hp),并将其分配到一个C个头大小的箱子之中。预测头部大小η(hp)在3.4节中介绍。生成每个尺度监督掩模Sc∈{S1,…,SC},我们设置1个区域σ × σ围绕每个训练头hp分配到C个头大小的箱子之中。
这一监督指导每个密度图在其比例范围内正确预测头部,但它不给予任何惩罚的头部以外。我们计算新的尺度感知损失如下:
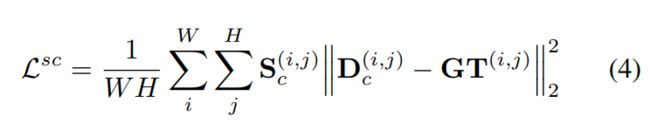
最后,我们的最终损失是最终密度(eq. 1)上的“2”损失和我们在网络中间层上的尺度感知损失的结合。

λ为正则化权值。
3.4 Estimating the size of each head: η(hp)
前一节中提出的尺度感知损失正则化需要估计头部η(hp)的直径,然而,头部大小在任何人群计数数据集中都是不可用的。在本节中,我们提出一种新的估计方法。我们结合了流行的几何自适应技术ηGA[ Single-image crowd counting via multi-column convolutional neural network]和新的定界盒自适应技术ηBB,该技术根据头部探测器的输出估计头部大小。更具体地说,给定头部hp,我们估计其大小如下:
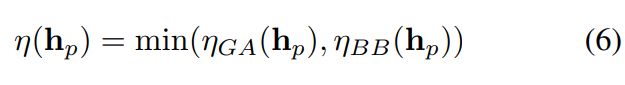
我们首先运行一个人头探测器来计算ηBB。然后,对于每个ground truth head point,我们将其尺度估计为k个最近的head detection的中值大小预测:
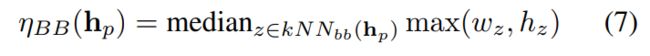
其中kNNbb(hp)为距离hp最近中心的k个检测包围盒,wz和hz分别为包围盒z的宽度和高度。这个估计值只和探测器一样好。我们发现,我们的探测器大多数时候工作得很好,但当人太小、靠得太近时,它就失败了。因此,我们使用Zhang等人的几何自适应方法(ηGA(hp))来增强这种预测。对于每一个头像,这个度量被计算为到k个最近的头像的平均距离的一半,或者:
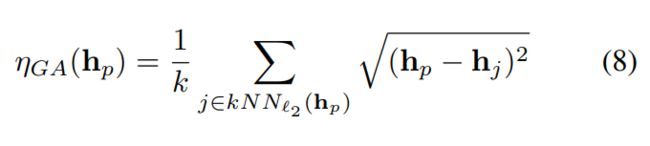
其中k为邻居数,hp为ground truth head注释的(x, y)位置。这种方法适用于拥挤的场景,但不适用于距离较远的人群,因此可以很好地补充我们的ηBB。
4. Experiment
4.1 评价指标
在人群计数中,计数精度由两个误差度量:平均绝对误差(Mean Absolute error, MAE)和平均平方误差(Mean Squared error, MSE),它们的定义如下:
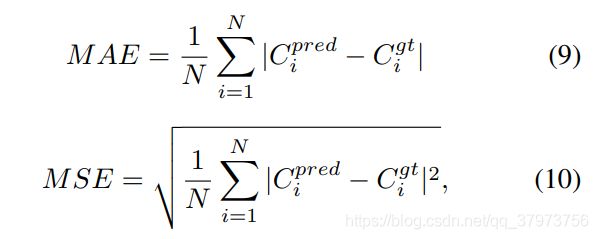
4.2 数据集
我们在UCF- qnrf[17]、shanghaiTech A & B[7]和UCF CC 50[21]这4个公开的人群统计数据集上评估了我们的方法。
UCF-QNRF(2018)是最新发布的数据集,由来自Flickr、网络搜索和麦加朝圣的1535张具有挑战性的图片组成。一张图片中的人数(即计数)从49到12865不等,这使得这个数据集具有最大的人群变化。此外,与所有其他数据集相比,图像的平均分辨率更大,导致一个人的头部的绝对大小从几个像素到超过1500像素变化很大。
ShanghaiTech (2016)由两部分组成:A和b。A部分包含482张密集场景的图像,如体育场和游行;它的计数从33到3139不等。B部分包含716张固定摄像机拍摄的街道场景图片,这些图片捕捉的是稀疏人群;它的计数从12到578不等。
UCF CC 50(2013)由50张黑白低分辨率图像组成,其数量从94到4543不等。我们遵循数据集指令,使用5倍交叉验证评估我们的结果。
4.3 Implementation details
网络体系结构.类似于其他最近的人群计数工作[8,10,11,14],我们使用了VGG-16骨干[30]。我们使用VGG的三个分支(C = 3),分别来自3,4,5块的特征conv3 3, conv4 3和conv5 3。我们的回归头由两个3×3卷积组成,每个卷积有128和64个通道,然后是最后一个1 × 1卷积回归层。
网络hyper-parameters.我们将UCF-QRNF数据集的训练集分为训练集(80%)和验证集(20%),并在验证集上选择最优模型超参数。我们在上海科技公司重复了这个过程,有趣的是,我们观察到最优参数与UCF-QRNF非常相似。我们用随机权值来初始化网络中的所有新层,这些权值来自于一个均值为零、标准差为0.0033的高斯分布。我们使用Adam优化器[31],以1e-4的初始学习速率训练我们的网络120个epoch, 80个epoch后下降到1e-5。我们使用64个批次,从每个训练图像的不同位置随机抽取大小为384 × 384的网络作物。根据之前的工作[7],我们设置σ = 15。为了选择我们的头大小的箱子,我们将所有的训练头按大小(估计如第3.4节所述)分成三个桶,其中训练示例的数量大致相同。这确保了每个中间层都有足够的训练数据。在补充材料中(图1),我们展示了通过装箱头尺寸生成的规模监督面具的可视示例。最后,我们将eq. 5的λ设为0.1,这在仅依赖损耗函数L2(λ = 0)和仅依赖中间损耗Lsc(λ >> 1)之间提供了很好的平衡。
头估计。对于几何自适应和边界盒自适应估计,我们设置邻居的数量为3。对于边界盒自适应估计,我们训练了一个带有ResNet-50骨干[33]的Faster-RCNN[32]头检测器。我们使用了与[34]相同的超参数,但是我们将最小的锚框尺寸从32像素减少到8像素,以便能够定位非常小的头部。我们在两个公共数据集的组合上训练我们的检测器:SCUT-HEAD[35]和Pascal-Parts[36]。SCUT-HEAD包含约111k头的注释,这在视觉上类似于那些在人群计数图像。另一方面,Pascal-Parts只包含7.5k头部的注释,但是它提供了大量非常有用和困难的背景。我们发现将这两个互补的数据集结合起来可以获得很好的检测性能(图4)。
4.4. Analysis of our method
在本节中,我们将研究一些模型组件并分析它们的输出。我们在UCF-QNRF数据集上进行所有的实验,因为它在图像数量和人群计数的多样性上都是最大的。
多尺度密度(D).Li等人的[14]研究表明,MCNN的三列[7]学习到的信息是相似的,而不是被专门化到特定的尺度。在这里,我们调查了我们分支结构的预测,以及在多大程度上我们的分支结构学习了不同规模的信息(图3)。有趣的是,即使没有我们的尺度感知损失,我们的方法也能够学习不同的尺度信息:分支1(输出D1)在体型较小的人身上有更强的激活,因为它将体型较小的人与低水平的纹理模式联系起来,而分支2和分支3在体型中等和体型较大的人身上犯的错误要少得多,因为他们的接受域更大。这种尺度信息的互补性对于更好的尺度感知表示至关重要。
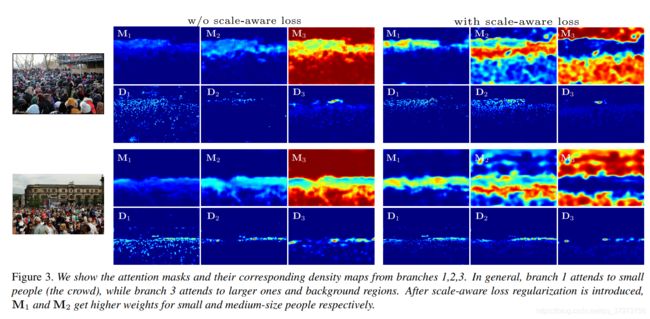
注意遮罩(M)。在图3中,我们也展示了我们的方法生成的注意遮罩。我们的网络为每个分支学习独特的注意力面具。一般情况下,M3对于体型较大的人和背景区域具有更高的权重,而m1对于体型较小的人具有更高的权重。有趣的是,如果没有我们的比例感知损失正则化,掩模学会主要关注分支3预测的密度图(即M3中的红色区域)。另一方面,当使用尺度感知损失时,m1和M2分别获得了对中小型人群更高的权重。这说明了使用我们的正则化来帮助分支更好地专业化其各自的规模的重要性。
聚合多尺度地图。我们将用于聚合多尺度密度预测的软注意机制(第3.2节)与其他流行的聚合方法进行了比较:’ average ‘在语义切分[19]中比较流行,’ max ‘在人体姿态估计[37]中比较流行,’ concatenation+conv '在多列人群计数工作中也比较常用[7,11,12]。结果如表1所示。“Max”产生最大的误差,因为它倾向于高估计数;“连接+conv”和“平均”效果更好,但表现最好的方法是我们的注意力机制。这一结果证明了我们的尺度感知聚合机制对融合多尺度密度图的有效性。

我们的头大小估计方法。我们为我们的头大小估计方法(第3.4节)提供了一些视觉结果(图4)。该图显示了由我们的头部探测器检测到的边界框和由流行的η ga估计的相应的头部大小,我们的η bband和最终的η。为了可视化的目的,我们根据每个头部的大小为其着色,其中暗红色用于每个地图中最大的头部,深蓝色用于最小的头部。ηGA在非常拥挤的场景中表现较好(图4,下行),但在小头彼此远离的稀疏区域中表现较差(图4,上行)。这可能就是为什么CSRNet[14]在其他工作中,在非常密集的shanghai itech Part A数据集中使用几何自适应高斯,而在所有其他人群计数数据集中使用固定高斯的原因。另一方面,η bbr在稀疏和稠密的场景上都表现得很好,但在未探测到的头部上,它预测的个头比现实中要大一些(图4,底部图像,尾部末端)。通过在小说中结合这两种技术,我们能够克服它们的大多数局限性,并产生高度精确的地图(图4,最后一栏)。

我们现在定量地比较了我们用头箱训练的尺度感知方法的性能,头箱由(i)我们的估计η和(ii)经典几何自适应技术η ga定义。虽然两种模型都实现了可比较的MAE性能(约97.5),但结果显示了MSE的差异(175.3 vs 167.8,有利于使用我们的估计)。这是由于几何自适应估计在包含稀疏人头的图像上产生较大的错误。当这些头与更大的头一起被丢弃时,它们被分配到错误的分支,现在需要在其域之外的规模预测头(图2),有效地使训练数据嘈杂。
最后,我们想指出的是,我们的头部估计技术的用途超出了我们在本文中提出的,它可以为未来的人群计数思想打开新的研究方向。
4.5 消融实验
在本节中,我们将展示我们的模型及其组件的增量结果(第3节)。同样,我们将使用UCF-QNRF数据集进行这些实验。
基线结果。作为基线,我们用eq. 1的L2损失和第3.1节的设置训练VGG-16架构骨干。这从网络的最后一个卷积层生成了一个单一的特征映射,它获得了128.5的MAE(表2,行1),这是表中所有条目的最高错误。尽管如此,这个简单的基线还是获得了具有竞争力的结果,可以与最先进的技术相媲美(表3)。
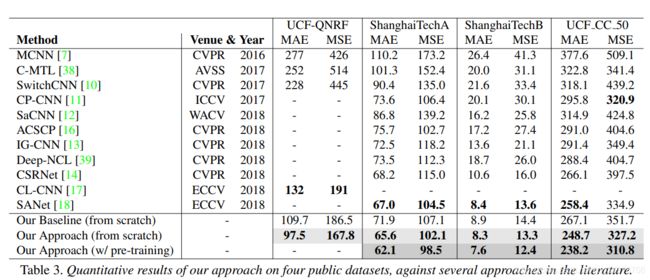
添加m。通过添加三个预测多尺度密度图的分支和我们的新的尺度感知注意机制(第3.2节)来丰富基线,误差减小到116.7(表2第3行),这是一个显著的改进。这表明(1)多尺度特征地图有利于人群计数,(2)从多分支网络中推断出的注意力掩码在聚合多尺度预测方面表现良好。
添加Lsc。添加我们的尺度感知损失正则化(第3.3节)也带来了改进,误差进一步减小到113.3(表2,第3行)。这表明,我们的正则化帮助每个分支在其指定的尺度范围内输出精确的密度图,这共同有助于提高人群估计的精度。
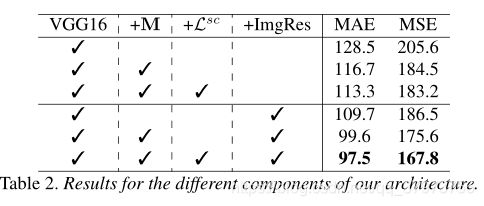
增加图像分辨率的正则化。虽然在训练过程中可以学到规模变化,但有时这些变化超过了网络的能力。我们观察到UCF-QNRF数据集的情况是这样的:它的一些图像是6k×9k,它们包含1.5k×1.5k的头部,显然,这超出了我们的网络接受域的范围。为了克服这个分辨率问题,在推断时,我们将这些大图像降采样到1080p的最大尺寸。这个简单的标准化大大提高了所有组件的性能,将我们的完整方法MAE降低到97.5(表2,最后一行)。值得注意的是,虽然这种改进是通用的,但它仍然保持了每个模型组件的相对重要性:添加M仍然大大提高了基线,添加lsc仍然是性能最好的模型。有趣的是,比起M(175.6到167.8),添加lsc可以显著提高MSE。
4.6. Comparison to other crowd counting methods
我们现在将我们的模型与文献中介绍的数据集上的几种方法进行比较。结果见表3、图5。与文献中的大多数其他工作一样,我们从头开始训练我们的模型,并且只在UCFQNRF数据集上使用图像分辨率正则化(UCFQNRF数据集是唯一一个具有超大图像的数据集)。总的来说,我们的方法总是比基线更好,显示了学习多尺度特征的重要性。此外,我们的方法在所有数据集和所有指标上也优于文献中所有以前的方法。有趣的是,我们在UCF-QNRF数据集上观察到最大的改进,它是最大的数据集,也是头部大小变化最多样的数据集。这进一步表明,我们的模型能够处理如此大规模的变化,从而产生积极的结果(图5)。此外,我们还展示了在大型UCF-QNRF数据集上预训练的模型的结果。由于这个数据集是最近才发布的,以前没有研究过人群计数前训练的影响。我们的结果表明,预处理是非常重要的,它进一步提高了我们的结果5-10%的所有数据集。

最后,图5展示了我们的基线和我们的方法的一些可视化结果。除了在计算图像中的人数方面表现更好之外,我们的方法还显示了更好的局部预测。它的密度地图比基线输出的要清晰得多,后者倾向于平滑有大量人群的区域。这在图5d中尤为明显。这也验证了我们的假设,直接使用低级层次输出中等密度地图有利于小尺度人群的定位,因为这些低级特征地图具有详细的空间布局。
5.Conclusion
在这项工作中,我们提出了一个新的多分支架构,从其中间层生成多尺度密度地图。为了将这些密度图汇总到我们的最终预测中,我们开发了一种新的软注意机制,它可以学习一组门罩,每个门罩对应一个地图。我们进一步引入了规模感知损失,以指导每个分支专门针对不同的规模范围。最后,我们提出了一种简单而有效的方法来估计图像中每个头部的大小。我们的方法在四个具有挑战性的人群计数数据集上,在所有评估指标上取得了最先进的结果。