论文阅读笔记:D-LinkNet(CVPR2018)
D-LinkNet:用于高分辨率卫星图像道路提取的带有预训练编码器和膨胀卷积的LinkNet
摘要:道路提取是遥感领域的一项基础性工作,是近十年来的一个研究热点。在本文中,我们提出了一个语义分割神经网络,称为D-LinkNet,它采用编码器-解码器结构,膨胀卷积和预先训练的编码器用于道路提取任务。该网络采用linknet架构,中心部分采用了膨胀卷积层。Linknet体系结构在计算和存储方面都是有效的。膨胀卷积是一种强大的工具,可以在不降低特征图分辨率的情况下扩大特征点的感受野。在CVPR DeepGlobe 2018道路提取挑战赛中,我们在验证集和测试集上的最佳IoU得分分别为0.6466和0.6342。
1、Introduction
近十年来,从卫星图像中提取道路信息一直是研究的热点。它有广泛的应用,如自动危机响应、道路地图更新、城市规划、地理信息更新、汽车导航等。在卫星图像道路提取领域,近年来提出了多种方法。这些方法大多可以分为三类:生成像素级道路标识[1,2],检测道路骨架[3,4],以及两者的结合[5,6]。
在DeepGlobe道路提取挑战[7]中,从卫星图像中提取道路的任务被描述为一个二值分类问题:将每个像素标记为道路或非道路。在本文中,我们将道路提取任务作为二值语义分割任务来处理,以生成像素级的道路标记。
近年来,深度卷积神经网络(deep convolutional neural networks, DCNN)[8,9,10,11]在许多视觉识别任务中显示出了优势。在图像语义分割领域,普遍采用的是全卷积网络(FCN)[12]体系结构,它可以通过单次前向传递生成整个输入图像的分割图。最新的优秀语义分割网络[13,14,15,16]都是FCN的改进版本。
以往的研究已经将深度学习应用于道路分割任务。Mnih和Hinton[17]公司利用限制玻尔兹曼机器从高分辨率航空图像中分割道路。Saitoet al.[18]使用分类网络将从整个图像中提取的每个斑块分配为道路、建筑或背景。Zhangetal。[1]遵循了FCN架构,并使用了一个带有残差连接的UNet,从一个图像通过单个向前通道分割道路。在本文中,我们遵循这些方法,使用DCNN处理道路分割任务。
虽然近年来对高分辨率卫星图像进行了广泛的研究,但由于其自身的一些特点,道路分割仍然是一项具有挑战性的任务。首先,输入的图像是高分辨率的,所以用于这项任务的网络应该有一个大的感受野,可以覆盖整个图像。其次,卫星图像上的道路往往细长复杂,只覆盖了整个图像的一小部分。在这种情况下,保留详细的空间信息是很重要的。第三,道路具有天然的连通性和大跨度。考虑到道路的这些自然特性是必要的。基于以上讨论的挑战,我们提出了一个语义分割网络,命名为D-LinkNet,它可以很好地处理这些挑战。
D-LinkNet使用预训练编码器的Linknet[15]作为骨干,并在中心部分有额外的膨胀卷积层。Linknet是一种利用跳跃连接、残差块[10]和编解码器结构的高效语义分割神经网络。最初的Linknet使用ResNet18作为其编码器,这是一个相当轻的网络,但性能很好。Linknet在几个基准测试中显示了很高的精度[19,20],而且运行速度相当快。
扩张卷积是在不降低特征图分辨率的情况下调整特征点接收域的有效核函数。它最近被广泛使用,而且一般有两种模式,级联模式如[21]和并行模式如[16],两种模式都显示出很强的提高分割精度的能力。我们充分利用了这两种模式,利用shortcut连接将两种模式结合起来。
迁移学习在大多数情况下,特别是在训练数据有限的情况下,是一种可以直接改善网络性能的有效方法。在语义分割领域,使用ImageNet[23]预训练权值初始化编码器已经显示出很好的结果[16,24]。
在DeepGlobe道路提取挑战中,我们最好的单模型在验证集上获得了0.6412分的IoU。
2、Method
2.1 网络结构
在DeepGlobe道路提取挑战中,所提供的图像和masks的原始大小为1024×1024,以及大多数图像中的道路跨越了整个图像。考虑到这些特性,D-LinkNet设计为以1024×1024的图像作为输入并保存详细的空间信息。如图1所示,D-LinkNet可以分为A、B、C三个部分,分别称为编码器、中心部分和解码器。
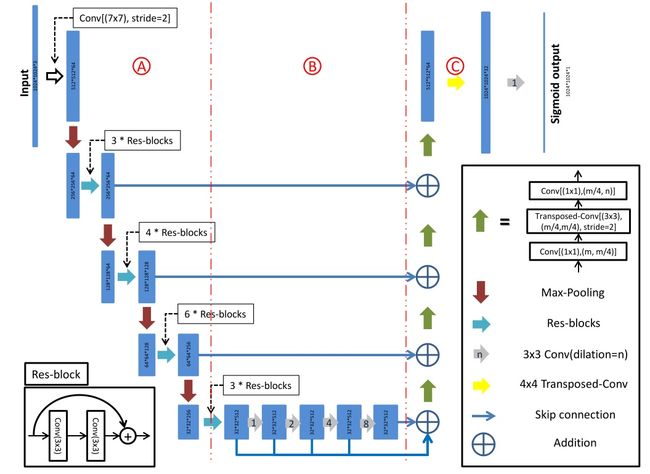
图1 D-LinkNet网络结构
D-LinkNet使用在ImageNet[23]数据集上预先训练的ResNet34[10]作为编码器。ResNet34最初是为中分辨率图像大小为256×256的分类任务而设计的,但在这个挑战中,任务是从大小为1024×1024的高分辨率卫星图像分割道路。考虑到道路的狭窄性、连通性、复杂性和跨度大,在保留详细信息的同时,增加网络中心部分特征点的接受域是很重要的。利用池化层可以成倍增加特征点的接收域,但可能会降低中心特征图的分辨率,降低空间信息。一些最先进的深度学习模型[21,25,26,16]表明,膨胀卷积层是池化层的理想选择。D-LinkNet使用了一些膨胀卷积层,在中心部分跳跃连接。
膨胀卷积可以以级联方式堆叠。如图[21]的图1所示,如果堆叠的膨胀卷积层的膨胀率分别为1、2、4、8、16,则每一层的接受域为3、7、15、31、63。编码器部分(RseNet34)有5个下采样层,如果一个大小为1024×1024的图像通过编码器部分,输出的feature map为大小为32×32。在这种情况下,D-LinkNet在中心部分使用膨胀的卷积层,膨胀率为1,2,4,8,因此最后中间的层上的特征点将在第一个中心特征图上看到31×31个点,覆盖第一个中心特征图的主要部分。但是,D-LinkNet利用了多分辨率的特性,D-LinkNet的中心部分可以看作是如图2所示的并行模式。
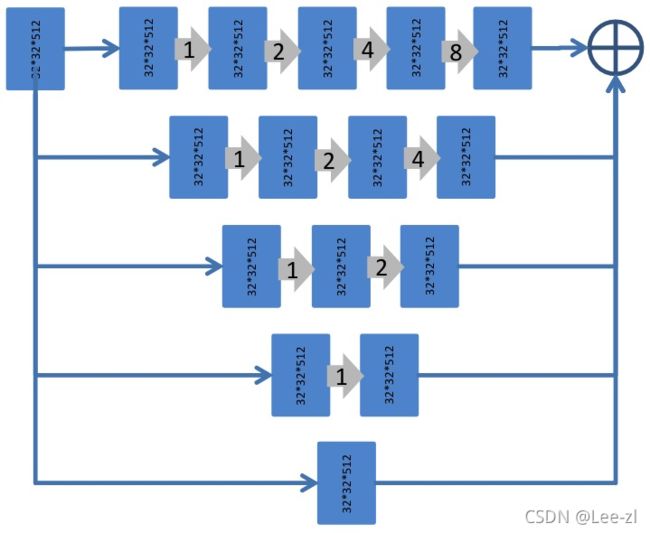
图2 膨胀卷积
D-LinkNet的解码器与原LinkNet[15]相同,具有较高的计算效率。解码器部分采用转置卷积[27]层进行双重采样,恢复特征图从32×32变为1024×1024的分辨率。
2.2 预训练的编码器
迁移学习是一种有效的计算机视觉方法,特别是在训练图像数量有限的情况下。使用ImageNet[23]预训练模型作为网络的编码器是语义分割领域广泛使用的一种方法[16,24]。在DeepGlobe Road extraction Challenge中,我们发现迁移学习可以加速我们的网络收敛,使其在几乎不需要额外成本的情况下具有更好的性能。
3. Experiments
DeepGlobe道路提取挑战赛。我们使用PyTorch[28]作为深度学习框架。所有模型都在4个NVIDIA GTX1080 gpu上训练。
3.1 Dataset
我们在DeepGlobe道路提取数据集[7]上测试了我们的方法,该数据集包含6226幅训练图像、1243幅验证图像和1101幅测试图像。每个图像的分辨率为1024×1024。将数据集表示为二值分割问题,其中道路标记为前景,其他物体标记为背景。
3.2 实施细节
在训练阶段,我们没有使用交叉验证。尽管如此,我们还是想充分利用所提供的数据,所以我们对所有的6226张标签图像训练了我们的模型,只使用组织者提供的1243张验证图像进行验证。这可能存在训练集拟合过度的风险,所以我们以一种大胆的方式进行了数据增强,包括水平翻转、垂直翻转、对角翻转、比较ambitious的颜色抖动、图像移动、缩放。
对于我们的最佳模型,我们使用BCE(二进制交叉熵,binary cross entropy) 和 dice coefficient loss作为损失函数,并选择Adam[29]作为我们的优化器。初始学习率设定为2e-4,每观察3次训练损失缓慢下降时,将学习率降低5。训练阶段的batch大小固定为4。我们的网络花了大约160个时代才收敛。
我们在预测阶段进行了测试时间增强(TTA)测试,包括图像水平翻转、图像垂直翻转、图像对角翻转(预测每个image2×2×2= 8次),然后将输出恢复到与原始图像匹配的位置。然后,我们平均每个预测的概率,使用0.5作为预测阈值来生成二进制输出。
3.3 结果
在DeepGlobe道路提取挑战中,我们训练了一个有7个池层的深层UNet,它可以覆盖大小为1024×1024的图像,作为我们的基线模型,并训练了一个LinkNet34,使用预先训练的编码器,但中心部分没有扩张卷积。不同模型的性能如表1所示。我们发现预先训练的LinkNet34只是比unet从头训练好一点点。我们评估了Unet预测的掩码IoU和LinkNet34预测的掩码IoU,发现在验证集上,这两个模型的平均IoU为0.785,我们认为这是一个相当低的分数。我们认为这两个模型可能会以不同的方式得到几乎相同的分数。我们的基线Unet有更大的感受野,但没有预先训练的编码器和中心特征图的分辨率为8×8,这太小了,无法保存详细的空间信息。linknet34有预先训练的编码器,使网络有更好的表示,但它只有5个下行采样层,几乎没有覆盖the1024×1024images。在回顾这两个模型的输出时,我们发现虽然linknet34在判断一个物体是否为道路时比Unet更好,但它存在道路连接问题。图3中显示了一些示例。D-LinkNet通过在中间部分添加带有捷径的扩展卷积,可以获得比LinkNet更大的接受域,同时保留详细信息,从而缓解了LinkNet34中出现的道路连通性问题。

表1 验证集本文不同模型的测试结果

3.4 分析
在DeepGlobe道路提取挑战赛期间,我们使用了几种方法,我们还做了几项实验,以找出每种方法的贡献。贡献最大的方法是测试时间增加法(TTA),约贡献0.029点。使用BCE + dice coefficient损失比使用BCE + IoU损失高约0.005个点。预训练的编码器贡献了大约0.01个点。中心部分的膨胀卷积约贡献0.011个点。数据增强比没有颜色抖动和形状变换的普通数据增强要好,提高约0.01个点。
4 总结
本文提出了一种用于高分辨率卫星图像道路提取的语义分割网络D-LinkNet。D-LinkNet在保持详细信息的同时,通过在中心部分扩大感受野,集成多尺度特征,在一定程度上处理道路的窄性、连通性、复杂性和长跨度等属性。但是,D-LinkNet仍然存在识别错误和道路连接问题,我们计划在功能上对这些问题做更多的研究。
此外,虽然提出的D-LinkNet架构最初是为道路分割任务设计的,但我们预期它也可能在其他分割任务中有用,我们计划在未来的研究中对此进行研究。
参考文献
D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extractionhttps://zhuanlan.zhihu.com/p/128050957 https://zhuanlan.zhihu.com/p/128050957
https://zhuanlan.zhihu.com/p/128050957
PS:如有侵权,请联系删除,谢谢!