使用python进行数据分析(二)
0x00目标
对<<功夫>>影片的短评进行数据分析,算是童年回忆吧。
站点: aHR0cHM6Ly93d3cuYmlsaWJpbGkuY29tL2Jhbmd1bWkvbWVkaWEvbWQyODIyNzgyMC8/c3BtX2lkX2Zyb209NjY2LjI1LmJfNzI2NTc2Njk2NTc3NWY2ZDZmNjQ3NTZjNjUuMSNzaG9ydA==
项目结构如下:

0x01爬虫部分
1.1接口分析
在源代码里也有部分数据,但应该不够。
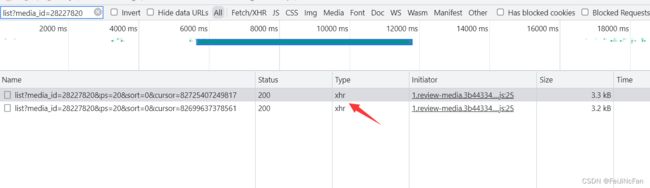
这里可以看到是xhr。
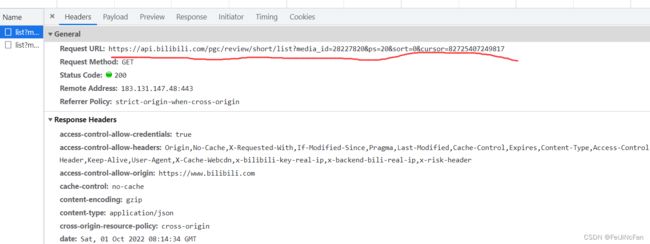
直接在浏览器访问这个接口,可以发现数据全给我们了,因此可以判定没啥反爬。

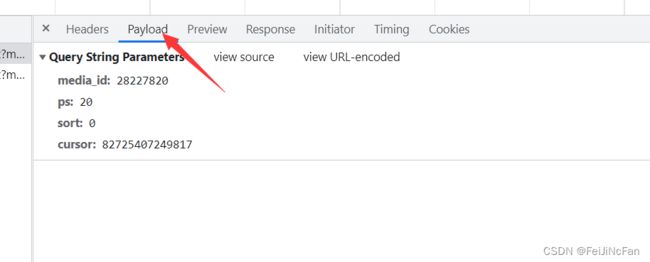
对下一次请求需要拿到cursor,但是最后一次的cursor不知道是什么。那就换一个少评论的影片,观察即可。是0

总结一下:请求方式为get.携带的参数有media_id,ps,sort,cursor,均不难得到。返回的数据类型是json格式。没什么特别的反爬,注意模拟浏览器即可。
1.2存储设计
这里我将uname,score,disliked,liked,likes,ctime,content写入xls文件里,后面转成了csv方便读取数据,感觉xls还是比csv慢。
1.3程序运行的情况
有如下error:

![]()
recursion的默认最大深度应该是1000,导入sys 修改下即可,但是这里就浪费了40分钟了,因为没写日志…后面开了个线程
1.4代码
# !/usr/bin/env python
# -*- coding: utf-8 -*-
# @author: yjp
# @software: PyCharm
# @file: main.py
# @time: 2022-09-30 22:57
import sys
import os
import xlwt
import xlrd
from xlutils.copy import copy
from requests_html import HTMLSession
import time
from threading import *
sys.setrecursionlimit(3000) # 将默认的递归深度修改为3000
session = HTMLSession()
class plSpider(object):
def __init__(self):
self.start_url = "https://api.bilibili.com/pgc/review/short/list?media_id=28227820&ps=20&sort=0&cursor={}"
self.headers = {
'user-agent' : 'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
self.cnt = 0
def parse_start_url(self):
start_url = self.start_url.format(0)
response = session.get(start_url,headers = self.headers).json()
self.parse_start_response(response)
def parse_start_response(self,response):
data = response["data"]['list']
cursor = response["data"]["next"]
self.parse_data(data)
self.get_next_url(cursor)
def get_next_url(self,cursor):
next_url = self.start_url.format(cursor)
response = session.get(next_url, headers=self.headers).json()
self.parse_next_response(response)
def parse_next_response(self,response):
data = response["data"]['list']
cursor = response["data"]["next"]
if cursor == 0:
exit(0)
self.parse_data(data)
self.get_next_url(cursor)
def parse_data(self,data):
"""
提取 uname,score,disliked,liked,likes,ctime,content
:param data:
:return:
"""
for item in data:
self.cnt += 1
print(f"{self.cnt}")
uname = item['author']['uname']
content = item['content']
score = item['score']
ctime = item['ctime']
timeArray = time.localtime(int(ctime))
otherStyleTime = time.strftime("%Y--%m--%d %H:%M:%S", timeArray)
disliked, liked, likes = item["stat"]["disliked"],item["stat"]["liked"],item["stat"]["likes"]
dict = {
'评论数据':[uname,score,disliked,liked,likes,otherStyleTime,content]
}
self.save_excel(dict)
def save_excel(self, data):
#传入的是字典
# data = {
# '基本详情': ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
# }
os_path_1 = os.getcwd() + '/短评数据/'
if not os.path.exists(os_path_1):
os.mkdir(os_path_1)
# os_path = os_path_1 + self.os_path_name + '.xls'
os_path = os_path_1 + '功夫短评数据1.xls'
if not os.path.exists(os_path):
# 创建新的workbook(其实就是创建新的excel)
workbook = xlwt.Workbook(encoding='utf-8')
# 创建新的sheet表
worksheet1 = workbook.add_sheet("评论数据", cell_overwrite_ok=True)
borders = xlwt.Borders() # Create Borders
"""定义边框实线"""
borders.left = xlwt.Borders.THIN
borders.right = xlwt.Borders.THIN
borders.top = xlwt.Borders.THIN
borders.bottom = xlwt.Borders.THIN
borders.left_colour = 0x40
borders.right_colour = 0x40
borders.top_colour = 0x40
borders.bottom_colour = 0x40
style = xlwt.XFStyle() # Create Style
style.borders = borders # Add Borders to Style
"""居中写入设置"""
al = xlwt.Alignment()
al.horz = 0x02 # 水平居中
al.vert = 0x01 # 垂直居中
style.alignment = al
# 合并 第0行到第0列 的 第0列到第13列
'''基本详情13'''
# worksheet1.write_merge(0, 0, 0, 13, '基本详情', style)
excel_data_1 = ('uname','score','disliked','liked','likes','ctime','content')
for i in range(0, len(excel_data_1)):
worksheet1.col(i).width = 2560 * 3
# 行,列, 内容, 样式
worksheet1.write(0, i, excel_data_1[i], style)
workbook.save(os_path)
# 判断工作表是否存在
if os.path.exists(os_path):
# 打开工作薄
workbook = xlrd.open_workbook(os_path)
# 获取工作薄中所有表的个数
sheets = workbook.sheet_names()
for i in range(len(sheets)):
for name in data.keys():
worksheet = workbook.sheet_by_name(sheets[i])
# 获取工作薄中所有表中的表名与数据名对比
if worksheet.name == name:
# 获取表中已存在的行数
rows_old = worksheet.nrows
# 将xlrd对象拷贝转化为xlwt对象
new_workbook = copy(workbook)
# 获取转化后的工作薄中的第i张表
new_worksheet = new_workbook.get_sheet(i)
for num in range(0, len(data[name])):
new_worksheet.write(rows_old, num, data[name][num])
new_workbook.save(os_path)
def Thread_Run(self):
Thread(target=self.parse_start_url()).start()
if __name__ == '__main__':
p = plSpider()
p.parse_start_url()
0x02数据分析部分
做点简单的分析。
主要从评分情况,评论时间,评论字数,情感分析等入手

可以看到五星率到达了99.28%,绝大部分人对这部作品还是很认可的。
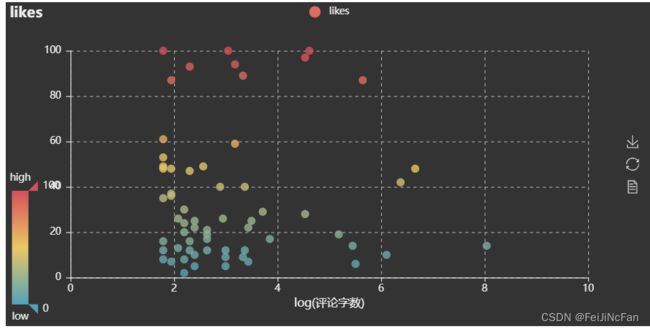
评论字数的话,因为是短评,所以每条评论的字数都不多。
出现最多的关键字如下:

星爷经典电影!!!
词云图如下:

情感分析的话就不做了,得选一个负面评论多点的例子。
0x03总结
可视化是对数据的进一步挖掘,也是数据价值的体现,可以让人轻松地捕捉到自己想看到的内容。