机器学习(西瓜书)--第一章绪论
本书主要介绍从数据获取结果:
代码:https://github.com/Tsingke/Machine-Learning_ZhouZhihua
课后习题:https://blog.csdn.net/snoopy_yuan/article/details/62045353
https://blog.csdn.net/icefire_tyh/article/details/52064910
Machine Learning:第一张主要是一些背景知识,所以简单介绍一些概念;
模型(model):指全局性结果(如一棵决策树);模式:指局部性成果(如一条规则);
第一部分:基本术语:
数据集:data set
样本:sample/instance
特征/属性:feature/attribute-- 属性空间 attribute space, 特征向量 feature vector
训练样本/示例:training data/instance-- 训练集:training set
测试数据/示例: testing data/instance-- 测试集:testing set
聚类:clustering
监督学习:supervised learning-- 无监督学习 unsupervised learning
泛化能力:generalization ,学习模型适应于新样本的能力;
第二部分:假设空间(hypothesis space)
归纳:induction,从特殊到一般的过程;从样例中学习;
演绎:deduction,从一般到特殊的过程;
学习的过程可以看作,在所有假设组成的空间里进行搜索的过程,搜索的目标是找到与训练集匹配(fit)的假设。
对于是否是好瓜,我们从色泽、根蒂、敲声三个维度进行考量,有以下训练集:

好瓜(色泽=?)^ (根蒂 =?) ^(敲声 =?) ,假设每个属性有三个值,比如色泽(青绿、乌黑、浅白),那么有四种可能(青绿、乌黑、浅白+任何色泽都不影响),则一共有4*4*4+1=65中可能性,即假设空间。+1是指根本不存在好瓜的概念。
版本空间(version space):当面临很大的假设空间,但是学习是基于有限的样本,则与训练集一致的假设空间,称作版本空间。
第三部分:归纳偏好
任何算法必有其归纳偏好,否则会被假设空间里看似“等效”的假设迷惑,无法产生确定的学习结果。
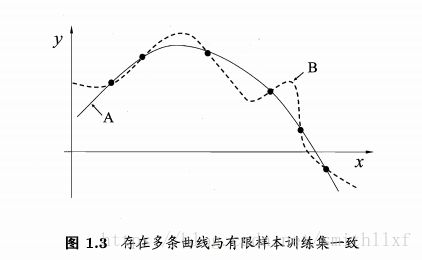
比如,对于相似的样本有相似的输出,对应的学习算法可能偏好于"平滑"的曲线A,而不是“崎岖”的曲线B;
Occam's razor(奥卡姆剃刀):若有多个假设与观察一致,选择最简单的那个;如图1.3,A具有更好的泛化能力。
然而完全有可能存在1.4情况,在(b)里算法B优于算法A;
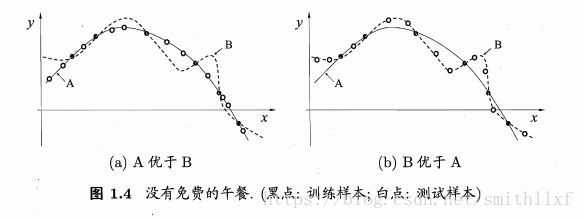
No Free Lunch Theorem(NFL定理)没有免费的午餐:在所有问题出现机会相同、且同等重要时,所有算法的期望值都是相同的。
然而实际情况不是如此,定理最重要的寓意是,脱离具体问题,空泛谈论什么算法更好毫无意义;
第四部分:发展历史
机器学习是人工智能研究到一定阶段必然产物。
4.1 人工智能
20世纪50~70年代,逻辑推理期
50年代中后期,基于神经网络的连接主义(connectionism),60~70年代符号主义(symbolism)
20世纪70年代开始,进入知识期(专家系统,人类将知识汇总给计算机),如果机器能自己学习多好!
4.2 机器学习
R.S.Michalski 把机器学习分为:1,从样例中学习; 2,在问题求解和规划中学习;3,通过观察和发现学习等等;
E.A.Feigenbaum 把机器学习分为:1,机械学习;2,示教学习和类比学习;3,归纳学习(本书的范畴)
数据库领域的研究为数据挖掘提供数据管理技术。
机器学习和统计学研究为数据挖掘提供数据分析技术。
课后习题:

答:数据集有3个属性,每个属性2种取值,一共 3∗3∗3+1=28种假设。

答:
表1.1包含4个样例,3种属性,假设空间中有3∗4∗4+1=49种假设。
析合范式(disjunctive normal form)亦称析取范式一种析取式.是若干简单合取式的析取式。倒三角符号,类似取并集。
合取范式(conjunctive normal form),类似取交集。
48种假设中:
具体假设:2*3*3=18
一个属性泛化假设:2*3+2*3+3*3 = 28
两个属性泛化假设:2+3+3=8
三属性泛化:11111\

答:若两个数据的属性一致,则将他们分为一类。
1.5.试述机器学习在互联网搜索的哪些环节起什么作用
答:推荐算法、文字图像检索算法、数据分类算法。