BEVStereo | nuScenes纯视觉3D目标检测新SOTA!(旷视、中科大)
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【3D检测综述】获取最新基于点云/BEV/图像的3D检测综述!
论文链接:https://arxiv.org/pdf/2209.10248.pdf
代码链接:https://github.com/Megvii-BaseDetection/BEVStereo
摘要
受深度估计固有的模糊性限制,目前基于相机的3D目标检测算法性能陷入瓶颈。直观地说,利用时序多视图立体(MVS) 技术是解决这种模糊性的可能途径。然而,传统MVS方法应用于 3D 目标检测时有两方面的缺陷:1)所有视图之间的亲和度测量计算成本高;2)难以处理室外移动场景。为此,论文提出了一种有效的立体方法来动态选择匹配候选的尺度,使其适应移动目标。论文提出的方法名为BEVStereo,BEVStereo在 nuScenes 上实现了纯视觉方案的新SOTA!(mAP 52.5% 和 NDS 61.0%)。同时,大量实验表明 BEVStereo比当前 MVS 方法能更好地处理复杂的室外场景。
传统时序立体技术主要有两个缺陷:
巨大的内存成本:当使用基本的时序立体方法替换 BEVDepth 中的深度模块时,尽管 NDS 提升1.6%,但内存开销却翻了 3.5 倍;
无法推理自车静止和移动物体的深度:因为自车静止时,视差角趋于 0,而如果物体移动,立体就无法匹配。在 nuScenes 中,超过 10% 的图像帧的自车是静止的,而大约 25% 的目标是移动的。因此,这两个缺点限制了其在自动驾驶场景中的应用。
论文的主要贡献如下:
论文指出MVS 技术是一种很有前途的方法,可以解决纯视觉3D目标检测任务中深度估计的不适定问题。但它暴露了自动驾驶场景中的两个致命缺陷,即大内存成本问题或自车静止和移动目标的问题。
论文提出了一种动态时序立体技术,可以节省极大的内存成本来构建cost volume。此外,提出了一种参数演化算法来解决目标的移动和噪声特征。
BEVStereo 在 nuScenes 数据集上提高了 1.7% mAP 和 1.7% NDS,同时取得了纯视觉新SOTA。实验结果证明 BEVStereo 可以有效地适应移动物体和自车静止的情况。
相关工作
单目3D目标检测
许多方法尝试直接从单目图像中预测3D目标。Cai 等人通过将图像中物体的高度与现实世界中物体的高度相结合来计算物体的深度。基于FCOS,FCOS3D 通过改变分类分支和回归分支将其扩展到3D。M3D-RPN 将单目3D目标检测任务视为独立的 3D 区域提议网络,缩小了 LiDAR 和相机方法之间的差距。DFM 将时序立体与单目 3D 检测相结合,提高了深度估计的质量,同时最大限度地减少时序立体无法处理的困难情况。
多目3D目标检测
当前的多视图 3D 目标检测器可以分为两种模式:基于 LSS 和基于transformer的模式。
BEVDet 是第一个结合 LSS 和 LiDAR 检测头的方法,使用 LSS 提取 BEV 特征并使用 LiDAR 检测头输出 3D 检测结果。通过引入时序信息,BEVDet4D 进一步提升了性能。为了节省内存开销并提升推理速度,M2BEV 减少了可学习的参数。BEVDepth 使用 LiDAR 生成深度真值进行监督,并对相机内外参进行编码,以增强模型的深度感知能力。
DETR3D 将 DETR 扩展到 3D 空间,使用transformer输出检测结果。在 DETR 的基础上,PETR 和 PETRV2 在其上增加了位置嵌入。BEVFormer 使用可变形transformer提取图像特征,并使用交叉注意力连接帧间特征以预测速度。
深度估计
根据用于深度估计的图像数量,深度估计方法可以分为单目和多目深度估计。
尽管从单目预测深度是不适定的,但仍然可以使用上下文信息来估计目标的深度。因此,许多方法使用 CNN 方法来预测深度。
对于多目深度估计,构建cost volume是预测深度的有效方法。MVSNet 是首篇使用cost volume进行深度估计的工作。RMVSNet 通过引入 GRU 模块来降低内存开销。Fast-MVSNet使用稀疏cost volume和 Gauss-Newton 层加速 MVSNet。Wang 等使用自适应patchmatch和多尺度融合来提升性能并保持效率。Bae等引入 MaGNet 以更好地融合单目和多目深度估计。
方法
BEVStereo是一个基于立体的多视图 3D 目标检测器。通过应用时序立体技术,其能够处理复杂的户外场景,同时保持内存效率。论文还提出了一种size-aware circle NMS 方法来提升性能。
Preliminary Knowledge
多目3D目标检测:基于LLS 的多视图3D检测算法目前包括四个组件:特征提取主干,生成深度和上下文的深度模块,将特征从相机视图转换为BEV视图的视图转换器,以及提3D检测头。
时序立体方法以预测深度:基于 MVS 的方法通过构建cost volume来预测深度。对于参考特征上的每个像素,首先沿深度轴选择一些候选目标。接下来使用单应性扭曲操作将候选目标转换到源图像上,以检索相关的源特征并创建cost volume。最后为了预测每个候选深度的置信度,使用 3D 卷积来正则化cost volume。
动态时序立体
基于 BEVDepth,BEVStereo 改变了深度预测的方式。BEVStereo 不是从单目预测深度,而是从单个特征(单目深度)和时序立体(多目深度)预测深度。对于单目深度,论文直接预测深度预测。对于多目深度,首先预测深度中心和深度范围,进一步生成深度分布。此外,使用Weight Net生成用于立体深度的权重图。单目深度和加权后的多目深度相结合得到最终的深度。框架图如下图所示。

深度模块:深度模块同时预测单目深度和上下文。在迭代和之后,通过 EM 方法生成多目深度。迭代过程如图 2 所示。

论文估计代表cost volume的深度中心和深度范围。与其他基于立体的沿深度维度拆分 bin 的方法相比,BEVStereo 可以动态选择搜索区域,同时还能减少候选深度的数量。在估计参考帧的和后,根据cost volume的深度中心和范围为每个像素动态选择候选深度。这些候选者进一步使用单应性warping操作以从源帧中获取特征,如下式所示:
受EM算法的启发,论文尝试在迭代过程中使期望值更接近深度真值。由于论文对接近的多个点云进行采样后计算点云置信度,因此尝试利用这些信息。即使用权重方法更新,公式如下所示:

当遇到自车静止和移动物体等情况时,所有候选共享相同的低概率,因为很难在源特征上找到最佳匹配点,能够通过使用权重和技术保持其值。对于其他场景,的值会在迭代过程中逼近真实的深度值。论文发现当和单目深度一起训练时,初始的质量也在单目深度的方向下得到了提升。因此,在所有场景中,BEVStereo 的动态时序立体方法可以改善深度预测。由于在迭代过程中不断更新,找到合适的设置搜索范围也很关键。根据现有信息,置信度高时应缩小搜索范围,置信度低时应扩大搜索范围,更新公式如下:
为了防止出现投影距离深度 gt 较远的情况,导致迭代时难以优化。论文将深度划分为不同的范围,并在每个范围内进行迭代。迭代过程完成后,深度图按照下式生成:

Weight Net:即使时序立体能够准确预测深度,但仍有不可靠区域,因为一些参考特征点与源特征上的位置不相关。因此,论文引入 Weight Net 以更好地结合单目和多目深度。
Size-aware Circle NMS
Circle NMS 函数使用两个框中心之间的距离作为抑制标准。Circle NMS绕过了计算目标框旋转 IoU的困难过程,实现了出色的效率和良好的性能。然而,忽略框的大小会导致两个缺点,如图 3 所示:
1)无论框重叠多近,只要框中心固定,NMS 算法都会产生相同的输出;
2)当box放置不同时,IoU为0的box可能会被移除,而IoU高的box会被保留。
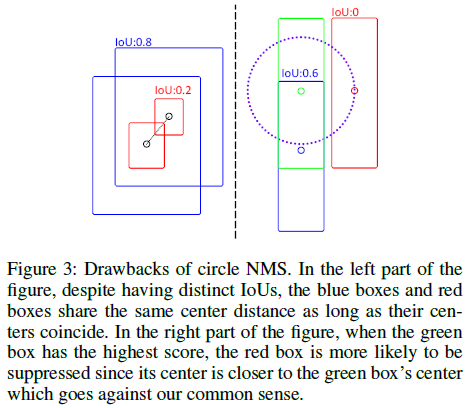
因此论文提出Size-aware Circle NMS,公式如下:

实验
本节首先描述使用的实验设置,然后再详细介绍实施策略。之后进行消融实验。
实验设置
数据集和评价指标:BEVStereo 在 nuScenes数据集上展开实验。训练使用 LiDAR 和图像数据,但只使用图像进行推理。在图像数据下,使用关键帧图像和与其连接的最远扫描,而在激光雷达下,仅使用关键帧数据。评测指标包含检测性能和深度性能。并监测内存的使用验证方法的有效性。具体来说,包含mAP、NDS、mATE、mASE、mAOE等。深度指标包含SILog、Abs Rel等。
实现细节:论文基于 BEVDepth 实现 BEVStereo。用于构建cost volume的特征图进行4倍下采样,而深度特征的最终形式保持不变。应用 MVS 方法以相同的输入分辨率和输出分辨率替换 BEVDepth 中的深度模块,以公平地证明方法的有效性。
分析
论文进行了大量实验来验证 BEVSetreo 算法,以便更好地了解它的工作原理。BEVDepth作为基线,并比较 MVSNet,以展示 BEVStereo 的明显优势,使用检测结果和召回结果进行比较。
内存分析:论文跟踪内存使用情况和检测结果,以展示内存的有效利用。如表6所示,BEVStereo 提升了 mAP、mATE 和 NDS 的指标,只增加了很少的内存开销。

性能分析:nuScenes 上的实验结果如表1所示,BEVStereo 在 mAP、mATE 和 NDS 上的表现优于 BEVDepth。

表2表明BEVStereo提升了深度估计的性能。

进一步论文评估了 BEVStereo 在难例下(例如移动物体和自车静止)的性能。如表3所示,即使 MVS 方法在处理移动物体时失败,BEVStereo 仍然具有提高性能的能力。

表4评估了静态目标场景的性能,BEVStereo对静态物体的感知能力甚至高于带MVS的BEVDepth。

表5评估了自车速度较低时的性能,因为MVS 无法处理这种情况。BEVStereo 仍然可以提高性能。重要的是要注意,如果在推理步骤中没有更新,当面对移动物体和自车静止等情况时,仍然会产生类似的结果。这表明BEVStereo 能够引导深度模块产生更好的结果,并在面对这些可能性时保持最初的预测。

消融实验
和迭代次数的消融实验如表7所示:

Size-aware Circle NMS的消融实验见表8:

Efficient Voxel Pooling v2:在之前版本的 Efficient Voxel Pooling中,同一个 warp 中的线程不连续地访问内存,导致更多的内存开销,从而导致性能不佳。论文通过改进线程映射方式来增强Efficient Voxel Pooling,如图 4 所示。以这种方式,来自 L2 高速缓存和全局内存的限制性能的内存事务将减少。论文在各种分辨率下比较两者的耗时,Efficient Voxel Pooling v2 能够将延迟降低 40%以上。

可视化
图5展示了BEVStereo能够提升对运动和静态物体的深度估计的准确性:

检测结果可视化如图6所示,可以看出BEVStereo取得了比BEVDepth更好的性能。

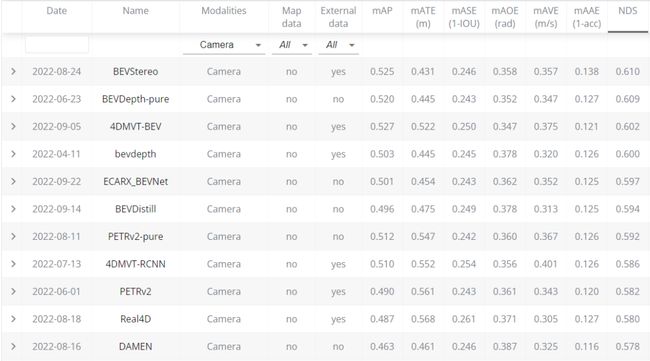
榜单结果
结论
本文提出了一种新颖的多目 3D 目标检测器,即 BEVStereo。BEVStereo 通过应用动态时序立体技术来创建时间立体,在不显著增加内存使用的情况下提高了性能。BEVStereo 可以解决其他基于立体的方法无法处理的一些复杂场景。此外,提出了size-aware circle NMS,它考虑了框的大小,同时避免了旋转 IoU 的困难计算。在类可知和类不可知的情况下,size-aware circle NMS 表现令人满意。最后但同样重要的是,Efficient Voxel Pooling v2 可以通过提高内存访问的效率来加速体素池化。
往期回顾
史上最全综述 | 3D目标检测算法汇总!(单目/双目/LiDAR/多模态/时序/半弱自监督)
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、多传感器融合、SLAM、光流估计、轨迹预测、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
