java 校验银行卡号_Java + OpenCV 实现银行卡号识别 (3)
卡号分类方法
想要做到既识别得了浮雕字体,又能识别印刷字体的银行卡,就需要分开来处理。前面已经讲解了如何针对浮雕卡号进行图像增强处理并分割出单独字符,而印刷类型银行卡号不需要这么麻烦的处理,网上的常规处理手段就能将数字完整的显现出来,上文已经看到效果,我采用的是固定阈值法。
再加上中值滤波的方法就能简单粗暴地对绝大部分印刷类银行卡号进行二值化,效果图上文也展示过了。
现在要做的是如何实现卡号类型的区分。


印刷型卡号

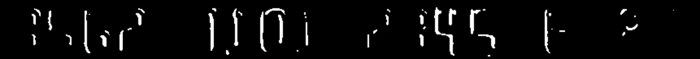
浮雕型卡号
不说出来估计你也猜到了如何辨别它们之间的差别,肉眼就能明显区分出来。浮雕字体在固定阈值法二值化之后大部分都林星点点,或者大片白色背景,而印刷体由于亮度均匀因而能够呈现大体样子。
根据这样的观察总结出的规律,就可以通过连通域的大小对它们进行区分了,实现起来比较简单,但要提高鲁棒性还是得多做测试加以修整。我觉得自己这部分做的还是不够简洁,就不放出代码了嘻嘻。
字符识别模块
对切割出来的单个图像数字 (0-9) 进行 OCR 转换成文本数字,这时需要依靠神经网络分类器来完成。简单的卷积神经网络 CNN 就能胜任这一工作,通过大量的图像数字样本的监督学习提高其识别准确率。
使用Tesseract
理论上来说是可行的,但实际上训练调参、防止过拟合等问题百出让人头大。于是我找到了 Tesseract 来帮我快速完成这个工作。Tessercat 是谷歌开源的 OCR 识别引擎,Tesseract 可具有字符序列识别能力,同时它的训练文件是开放的,包含各种语言文字,同时英文数字识别的精准度很高。
这样就免去了训练模型的繁琐操作,学习如何使用 Tesseract 就可以了。它可以实现字符序列的识别,也就是不需要自己做额外的分割字符的工作。但很遗憾的是,它的训练文件的字体没有浮雕类型,需要自己额外训练。但不知为何,自己训练的模型无法识别多个文字,而单个字符识别率还可以。这也是我一开始要对浮雕类型卡号做分割的原因。
然而印刷体就不需要了,因为官方的训练文件已经涵盖了,并且实际识别中正确率很高,所以识别印刷类银行卡只需定位到卡号就可以。
import org.bytedeco.javacpp.BytePointer;
import static org.bytedeco.javacpp.lept.*;
import org.bytedeco.javacpp.tesseract;
import org.bytedeco.javacpp.tesseract.TessBaseAPI;
import static org.bytedeco.javacpp.lept.pixDestroy;
import java.io.File;
import java.io.UnsupportedEncodingException;
/**
* Created by chenqiu on 11/12/18.
*/
public class TessReg {
static TessBaseAPI mTess;
/**
* tessdata 的父目录
*/
private static String path = "/res/";
public static void init(){
mTess = new TessBaseAPI();
if (mTess.Init(System.getenv("TESSDATA_PREFIX"), "eng") != 0) {
System.err.println("Could not initialize tesseract.");
System.exit(1);
}
String whiteListOfNumber = "1234567890";
// 限制识别的字符 0-9
mTess.SetVariable("tessedit_char_whitelist", whiteListOfNumber);
}
/**
* get result string
* @param f
* @return
*/
public static String getOCRText(File f){
init();
PIX image = pixRead(f.getAbsolutePath());
mTess.SetImage(image);
BytePointer outText = mTess.GetUTF8Text();
String out = null;
try {
out = outText.getString("UTF-8");
mTess.End();
outText.deallocate();
pixDestroy(image);
mTess.close();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (Exception e) {
System.out.println("Could not close tesseract.");
e.printStackTrace();
}
mTess = null;
return out;
}
}
使用前先转成 Maven 项目,在 pom.xml 文件加入依赖。
....
....
org.bytedeco.javacpp-presets
tesseract-platform
4.0.0-1.4.4
....
....
来看这篇文章的小伙伴都应该接触过 Tesseract,那就不再详细讲述它的用法了,如不清楚 Java 中的使用方式,请移步至 bytedeco GitHub。
Tesseract 识别印刷字体
下面是使用 Tesseract 识别印刷型银行卡的结果,最终我没有让卡号区域进行二值化处理,而是灰度化后直接交给 Tesseract 识别卡号序列,避免二值化后产生的微小噪声干扰到识别。这里使用的训练文件语言为英文 eng.traineddata

CardOCR_01
Tesseract 识别浮雕字体
而识别浮雕类银行卡就需要多走一步了,官方没有给我们提供这类字体的训练文件,需要自行收集数据集训练。终究还是逃不过机器学习的魔爪
这里包含两个步骤,一是收集数据,二是训练 Tesseract 的神经网络生成训练文件 xxx.traineddata。
收集的数据是单个银行卡字符且是凹凸的 Farrington-7B 字体的,数据量十万以上。目前我还没找到相关公开的数据集,不知道是不是因为银行卡号码这类数据过于敏感。如果有收集到的小伙伴留言咱们研究一下。
没有找到所以我怎么样呢,只能硬着头皮自己来了。靠着前面的卡号定位和分割算法,提供一张银行卡图像就能得到相对应的单个字符组,别忘了最后最好对所有字符图像大小归一化。网上的银行卡图片也很有限,自己的卡屈指可数,但是借助数十张的样本也能够识别,出错率较高,16 个数字下来,基本上不会全对。
所以,收集训练样本这一块是硬伤。
第二步,如何训练 Tesseract,网上有很多,Tesseract 的 GitHub 上也有,可以参考 《小昇的博客-Tesseract训练提高识别准确率》。
闲来无事写了这么多,希望对大家有所帮助。