Hadoop之企业级解决方案
目录
1. 小文件问题及企业级解决方案
1.1 小文件问题
1.2 小文件解决方案
1.2.1 SequenceFile
1.2.2 MapFile
1.3 读取HDFS上的SequenceFile实现WordCount案例
2. MapReduce数据倾斜问题
2.1 增加Reduce的个数
2.2 把倾斜的数据打散
3. Yarn资源队列配置和使用
3.1 Yarn调度器
3.2 Yarn对资源队列配置和使用
1.2.1 SequenceFile
1.2.2 MapFile
1.3 读取HDFS上的SequenceFile实现WordCount案例
2. MapReduce数据倾斜问题
2.1 增加Reduce的个数
2.2 把倾斜的数据打散
1. 小文件问题及企业级解决方案
1.1 小文件问题
Hadoop的HDFS和MapReduce框架是针对大数据文件来设计的,在小文件的处理上不但效率低下,而且十分消耗内存资源。很多小文件会存在两个问题:
- 针对NameNode而言,它在NameNode中都会占用150字节的内存空间,最终会导致我们集群中虽然存储了很多小文件,文件的体积并不大,这样没有意义。
- 针对MapReduce,每个小文件占用一个block,每个block会产生一个inputSplit,最终每个小文件会产生一个Map任务,这样会导致启动很多Map任务,Map的启动本身是非常耗时的,启动以后执行很短时间就停止了,真正计算的时间可能没有启动任务消耗的时间多,会影响MapReduce的执行效率。
解决方案是通常选择一个容器,将小文件同意组织起来,HDFS提供了两种类型的容器,分别是SequenceFile和MapFile
1.2 小文件解决方案
1.2.1 SequenceFile
- SequenceFile是Hadoop提供的一种二进制文件,这种二进制文件直接将
- 一般对小文件可以使用这种文件合并,即将文件名作为key,文件内容作为value序列化到大文件中。
注意:SequenceFile需要一个合并文件的过程,文件较大,且合并后的文件不方便查看,必须通过遍历查看每一个文件。
- 代码: 包括合并和读取
package com.sanqian.mr;
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import java.io.File;
import java.io.IOException;
/**
* 小文件解决方案之SequenceFile
*/
public class SmallFileSeq {
public static void main(String[] args) throws IOException {
//生成SequenceFile
write("D:\\data\\smallFile", "/data/lwx1087471/seqFile");
//读取SequenceFile
read("/data/lwx1087471/seqFile");
}
/**
* 生成SequenceFile文件
* @param inputDir 输入目录-windows目录
* @param outputFile 输出文件:HDFS文件
* @throws IOException
*/
private static void write(String inputDir, String outputFile) throws IOException {
// 创建一个配置
Configuration conf = new Configuration();
//指定HDFS地址
conf.set("fs.defaultFS", "hdfs://192.168.21.101:9000");
//删除HDFS上的输出文件
FileSystem fileSystem = FileSystem.get(conf);
fileSystem.delete(new Path(outputFile), true);
//构造opts数组,有三个元素
/**
* 第一个:输出路径
* 第二个:key的类型
* 第三个: value类型
*/
SequenceFile.Writer.Option[] opts = new SequenceFile.Writer.Option[]{
SequenceFile.Writer.file(new Path(outputFile)),
SequenceFile.Writer.keyClass(Text.class),
SequenceFile.Writer.valueClass(Text.class)
};
//创建一个Writer实例
SequenceFile.Writer writer = SequenceFile.createWriter(conf, opts);
// 指定需要压缩的文件的目录
File inputDirPath = new File(inputDir);
if (inputDirPath.isDirectory()){
// 获取目录中的文件
File[] files = inputDirPath.listFiles();
//迭代文件
for (File file: files){
//获取文件的名字
String fileName = file.getName();
//获取文件的内容
String content = FileUtils.readFileToString(file, "UTF-8");
Text key = new Text(fileName);
Text value = new Text(content);
//向SequenceFile写入数据
writer.append(key, value);
}
}
writer.close();
}
/**
* 读取SequenceFile文件
* @param inputFile : SequenceFile 文件路径
* @throws IOException
*/
private static void read(String inputFile) throws IOException {
// 创建配置
Configuration conf = new Configuration();
//指定HDFS地址
conf.set("fs.defaultFS", "hdfs://192.168.21.101:9000");
//创建阅读器
SequenceFile.Reader reader = new SequenceFile.Reader(conf, SequenceFile.Reader.file(new Path(inputFile)));
Text key = new Text();
Text value = new Text();
//循环读取数据
while (reader.next(key, value)){
//输出文件名
System.out.print("文件名:" + key.toString() + ",");
//输出文件内容
System.out.println("内容:" + value.toString());
}
}
}
效果:
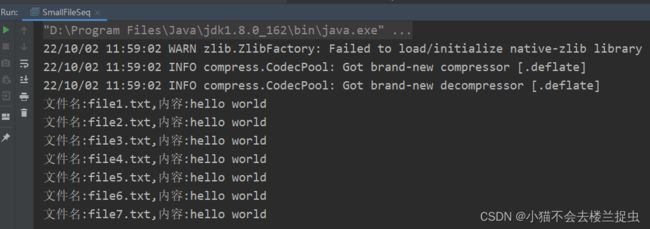
1.2.2 MapFile
- MapFile是排序后的SequenceFile, MapFile由两部分组成,分别是index 和 data
- index作为文件的数据索引,主要记录了每个Record的key值,以及该Record在文件中的偏移位置
- 在MapFile被访问的时候,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定Record所在文件的位置
代码与SequenceFile代码类似,如下所示:
package com.sanqian.mr;
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.MapFile;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import java.io.File;
import java.io.IOException;
/**
* 小文件解决方案之SequenceFile
*/
public class SmallMapFile {
public static void main(String[] args) throws IOException {
//生成SequenceFile
write("D:\\data\\smallFile", "/data/xxx/mapFile");
//读取SequenceFile
read("/data/xxx/mapFile");
}
/**
* 生成MapFile文件
* @param inputDir 输入目录-windows目录
* @param outputDir 输出目录:HDFS目录
* @throws IOException
*/
private static void write(String inputDir, String outputDir) throws IOException {
// 创建一个配置
Configuration conf = new Configuration();
//指定HDFS地址
conf.set("fs.defaultFS", "hdfs://192.168.21.101:9000");
//删除HDFS上的输出文件
FileSystem fileSystem = FileSystem.get(conf);
fileSystem.delete(new Path(outputDir), true);
//构造opts数组,有三个元素
/**
* 第一: key的类型
* 第二个: value类型
*/
SequenceFile.Writer.Option[] opts = new SequenceFile.Writer.Option[]{
MapFile.Writer.keyClass(Text.class),
MapFile.Writer.valueClass(Text.class)
};
//创建一个Writer实例
MapFile.Writer writer = new MapFile.Writer(conf, new Path(outputDir), opts);
// 指定需要压缩的文件的目录
File inputDirPath = new File(inputDir);
if (inputDirPath.isDirectory()){
// 获取目录中的文件
File[] files = inputDirPath.listFiles();
//迭代文件
for (File file: files){
//获取文件的名字
String fileName = file.getName();
//获取文件的内容
String content = FileUtils.readFileToString(file, "UTF-8");
Text key = new Text(fileName);
Text value = new Text(content);
//向SequenceFile写入数据
writer.append(key, value);
}
}
writer.close();
}
/**
* 读取MapFile文件目录
* @param inputDir : MapFile 文件路径
* @throws IOException
*/
private static void read(String inputDir) throws IOException {
// 创建配置
Configuration conf = new Configuration();
//指定HDFS地址
conf.set("fs.defaultFS", "hdfs://192.168.21.101:9000");
//创建阅读器
MapFile.Reader reader = new MapFile.Reader(new Path(inputDir), conf);
Text key = new Text();
Text value = new Text();
//循环读取数据
while (reader.next(key, value)){
//输出文件名
System.out.print("文件名:" + key.toString() + ",");
//输出文件内容
System.out.println("内容:" + value.toString());
}
}
}
运行效果:
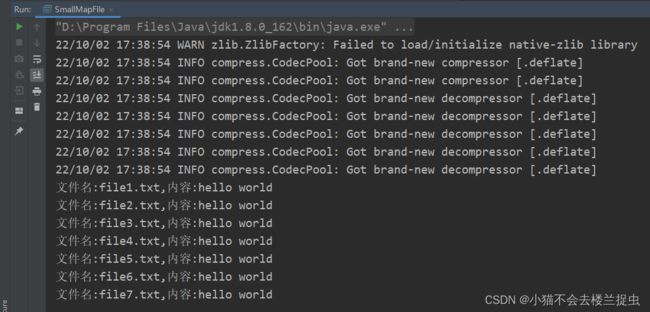
查看HDFS上的文件:

注意: 在本地运行的时候pom.xml中的
1.3 读取HDFS上的SequenceFile实现WordCount案例
在Job中设置输入输出处理类即可,默认情况下是TextInputFormat
- 需要更改地方一:将LongWritable改为Text

需要更改地方二: 在job设置输入数据处理类

完整代码:
package com.sanqian.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
/**
* 需求: 读取SequenceFile文件,计算文件中每个单词出现的次数
*/
public class WorldCountJobSeq {
/**
* Map阶段
*/
public static class MyMapper extends Mapper{
Logger logger = LoggerFactory.getLogger(MyMapper.class);
/**
* 需要实现map函数
* 这个map函数可以接收,产生
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(Text k1, Text v1, Context context) throws IOException, InterruptedException {
//k1 代表的是每一行数据的行首偏移量,va1代表的是每一行内容
//对每一行的内容进行切分,把单词切出来
System.out.println("=<" + k1.toString() + "," + v1.toString() + ">");
logger.info("=<" + k1.toString() + "," + v1.toString() + ">");
String[] words = v1.toString().split(" ");
//迭代切割出来的单词数据
for (String word: words){
// 把迭代出来的单词封装称的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
// 把写出去
context.write(k2, v2);
}
}
}
/**
* Reduce阶段
*/
public static class MyReduce extends Reducer{
Logger logger = LoggerFactory.getLogger(MyReduce.class);
/**
* 针对的数据进行累加求和,并且把数据转换成k3,v3写出去
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable v2s, Context context) throws IOException, InterruptedException {
// 创建sum变量,保存v2s的和
long sum = 0L;
// 对v2s中的数据进行累加求和
for (LongWritable v2: v2s){
System.out.println("=<" + k2.toString() + "," + v2.get() + ">");
logger.info("=<" + k2.toString() + "," + v2.get() + ">");
sum += v2.get();
}
// 组装k3, v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
System.out.println("=<" + k3.toString() + "," + v3.get() + ">");
logger.info("=<" + k3.toString() + "," + v3.get() + ">");
//把结果写出去
context.write(k3, v3);
}
}
/**
* 组装job : map + reduce
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
/**
* args[0]: 全类名, args[1]: HDFS 输入路径, args[2]: HDFS 输出路径
*/
if (args.length != 2){
//如果传递的参数不够,直接退出
System.out.println("参数的长度为:" + args.length);
System.exit(100);
}
// 创建一个job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 注意了:这一行必须设置,否则在集群中执行的时候找不到WordCountJob这个类
job.setJarByClass(WorldCountJobSeq.class);
// 指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//指定map相关代码
job.setMapperClass(MyMapper.class);
// 指定k2的类型
job.setMapOutputKeyClass(Text.class);
// 指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
//设置输入数据处理类
job.setInputFormatClass(SequenceFileInputFormat.class);
//指定reduce相关的代码
job.setReducerClass(MyReduce.class);
//指定k3的类型
job.setOutputKeyClass(Text.class);
//指定v3的类型
job.setOutputValueClass(LongWritable.class);
//提交job
job.waitForCompletion(true);
}
}
2. MapReduce数据倾斜问题
MapReduce程序执行时,Reduce节点大部分执行完毕,但是有一个或者几个Reduce节点运行很慢,导致整个程序处理时间变得很长,具体表现为:Reduce阶段一直卡着不动。
解决方案:
- 增加Reduce的个数
- 把倾斜的数据打散
2.1 增加Reduce的个数
- MapTask的个数是由block(inputSplit)数决定的
- reduce的个数可以指定,默认是1
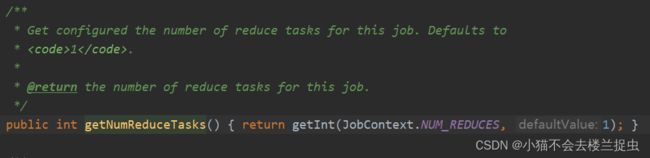
- 在job代码中指定reduce的个数
job.setNumReduceTasks(10);注意: 增加Reduce个数对于数据倾斜严重的情况作用不大
2.2 把倾斜的数据打散
- 在map代码中给k2增加随机数子前缀
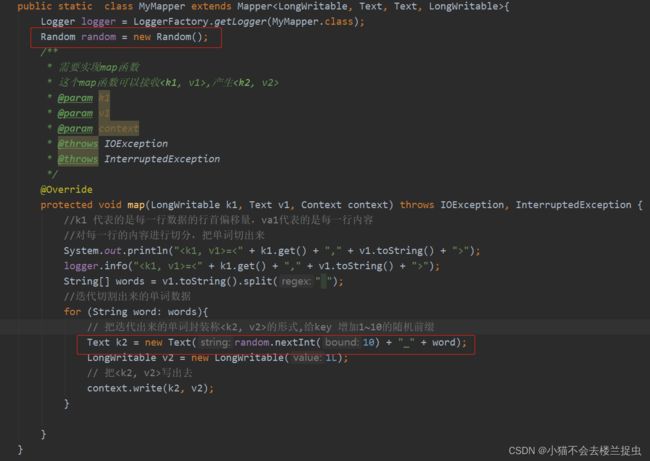
注意: 输出结果是带前缀的数据,相当于局部汇总,需要再写一个MapReduce切分出原始数据进行最终汇总
3. Yarn资源队列配置和使用
在Yarn框架中,调度器是一块很重要的内容。有了合适的调度规则,就可以保证多个应用可以在同一时间有条不紊的工作。最原始的调度规则就是FIFO,即按照用户提交任务的时间来决定哪个任务先执行,但是这样很可能一个大任务独占资源,其他的资源需要不断的等待。也可能一堆小任务占用资源,大任务一直无法得到适当的资源,造成饥饿。所以FIFO虽然很简单,但是并不能满足我们的需求。
3.1 Yarn调度器
在Yarn中有三种调度器可以选择:FIFO Scheduler,Capacity Scheduler,Fair Scheduler。
- FiFO Scheduler : 先进先出(FIFO)调度策略
- Capacity Scheduler : FiFO Scheduler 的对队列版本
- Fair Scheduler : 多队列,多用户共享资源
资源调度器对比图:
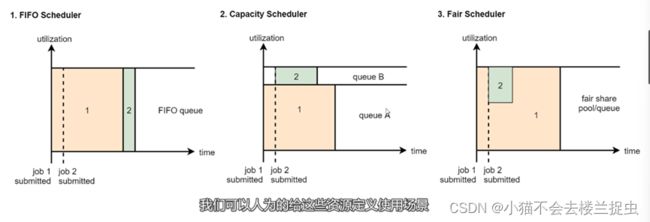
(1)FiFO Scheduler : job1占用了大量资源导致Job2无法执行
(2)Capacity Scheduler : job1和job2分别提交到不同的队列里,互不影响
(3)Fair Scheduler : 当只有job1时独占队列资源,当有job2时job1会把一部分资源分配给job2
总结:在实际工作中一般使用Capacity Scheduler
3.2 Yarn对资源队列配置和使用
yarn的默认配置是有一个默认的队列,事实上,是否使用Capacity Scheduler组件是可以配置的,但是默认配置就是这个Capacity Scheduler,如果想显式配置需要修改 conf/yarn-site.xml 内容如下:
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
- 增加两个队列: online 和offline, 编辑配置文件/etc/hadoop/capacity-scheduler.xml
yarn.scheduler.capacity.root.queues
default,online,offline
The queues at the this level (root is the root queue).
yarn.scheduler.capacity.root.default.capacity
70
Default queue target capacity.
yarn.scheduler.capacity.root.online.capacity
20
Default queue target capacity.
yarn.scheduler.capacity.root.offline.capacity
10
Default queue target capacity.
yarn.scheduler.capacity.root.default.maximum-capacity
70
default队列可以使用的资源上限
yarn.scheduler.capacity.root.online.maximum-capacity
20
online队列可以使用的资源上限
yarn.scheduler.capacity.root.ofline.maximum-capacity
10
offline队列可以使用的资源上限
- 重启集群

- 将MapReduce任务提交的指定队列
修改代码:
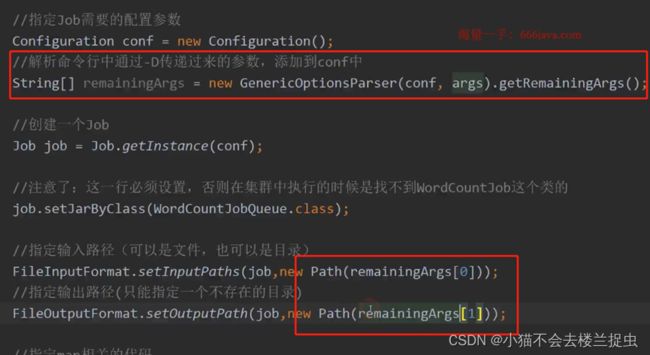
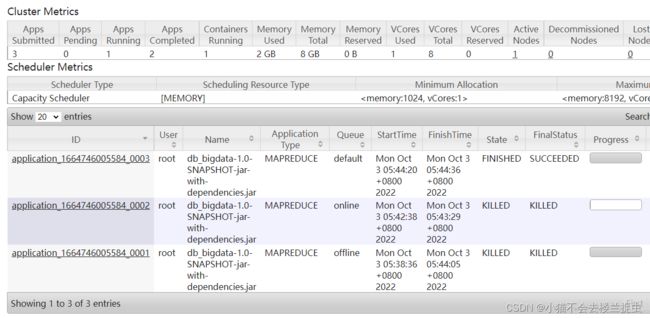
- 提交MapReduce任务:
hadoop jar jars/db_bigdata-1.0-SNAPSHOT-jar-with-dependencies.jar com.sanqian.mr.WorldCountJobQueue -Dmapreduce.job.queuename=default /data/lwx1087471/words.txt /data/lwx1087471/output10