基于卷积神经网络的猫狗识别系统的设计与实现
1.1 题目的主要研究内容
(1)工作的主要描述
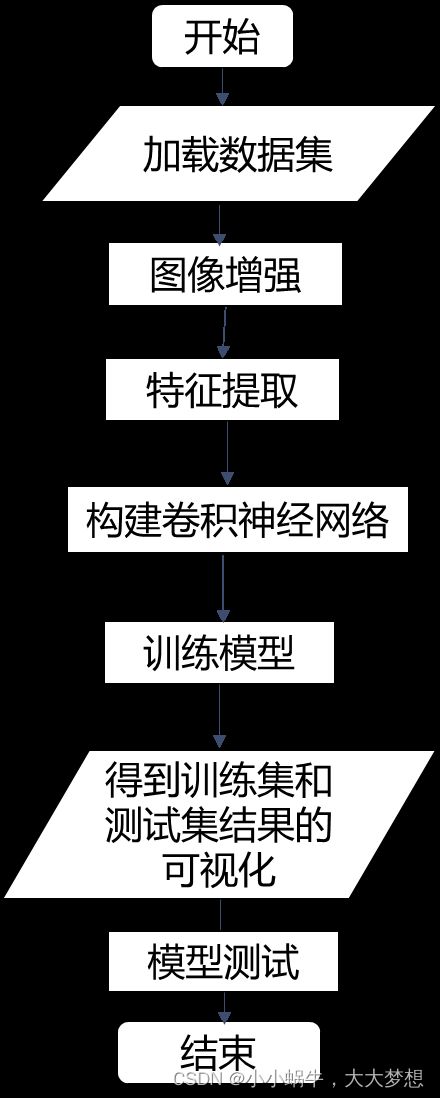
通过卷积网络实现猫狗图像的识别。首先,在数据集中抽取训练集和测试集;其次,对图像进行预处理和特征提取,对图像数据进行图像增强,将图像从.jpg格式转化为RGB像素网格,再转化为像素张量;再次,搭建卷积神经网络模型;最后,使用模型进行训练,得到猫狗识别的准确率和二元交叉熵损失及其可视化图像,并对模型进行测试。
(2)系统流程图
1.2 题目研究的工作基础或实验条件
(1)系统:Windows 10
处理器:i7-7700HQ CPU @2.80GHz
(2)编程软件:Pycharm
版本:Python 3.7
1.3 数据集描述
数据集中共有25000张图片,其中猫狗图片各12500张,在数据集中抽取一部分作为训练集和测试集。训练集中猫狗图片各3000张,测试集猫狗图片各1000张。


1.4 特征提取过程描述
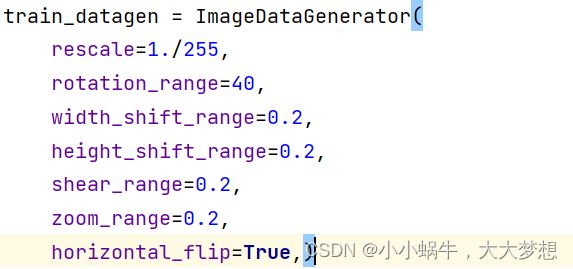
为了防止模型过拟合,采用图像增强的方法,利用ImageDataGenerator方法调整参数对图像进行增强。将所有图片重设尺寸大小为150*150大小,并使用 ImageDataGenerator 方法将本地图片.jpg格式转化成RGB像素网格,再转化成浮点张量上传到网络上,将像素值(介于0和255之间)重新缩放到[0,1]间隔。ImageDataGenerator参数介绍如下:
| 参数名 |
含义 |
| rotation_range |
一个角度值(0-180),在这个范围内可以随机旋转图片 |
| width_shift和height_shift |
范围,在其中可以随机地垂直或水平地转换图片 |
| shear_range |
用于随机应用剪切转换 |
| zomm_range |
用于水平随机翻转一半的图像——当没有假设水平不对称时 |
| horizontal_flip |
用于在图片内部随机缩放 |
| fill_mode |
用于填充新创建像素的策略,它可以在旋转或宽度/高度移动之后出现 |
参数设置为:
1.5 分类过程描述
卷积神经网络分为卷积层,池化层,激活函数,全连接层。首先将图片进行图像增强操作,然后将图片转化为150*150格式输入,通过3*3卷积核提取特征,一个卷积核对应一种特征类型,相当于一个神经元,卷积核的每个元素都有一个权重系数和一个偏差量。在卷积层进行特征提取后,虽然图像会有所减小,但是为了特征值能够准确代表该区域图像特征,输出特征图仍然很大,为了保留主要特征,减少噪声传递,采用最大池化法,再次进行特征值提取。经4次卷积4次池化后,进行全连接,全连接起到分类器的作用,将特征映射到样本的标记空间。然后通过激活函数函数输出分类标签,最后算出识别的准确率和交叉熵损失。本系统共迭代100次,最后将训练集和测试集的准确率和交叉熵损失的可视化图像输出。
本系统卷积神经网络模型如图所示:


1.6 主要程序代码(要求必须有注释)
import os, shutil
# 原始数据集解压缩所在目录的路径
original_dataset_dir = 'E:/catdog/train/train'
# 创建一个存储较小数据集的目录
base_dir = 'E:/catdog/find_cats_and_dogs'
# 培训、验证和测试拆分
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
# 训练猫图片
train_cats_dir = os.path.join(train_dir, 'cats')
# 训练狗图片
train_dogs_dir = os.path.join(train_dir, 'dogs')
# 验证猫图片
validation_cats_dir = os.path.join(validation_dir, 'cats')
# 验证狗图片
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
# 测试猫的图片
test_cats_dir = os.path.join(test_dir, 'cats')
# 测试猫的图片
test_dogs_dir = os.path.join(test_dir, 'dogs')
# 复制前3000个cat图像以训练模型
fnames = ['cat.{}.jpg'.format(i) for i in range(3000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
# 将1000个猫图像复制到验证
fnames = ['cat.{}.jpg'.format(i) for i in range(3000, 4000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
# 复制1000个猫图像到测试
fnames = ['cat.{}.jpg'.format(i) for i in range(3000, 4000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
# 复制3000个狗图片去训练模型
fnames = ['dog.{}.jpg'.format(i) for i in range(3000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
# 复制1000个狗图片去验证
fnames = ['dog.{}.jpg'.format(i) for i in range(3000, 4000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
# 复制1000个狗图片去测试
fnames = ['dog.{}.jpg'.format(i) for i in range(3000, 4000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
##统计图片数量
print('total training cat images:', len(os.listdir(train_cats_dir)))
print('total training dog images:', len(os.listdir(train_dogs_dir)))
print('total validation cat images:', len(os.listdir(validation_cats_dir)))
print('total validation dog images:', len(os.listdir(validation_dogs_dir)))
print('total test cat images:', len(os.listdir(test_cats_dir)))
print('total test dog images:', len(os.listdir(test_dogs_dir)))
from keras import layers
from keras import models
import scipy
from predata import *
import matplotlib.pyplot as plt
#网络模型
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
###输出模型各层的参数状况
model.summary()
from keras import optimizers
#配置优化器:
#loss:计算损失,这里用的是交叉熵损失
#metrics:列表,包含评估模型在训练和测试时的性能的指标
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
from keras.preprocessing.image import ImageDataGenerator
#图像增强 图片格式转化
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
# Note that the validation data should not be augmented!
test_datagen = ImageDataGenerator(rescale=1./255)
#训练集图片格式转化
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=32,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
#测试集图片格式转化
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
#模型训练
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
#保存模型
model.save('cats_and_dogs_small_1.h5')
#可视化
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
import cv2
import tensorflow as tf
categories = ['Dog', 'Cat']
from PIL import Image
import matplotlib.pyplot as plt
# 图片路径
#转化图片格式
def prepare(path):
img_size = 150
img_array = cv2.imread(path)
new_array = cv2.resize(img_array, (img_size, img_size))
return new_array.reshape(-1, img_size, img_size, 3)
#调用模型
model = tf.keras.models.load_model('cats_and_dogs_small_1.h5')
#测试一张图片
prediction = model.predict([prepare('3.jpg')])
if prediction == 1:
title = "this is a dog"
else:
title = "this is a cat"
img = Image.open("3.jpg")
#可视化
plt.imshow(img)
plt.axis('off') # 关掉坐标轴为 off
plt.title(title) # 图像题目
plt.show()
1.7 运行结果及分析
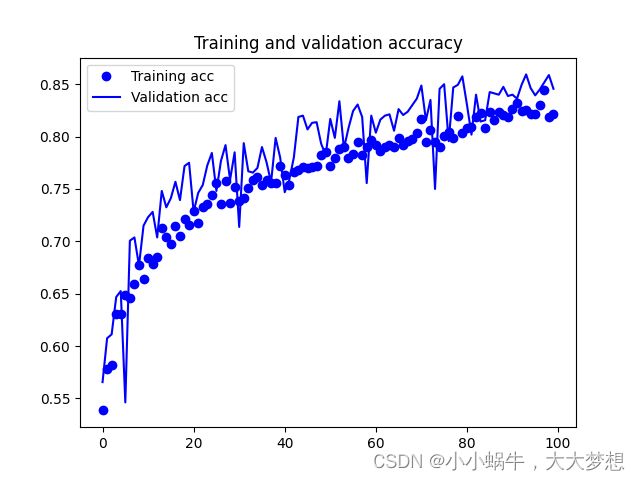
训练集和测试集的准确率变化:
训练集和测试集的损变化:
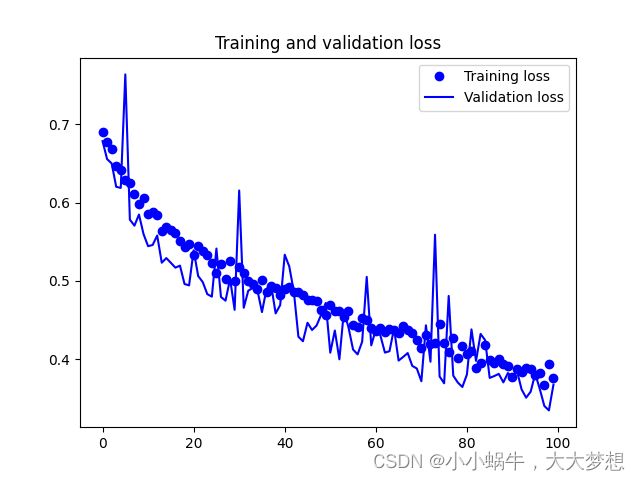
曲线没有过度拟合,训练曲线紧密地跟踪测试曲线,准确率虽然上下波动,但是最高能达到84%左右,测试集的准确率比训练集准确率高,交叉熵损失也呈下降趋势。
对模型进行测试:模型可以识别猫狗。
