Kubernetes故障排查与面试汇总
一、k8s集群pod一直terminating问题的排查
现象描述:
pod一直处于terminating状态,或者很久才能删除,内核日志中持续打印unregister_netdevice: waiting for XXX to become free. Usage count = 1。
故障诊断:
经过定位和排查,定位到是内核的一个bug导致网络设备无法删除。
具体参考:
route: set the deleted fnhe fnhe_daddr to 0 in ip_del_fnhe to fix a race · torvalds/linux@ee60ad2 · GitHub
另外在github的k8s的issues里也有该bug的相关讨论。有人给出了付现这个问题的方式,以及验证上面提到的修复方法是否有效。下面是按照他给出的方案做的复现和验证。
具体可参考:
https://github.com/moby/moby/issues/5618#issuecomment-549333485。
问题排查:
从kubelet内核日志来看是在删除pod的网卡设备时因为内核的引用计数bug,导致无法删除。后续对网卡信息的查询和再次删除操作应该也会导致超时失败(根据日志推断,暂时还未在代码中找到对应调用,线上环境也没法重启调整日志级别和调试)。
首先需要看一个概念:PLEG。
PLEG (pod lifecycle event generator) 是 kubelet 中一个非常重要的模块,它主要完成以下几个目标:
- 从 runtime 中获取 pod 当前状态,产生 pod lifecycle events
- 从 runtime 中获取 pod 当前状态,更新 kubelet pod cache
接下来分析一下造成问题的原因应该是k8s的PLEG在同步pod信息时,可能要查询网卡详情(ip地址),由于内核bug导致超时,致使syncLoop中每执行一次遍历的时间过长(4分钟左右),因此新建pod和删除pod的时候,node上的信息和server上的信息更新不及时。用busybox测试创建和删除时,通过docker ps可以看到响应容器很快就可以启动或删除掉。
从图中可以看到该日志:Calico CNI deleting device in netns /proc/16814/ns/net这条。这是在pod执行删除是产生的。在正常情况下后面会有删除完成的日志信息,如下图:
![]()
但上面的日志里的无此信息,并且10s后打印了unregister_netdevice xxx的日志。这里是触发了内核bug。通过ps aux | grep calico也可以看到在对应时间有一个calico进程启动去执行操作,目前这个进程还在(10.209.33.105),这里估计k8s也有bug,没有wait pid,导致calico成为僵尸进程。

下图是kubelet日志。其中的PLEG is not healthy日志也是在对应的时间点出现:
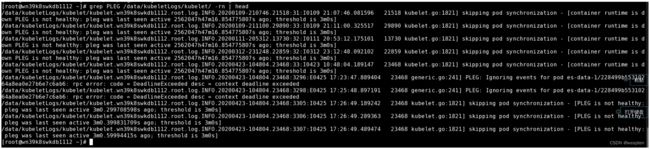
问题本地复现:
要在本地复现这个问题,首先需要给内核打补丁来协助复现。
diff --git a/net/ipv4/route.c b/net/ipv4/route.c
index a0163c5..6b9e7ee 100644
--- a/net/ipv4/route.c
+++ b/net/ipv4/route.c
@@ -133,6 +133,8 @@
static int ip_min_valid_pmtu __read_mostly = IPV4_MIN_MTU;
+static int ref_leak_test;
+
/*
* Interface to generic destination cache.
*/
@@ -1599,6 +1601,9 @@ static void ip_del_fnhe(struct fib_nh *nh, __be32 daddr)
fnhe = rcu_dereference_protected(*fnhe_p, lockdep_is_held(&fnhe_lock));
while (fnhe) {
if (fnhe->fnhe_daddr == daddr) {
+ if (ref_leak_test)
+ pr_info("XXX pid: %d, %s: fib_nh:%p, fnhe:%p, daddr:%x\n",
+ current->pid, __func__, nh, fnhe, daddr);
rcu_assign_pointer(*fnhe_p, rcu_dereference_protected(
fnhe->fnhe_next, lockdep_is_held(&fnhe_lock)));
fnhe_flush_routes(fnhe);
@@ -2145,10 +2150,14 @@ static struct rtable *__mkroute_output(const struct fib_result *res,
fnhe = find_exception(nh, fl4->daddr);
if (fnhe) {
+ if (ref_leak_test)
+ pr_info("XXX pid: %d, found fnhe :%p\n", current->pid, fnhe);
prth = &fnhe->fnhe_rth_output;
rth = rcu_dereference(*prth);
if (rth && rth->dst.expires &&
` time_after(jiffies, rth->dst.expires)) {
+ if (ref_leak_test)
+ pr_info("eXX pid: %d, del fnhe :%p\n", current->pid, fnhe);
ip_del_fnhe(nh, fl4->daddr);
fnhe = NULL;
} else {
@@ -2204,6 +2213,14 @@ static struct rtable *__mkroute_output(const struct fib_result *res,
#endif
}
+ if (fnhe && ref_leak_test) {
+ unsigned long time_out;
+
+ time_out = jiffies + ref_leak_test;
+ while (time_before(jiffies, time_out))
+ cpu_relax();
+ pr_info("XXX pid: %d, reuse fnhe :%p\n", current->pid, fnhe);
+ }
rt_set_nexthop(rth, fl4->daddr, res, fnhe, fi, type, 0);
if (lwtunnel_output_redirect(rth->dst.lwtstate))
rth->dst.output = lwtunnel_output;
@@ -2733,6 +2750,13 @@ static int ipv4_sysctl_rtcache_flush(struct ctl_table *__ctl, int write,
.proc_handler = proc_dointvec,
},
{
+ .procname = "ref_leak_test",
+ .data = &ref_leak_test,
+ .maxlen = sizeof(int),
+ .mode = 0644,
+ .proc_handler = proc_dointvec,
+ },
+ {
.procname = "max_size",
.data = &ip_rt_max_size,
.maxlen = sizeof(int),编译内核的详细步骤参考:zh/HowTos/Custom_Kernel - CentOS Wiki
添加用户useradd kernel-build。
下载内核源码kernel-3.10.0-693.el7.src.rpm,拷贝到/home/kernel-build,并切换到kernel-build用户。
执行rpm -i kernel-3.10.0-693.el7.src.rpm | grep -v exist解压源码包。
进入cd /home/kernel-build/rpmbuild目录。
修改rpm打包文件vim SPECS/kernel.spec,添加patch说明。
ApplyOptionalPatch netdev-leak.patch编辑并生成patch文件,保存到SOURCES/netdev-leak.patch,其内容为:
--- a/net/ipv4/route.c 2017-07-07 07:37:46.000000000 +0800
+++ b/net/ipv4/route.c 2020-05-06 17:33:19.746187091 +0800
@@ -129,6 +129,7 @@
static int ip_rt_min_advmss __read_mostly = 256;
static int ip_rt_gc_timeout __read_mostly = RT_GC_TIMEOUT;
+static int ref_leak_test;
/*
* Interface to generic destination cache.
*/
@@ -1560,8 +1561,15 @@
fnhe = rcu_dereference_protected(*fnhe_p, lockdep_is_held(&fnhe_lock));
while (fnhe) {
if (fnhe->fnhe_daddr == daddr) {
+ if (ref_leak_test)
+ pr_info("XXX pid: %d, %s: fib_nh:%p, fnhe:%p, daddr:%x\n",
+ current->pid, __func__, nh, fnhe, daddr);
rcu_assign_pointer(*fnhe_p, rcu_dereference_protected(
fnhe->fnhe_next, lockdep_is_held(&fnhe_lock)));
+ /* set fnhe_daddr to 0 to ensure it won't bind with
+ * new dsts in rt_bind_exception().
+ */
+ // fnhe->fnhe_daddr = 0; 这行是修复代码,复现问题的时候不需要,注释掉
fnhe_flush_routes(fnhe);
kfree_rcu(fnhe, rcu);
break;
@@ -2054,10 +2062,14 @@
fnhe = find_exception(nh, fl4->daddr);
if (fnhe) {
+ if (ref_leak_test)
+ pr_info("XXX pid: %d, found fnhe :%p\n", current->pid, fnhe);
prth = &fnhe->fnhe_rth_output;
rth = rcu_dereference(*prth);
if (rth && rth->dst.expires &&
time_after(jiffies, rth->dst.expires)) {
+ if (ref_leak_test)
+ pr_info("eXX pid: %d, del fnhe :%p\n", current->pid, fnhe);
ip_del_fnhe(nh, fl4->daddr);
fnhe = NULL;
} else {
@@ -2122,6 +2134,14 @@
#endif
}
+ if (fnhe && ref_leak_test) {
+ unsigned long time_out;
+
+ time_out = jiffies + ref_leak_test;
+ while (time_before(jiffies, time_out))
+ cpu_relax();
+ pr_info("XXX pid: %d, reuse fnhe :%p\n", current->pid, fnhe);
+ }
rt_set_nexthop(rth, fl4->daddr, res, fnhe, fi, type, 0);
if (lwtunnel_output_redirect(rth->dst.lwtstate))
rth->dst.output = lwtunnel_output;
@@ -2661,6 +2681,13 @@
.maxlen = sizeof(int),
.mode = 0644,
.proc_handler = proc_dointvec,
+ },
+ {
+ .procname = "ref_leak_test",
+ .data = &ref_leak_test,
+ .maxlen = sizeof(int),
+ .mode = 0644,
+ .proc_handler = proc_dointvec,
},
{
.procname = "max_size",执行:
rpmbuild -bb –target=`uname -m` SPECS/kernel.spec 2> build-err.log | tee build-out.log安装新内:
yum localinstall RPMS/x86_64/kernel-3.10.0-693.el7.centos.x86_64.rpm编辑ref_leak_test_begin.sh:
#!/bin/bash
# constructing a basic network with netns
# client <-->gateway <--> server
ip netns add svr
ip netns add gw
ip netns add cli
ip netns exec gw sysctl net.ipv4.ip_forward=1
ip link add svr-veth type veth peer name svrgw-veth
ip link add cli-veth type veth peer name cligw-veth
ip link set svr-veth netns svr
ip link set svrgw-veth netns gw
ip link set cligw-veth netns gw
ip link set cli-veth netns cli
ip netns exec svr ifconfig svr-veth 192.168.123.1
ip netns exec gw ifconfig svrgw-veth 192.168.123.254
ip netns exec gw ifconfig cligw-veth 10.0.123.254
ip netns exec cli ifconfig cli-veth 10.0.123.1
ip netns exec cli route add default gw 10.0.123.254
ip netns exec svr route add default gw 192.168.123.254
# constructing concurrently accessed scenes with nerperf
nohup ip netns exec svr netserver -L 192.168.123.1
nohup ip netns exec cli netperf -H 192.168.123.1 -l 300 &
nohup ip netns exec cli netperf -H 192.168.123.1 -l 300 &
nohup ip netns exec cli netperf -H 192.168.123.1 -l 300 &
nohup ip netns exec cli netperf -H 192.168.123.1 -l 300 &
# Add delay
echo 3000 > /proc/sys/net/ipv4/route/ref_leak_test
# making PMTU discovery exception routes
echo 1 > /proc/sys/net/ipv4/route/mtu_expires
for((i=1;i<=60;i++));
do
for j in 1400 1300 1100 1000
do
echo "set mtu to "$j;
ip netns exec svr ifconfig svr-veth mtu $j;
ip netns exec cli ifconfig cli-veth mtu $j;
ip netns exec gw ifconfig svrgw-veth mtu $j;
ip netns exec gw ifconfig cligw-veth mtu $j;
sleep 2;
done
done编辑ref_leak_test_end.sh:
#!/bin/bash
echo 0 > /proc/sys/net/ipv4/route/ref_leak_test
pkill netserver
pkill netperf
ip netns exec cli ifconfig cli-veth down
ip netns exec gw ifconfig svrgw-veth down
ip netns exec gw ifconfig cligw-veth down
ip netns exec svr ifconfig svr-veth down
ip netns del svr
ip netns del gw
ip netns del cli执行测试,首先执行bash ref_leak_test_begin.sh,等待数秒至一分钟时间。Ctrl + C结束,执行bash ref_leak_test_end.sh。大概在10秒钟之内会打印下列信息:
[root@VM_1_72_centos ~]# bash ref_leak_test_begin.sh
net.ipv4.ip_forward = 1
nohup: 忽略输入并把输出追加到"nohup.out"
nohup: 把输出追加到"nohup.out"
nohup: 把输出追加到"nohup.out"
set mtu to 1400
nohup: 把输出追加到"nohup.out"
nohup: 把输出追加到"nohup.out"
set mtu to 1300
set mtu to 1100
set mtu to 1000
set mtu to 1400
set mtu to 1300
^C^C
[root@VM_1_72_centos ~]# bash ref_leak_test_end.sh
[root@VM_1_72_centos ~]# ip netns list
Message from syslogd@VM_1_72_centos at May 6 17:43:49 ...
kernel:unregister_netdevice: waiting for cli-veth to become free. Usage count = 1
[root@VM_1_72_centos ~]# ip netns list
[root@VM_1_72_centos ~]#
Message from syslogd@VM_1_72_centos at May 6 17:43:59 ...
kernel:unregister_netdevice: waiting for cli-veth to become free. Usage count = 1
Message from syslogd@VM_1_72_centos at May 6 17:44:09 ...
kernel:unregister_netdevice: waiting for cli-veth to become free. Usage count = 1
Message from syslogd@VM_1_72_centos at May 6 17:44:19 ...
kernel:unregister_netdevice: waiting for cli-veth to become free. Usage count = 1
Message from syslogd@VM_1_72_centos at May 6 17:44:29 ...
kernel:unregister_netdevice: waiting for cli-veth to become free. Usage count = 1现在可以复现出unregister_netdevice: waiting for XXX to become free. Usage count = 1的问题。
修复和验证:
问题修复的patch是修改内核代码net/ipv4/route.c中的下列内容:
@@ -1303,6 +1303,10 @@ static void ip_del_fnhe(struct fib_nh *nh, __be32 daddr)
if (fnhe->fnhe_daddr == daddr) {
rcu_assign_pointer(*fnhe_p, rcu_dereference_protected(
fnhe->fnhe_next, lockdep_is_held(&fnhe_lock)));
/* set fnhe_daddr to 0 to ensure it won't bind with
* new dsts in rt_bind_exception().
*/
fnhe->fnhe_daddr = 0;
fnhe_flush_routes(fnhe);
kfree_rcu(fnhe, rcu);
break;将这段补丁代码打入内核中,可参考netdev-leak.patch中,重新编译、安装内核。
再次执行上面的bash ref_leak_test_begin.sh和bash ref_leak_test_end.sh发现不会在打印unregister_netdevice: waiting for XXX to become free. Usage count = 1的日志。说明这段代码起作用了。
除了等待eth0这个问题,还有一个等待lo的类似问题,也有可能会出现。新版内核得到修复(v4.15),不过目前还没遇到这个问题。
另外对于pod terminating问题我们的内部环境上还没复现,个人觉得可参考ref_leak_test_begin.sh中的做法,在一个pod内向另一个pod发起大量的tcp连接请求进行测试。
参考
- RHEL7 and kubernetes: kernel:unregister_netdevice: waiting for eth0 to become free. Usage count = 1 - Red Hat Customer Portal
- route: set the deleted fnhe fnhe_daddr to 0 in ip_del_fnhe to fix a race · torvalds/linux@ee60ad2 · GitHub
- net: tcp: close sock if net namespace is exiting · torvalds/linux@4ee806d · GitHub
- https://github.com/kubernetes/kubernetes/issues/64743
- Try to Fix Two Linux Kernel Bugs While Testing TiDB Operator in K8s | PingCAP
- https://github.com/moby/moby/issues/5618
- GitHub - fho/docker-samba-loop: docker + scripts to reproduce a linux 4.x kernel oops
二、prometheus问题
Kubernetes集群上部署kube-prometheus套件遇到了一点小问题。
按照官方的快速指引部署到集群中后,发现没有部署custom-metrics和external-metrics服务,而正好需要使用这两个功能做自动扩缩容,因此按照该文档进行自定义部署,但是这里遇到了一些小问题。
首先按照文档中的指引,安装jb,jsonnet和gojsontoyaml这几个命令:
# 此处静态编译为了拿到任何地方都能直接用
yum install -y glibc-devel
go install -a -ldflags='-linkmode external -extldflags -static' github.com/jsonnet-bundler/jsonnet-bundler/cmd/jb@latest
go install -a github.com/google/go-jsonnet/cmd/jsonnet@latest
go install -a github.com/brancz/gojsontoyaml@latest
mkdir bin/
cp ~/go/bin/{gojsontoyaml,jsonnet,jb} bin/
export PATH=`pwd`/bin:$PATH
jb init # Creates the initial/empty `jsonnetfile.json`
jb install github.com/prometheus-operator/kube-prometheus/jsonnet/[email protected]
# jb update
# 下载对应版本的build.sh和example.jsonnet文件
$ wget https://raw.githubusercontent.com/prometheus-operator/kube-prometheus/release-0.9/example.jsonnet -O example.jsonnet
$ wget https://raw.githubusercontent.com/prometheus-operator/kube-prometheus/release-0.9/build.sh -O build.sh
# 编辑example.jsonnet,去掉被注释掉的custom metrics和external metrics部分
sh build.sh example.jsonnet
# 上面命令会重新生成manifests目录
kubectl apply -f manifests/setup
kubectl apply -f manifests遇到的问题如下:
无法获取pods的cpu指标,通过打开prometheus的日志发现,访问kubelet的10250端口没权限(应该是和集群配置有关),通过修改下面文件,将kubelet监控的https-metrics改为http-metrics,这样会访问kubelet的10250端口获取cadvisor指标。
# 将serviceMonitorKubelet监控中的https-metrics改为http-metrics
./vendor/github.com/prometheus-operator/kube-prometheus/jsonnet/kube-prometheus/components/k8s-control-plane.libsonnet获取Pod的指标无权限,因为默认生成的prometheus的clusterrole中缺少了相关权限
# 将prometheus的clusterrole增加了权限
./vendor/kube-prometheus/components/prometheus.libsonnet在example.jsonnet中可自定义镜像配置(如下),但是grafana部分使用了一个jsonnet中的std.split函数,使用“:”分割,导致生成的grafana镜像配置丢失了后面的端口和路径,目前手动修改manifests中的grafana deployment解决:
values+:: {
common+: {
namespace: 'monitoring',
images: {
alertmanager: 'mydomain.com:1234/prometheus/alertmanager:v' + $.values.common.versions.alertmanager,
blackboxExporter: 'mydomain.com:1234/prometheus/blackbox-exporter:v' + $.values.common.versions.blackboxExporter,
grafana: 'mydomain.com:1234/grafana/grafana:v' + $.values.common.versions.grafana,
kubeStateMetrics: 'hmydomain.com:1234/kube-state-metrics/kube-state-metrics:v' + $.values.common.versions.kubeStateMetrics,
nodeExporter: 'mydomain.com:1234/prometheus/node-exporter:v' + $.values.common.versions.nodeExporter,
prometheus: 'mydomain.com:1234/prometheus/prometheus:v' + $.values.common.versions.prometheus,
prometheusAdapter: 'mydomain.com:1234/prometheus-adapter/prometheus-adapter:v' + $.values.common.versions.prometheusAdapter,
prometheusOperator: 'mydomain.com:1234/prometheus-operator/prometheus-operator:v' + $.values.common.versions.prometheusOperator,
prometheusOperatorReloader: 'mydomain.com:1234/prometheus-operator/prometheus-config-reloader:v' + $.values.common.versions.prometheusOperator,
kubeRbacProxy: 'mydomain.com:1234/brancz/kube-rbac-proxy:v' + $.values.common.versions.kubeRbacProxy,
configmapReload: 'mydomain.com:1234/jimmidyson/configmap-reload:v' + $.values.common.versions.configmapReload,
},
},三、面试问题汇总
1、基础问题
1)ervice是怎么关联Pod的?
答:创建Pod是都会定义Pod的便签,比如role=frontend,Service通过Selector字段匹配该标签即可关联至该Pod,Pod和Service需要在同一个namespace,中文文档。
2)HPA V1 V2的区别
答:HPA v1为稳定版自动水平伸缩,只支持CPU指标。V2为beta版本,分为v2beta1(支持CPU、内存和自定义指标),v2beta2(支持CPU、内存、自定义指标Custom和额外指标ExternalMetrics),从k8s 1.11之后,度量指标的采集依赖metrics-server,弃用了heapster,中文文档。
3)Pod生命周期
答: Pod创建: 1. API Server 在接收到创建pod的请求之后,会根据用户提交的参数值来创建一个运行时的pod对象。 2. 根据 API Server 请求的上下文的元数据来验证两者的 namespace 是否匹配,如果不匹配则创建失败。 3. Namespace 匹配成功之后,会向 pod 对象注入一些系统数据,如果 pod 未提供 pod 的名字,则 API Server 会将 pod 的 uid 作为 pod 的名字。 4. API Server 接下来会检查 pod 对象的必需字段是否为空,如果为空,创建失败。 5. 上述准备工作完成之后会将在 etcd 中持久化这个对象,将异步调用返回结果封装成 restful.response,完成结果反馈。 6. API Server 创建过程完成,剩下的由 scheduler 和 kubelet 来完成,此时 pod 处于 pending 状态。 7. Scheduler选择出最优节点。 8. Kubelet启动该Pod。
Pod删除: 1. 用户发出删除 pod 命令 2. 将 pod 标记为“Terminating”状态 监控到 pod 对象为“Terminating”状态的同时启动 pod 关闭过程 endpoints 控制器监控到 pod 对象关闭,将pod与service匹配的 endpoints 列表中删除 Pod执行PreStop定义的内容 3. 宽限期(默认30秒)结束之后,若存在任何一个运行的进程,pod 会收到 SIGKILL 信号 4. Kubelet 请求 API Server 将此 Pod 资源宽限期设置为0从而完成删除操作。
4)Kubernetes Master节点高可用
答:Kube-APIServer为无状态服务,可以启动多个,通过负载均衡进行轮训。ControllerManager和Scheduler为有状态服务,多节点启动会进行选主,主节点信息保存在kube-system命名空间下的对应名称的endpoint中
5)QoS
答: 最高级别:Guaranteed节点资源不够时最后一个被杀掉, Burstable第二个被杀掉,BestEffort第一个被杀掉
6)flannel和calico
答:如果没有用过flannel可以直接说没有用过flannel,都是用的calico,因为calico性能强大,并且配置简单。Flannel的host-gw虽然性能好,但是只能用于大二层网络,vxlan对内核要求高,并且flannel不支持网络策略,所以采用calico。因为公司和公有云网络环境不支持BGP,所以目前采用的都是IPIP模式。
7)Helm优点
答:大型项目更加方便管理,可以一键创建一个环境,可以对整个项目进行版本升级、回滚,部署更加方便。
8)公司的架构是什么样的
答:我们的架构是这样的,三台master,三台etcd,etcd和master没有放在一起。然后在指定的节点上部署了ingress nginx,然后外部有个网关(可以选择性说网关是硬件设备F5或者DMZ的nginx,或者公有云的LB)连接到了k8s ingress节点的80和433,然后有个通配符域名指向了ingress,在ingress上面又做的分发。
2、日志监控
1)容器内日志怎么采集的
答:容器内日志我们是使用filebeat进行采集的,filebeat以sidecar的形式和业务应用运行在同一个Pod内,使用emptyDir进行日志文件的共享。
2)Fluentd
答:Fluentd配置简单,并且Docker日志一般是json输出,使用fluentd收集更加方便,当然filebeat也是可以采集节点日志的。
3)日志的索引
答:为了更快的查询日志,一般我们会根据集群、命名空间、资源名称进行添加索引。
4)etcd怎么监控的
答:etcd属于云原生应用,自带了metrics接口,可以直接请求metrics接口即可获取到监控数据,一般监控etcd的状态、leader是否正常、选择次数、选主失败次数、集群延迟、落盘延迟等。(此问题可以根据监控项自行补充)
5)黑盒监控blackbox
答:黑盒监控可以监控http、tcp的监控状态、延迟、解析速度、证书到期时间等指标。
6)状态码监控
答:可以这么回答,我们使用的是ingress,ingress也是用Prometheus监控的,可以监控到某个应用的请求状态,比如多个200、502、403等。
7)你之前是怎么监控K8S的,监控哪些指标
答:我是利用Prometheus监控的,主要是监控宿主机的指标、Pod指标,比如内存CPU使用率,是否有重启这类的。然后也使用了黑盒监控,监控应用是否是正常的等。在k8s的监控和传统架构区别不大,该监控的还要监控,可以想一下之前是怎么监控的,那在k8s里面同样也可以监控。
8)你之前是怎么收集K8S日志的,有哪些方案
答:可以回答使用filebeat进行收集的,因为filebeat比较轻量级,并且配置比较简单。同时也支持以sidecar的方式部署到Pod里面,这样同时也能收集Pod容器内的日志。一般会采用filebeat+kafka+logstash+es+kibana这种架构。
3、存储问题
1)Rook问题
答:Rook现在已经毕业了,之前虽然没有毕业,但是对ceph的支持已经是stable了,并且rook降低了ceph的学习成本,几乎不用运维,所以我们采用了Rook。使用Rook操作ceph扩容也是非常简单的,只需要更改rook创建ceph集群的资源文件即可。
2)如何对接外部CEPH
答:对接的方式有很多,使用Rook可以对接外部ceph,使用volume、pvc、storageClass和CSI插件都可以对接外部ceph。
3)生产环境的pv回收策略如何选择
答:目前pv的回收策略分为recycle、delete、retain。其中recycle(相当于对数据目录进行rm -rf /xxx/* ,进行回收的时候会创建一个Pod进行rm操作)将被官方使用动态存储供应(dynamic provisioning)逐步替代。所以面试遇到这类问题,可以着重回答delete和retain。
其中Delete回收策略一般用于动态存储,比如ceph、GFS这类的,也就是通过StorageClass进行管理创建的pv,Delete的策略也是StorageClass的默认策略,因为当一个项目用到存储时,会通过pvc或者volumeTemplateClaim申请存储,然后后端存储会自动创建pv,所以当你删除pvc或者pv时,就认为你已经不需要这个存储了,就会触发自动删除pv,防止造成存储池存储过多无人使用的垃圾pv。而静态文件建议使用Retain,比如NFS、NAS这类的,因为这些文件一般都是手动管理的,所以最好是尽量保持这些文件的可用性,就算不用了,也是可以根据目录名称进行手动删除。所以retain和delete是用的比较多的。
4)K8S持久化对接过哪些储存,为什么要选择它
答:可以写自己的实际情况,不能没有做过就胡说。比如常见的NFS和ceph,可以回答CEPH,因为ceph是比较常用的分布式存储,支持文件存储、块存储和对象存储,而且性能还是比较好的。GFS和NFS可以不说,因为GFS可能会被淘汰,NFS是单点的。
4、大厂面试题
1)介绍下工作经历,从事过哪些和K8s相关的工作
答:真是的工作要说,你在学习过程中做的一些项目或者经验都可以说一下,但是自己没有经过手的最好不要说,防止露馅。比如高可用集群搭建和维护、Prometheus监控的使用、CICD的建设等。要往自己会的方向引导。
2)主要语言是什么?平时这些项目上云有哪些注意的点
答:主要考察的是你对项目上云以及对某个语言的发版流程是否熟悉。比如Java语言是mvn编译,go语言是go build,nodejs是npm run build等。你可以说一下自己做过的容器化项目,比如Java语言的或者是nodejs。注意事项就是一个应用上云的步骤的一些细节。比如如何发版、如何回滚、如何配置QoS和健康检查等。
3)有遇到过容器的OOM的问题吗?怎么处理的?
答:遇到OOM有两种情况,第一种情况是这个程序确实需要4Gi(假设)内存,但是你的limit配置只给了3Gi,这样就会有OOM。另外一种情况是程序本身是有内存溢出的,可能没有做好垃圾回收,导致内存一直往上涨,这样的可能需要开发人员加上相应的垃圾回收,还有一种程序内存溢出是因为limit设置的太低导致不能正常的垃圾回收,比如一个程序正常运行需要3Gi,但是垃圾回收可能也需要占用内存,所以此时给3Gi肯定是不行的,一般需要超过3Gi,也就是limit配置要超过程序需求的800M-1Gi。
4)有状态应用如何上云
答:有状态应用其实也分为需要存储数据的和不需要存储数据的。如果是有需要存储数据的部署在K8s上,最好有后端可靠的存储支持,比如分布式的ceph或者公有云的存储,最极端的情况是没有后端存储支持,可以采用hostPath挂载,采用固定节点的形式,可以参考csi hostpath,或者storageClass hostPath。而有的有状态应用并不需要存储数据,只是想要有规定的标识符。
5)解析下CRD和Operator?有没有自己开发过CRD和Operator?
答:operator规范的说是operator = crd+controller,也就是operator可以理解为是一个自定义的控制器,CRD是一个自定义的资源类型,就像我们定义的deployment、service等,这些是官方自带的控制器,CRD则是扩展的资源类型。开发过就说开发过,可以讲一下如何开发的,没有开发过就说没有用到这种场景,目前还没有这个需求,因为一些中间件他们官方已经写好了operator,然后自己公司的项目一键部署使用helm管理的,因为helm比较简单(不会helm这句话不要说)。
6)什么是CNI?平时K8s集群用的是哪个网络插件?
答:CNI是k8s提出的容器网络接口,相当于一种规范,只要网络厂商的产品符合了这个规范,那么这个网络厂商的产品就能为k8s提供网络管理。常用的有calico、cilium、flannel等,可以回答说现在常用的是calico,因为他部署方便,很多大厂都在用,并且原生支持网络策略,flannel不支持网络策略。
7)为什么Pod中关于资源有request和limit两个字段?有想过这么设计的原因吗?
答:request是用于程序的最小请求,limit是用于程序的最大请求。另一方面request可以防止节点部署过多的Pod,limit可以防止拖垮节点。
8)OpenShift和K8s相比有哪些不同?
答:以我个人的理解,openshift是一个企业级的平台,包含了很多开箱即用的东西,比如可以很方便的创建一个Java应用,或者很方面的进行服务发布,他是对k8s进行了一层封装,并且提供了S2I的形式用于应用的构建和发布。而K8s是原生的下一代云计算平台,很多东西都需要自己去维护,比如你想要监控程序,就需要自己去搭建一个Prometheus或者其他的。如果大家对openshift不太熟悉,切记不能说太多openshift的东西。
9)Pod被调度到一个节点的具体过程
答:参考Pod生命周期。
10)有了解过istio吗,和springcould有什么区别
答:有过一些了解Istio是Google开源的服务网格,号称可以让开发人员无需关心流量管理方面的代码,只需要关心业务逻辑,可以提高开发效率。而springcloud是专门为Java语言设计,虽然他可以很方面实现流量管理的功能,比如灰度、熔断、负载均衡等,但是也需要开发写少量代码,并且只能Java使用,而istio和语言无关,并且不需要开发写代码。
11)在k8s Jenkins 发布详细流程
大致流程如下:
- 开发人员把做好的 knight.blog.csdn.net 项目代码通过git推送到gitlab;
- 然后Jenkins通过 gitlab webhook (前提是配置好),自动从拉取gitlab上面拉取代码下来。(作用是实现本地 git push 后 jenkins 自动构建部署服务);
- 然后进行build,编译、生成镜像、然后把镜像推送到Harbor仓库;
- 然后在部署的时候通过k8s拉取Harbor上面的代码进行创建容器和服务,最终发布完成,然后可以用外网访问;
第一阶段,获取代码(Git)
第二阶段,编译打包(Maven)
第三阶段,镜像打包与推送到仓库 (Harbor)
第四阶段,部署应用到k8s集群 (kubectl)

形象图描述如下:
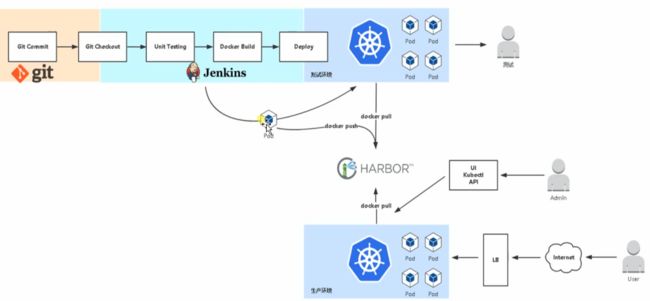
pipeline 的编写:
pipeline{
environment{
// 定义变量,或从Jenkins传入进来的变量
}
agent{
node{
// 选择 k8s 集群节点
}
}
stages{
stage('获取代码'){
steps{
// 拉取项目程序源码
}
}
stage('代码编译打包'){
steps{
container("maven") {
// 使用 maven 容器,编译打包
}
}
}
stage('镜像构建推送'){
steps{
container("kaniko") {
// 使用 kaniko 容器, docker镜像编译与推送到镜像仓库
}
}
}
stage('获取部署配置'){
steps{
// 拉取 yaml 部署文件
}
}
stage('应用部署到K8S集群') {
steps {
container('kubectl') {
// 使用 kubectl 容器, 执行 yaml 部署文件,部署应用到 k8s集群
}
}
}
}
}命令流程:
export JENKINS_HOME="/root/.jenkins/workspace/springboot-jenkins"
export JENKINS_VERSION="v0.1"
echo "JENKINS_HOME:${JENKINS_HOME},JENKINS_VERSION:${JENKINS_VERSION}"
echo "开始打包"
mvn clean
mvn package
echo "开始制作镜像"
docker build -t 你的私有Harbor地址/knight/jenkins:$JENKINS_VERSION $JENKINS_HOME
echo "开始推镜像"
docker push 你的私有Harbor地址/knight/jenkins:$JENKINS_VERSION
echo "开始运行镜像"
kubectl apply -f $JENKINS_HOME/build/jenkins-svc.yaml
# 使用envsubst传递export的参数
envsubst < $JENKINS_HOME/build/jenkins-deployment.yaml | kubectl apply -f -编写DockerFile:
# Java8镜像
FROM knight/base:latest
WORKDIR /
# 将系统编码设置为c.utf-8,默认的POSIX不支持中文
ENV LANG C.UTF-8
ENV LANGUAGE C.UTF-8
ENV LC_ALL C.UTF-8
# 将子项目打包的jar包拷贝到项目根目录
COPY target/springboot-jenkins-0.0.1-SNAPSHOT.jar /jenkins.jar
# 设置容器启动时执行的命令,-Dfile.encoding=utf-8
CMD ["java", "-jar", "jenkins.jar"]编写暴露端口的Service:
cat jenkins-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: jenkinks-service
labels:
app: jenkinks-service
spec:
type: NodePort
ports:
- port: 8888
name: jenkinks-service
targetPort: 8888
nodePort: 32088
protocol: TCP
selector:
app: jenkinks-service编写Deployment:
cat jenkins-svc.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: jenkinks-deployment
spec:
replicas: 1
selector:
matchLabels:
name: jenkinks-service
template:
metadata:
labels:
name: jenkinks-service
app: jenkinks-service
spec:
containers:
- name: jeecg
image: 你的私有Harbor地址/knight/jenkins:$JENKINS_VERSION
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8888