【读书笔记】《深入浅出图神经网络——GNN原理解析》
目录
-
- 0. 前言
- 1. 图信号处理与图卷积神经网络
-
- 1.1 图信号与图的拉普拉斯矩阵
- 1.2 傅里叶变换
- 1.3 图滤波器(Graph Filter)
- 1.4 图卷积神经网络
- 2. GCN实战
- 3. 图卷积层的数学表达
- 4. GraphSAGE
0. 前言
《深入浅出图神经网络——GNN原理解析》这本书是目前关于图神经网络的第一本中文图书。书上更多地是从数学的角度来解释GNN的原理,对程序的编写和理解更有帮助,个人觉得从数学的角度去理解更有意思。可以结合cs224w来看,cs224w是从实际的社交网络出发逐渐讲到图神经网络,两个视角结合来看比较有趣。
书中的1-4章是一些基础概念,第五章开始和图神经网络相关。
《深入浅出图神经网络:GNN原理解析》配套代码:GraphNeuralNetwork
书的链接:深入浅出图神经网络:GNN原理解析
1. 图信号处理与图卷积神经网络
第五章《图信号处理与图卷积神经网络》可以结合cs224w的Spectral Clustering(cs224w 图神经网络 学习笔记(六)Spectral Clustering 谱聚类)这节课来看。
1.1 图信号与图的拉普拉斯矩阵
书中提到的图信号处理实质上就是Node2Vec。
图信号是一种描述 V → R V \to R V→R的映射,表示成向量的形式: x = [ x 1 , x 2 , ⋯ , x N ] T {\bf{x}}=[x_1, x_2, \cdots, x_N]^T x=[x1,x2,⋯,xN]T,其中 x i x_i xi表示的是节点 v i v_i vi上的信号强度。
拉普拉斯矩是图论中的一个重要的矩阵,作为一个图的矩阵表示。其定义为 L = D − A L=D-A L=D−A,其中 D i i = ∑ j A i j D_{ii}=\sum_j A_{ij} Dii=∑jAij为图的度矩阵, A A A为图的邻接矩阵。即
L i j = { d e g ( v i ) , if i = j − 1 , if e i j ∈ E 0 , otherwise L_{ij}= \begin{cases} deg(v_i), & \text {if $i=j$} \\ -1, & \text{if $e_{ij} \in E$} \\ 0, &\text{otherwise} \end{cases} Lij=⎩⎪⎨⎪⎧deg(vi),−1,0,if i=jif eij∈Eotherwise
显然,拉普拉斯矩阵是对称的。此外,拉普拉斯矩阵还有一种正则化的形式(symmetric normalized laplacian) L s y m = D − 1 / 2 L D − 1 / 2 L_{sym}=D^{-1/2}LD^{-1/2} Lsym=D−1/2LD−1/2,元素级别的定义如下:
L s y m [ i , j ] = { 1 , if i = j − 1 d e g ( v i ) d e g ( v j , if e i j ∈ E 0 , otherwise L_{sym}[i,j]= \begin{cases} 1, & \text {if $i=j$} \\ \frac{-1}{\sqrt{deg(v_i)deg(v_j}}, & \text{if $e_{ij} \in E$} \\ 0, &\text{otherwise} \end{cases} Lsym[i,j]=⎩⎪⎪⎨⎪⎪⎧1,deg(vi)deg(vj−1,0,if i=jif eij∈Eotherwise
当涉及到信号处理或者图论的时候,就避不开拉普拉斯矩阵。拉普拉斯矩阵的定义来源于拉普拉斯算子。关于为什么拉普拉斯矩阵的定义式如上所述,以及为什么拉普拉斯矩阵常用于无向图,可以看这篇文章:【其实贼简单】拉普拉斯算子和拉普拉斯矩阵。对于一个函数,拉普拉斯算子实际上衡量了在空间中的每一点处,该函数梯度是倾向于增加还是减少。
对于图中的每个节点来说:
L x = ( D − A ) x = [ ⋯ , ∑ v j ∈ N ( v i ) ( x i − x j ) , ⋯ ] L{\bf{x}}=(D-A){\bf{x}}=[\cdots, \sum_{v_j \in N(v_i)}(x_i-x_j), \cdots] Lx=(D−A)x=[⋯,vj∈N(vi)∑(xi−xj),⋯]
也就是说,拉普拉斯矩阵式一个反映图信号局部平滑度的算子。
同时,可以定义一个重要的二次型:
T V ( x ) = x T L x = ∑ v i ∑ v j ∈ N ( v i ) x i ( x i − x j ) = ∑ e i j ∈ E ( x i − x j ) 2 TV({\bf{x}})={\bf{x}}^TL{\bf{x}}=\sum_{v_i} \sum_{v_j \in N(v_i)} x_i(x_i-x_j)=\sum_{e_{ij} \in E}(x_i-x_j)^2 TV(x)=xTLx=vi∑vj∈N(vi)∑xi(xi−xj)=eij∈E∑(xi−xj)2
称 T V ( x ) TV({\bf{x}}) TV(x)为图信号的总变差(Total Variantion),刻画的是图信号整体的平滑度。
1.2 傅里叶变换
这一部分实质上是对cs224w课程Spectral Clustering的一些从数学角度上的补充,图傅里叶变换是图谱分析的基础。
时域和频域
时域和频域是信号的基本性质。时域(Time domain)是描述数学函数或物理信号对时间的关系。频域(frequency domain)是描述信号在频率方面特性时用到的一种坐标系。相对于更加直观的时域视角,频域分析则更能体现信号的一些特征和本质。
傅里叶变换则是将信号从时域空间转换到频域空间的方法,是数字信号处理的基石。类比傅里叶变换,书中首先给出图信号傅里叶变换的定义,即将图信号由空域(spatial domain)视角转换成频域视角。在我们得到图信号(这个图信号可以看做是空域视角)的时候,我们就需要进行频域分析(我们需要切换到频域视角来观察图信号的特征),得到图的谱,进而进行谱聚类等操作。
拉普拉斯矩阵的一些性质
由于拉普拉斯矩阵是一个实对称矩阵,它可以被正交对角化表示为
L = V Λ V T = [ ⋮ ⋮ ⋯ ⋮ v 1 v 2 ⋯ v N ⋮ ⋮ ⋯ ⋮ ] [ λ 1 λ 2 ⋱ λ N ] [ ⋯ v 1 ⋯ ⋯ v 2 ⋯ ⋯ ⋮ ⋯ ⋯ v N ⋯ ] L=V \Lambda V^T=\begin{bmatrix} \vdots & \vdots & \cdots & \vdots \\ {\bf{v}}_1 & {\bf{v}}_2 & \cdots & {\bf{v}}_N \\ \vdots & \vdots & \cdots & \vdots\\ \end{bmatrix} \begin{bmatrix} \lambda_1 \\ & \lambda_2 \\ & & \ddots \\ & & & & \lambda_N\end{bmatrix} \begin{bmatrix} \cdots & {\bf{v}}_1 & \cdots \\ \cdots & {\bf{v}}_2 & \cdots \\ \cdots & \vdots & \cdots \\ \cdots & {\bf{v}}_N & \cdots \\ \end{bmatrix} L=VΛVT=⎣⎢⎢⎡⋮v1⋮⋮v2⋮⋯⋯⋯⋮vN⋮⎦⎥⎥⎤⎣⎢⎢⎡λ1λ2⋱λN⎦⎥⎥⎤⎣⎢⎢⎢⎡⋯⋯⋯⋯v1v2⋮vN⋯⋯⋯⋯⎦⎥⎥⎥⎤
其中 V V V是一个正交矩阵,即 V V T = I VV^T=I VVT=I。 V = [ v 1 , v 2 , ⋯ , v N ] V=[{\bf{v}}_1, {\bf{v}}_2, \cdots, {\bf{v}}_N] V=[v1,v2,⋯,vN]为 L L L的 N N N个特征向量,这些特征向量都是彼此之间线性无关的单位向量。 λ k \lambda_k λk表示第 k k k个特征向量对应的特征值,并对特征值进行升序排列,即 λ 1 ≤ λ 2 ≤ ⋯ ≤ λ N \lambda_1 \le \lambda_2 \le \cdots \le \lambda_N λ1≤λ2≤⋯≤λN。
同时,可以得到以下性质:
- 由于 T V ( x ) = ∑ e i j ∈ E ( x i − x j ) 2 ≥ 0 TV({\bf{x}})=\sum_{e_{ij} \in E}(x_i-x_j)^2 \ge 0 TV(x)=∑eij∈E(xi−xj)2≥0,因此拉普拉斯矩阵为半正定型矩阵,因此其所有的特征子均大于等于零。
- 由于 L x = ( D − A ) x = [ ⋯ , ∑ v j ∈ N ( v i ) ( x i − x j ) , ⋯ ] L{\bf{x}}=(D-A){\bf{x}}=[\cdots, \sum_{v_j \in N(v_i)}(x_i-x_j), \cdots] Lx=(D−A)x=[⋯,∑vj∈N(vi)(xi−xj),⋯],所以 L I = 0 LI=0 LI=0,因此拉普拉斯矩阵拥有最小的特征值0,即 λ 1 = 0 \lambda_1=0 λ1=0。
- 同时可以证明,对于 L s y m L_{sym} Lsym,其特征值存在一个上限: λ N ≤ 2 \lambda_N \le 2 λN≤2。
图傅里叶变换(Graph Fourier Transform, GFT)
定义:对于任意一个在图G上的信号 x x x,其图傅里叶变换为
x ~ k = ∑ i = 1 N V k i T x i = ⟨ v k , x ⟩ \tilde{x}_k=\sum_{i=1}^N V_{ki}^T x_i =\langle v_k, {\bf{x}} \rangle x~k=i=1∑NVkiTxi=⟨vk,x⟩
其中 v k v_k vk为拉普拉斯的第 k k k个特征向量,成为傅里叶基; x ~ k \tilde{x}_k x~k是 x {\bf{x}} x在第 k k k个傅里叶基上的傅里叶系数。本质上来说,傅里叶系数是图信号在傅里叶基上的投影,衡量了图信号与傅里叶基之间的相似度。
将上式写成矩阵形式:
x ~ = V T x , x ~ ∈ R N \tilde{{\bf{x}}}=V^T{\bf{x}},\tilde{{\bf{x}}} \in R^N x~=VTx,x~∈RN
又 V x ~ = V V T x = I x = x V\tilde{{\bf{x}}}=VV^T{\bf{x}}=I{\bf{x}}={\bf{x}} Vx~=VVTx=Ix=x,所以
x = V x ~ , x ∈ R N {\bf{x}}=V\tilde{{\bf{x}}},{\bf{x}} \in R^N x=Vx~,x∈RN
可以将上式代入到总变差 T V ( x ) TV({\bf{x}}) TV(x)的式子,得到
T V ( x ) = x T L x = x T V Λ V T x = ( V x ~ ) T V Λ V T ( V x ~ ) = x ~ T V T V Λ V T V x ~ = x ~ T Λ x ~ = ∑ k N λ k x ~ k 2 \begin{aligned} TV({\bf{x}})&={\bf{x}}^TL{\bf{x}}={\bf{x}}^T V \Lambda V^T {\bf{x}}\\ &=(V\tilde{{\bf{x}}})^T V \Lambda V^T (V\tilde{{\bf{x}}})\\ &=\tilde{{\bf{x}}}^T V^TV \Lambda V^TV \tilde{{\bf{x}}}\\ &=\tilde{{\bf{x}}}^T \Lambda \tilde{{\bf{x}}}\\ &=\sum_k^N \lambda_k \tilde{x}_k^2\\ \end{aligned} TV(x)=xTLx=xTVΛVTx=(Vx~)TVΛVT(Vx~)=x~TVTVΛVTVx~=x~TΛx~=k∑Nλkx~k2
即 T V ( x ) = ∑ k N x ~ k 2 λ k TV({\bf{x}})=\sum_k^N \tilde{x}_k^2 \lambda_k TV(x)=∑kNx~k2λk,总变差是图的所有特征值的一个线性组合,权重是图信号相对应的傅里叶系数的平方。因此,对于一个给定的图,总变差取最小值的条件是:图信号与最小的特征值 λ 1 \lambda_1 λ1所对应的特征向量 v 1 v_1 v1完全重合,此时仅有 x 1 ≠ 0 x_1 \neq 0 x1=0,其他项的傅里叶系数为0,总变差 T V ( x ) = λ 1 TV({\bf{x}})=\lambda_1 TV(x)=λ1。事实上,可以进一步证明,如果图信号 x = v k {\bf{x}}={\bf{v}}_k x=vk,则总变差 T V ( x ) = λ k TV({\bf{x}})=\lambda_k TV(x)=λk。前面提到,总变差刻画的是图信号的整体平滑度,那么将特征值依次排序,相当于对图信号的平滑度做出了一种梯度刻画,因此,可以将特征值等价成频率——特征值越低,频率越低,对应的傅里叶基变化的越缓慢,相近节点上的信号值趋于一致;特征值越高,频率越高,对应的傅里叶基就变化的越剧烈,相近节点上的信号值则非常不一致。
我们进而可以定义图信号的能量,图信号的能量可以同时从空域和频域进行等价定义:
E ( x ) = ∣ ∣ x ∣ ∣ 2 2 = x T x = ( V x ~ ) T ( V x ~ ) = x ~ T V T V x ~ = x ~ T x ~ E({\bf{x}})=||{\bf{x}}||_2^2={\bf{x}}^T{\bf{x}}=(V\tilde{{\bf{x}}})^T(V\tilde{{\bf{x}}})=\tilde{{\bf{x}}}^T V^TV \tilde{{\bf{x}}}=\tilde{{\bf{x}}}^T\tilde{{\bf{x}}} E(x)=∣∣x∣∣22=xTx=(Vx~)T(Vx~)=x~TVTVx~=x~Tx~
结合上述书上的内容,可以对维基百科中对于图傅里叶变换的定义理解的更加清楚:In mathematics, graph Fourier transform is a mathematical transform which eigendecomposes the Laplacian matrix of a graph into eigenvalues and eigenvectors. Analogously to classical Fourier Transform, the eigenvalues represent frequencies and eigenvectors form what is known as a graph Fourier basis.(从数学上看,图的傅里叶变换是对图的拉普拉斯矩阵进行频谱分析,得到特征值和特征向量。与传统的傅里叶分析类似,频谱分析得到的特征值代表频率,特征向量代表图的傅里叶基。)
那么,傅里叶系数可以看做是对应特征向量(傅里叶基)上的幅值,反映图信号在该频率分量上的强度。图信号在低频分量上的强度越大,该信号的平滑度越高;图信号在高频分量上的强度越大,该信号平滑度越低。
将图的所有傅里叶系数合在一起,就可以得到图的频谱(spectrum),这个频谱完整地描述了图信号的频域特性,就相当于是图的一种身份ID。
到这里,我们就可以更好地去理解Spectral Clustering(cs224w 图神经网络 学习笔记(六)Spectral Clustering 谱聚类)课程中的思想。
谱聚类有三个基本的步骤:
(1)Pre-processing 预处理
- Construct a matrix representation of the graph 构造图的矩阵表示
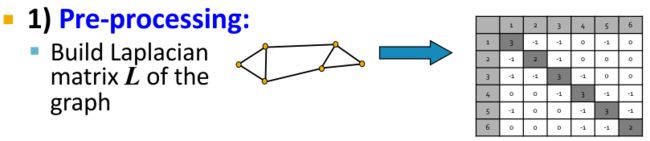
第一步就是构建拉普拉斯矩阵。
(2)Decomposition 分解
- Compute eigenvalues and eigenvectors of the matrix 计算矩阵的特征值和特征向量
- Map each point to a lower-dimensional representation based on one or more eigenvectors 将每个点映射到一个低维向量

第二步就是进行图傅里叶变换,也就是进行频谱分析,得到拉普拉斯矩阵的特征值和特征向量。
(3)Grouping 聚类
- Assign points to two or more clusters, based on the new representation 根据降维后的向量进行分组
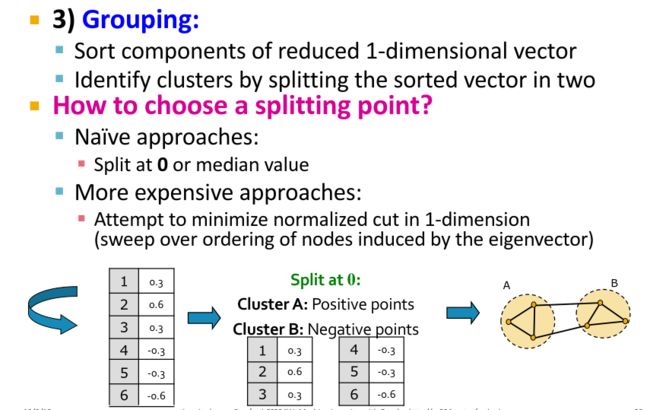
结合总变差的意义,就可以理解为什么可以选用第k个特征值对应的特征向量来作为节点的标签,然后进行聚类了。
如果图信号 x = v k {\bf{x}}={\bf{v}}_k x=vk,则总变差 T V ( x ) = λ k TV({\bf{x}})=\lambda_k TV(x)=λk。
那么,怎么确定选择第几个特征向量呢?
课程中也给出了方法——通过两个连续的特征值之间的差来确定。
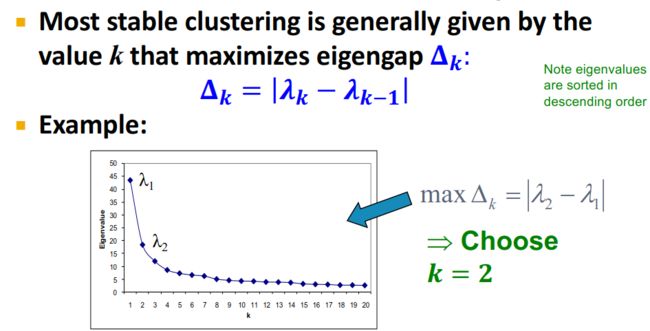
前面提到, λ \lambda λ值可以等价于频率, λ \lambda λ值越低,信号值越趋于一致——这显然不符合我们聚类的想法,聚类就是为了将信号值不一样的节点进行归类。那么,当信号值发生抖动时, λ \lambda λ值就会变大,因此,我们找到 λ \lambda λ差值最大的一组特征向量作为聚类选择的依据——这意味着图信号可能从相对一致的状态下(较小的 λ \lambda λ值对应的特征向量)发生了质变。
那么根据特征向量(图信号),就可以自然而然地进行聚类了。
1.3 图滤波器(Graph Filter)
定义:对给定图信号的频谱中各个频率分量的强度进行增强或衰减的操作。
设图滤波器为 H ∈ R N × N H \in R^{N \times N} H∈RN×N, H : R N → R N H:R^N \to R^N H:RN→RN,令输出图信号为 y {\bf{y}} y,则
y = H x = ∑ k = 1 N ( h ( λ k ) x ~ k ) v k {\bf{y}}=H{\bf{x}}=\sum_{k=1}^N(h(\lambda_k)\tilde{x}_k){\bf{v}}_k y=Hx=k=1∑N(h(λk)x~k)vk
可以看出,图滤波器实质上是通过控制 h ( λ ) h(\lambda) h(λ)项来进行增强或者衰减的。将上式写成矩阵形式
y = H x = ∑ k = 1 N ( h ( λ k ) x ~ k ) v k = [ ⋮ ⋮ ⋯ ⋮ v 1 v 2 ⋯ v N ⋮ ⋮ ⋯ ⋮ ] [ h ( λ 1 ) x ~ 1 h ( λ 2 ) x ~ 2 ⋮ h ( λ N ) x ~ N ] = V [ h ( λ 1 ) h ( λ 2 ) ⋱ h ( λ N ) ] [ x ~ 1 x ~ 2 ⋮ x ~ N ] = V [ h ( λ 1 ) h ( λ 2 ) ⋱ h ( λ N ) ] V T x \begin{aligned} {\bf{y}}&=H{\bf{x}}=\sum_{k=1}^N(h(\lambda_k)\tilde{x}_k){\bf{v}}_k\\ &=\begin{bmatrix} \vdots & \vdots & \cdots & \vdots \\ {\bf{v}}_1 & {\bf{v}}_2 & \cdots & {\bf{v}}_N \\ \vdots & \vdots & \cdots & \vdots \\ \end{bmatrix} \begin{bmatrix} h(\lambda_1)\tilde{x}_1 \\ h(\lambda_2)\tilde{x}_2 \\ \vdots \\ h(\lambda_N)\tilde{x}_N \\ \end{bmatrix}\\ &=V \begin{bmatrix} h(\lambda_1)\\ & h(\lambda_2) \\ & & \ddots \\ & & & h(\lambda_N)\\ \end{bmatrix} \begin{bmatrix} \tilde{x}_1 \\ \tilde{x}_2 \\ \vdots \\ \tilde{x}_N \\ \end{bmatrix}\\ &=V \begin{bmatrix} h(\lambda_1)\\ & h(\lambda_2) \\ & & \ddots \\ & & & h(\lambda_N)\\ \end{bmatrix} V^T {\bf{x}}\\ \end{aligned} y=Hx=k=1∑N(h(λk)x~k)vk=⎣⎢⎢⎡⋮v1⋮⋮v2⋮⋯⋯⋯⋮vN⋮⎦⎥⎥⎤⎣⎢⎢⎢⎡h(λ1)x~1h(λ2)x~2⋮h(λN)x~N⎦⎥⎥⎥⎤=V⎣⎢⎢⎡h(λ1)h(λ2)⋱h(λN)⎦⎥⎥⎤⎣⎢⎢⎢⎡x~1x~2⋮x~N⎦⎥⎥⎥⎤=V⎣⎢⎢⎡h(λ1)h(λ2)⋱h(λN)⎦⎥⎥⎤VTx
于是,得到
H = V [ h ( λ 1 ) h ( λ 2 ) ⋱ h ( λ N ) ] V T = V Λ h V T H=V \begin{bmatrix} h(\lambda_1)\\ & h(\lambda_2) \\ & & \ddots \\ & & & h(\lambda_N)\\ \end{bmatrix} V^T=V \Lambda_h V^T H=V⎣⎢⎢⎡h(λ1)h(λ2)⋱h(λN)⎦⎥⎥⎤VT=VΛhVT
相较于拉普拉斯矩阵, H H H仅仅改动了对角矩阵上的值。

图滤波器的性质
- 线性—— H ( x + y ) = H x + H y H({\bf{x}}+{\bf{y}})=H{\bf{x}}+H{\bf{y}} H(x+y)=Hx+Hy
- 顺序无关—— H 1 ( H 2 x ) = H 2 ( H 1 x ) H_1(H_2 {\bf{x}})=H_2(H_1 {\bf{x}}) H1(H2x)=H2(H1x)
- 如果 h ( λ ) ≠ 0 h(\lambda) \neq 0 h(λ)=0,则该滤波操作是可逆的。
三种滤波器
称 Λ h \Lambda_h Λh为滤波器 H H H的频率响应矩阵,对应的函数 h ( λ ) h(\lambda) h(λ)为 H H H的频率响应函数,不同的频率响应函数有不同的滤波效果。
| 低通滤波器 | 高通滤波器 | 带通滤波器 |
|---|---|---|
 |
 |
 |
| 只保留图信号中的低频部分,更关注信号中平滑的部分 | 只保留信号中的高频部分,更关注信号中快速变化的部分 | 只保留信号中特定频段的部分 |
如果我们想要实现任意性质的图滤波器,可以用泰勒展开,得到
H = h 0 L 0 + h 1 L 1 + h 2 L 2 + ⋯ + h K L K = ∑ k = 0 K h k L k H=h_0L^0 + h_1L^1 + h_2L^2 + \cdots + h_KL^K=\sum_{k=0}^K h_kL^k H=h0L0+h1L1+h2L2+⋯+hKLK=k=0∑KhkLk
其中 K K K是图滤波器 H H H的阶数。
从空域视角理解图滤波器
对于 y = H x = ∑ k = 0 K h k L k x {\bf{y}}=H{\bf{x}}=\sum_{k=0}^K h_kL^k{\bf{x}} y=Hx=∑k=0KhkLkx,若假设 x ( k ) = L k x = L x ( k − 1 ) {\bf{x}}^{(k)}=L^k{\bf{x}}=L{\bf{x}}^{(k-1)} x(k)=Lkx=Lx(k−1),那么 y = ∑ k = 0 K h k x ( k ) {\bf{y}}=\sum_{k=0}^K {\bf{h}}^k{\bf{x}}^{(k)} y=∑k=0Khkx(k),也就是说,经过滤波器操作的输出图信号编程了 ( K + 1 ) (K+1) (K+1)组图信号的线性加权。
从空域视角来看,滤波操作具有以下性质:
- 局部性——每个节点的输出信号值只需要考虑其K阶子图;
- 可以通过K步迭代式的矩阵向量乘法来完成滤波操作。
从频域视角理解图滤波器
将 L = V Λ V T L=V \Lambda V^T L=VΛVT代入 H = ∑ k = 0 K h k L k H=\sum_{k=0}^K h_kL^k H=∑k=0KhkLk,得到
H = ∑ k = 0 K h k ( V Λ V T ) k = V ( ∑ k = 0 K h k Λ k ) V T = V [ ∑ k = 0 K h k λ 1 k ⋱ ∑ k = 0 K h k λ N k ] V T \begin{aligned} H&=\sum_{k=0}^K h_k (V \Lambda V^T)^k=V (\sum_{k=0}^K h_k \Lambda^k) V^T \\ &=V \begin{bmatrix} \sum_{k=0}^K h_k \lambda_1^k \\ & \ddots \\ & & \sum_{k=0}^K\ h_k \lambda_N^k\ \end{bmatrix} V^T\\ \end{aligned} H=k=0∑Khk(VΛVT)k=V(k=0∑KhkΛk)VT=V⎣⎡∑k=0Khkλ1k⋱∑k=0K hkλNk ⎦⎤VT
那么,应用滤波器进行滤波,则 y = H x = V ( ∑ k = 0 K h k Λ k ) V T x {\bf{y}}=H{\bf{x}}=V (\sum_{k=0}^K h_k \Lambda^k) V^T {\bf{x}} y=Hx=V(∑k=0KhkΛk)VTx
由此可以得到频域视角下的滤波操作:
- 通过图傅里叶变换 V T x V^T{\bf{x}} VTx将图信号变换到频域空间
- 通过 Λ h = ∑ k = 0 K h k Λ k \Lambda_h=\sum_{k=0}^K h_k \Lambda^k Λh=∑k=0KhkΛk对频率分量的强度进行调节,得到 y ~ \tilde{{\bf{y}}} y~;
- 通过逆图傅里叶变换 V y ~ V\tilde{{\bf{y}}} Vy~将 y ~ \tilde{{\bf{y}}} y~反解成图信号 y {\bf{y}} y。
假设滤波器 H H H经过泰勒展开后的多项式系数 h h h构成向量 h {\bf{h}} h,则 H H H的频率响应矩阵为
Λ h = ∑ k = 0 K h k Λ k = d i a g ( Ψ h ) \Lambda_h=\sum_{k=0}^K h_k \Lambda^k=diag(\Psi {\bf{h}}) Λh=k=0∑KhkΛk=diag(Ψh)
其中 Ψ = [ 1 λ 1 ⋯ λ 1 K 1 λ 2 ⋯ λ 2 K ⋮ ⋮ ⋱ ⋮ 1 λ N ⋯ λ N K ] \Psi=\begin{bmatrix} 1 & \lambda_1 & \cdots &\lambda_1^K \\ 1 & \lambda_2 & \cdots & \lambda_2^K \\ \vdots & \vdots & \ddots & \vdots \\ 1 & \lambda_N & \cdots & \lambda_N^K \\\end{bmatrix} Ψ=⎣⎢⎢⎢⎡11⋮1λ1λ2⋮λN⋯⋯⋱⋯λ1Kλ2K⋮λNK⎦⎥⎥⎥⎤为范德蒙矩阵。同理可以反解得到多项式系数: h = Ψ − 1 d i a g − 1 ( Λ h ) {\bf{h}}=\Psi^{-1} diag^{-1}(\Lambda_h) h=Ψ−1diag−1(Λh)。这样一来,我们就可以设计具有特定性质的图滤波器。
从频域视角来看,图滤波操作具有以下特点:
- 从频域视角能够更加清晰地完成对图信号的特定滤波操作;
- 图滤波器如何设计具有显示的公式指导;
- 对矩阵进行特征分解的时间复杂度为 O ( N 3 ) O(N^3) O(N3),相比空域视角中的矩阵向量乘法而言,有工程上的局限性。
1.4 图卷积神经网络
图卷积运算的定义如下:
x 1 ∗ x 2 = I G F T ( G F T ( x 1 ) ⊙ G F T ( x 2 ) ) x_1*x_2=IGFT(GFT(x_1)\odot GFT(x_2)) x1∗x2=IGFT(GFT(x1)⊙GFT(x2))
其中 ⊙ \odot ⊙表示哈达玛积, G F T GFT GFT表示傅里叶变换。将 G F T ( x ) = x ~ = V T x GFT({\bf{x}})=\tilde{{\bf{x}}}=V^T{\bf{x}} GFT(x)=x~=VTx代入上式,得到
x 1 ∗ x 2 = V ( ( V T x 1 ) ⊙ ( V T x 2 ) ) = V ( x ~ 1 ⊙ ( V T x 2 ) ) = V ( d i a g ( x ~ 1 ) ( V T x 2 ) ) = ( V d i a g ( x ~ 1 ) V T ) x 2 \begin{aligned} x_1*x_2 &=V((V^T{\bf{x}}_1) \odot (V^T{\bf{x}}_2)) = V(\tilde{{\bf{x}}}_1 \odot (V^T{\bf{x}}_2))\\ &= V(diag(\tilde{{\bf{x}}}_1)(V^T{\bf{x}}_2))\\ &=(V diag(\tilde{{\bf{x}}}_1) V^T) {\bf{x}}_2\\ \end{aligned} x1∗x2=V((VTx1)⊙(VTx2))=V(x~1⊙(VTx2))=V(diag(x~1)(VTx2))=(Vdiag(x~1)VT)x2
令 H x ~ 1 = V d i a g ( x ~ 1 ) V T H_{\tilde{{\bf{x}}}_1}=V diag(\tilde{{\bf{x}}}_1) V^T Hx~1=Vdiag(x~1)VT,则 x 1 ∗ x 2 = H x ~ 1 x 2 x_1*x_2 = H_{\tilde{{\bf{x}}}_1} x_2 x1∗x2=Hx~1x2。显然, H x ~ 1 H_{\tilde{{\bf{x}}}_1} Hx~1是一个图位移算子,其频率响应矩阵为 x 1 {\bf{x}}_1 x1的频谱;也就是说,图卷积等价于图滤波。
那么,我们可以定义如下神经网络层对频率响应矩阵尽心参数化:
X ′ = σ ( V [ θ 1 θ 2 ⋱ θ N ] V T X ) = σ ( V d i a g ( θ ) V T X ) = σ ( Θ X ) \begin{aligned} X' &= \sigma (V \begin{bmatrix} \theta_1 \\ & \theta_2 \\ & & \ddots \\ & & & \theta_N \end{bmatrix} V^T X)\\ &=\sigma (V diag(\theta) V^T X) \\ &=\sigma (\Theta X) \\ \end{aligned} X′=σ(V⎣⎢⎢⎡θ1θ2⋱θN⎦⎥⎥⎤VTX)=σ(Vdiag(θ)VTX)=σ(ΘX)
其中 σ ( ⋅ ) \sigma(·) σ(⋅)是激活函数, θ = [ θ 1 , θ 2 , ⋯ , θ N ] \theta=[\theta_1, \theta_2, \cdots, \theta_N] θ=[θ1,θ2,⋯,θN]是需要学习的参数, Θ \Theta Θ是需要学习的图滤波器, X X X是输入的图信号矩阵, X ′ X' X′是输出的图信号矩阵。
从空域视角来看,定义的这个神经网络层引入了一个自适应的图位移算子;从频域视角来看,该神经网络层在 X X X和 X ′ X' X′之间训练了一个可自适应的图滤波器,其频率响应函数可以通过任务与数据之间的对应关系来进行监督学习。
不过,需要注意的是,在真实的图数据中,数据的有效信息通畅都蕴含在低频段中,因此一般会为图滤波器设置N个维度的自由度。
为了拟合任意的频率响应函数,论文Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering将拉普拉斯矩阵 V d i a g ( θ ) V T V diag(\theta) V^T Vdiag(θ)VT的多项式形式转换成一种可以学习的形式:
X ′ = σ ( V ( ∑ k = 0 K Λ k ) V T X ) = σ ( V d i a g ( Ψ θ ) V T X ) X'=\sigma(V (\sum_{k=0}^K \Lambda^k)V^T X)=\sigma (V diag(\Psi \theta) V^T X) X′=σ(V(k=0∑KΛk)VTX)=σ(Vdiag(Ψθ)VTX)
同样的, θ = [ θ 1 , θ 2 , ⋯ , θ N ] \theta=[\theta_1, \theta_2, \cdots, \theta_N] θ=[θ1,θ2,⋯,θN]是需要学习的参数;不同的是这个方法的参数量 K K K可以自由控制。 K K K越大,可拟合的频率响应函数的次数就越高,可以对应输入图信号矩阵与输出图信号矩阵之间复杂的滤波关系;反之就越简单。一般来说,会设 K < < N K << N K<<N以降低模型过拟合的风险。
为了进一步简化矩阵特征分解的计算复杂度,论文Semi-supervised classification with graph convolutional networks中限制 K = 1 K=1 K=1,则
X ′ = σ ( θ 0 X + θ 1 L X ) X'=\sigma (\theta_0 X+\theta_1LX) X′=σ(θ0X+θ1LX)
令 θ 0 = θ 1 = θ \theta_0=\theta_1=\theta θ0=θ1=θ,则
X ′ = σ ( θ ( I + L ) X ) = σ ( θ L ~ X ) X'=\sigma (\theta (I+L) X) = \sigma(\theta \tilde{L} X) X′=σ(θ(I+L)X)=σ(θL~X)
设 θ = 1 \theta=1 θ=1,则 X ′ = σ ( L ~ X ) X'=\sigma(\tilde{L} X) X′=σ(L~X),也就是说,我们可以通过一个固定的图滤波器 L ~ \tilde{L} L~,哎进行图卷积操作。
定义 L ~ s y m \tilde{L}_{sym} L~sym为重归一化形式的拉普拉斯矩阵, L ~ s y m \tilde{L}_{sym} L~sym的特征值范围为 ( − 1 , 1 ] (-1,1] (−1,1], L ~ s y m = D ~ − 1 / 2 A ~ D ~ − 1 / 2 \tilde{L}_{sym}=\tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} L~sym=D~−1/2A~D~−1/2,其中 A ~ = A + I \tilde{A}=A+I A~=A+I, D ~ i j = ∑ j A ~ i j \tilde{D}_{ij}=\sum_j \tilde{A}_{ij} D~ij=∑jA~ij。同时,定义一个参数化的权重矩阵 W W W对输入的图信号矩阵进行仿射变换,则可以得到图卷积层的数学表达,以此为主体堆叠多层的神经网络模型称为图卷积模型(GCN):
X ′ = σ ( L ~ s y m X W ) X'=\sigma (\tilde{L}_{sym}XW) X′=σ(L~symXW)
2. GCN实战
【深度学习实战】《深入浅出图神经网络》GCN实战(pytorch)
3. 图卷积层的数学表达
关于图卷积层的数学表达,结合cs224w课程中的思路,理解起来更加清晰。

X ′ = σ ( L ~ s y m X W ) X'=\sigma (\tilde{L}_{sym}XW) X′=σ(L~symXW)实质上可以看成两步,第一步 X W XW XW是对属性信息的f仿射变换,学习属性特征之间的交互模式;第二步 L ~ s y m ( X W ) \tilde{L}_{sym}(XW) L~sym(XW)是聚合邻居节点的过程,代表了对节点局部结构信息的编码。
4. GraphSAGE
实际上cs224w 图神经网络 学习笔记(九)Graph Neural Networks 图神经网络课程中提到的图神经网络模型的思想是GraphSAGE的“聚合邻居(aggregation)”的思想,从两个方面将图卷积神经网络模型 X ′ = σ ( L ~ s y m X W ) X'=\sigma (\tilde{L}_{sym}XW) X′=σ(L~symXW)进行了简化:
- 通过采用邻居的策略,将GCN由全图(full batch)的训练方式变成以节点为中心的小批量(mini batch)的方式。
- 对聚合邻居的操作提出了扩展,提出了替换GCN操作的几种新方式。
相关论文:
| 论文 | 简介 |
|---|---|
| Inductive Representation Learning on Large Graphs | 理论的提出 |
| 1. FastGCN: Fast Learning with Graph Convolutional Networks via Importance Sampling 2. Adaptive Sampling Towards Fast Graph Representation Learning 3. Stochastic Training of Graph Convolutional Networks with Variance Reduction |
GraphSAGE选择的了均匀分布,事实上根据工程效率或者数据的业务背景,我们可以采用其他形式的分布来代替。 |
| Graph Convolutional Neural Networks for Web-Scale Recommender Systems | 基于GraphSAGE的工业级大规模推荐系统的应用 |
GraphSAGE算法的计算过程完全没有拉普拉斯矩阵的参与,每个节点的特征学习过程仅仅只与其k阶邻居相关,而不需要考虑全图的结构信息。这样的方法适合做归纳学习(Inductive Learning),这是指可以对在训练阶段见不到的数据直接进行预测而不需要重新训练的学习方法——这也使得GraphSAGE有着很高的推广和应用价值。与之对应的是转导学习(Transductive Learning),指所有的数据在训练阶段都可以拿到,学习过程是作用在这个固定的数据上的,一旦数据发生改变,需要重新进行学习训练,如随机游走算法。