何向南教授团队最新综述:对话推荐系统中的进展与未来挑战

©作者|高崇铭、雷文强等
来源|社媒派SMP

背景介绍
推荐系统为工业界带来了巨大的收益。大多数推荐系统都是以静态的方式工作,即从用户历史的交互中来推测用户的兴趣爱好从而做出推荐。然而,这样的方式有缺陷,具体来说,两个较重要的问题无法被解答:1)用户目前具体喜欢什么?2)用户为什么喜欢一个商品?
对话推荐系统(Conversational Recommender Systems,CRSs)的出现,从根本上解决这个问题。其打破了传统静态的工作方式,动态地和用户进行交互,获得用户的实时反馈,进而向用户做出心仪的推荐。此外,借助自然语言的这一工具,CRSs 还可以灵活地实现一系列任务,满足用户的各种需求。
本文将总结 CRSs 中的五个任务梳理其难点。最后本文对 CRSs 未来的科研方向进行了探讨和展望。

论文标题:
Advances and Challenges in Conversational Recommender Systems: A Survey
论文链接:
https://arxiv.org/abs/2101.09459
论文作者:
高崇铭(中国科学技术大学),雷文强(新加坡国立大学),何向南(中国科学技术大学),Maarten de Rijke(荷兰阿姆斯特丹大学),Tat-Seng Chua(新加坡国立大学)
注:本文根据 tutorial [1] 深度扩展。

CRSs的定义与架构
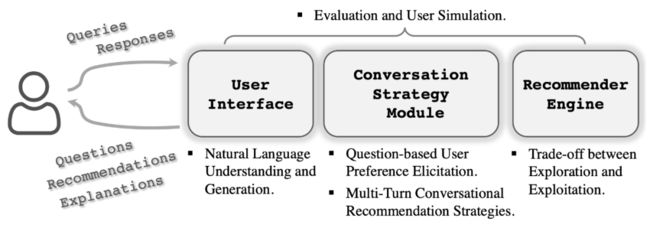
▲ 图1. CRSs的架构
目前,CRSs 还没有主流、统一的定义。本文将 CRS 定义为:能通过实时的多轮对话,探出用户的动态喜好,并采取相应措施的推荐系统(“A recommendation system that can elicit the dynamic preferences of users and take actions based on their current needs through real-time multiturn interactions using natural language.”)。
其架构可以用三个模块来组成,其中一个用户接口模块(User Interface)负责直接与用户进行交互;一个推荐引擎(Recommender Engine)负责推荐工作;还有一个最为核心的对话策略模块(Conversation Strategy Module)负责统筹整个系统的任务、决定交互的逻辑。本文总结了五个具有挑战的任务和研究方向,分别对应到这三个模块中。

CRSs的定位与作用
3.1 CRSs与传统推荐系统的区别
传统推荐系统是静态的:其从用户的历史交互信息中来估计用户偏好。而 CRSs 是动态地与用户进行交互,在模型有不确定的地方,可以主动咨询用户。故 CRSs 能解决传统推荐系统做不到的一些事儿。
一方面,传统推荐系统不能准确的估计用户目前具体喜欢什么东西(What exactly does a user like?)这是由于用户的历史记录通常很稀疏,而且充满噪声。举例来说,用户可能做出错误决策,从而购买过一个不喜欢的东西。且用户的喜好是会随着时间改变的。
另一方面,传统推荐系统不能得知为什么用户喜欢一个东西(Why does a user like an item?)举例来说,用户可能由于好奇购买一个东西,可能由于受朋友影响购买一个东西。不同理由下的购买,其喜好动机和程度都是不一样的。
受益于 CRSs 的交互能力,CRSs 能解决传统推荐系统做不到的以上两点内容。系统在不确定用户具体偏好,以及为什么产生该偏好时,直接向用户询问即可。
3.2 CRSs与交互式推荐系统的区别
交互式推荐系统可以视为 CRSs 的一种早期雏形,目前仍然有交互式推荐系统的研究。大多数交互式推荐系统,都遵循两个步骤:1)推荐一个列表;2)收集用户对于该推荐的反馈。然后往复循环这两个步骤。
然而这并不是一种好的交互模式。首先,这种交互太单调了,每轮都在循环推荐和收集反馈,很容易让用户失去耐心;其次,一个好的推荐系统应该只在其置信度比较高、信心比较充足的情况下进行推荐;最后,由于商品的数量巨大,用推荐商品的方式来了解用户的兴趣喜好,是低效的。
而 CRSs 引入了更多的交互模式。例如,其可以主动问用户问题,例如问关于商品属性的问题:“你喜欢什么样颜色的手机?”“你喜欢关于摇滚类乐曲吗?”丰富的交互模式克服了交互式推荐系统的三个问题,用更高效的方式来进行交互,从而快速获得用户的兴趣爱好,在信心比较充足的情况下,才作出推荐。
3.3 CRSs与任务型对话系统的区别
两者没有本质上的区别,然而两者在目前的实现方式和侧重点上有差异。目前,大多数任务型的对话系统,主要关注点还是自然语言处理的任务,而非检索、推荐任务。任务型对话系统也有一个对话策略(Dialog Policy)模块作为核心模块来进行任务的统筹和规划,但由于其侧重对话本身,其训练和工作方式还是以从人类的文本(训练集)中拟合特定模式为主,同时加入知识图谱等信息作为辅助,来进行监督学习式训练,最终使得系统能生成流畅合理的自然语言以回复用户以完成某一特定任务。
有学者在实验探究中发现,用基于任务型对话系统实现的对话推荐,存在一些问题 [2]。首先系统“生成”的对话,并不是真正意义上的生成,所有词汇、句子都在之前的训练文本中出现过。而且,这种方式产生的推荐,质量并不令人满意。
相比较任务型对话系统,CRSs 关注的重点并不在于语言,而是推荐的质量。CRSs 的核心任务,还是利用其交互的能力去想方设法获得用户喜好,做出高质量体检。与此同时,CRSs 的输入输出可以用基于规则的文本模版来实现。当然,这并不代表语言不重要。随着技术的的发展迭代以及学者们研究方向的重合,不同领域的差距将越来越小。

重要的研究方向
4.1 基于问题的用户偏好刺探
CRSs 的一项重要功能,是实时地向用户进行提问,以获得用户的动态偏好。这其中,各式方法可以分为两个类。一是询问商品,即收集用户对推荐商品本身的喜好;二是询问用户对商品属性的偏好,例如“你喜欢摇滚类的音乐吗?”一个基于路径推理的 CRS 示意图如下。原文表 1 总结了各种 CRSs 的工作原理。更多细节请看原文。
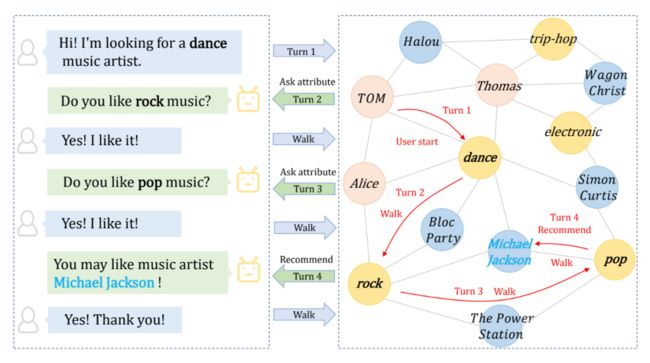
▲ 图2. 一个基于路径推理的CRS工作示意图(来源[3])

4.2 多轮对话推荐策略
CRSs 的一个核心任务是关注如何问问题,即什么时候问问题,什么时候做推荐。本文总结了集中模式,包括“问一轮推一轮”、“问 X 轮推一轮”,“问 X 轮推 Y 轮”几种方式。其中 X 和 Y 可固定或由模型决定。图 3 给出了一个“问 X 轮推 Y 轮”的 CRS 模型示意图。
除了提问以外,CRSs 也可考虑其他多轮对话策略,如加入闲聊以增加趣味,或者加入说服,协商等多样化的功能以进一步引导对话。原文表 2 总结了 CRSs 的多轮对话策略。
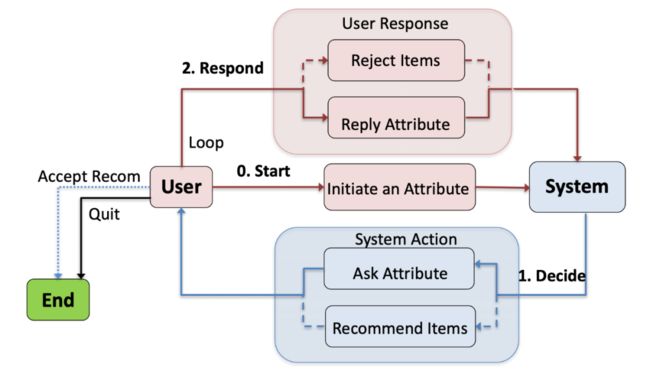
▲ 图3. CRS中的多轮对话策略示意图 (来源[4])

4.3 自然语言理解及生成
处理用户多样化的输入以及灵活的输出,也是 CRSs 中的一大挑战。目前的 CRSs 多数还是以基于提前标注的输入以及基于模版的输出为主,少数 CRSs 以对话系统的模式出发来考虑直接处理自然语言和生成自然语言。这是因为 CRSs 的主要目标还是保证推荐的质量,而非语言处理能力。原文表三总结了两个分类下的部分工作。
4.4 探索与深究之间的权衡
探索与深究是推荐系统中一个重要的研究方向,也是处理冷启动用户的一个有效手段。探索意味着去让用户尝试以往没有选择过的商品,而深究则是利用用户之前的喜好继续推荐。前者冒着用户可能不喜欢的风险,但能探索到用户一些额外的喜好;后者则安全保险,但一直陷入在已知的局部偏好中,不去改变。
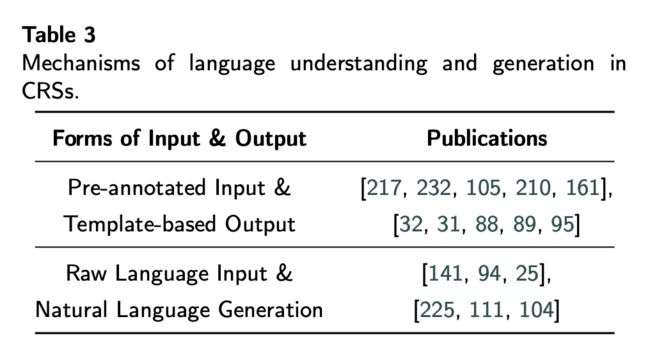
这就如同经典的多臂老虎机问题(Multi-armed Bandit, MAB),如图 4,一个赌徒可以选择多个老虎机的摇杆进行下拉。每个摇杆 下拉后的收益期望 μ 是可以根据多次实验估计出来的,但由于实验次数有限,对收益的估计存在不确定性 。若要追求全局最优点,便需要从尝试新摇杆(Exploration)与选择目前已知的高收益摇杆(Exploitation)这两者中不断交替权衡,从而达到长期的高收益。
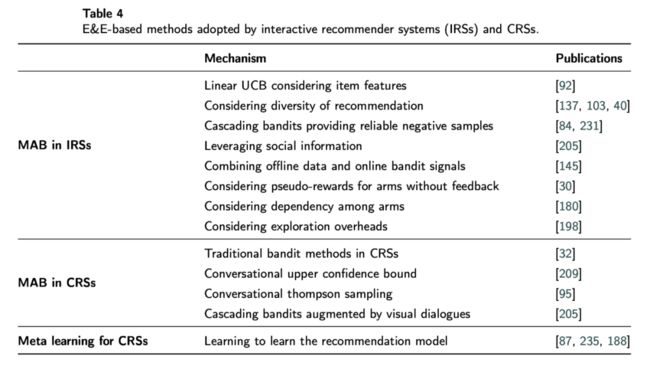
由于 CRSs 和交互式推荐系统一样,都可以实时地获得用户的反馈,于是 MAB 问题以及一系列解决方法都可以应用在 CRSs 与交互式推荐中。此外,除了经典的 MAB 算法,Meta learning 的方法也可以应用在 CRSs 中来解决冷启动或者 EE 问题。原文表 4 中列举了一些工作。
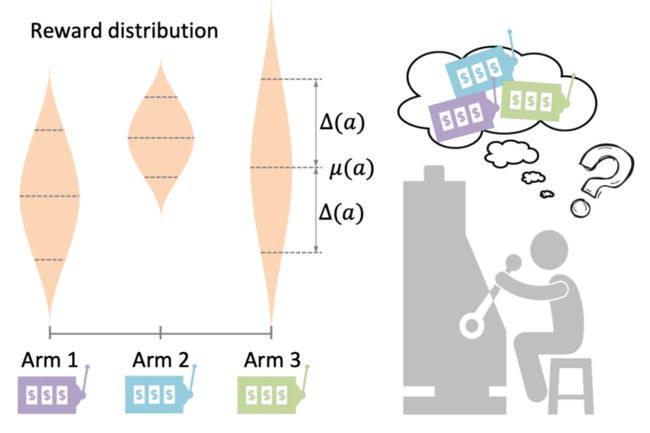
▲ 图4. 多臂老虎机问题
4.5 模型评测和用户模拟
算法评测是个很重要的问题,在 CRSs 中,由于有些算法要求文本数据,有些算法要求实时交互数据,故有工作从众包平台采集实时交互的对话数据。而有些工作则另辟蹊径,从已有的推荐数据集中造出用户模拟器(User simulators)来与 CRS 模型进行实时的交互。原文表 5 列举了目前 CRSs 中常用的数据集。
关于 CRSs 的评测指标。本文将其分为两个层级,第一个层级是每一轮级别的评测,其中值得评测的量包括推荐的质量,指标用推荐中常用的Rating-based指标,如 RMSE 或者 Ranking-based 指标,如 MAP,NDCG。另一个值得评测的量是文本生成的质量,指标包括 BLEU 与 ROUGE 等。第二个层级是对话级别的评测,主要关心的量是对话的平均轮次(Average Turns, AT),在 CRS 任务中,越早推中用户喜欢的商品越好,故对话的轮次越短越好。另外一个指标是对话在特定轮次的成功率(Success Rate@t, SR@t),该指标越高越好。
由于用户参与的交互通常很慢且难以获取,CRSs 的评测依赖用户模拟器。常用的用户模拟策略包括:
1. 从历史交互中直接模拟出用户在线的偏好,然而这种方式存在问题:历史交互通常非常稀疏,模拟出的用户无法回答那些空缺值处的喜好;
2. 先补齐用户历史交互中的空缺值,用补齐后的交互来模拟用户在线偏好。这种方式潜在的风险是补齐算法难免引入额外偏差;
3. 利用用户对商品的在线评论进行模拟。由于用户对商品的评论中包含很多可以反映用户偏好的属性信息,这种模拟方式将带来更全量的信息;
4. 从历史的人类对话文本库中模拟出用户,其适用于让 CRS 系统来模拟训练数据中的模式及语言的模型。
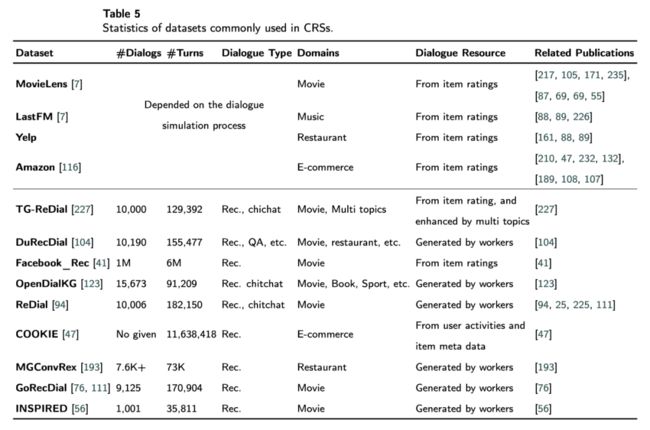

展望未来的可做方向
5.1 对CRSs的三个模块进行协同优化
CRSs 包含三个模块,用户界面、对话策略模块以及推荐引擎。很多 CRSs 的工作将它们分开进行优化。然而这三个模块在任务上是有交叉的地方,需要考虑对它们考虑协同优化。
5.2 关注CRSs中的偏差并进行去偏差
推荐偏差近年来受到研究者们很大关注,原因是观测到的数据中通常存在各式各样的偏差,例如选择性偏差,即用户倾向于选择自己更喜欢的东西进行交互,这就使得没有观测到的东西与观测到的东西有着不一样的喜好分布。因此不能简单地用观测到的东西的分布来估计空缺值。除此之外,观测数据中其他偏差,可参考另外一篇综述 [5]。虽然 CRSs 的实时交互可以部分缓解这些偏差问题,然而偏差依然会影响推荐结果。故去除 CRSs 中的偏差是一个有意义的研究方向。
5.3 设计更智能的对话策略
CRSs 最核心的部件是对话策略模块。目前已有工作考虑的策略还比较基础简单。我们可以考虑更加智能的策略,例如将强化学习的最新研究成果应用到 CRSs 的对话策略中。例如,逆强化学习可以自动的学习回报项,元强化学习可以考虑交互非常稀疏场景。
5.4 融入额外信息
让 CRSs 更加智能的一种直接的方法,便是融入更多信息。这些信息可以是商品知识图谱,也可以是多模态的信息,例如声音信息,视觉信息等。处理这些信息的相应算法已经被研究了多年,例如图卷积网络等方法,也可利用起来造福 CRSs。
5.5. 开发更好的评测方式以及模拟用户的方法
仅开发算法还不够,好的评测方法如同好的指导老师,能指引 CRSs 正确的前进方向。故研究 CRSs 的评测也意义重大。此外,由于 CRSs 的训练和评测都很依赖模拟用户,研究更加全面更加靠谱的模拟用户也是亟待解决的问题。
参考文献
[1] Wenqiang Lei, Xiangnan He, Maarten de Rijke, Tat-Seng Chua. 2020. Conversational Recommendation: Formulation, Methods, and Evaluation. SIGIR‘20 Tutorial.
[2] Dietmar Jannach and Ahtsham Manzoor. 2020. End-to-End Learning for Conversational Recommendation: A Long Way to Go? Proceedings of the 7th Joint Workshop on Interfaces and Human Decision Making for Recommender Systems co-located with 14th ACM Conference on Recommender Systems (RecSys 2020) (2020).
[3] Wenqiang Lei, Gangyi Zhang, Xiangnan He, Yisong Miao, Xiang Wang, Liang Chen, and Tat-Seng Chua. 2020. Interactive Path Reasoning on Graph for Conversational Recommendation. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’20). 2073–2083.
[4] Wenqiang Lei, Xiangnan He, Yisong Miao, Qingyun Wu, Richang Hong, Min-Yen Kan, and Tat-Seng Chua. 2020. Estimation-Action-Reflection: Towards Deep Interaction Between Conversational and Recommender Systems. In Proceedings of the 13th International Conference on Web Search and Data Mining (WSDM’20). ACM, 304–312.
[5] Jiawei Chen, Hande Dong, Xiang Wang, Fuli Feng, Meng Wang, and Xiangnan He. 2020. Bias and Debias in Recommender System: A Survey and Future Directions. arXiv preprint arXiv:2010.03240 (2020).
关于作者

高崇铭,中国科学技术大学博士研究生。本科与硕士毕业于电子科技大学计算机专业,致力于信息检索、数据挖掘以及推荐系统的前沿研究。曾获得 DASFAA’19(CCF B)最佳论文奖。

雷文强,新加坡国立大学博士后。博士毕业于新加坡国立大学,本科毕业于华东师大,是华东师大极少数三年半拿到学士学位的毕业生。研究兴趣在于自然语言处理以及信息检索,特别是篇章语义,对话系统以及 human-in-the-loop 技术。在各大顶级会议和期刊发表 20 余篇,包括国际顶级会议 KDD,ACL,MM,EMNLP,AAAI,IJCAI 和顶级期刊 TOIS 等。其中担任通讯作者的论文获得 CCF A 类会议 ACM MM 2020 最佳论文奖。他担任 2020 届新加坡全国自然语言处理会议 SSNLP 2020 的程序委员会共同主席,并长期担任各大 CCF A 类会议会议的(高级)程序会员会委员以及 CCF A 类期刊的审稿人。最近,他与信息检索领域几位活跃的学者一起在 SIGIR 2020,CCL 2020,CCIR 2020 作了关于题为 Conversational Recommendation: Formulation 的 tutorial。

何向南,中国科学技术大学教授,大数据学院副院长。博士毕业于新加坡国立大学计算机科学专业,致力于信息检索、数据挖掘和机器学习等人工智能领域前沿研究,取得了丰硕的研究成果。在 CCF A 类会议和期刊发表论文 90 余篇,谷歌学术引用近 9000 次,包括国际顶级会议 SIGIR、WWW、KDD 和顶级期刊 TKDE、TOIS、TNNLS 等。长期担任这些会议和期刊的审稿人,以及 CCIS 2019(云计算与智能系统IEEE国际会议)的程序委员会主席,AI Open 期刊编委。研究成果曾获 SIGIR 2016 最佳论文提名奖、WWW 2018 最佳论文提名奖、WWW 2018 最佳海报论文奖等,并在多个商业公司的线上系统获得应用,取得积极效果。
.png")
Maarten de Rijke,荷兰皇家艺术与科学院院士,荷兰国家人工智能创新中心主任、荷兰阿姆斯特丹大学教授。发表论文 900 余篇,h 因子 77,谷歌学术引用近 28000 次。主要研究领域包括自然语言处理、信息检索、知识挖掘等。多次担任信息检索领域重要会议的程序委员会主席,包括 SIGIR, WSDM, WWW, CIKM, ECIR, ICTIR 等,同时担任人工智能领域顶级期刊的主编。并于 2017 年获得代表国际信息检索领域终身成就的 Tony Kent Strix 等奖项。

Tat-Seng Chua,新加坡国立大学计算机学院创始院长,清华大学访问教授,新加坡国立大学与清华大学联合研究中心(NExT)主任。h 因子 90,谷歌学术引用超过 33000 次。研究方向包括非结构化数据分析,多媒体信息检索,推荐系统与对话系统等。其担任多个国际顶级会议会议的联合主席,包括 MM 2005, CIVR 2005, SIGIR 2008 以及 WebSci 2015 等,同时是多个期刊的编委会成员。
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

