【数据结构与算法】【C】 - 有头循环双向链表(重点)
作者:傻响
专栏:《数据结构与算法》
格言:你只管努力,剩下的交给时间!

目录
一,数据结构概述
1.1什么是数据结构?
1.2数据结构分类
1.3数据结构术语
二、线性表
三、链表的分类
1:单向或者双向链表
2:带头或不带头链表
3:循环非循环链表
(二)、带头双向循环链表的实现(重点)
1.1 带头双向循环链表中数据元素的构成
1.2 带头双向循环链表初始化函数
1.3 带头双向循环链表开辟节点空间函数
1.4 带头双向循环链表打印函数
1.5 带头双向循环链表尾插函数
1.6 带头双向循环链表头插函数
1.7 带头双向循环判断链表是否为空函数
1.8 带头双向循环链表尾删函数
1.9 带头双向循环链表头删函数
2.0 带头双向循环链表统计链表节点个数函数
2.1 带头双向循环链表查找节点函数
2.2 带头双向循环链表任意节点之前插函数
2.3 带头双向循环链表任意节点之前删函数
2.4 带头双向循环链表内存销毁函数
2.5 有了Insert和Erase函数替代 - 头尾插/头尾删
一,数据结构概述
1.1什么是数据结构?
官方解释:
数据结构是一门研究非数值计算的程序设计问题中的操作对象,以及他们之间的关系和操作等相关问题的学科
大白话:
数据结构就是把数据元素按照一定的关系组织起来的集合,用来组织和存储数据
1.2数据结构分类
传统上,我们可以把数据结构分为逻辑结构和物理结构两大类。
逻辑结构分类:
逻辑结构是从具体问题中抽象出来的模型,是抽象意义上的结构,按照对象中数据元素之间的相互关系分类,也是我们后面课题中需要关注和讨论的问题。
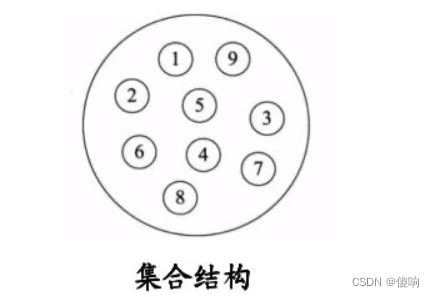
a,集合结构:结合结构中数据元素出了属于同一集合外,他们之间没有任何其他关系
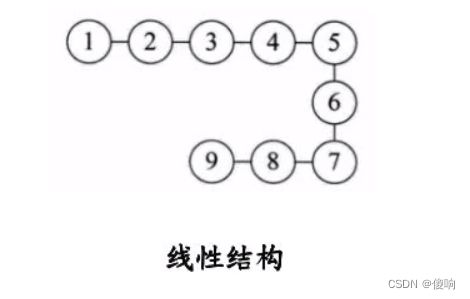
b,线性结构:线性结构中的数据元素之间存在一对一的关系
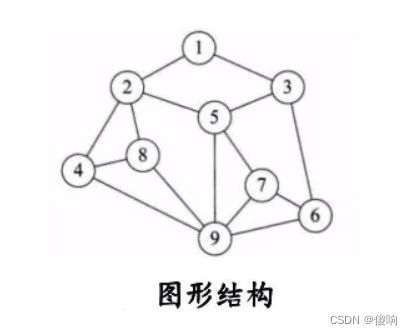
c,树形结构:树形结构中的数据元素之间存在多对一的层次关系

d,图形结构:图形结构的数据元素是多对多的关系
物理结构分类:
逻辑结构在计算机中真正的表示方式(又称映像)称为物理结构,也可以叫做存储结构,常见的物理结构有顺序存储结构、链式存储结构。
顺序存储结构
把数据元素放到地址连续的内存单元里面,其数据间的逻辑关系和物理关系是一致的,比如我们常用的数组就是顺序存储结构。

顺序存储结构存在一定的弊端,就想生活中排队时,会有人插队也有可能有人突然离开,这时候整个结构都处于变化之中,此时就需要链式存储结构。
链式存储结构
是把数据元素存放在任意的存储单元里面,这组存储单元可以是连续的,也可以是不连续的。此时,数据元素之间的关系,并不能反映元素间的逻辑关系,因此链式存储中引进了一个指针存放数据元素的地址,这样通过地址就可以找到相关联数据元素的位置。
1.3数据结构术语
抽象数据类型:(Abstract Data Type,简称ADT)是指一个数学模型以及定义在该模型上的一组操作。抽象数据类型的定义仅取决于它的一组逻辑特性,而与其在计算机内部如何表示和实现无关,即不论其内部结构如何变化,只要它的数学特性不变,都不影响其外部的使用。
抽象数据类型和数据类型实质上是一个概念。例如,各个计算机都拥有的“整数”类型是一个抽象数据类型,尽管它们在不同处理器上实现的方法可以不同,但由于其定义的数学特性相同,在用户看来都是相同的。因此,“抽象”的意义在于数据类型的数学抽象特性。
数据结构的表示(存储结构)用类型定义( typedef)描述。数据元素类型约定为Data。
二、线性表
线性结构的特点是:在数据元素的非空有限集合中
-
存在唯一的一个被称为"第一个"的数据元素
-
存在唯一的一个被称为“最后一个”的数据元素
-
除了第一个之外,结合中的每个数据元素均只有一个前驱
-
除了最后一个之外,集合中每个数据元素均只有一个后继
顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存 储。在数组上完成数据的增删查改。
线性表示一个相当灵活的数据结构,它的长度可以根据需要增长或缩短,即对线性表的数据元素不仅可以进行访问,还可以进行插入和删除等。
1.2 链表
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
链表是指逻辑结构上一个挨一个的数据,在实际存储时,并没有像顺序表那样也相互紧挨着。恰恰相反,数据随机分布在内存中的各个位置。
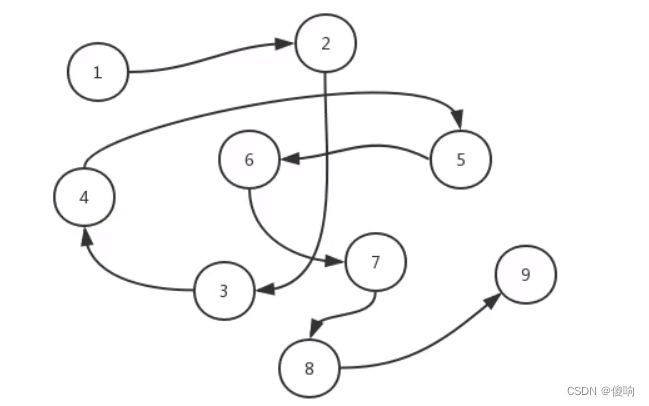
由于分散存储,为了能够体现出数据元素之间的逻辑关系,每个数据元素在存储的同时,要配备一个指针,用于指向它的直接后继元素,即每一个数据元素都指向下一个数据元素(最后一个指向NULL(空))。

如图所示,当每一个数据元素都和它下一个数据元素用指针链接在一起时,就形成了一个链,这个链子的头就位于第一个数据元素,这样的存储方式就是链式存储。
三、链表的分类
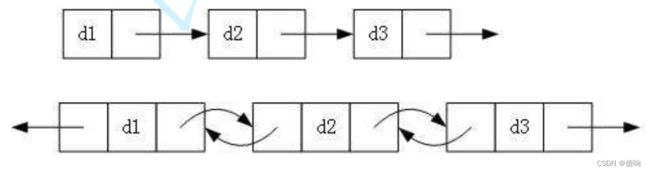
1:单向或者双向链表
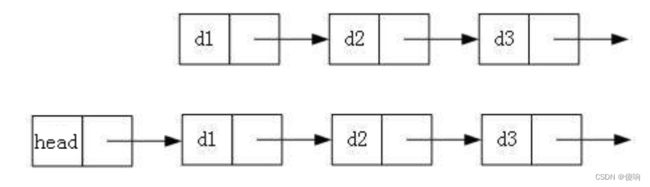
2:带头或不带头链表
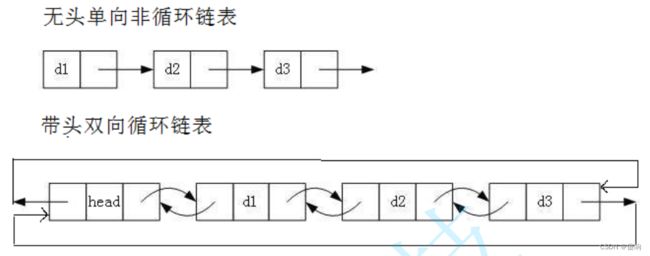
3:循环非循环链表

虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:
-
无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结 构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
-
带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都 是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带 来很多优势,实现反而简单了,后面我们代码实现了就知道了。
(二)、带头双向循环链表的实现(重点)
先看一下双向链表的结构问题:
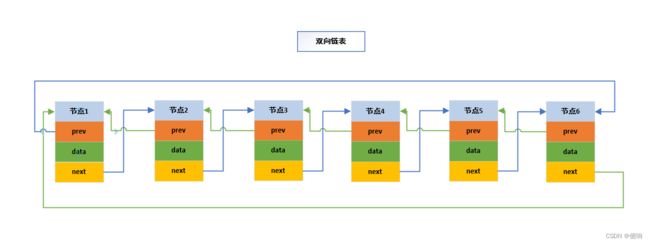
1.1 带头双向循环链表中数据元素的构成
链表中存放的不是基本数据类型,需要用结构体实现自定义:
// 双向带头循环链表中数据元素的构成
typedef int DLDataType;
typedef struct DListNode
{
DLDataType data; // 数据存储区、
struct DListNode* prev; // 记录上一个节点。
struct DListNode* next; // 记录下一个节点。
}DListNode;
// 双向带头循环链表 - 初始化函数声明。
DListNode* DListInit();
// 双向带头循环链表 - 开辟节点函数声明。
DListNode* BuyDListNode(DLDataType val);
// 双向带头循环链表 - 内存销毁函数声明。
void DListDestory(DListNode* pHead);
// 双向带头循环链表 - 尾插函数声明。
void DListPushBack(DListNode* pHead, DLDataType val);
// 双向带头循环链表 - 头插函数声明。
void DListPushFront(DListNode* pHead, DLDataType val);
// 双向带头循环链表 - 尾删函数声明。
void DListPopBack(DListNode* pHead);
// 双向带头循环链表 - 头删函数声明。
void DListPopFront(DListNode* pHead);
// 双向带头循环链表 - 在任意位置前插函数声明。
void DListInsert(DListNode* pos, DLDataType val);
// 双向带头循环链表 - 在任意位置前删函数声明。
void DListErase(DListNode* pos);
// 双向带头循环链表 - 打印函数声明。
void DListPrint(DListNode* pHead);
// 双向带头循环链表 - 判断链表是否为空函声明。
bool DListEmpty(DListNode* pHead);
// 双向带头循环链表 - 统计节点个数空函数声明。
size_t DListSize(DListNode* pHead);
// 双向带头循环链表 - 查找节点函数声明。
DListNode* DListFind(DListNode* pHead, DLDataType val);1.2 带头双向循环链表初始化函数
链表初始化是头节点:下面是刚初始化出来的头节点结构->
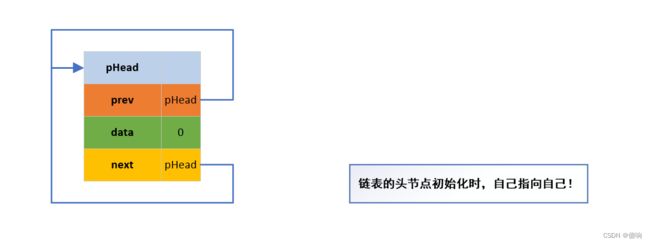
// 双向带头循环链表。
DListNode* ListInit()
{
DListNode* newNode = (DListNode*)malloc(sizeof(DListNode));
// 判断是否开辟内存空间成功。
if (newNode == NULL)
{
perror("ListInit malloc fail!");
exit(-1);
}
// 程序走到这里说明开辟空间成功了。
newNode->prev = newNode;
newNode->next = newNode;
newNode->data = 0;
return newNode;
}1.3 带头双向循环链表开辟节点空间函数
开辟空间和初始化的区别不大,这里就不说了。
DListNode* BuyDListNode(DLDataType val)
{
DListNode* newNode = (DListNode*)malloc(sizeof(DListNode));
// 判断是否开辟内存空间成功。
if (newNode == NULL)
{
perror("ListInit malloc fail!");
exit(-1);
}
// 程序走到这里说明开辟空间成功了。
newNode->prev = NULL;
newNode->next = NULL;
newNode->data = val;
return newNode;
}1.4 带头双向循环链表打印函数
打印函数和之前单链表的区别那大,这里就不说了,唯独要去别的一点是,不能判断NULL结束。
// 双向带头循环链表 - 打印函数。
void DListPrint(DListNode* pHead)
{
// 断言保护形参指针不为空。
assert(pHead);
// 打印一个头作为标志。
printf("pHead");
// 遍历节点打印数据
DListNode* pBegin = pHead->next;
while (pBegin != pHead)
{
printf("<-%d->",pBegin->data);
pBegin = pBegin->next;
}
printf("pHead");
printf("\n");
}1.5 带头双向循环链表尾插函数
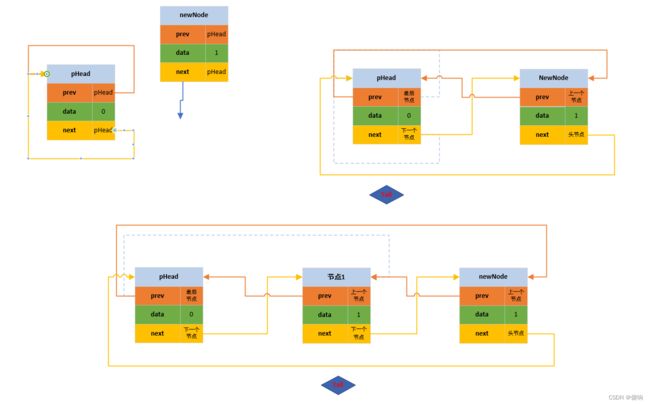
// 双向带头循环链表 - 尾插函数。
void DListPushBack(DListNode* pHead, DLDataType val)
{
// 断言保护形参指针不为空。
assert(pHead);
// 开辟新的节点空间。
DListNode* newNode = BuyDListNode(val);
// 链接链表 - 指针交换。
DListNode* pTail = pHead->prev;
pTail->next = newNode;
newNode->next = pHead;
newNode->prev = pTail;
pHead->prev = newNode;
}1.6 带头双向循环链表头插函数
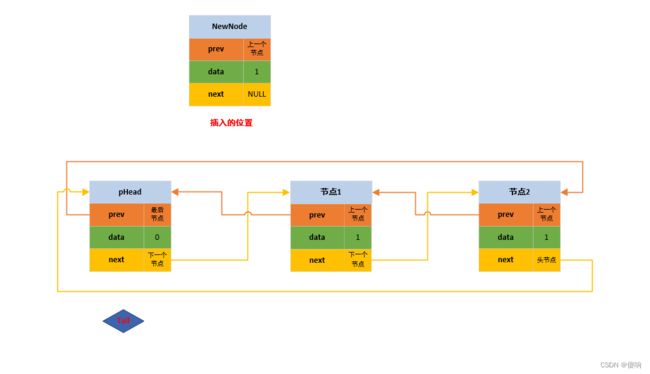
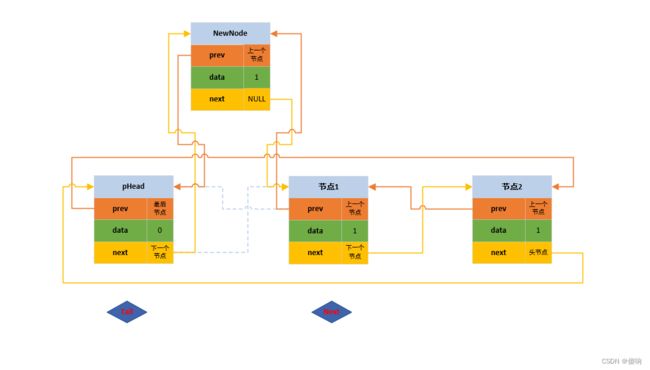
// 双向带头循环链表 - 头插函数。
void DListPushFront(DListNode* pHead, DLDataType val)
{
// 断言保护形参指针不为空。
assert(pHead);
// 开辟新的节点空间。
DListNode* newNode = BuyDListNode(val);
// 链接链表 - 指针交换。
DListNode* next = pHead->next;
pHead->next = newNode;
newNode->prev = pHead;
newNode->next = next;
next->prev = newNode;
}1.7 带头双向循环判断链表是否为空函数
此函数是为了协助判断双向链表是否为空的。
// 双向带头循环链表 - 判断链表是否为空函数。
bool DListEmpty(DListNode* pHead)
{
assert(pHead);
// 判断链表是不是NULL链表。
return pHead->next == pHead;
}1.8 带头双向循环链表尾删函数
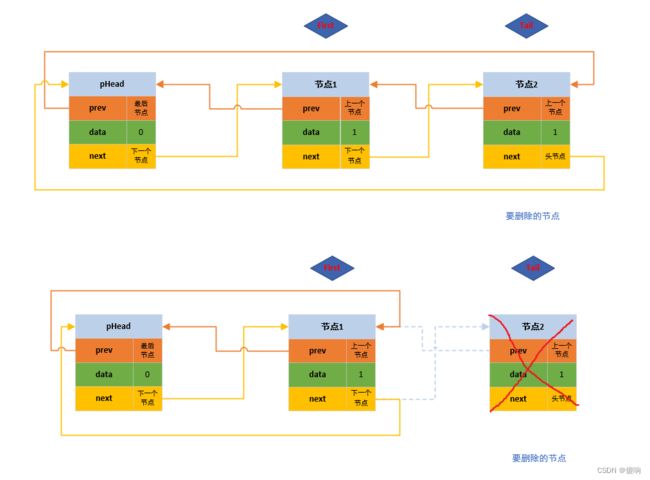
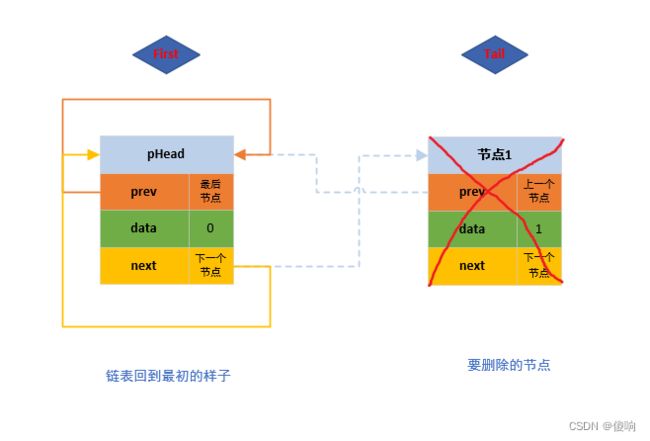
// 双向带头循环链表 - 尾删函数。
void DListPopBack(DListNode* pHead)
{
// 断言保护形参指针不为空,判断链表不为空。
assert(pHead);
assert(!DListEmpty(pHead));
DListNode* pTail = pHead->prev;
DListNode* pFirst = pTail->prev;
// 修改链接。
pHead->prev = pFirst;
pFirst->next = pHead;
// 释放掉保留的最后一个节点。
free(pTail);
pTail = NULL;
}1.9 带头双向循环链表头删函数
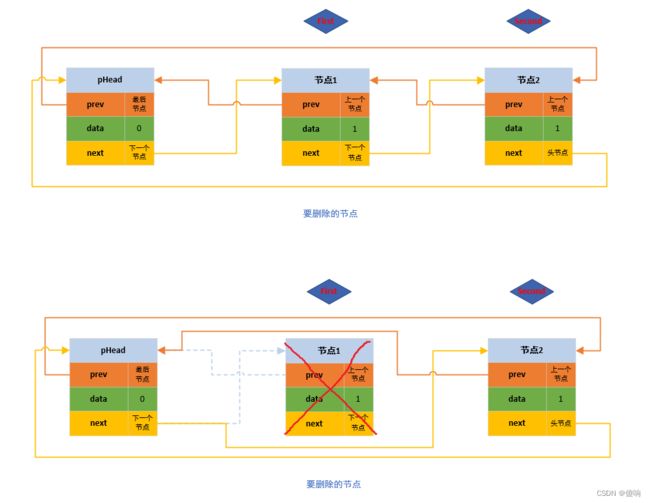

// 双向带头循环链表 - 头删函数。
void DListPopFront(DListNode* pHead)
{
// 断言保护形参指针不为空,判断链表不为空。
assert(pHead);
assert(!DListEmpty(pHead));
DListNode* pFirst = pHead->next;
DListNode* pSecond = pFirst->next;
// 修改链接。
pHead->next = pSecond;
pSecond->prev = pHead;
// 释放掉保留的最后一个节点。
free(pFirst);
pFirst = NULL;
}2.0 带头双向循环链表统计链表节点个数函数
函数比较简单,这里就不进行解释了。
// 双向带头循环链表 - 统计节点个数空函数。
size_t DListSize(DListNode* pHead)
{
// 断言保护形参指针不为空。
assert(pHead);
// 遍历所有节点统计大小
DListNode* pBegin = pHead->next;
size_t count = 0;
while (pBegin != pHead)
{
count++;
pBegin = pBegin->next;
}
// 返回个数
return count;
}2.1 带头双向循环链表查找节点函数
函数比较简单,这里就不进行解释了,查找就等于修改。
// 双向带头循环链表 - 查找节点函数。
DListNode* DListFind(DListNode* pHead, DLDataType val)
{
// 断言保护形参指针不为空。
assert(pHead);
// 遍历所有节点统计大小
DListNode* pBegin = pHead->next;
while (pBegin != pHead)
{
if (pBegin->data == val)
{
return pBegin;
}
pBegin = pBegin->next;
}
// 返回NULL
return NULL;
}2.2 带头双向循环链表任意节点之前插函数
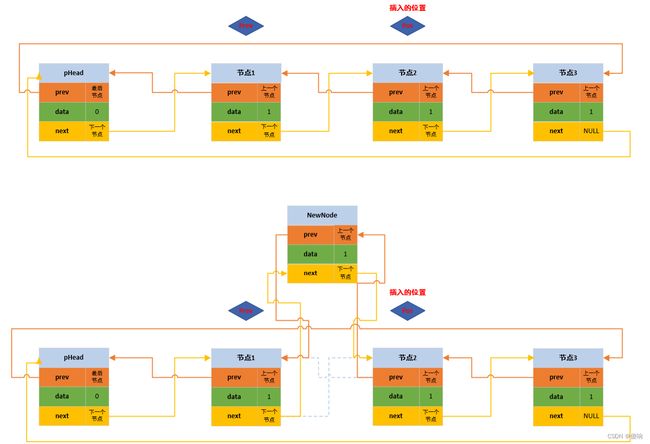
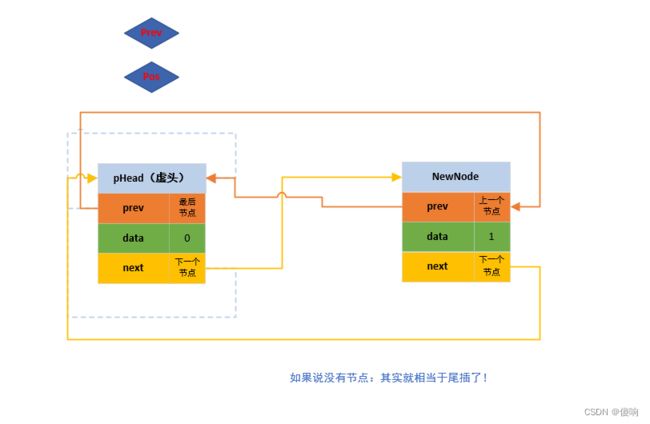
// 双向带头循环链表 - 在任意位置前插函数声明。
void DListInsert(DListNode* pos, DLDataType val)
{
// 断言保护形参指针不为空。
assert(pos);
// 定位置和开辟新节点。
DListNode* prev = pos->prev;
DListNode* newNode = BuyDListNode(val);
// 链接
prev->next = newNode;
newNode->prev = prev;
newNode->next = pos;
pos->prev = newNode;
}2.3 带头双向循环链表任意节点之前删函数
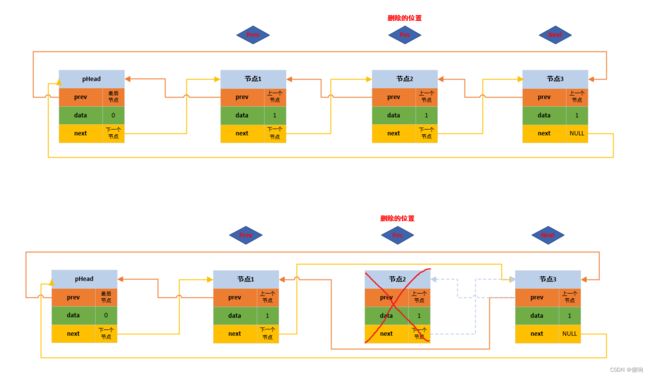
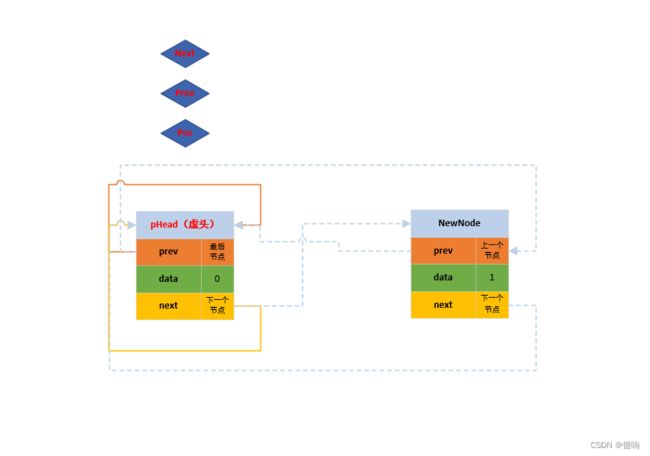
// 双向带头循环链表 - 在任意位置前删函数声明。
void DListErase(DListNode* pos)
{
// 断言保护形参指针不为空。
assert(pos);
// 定位置
DListNode* prev = pos->prev;
DListNode* next = pos->next;
// 链接
prev->next = next;
next->prev = prev;
//销毁pos节点
free(pos);
pos = NULL;
}2.4 带头双向循环链表内存销毁函数
带头双向循环链表的销毁函数,和单向的函数思想是一样的,从头开始遍历,最后消除头。

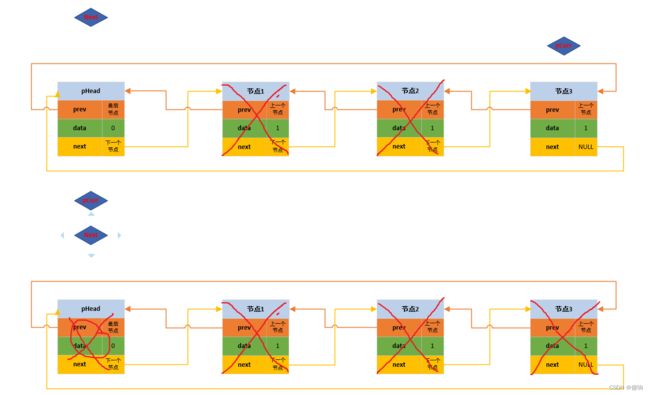
// 双向带头循环链表 - 内存销毁函数声明。
void DListDestory(DListNode* pHead)
{
// 断言保护形参指针不为空。
assert(pHead);
// 遍历一个一个的进行销毁。
DListNode* pBegin = pHead->next;
while (pBegin != pHead)
{
DListNode* next = pBegin->next;
free(pBegin);
pBegin = NULL;
// 迭代
pBegin = next;
}
// 其实这里是无效的,因为传递的是一级指针,外部调用完进行置NULL;
pHead = NULL;
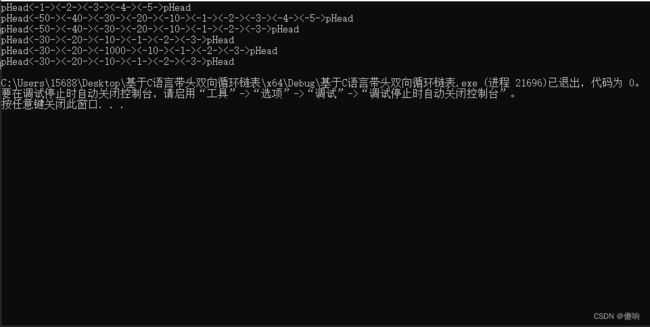
}到这里我们可以看一下测试结果:
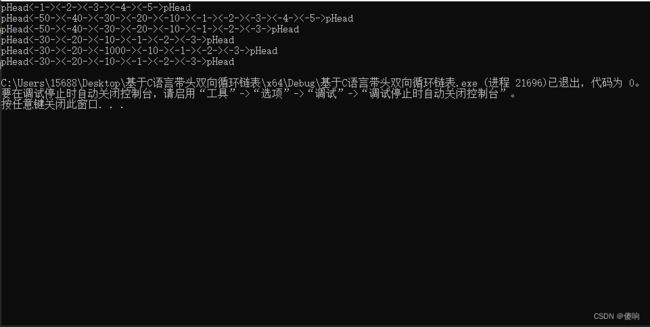
Main函数调用代码:
void TextDList()
{
DListNode* pDList = DListInit();
// 双链表尾插
DListPushBack(pDList, 1);
DListPushBack(pDList, 2);
DListPushBack(pDList, 3);
DListPushBack(pDList, 4);
DListPushBack(pDList, 5);
DListPrint(pDList);
// 双链表头插
DListPushFront(pDList, 10);
DListPushFront(pDList, 20);
DListPushFront(pDList, 30);
DListPushFront(pDList, 40);
DListPushFront(pDList, 50);
DListPrint(pDList);
// 双链表尾删
DListPopBack(pDList);
DListPopBack(pDList);
DListPrint(pDList);
// 双链表头删
DListPopFront(pDList);
DListPopFront(pDList);
DListPrint(pDList);
// 双链表任意位置前插入
DListNode* pos = DListFind(pDList, 10);
DListInsert(pos, 1000);
DListPrint(pDList);
// 双链表任意位置前删除
pos = DListFind(pDList, 1000);
DListErase(pos);
DListPrint(pDList);
DListDestory(pDList);
pDList = NULL;
}
2.5 有了Insert和Erase函数替代 - 头尾插/头尾删
其实Insert和Erase就可实现所有的插删功能了 ,上面写出来也是为了练手,接下来代码改造一下试一下效果。
尾插
// 双向带头循环链表 - 尾插函数。
void DListPushBack(DListNode* pHead, DLDataType val)
{
// 断言保护形参指针不为空。
assert(pHead);
/*
// 开辟新的节点空间。
DListNode* newNode = BuyDListNode(val);
// 链接链表 - 指针交换。
DListNode* pTail = pHead->prev;
pTail->next = newNode;
newNode->next = pHead;
newNode->prev = pTail;
pHead->prev = newNode;
*/
DListInsert(pHead, val);
}头插
// 双向带头循环链表 - 头插函数。
void DListPushFront(DListNode* pHead, DLDataType val)
{
// 断言保护形参指针不为空。
assert(pHead);
/*
// 开辟新的节点空间。
DListNode* newNode = BuyDListNode(val);
// 链接链表 - 指针交换。
DListNode* next = pHead->next;
pHead->next = newNode;
newNode->prev = pHead;
newNode->next = next;
next->prev = newNode;
*/
DListInsert(pHead->next, val);
}尾删
// 双向带头循环链表 - 尾删函数。
void DListPopBack(DListNode* pHead)
{
// 断言保护形参指针不为空,判断链表不为空。
assert(pHead);
assert(!DListEmpty(pHead));
/*
DListNode* pTail = pHead->prev;
DListNode* pFirst = pTail->prev;
// 修改链接。
pHead->prev = pFirst;
pFirst->next = pHead;
// 释放掉保留的最后一个节点。
free(pTail);
pTail = NULL;
*/
DListErase(pHead->prev);
}头删
// 双向带头循环链表 - 头删函数。
void DListPopFront(DListNode* pHead)
{
// 断言保护形参指针不为空,判断链表不为空。
assert(pHead);
assert(!DListEmpty(pHead));
/*
DListNode* pFirst = pHead->next;
DListNode* pSecond = pFirst->next;
// 修改链接。
pHead->next = pSecond;
pSecond->prev = pHead;
// 释放掉保留的最后一个节点。
free(pFirst);
pFirst = NULL;
*/
DListErase(pHead->next);
}测试效果