时间序列是由表示时间的x轴和表示数据值的y轴组成,使用折线图在显示数据随时间推移的进展时很常见。它在提取诸如趋势和季节性影响等信息方面有一些好处。
但是在处理超长的时间轴时有一个问题。尽管使用数据可视化工具可以很容易地将长时间序列数据拟合到绘图区域中,但结果可能会很混乱。让我们比较一下下面的两个示例。
上图显示了2021年的每日温度数据
上图像显示了1990-2021年的每日温度数据
虽然我们可以在第一张图上看到细节,但第二张图由于包含了很长的时间序列数据,所以无法看到细节,一些有重要的数据点可能会被隐藏。
为了解决这个问题,本文将介绍6种简单的技巧,帮助更有效地呈现长时间序列数据。
获取数据
本文将使用都柏林机场每日数据,包含自1942年以来在都柏林机场测量的气象数据。数据集包含每日天气信息,如温度、风速、气压等。
导入必要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import plotly.graph_objects as go
%matplotlib inline读取CSV文件
df = pd.read_csv('location/file name.csv')
df['date'] = pd.to_datetime(df['date'])
df.tail()df.info()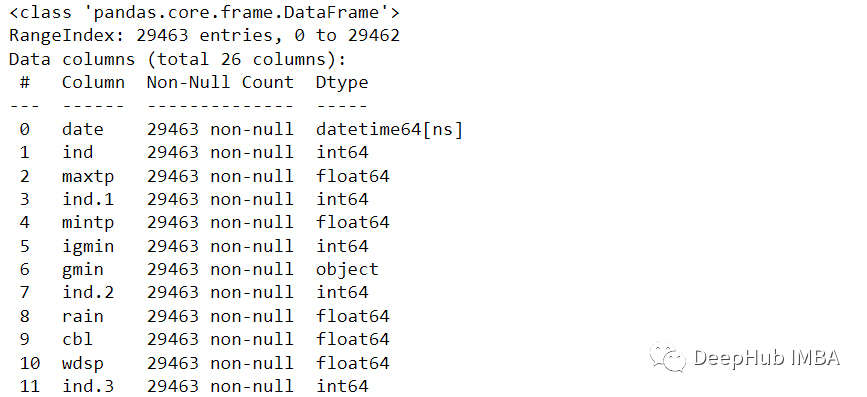
一个好消息是数据集没有缺失值。
准备数据
这里使用最高和最低温度数据。所用的时间是从1990年到2021年,总共32年。如果想选择其他变量或范围,请随意修改下面的代码。
start = pd.Timestamp('1990-01-01')
end = pd.Timestamp('2021-12-31')
df_temp = df[(df['date']>=start)&(df['date']<=end)][['date','maxtp','mintp']]
df_temp.reset_index(drop=True, inplace=True)
#create an average temperature column
df_temp['meantp'] = [(i+j)/2 for i,j in zip(df_temp.maxtp, df_temp.mintp)]
df_temp.head()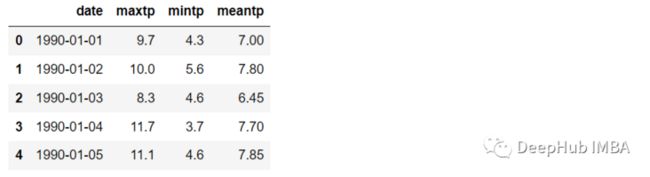
创建一些以后使用的日期特征。
df_temp['month'] = pd.DatetimeIndex(df_temp['date']).month
df_temp['year'] = pd.DatetimeIndex(df_temp['date']).year
df_temp['month_year'] = [str(i)+'-'+str(j) for i,j in zip(df_temp.year, df_temp.month)]
df_temp.head()
绘制时间序列图
下面的代码展示了如何从DataFrame绘制一个基本的时间序列图。稍后可以将结果与本文中的其他可视化结果进行比较。
plt.figure(figsize=(16,9))
sns.set_style('darkgrid')
sns.lineplot(data=df_temp, y='meantp', x ='date')
plt.show()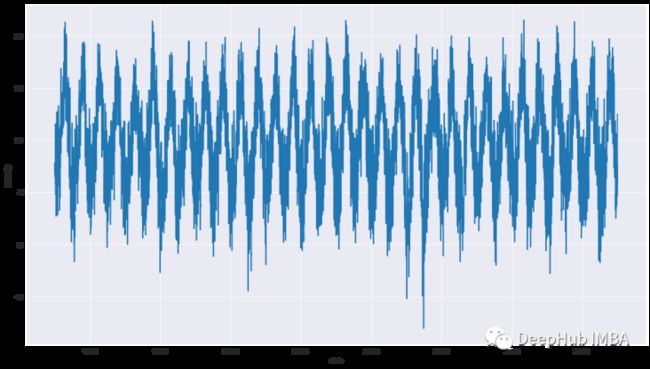
可以看到的图表过于密集,让我们看看如何处理这个问题。
处理超长时间序列数据的可视化
我们用6个简单的技巧来呈现一个长时间序列:
1、放大和缩小
我们可以创建一个交互式图表,结果可以放大或缩小以查看更多细节。所以Plotly是一个很有用的库,可以帮助我们创建交互式图表。
用一行代码直接绘制一个简单的交互式时间序列图。
px.line(df_temp, x='date', y='meantp')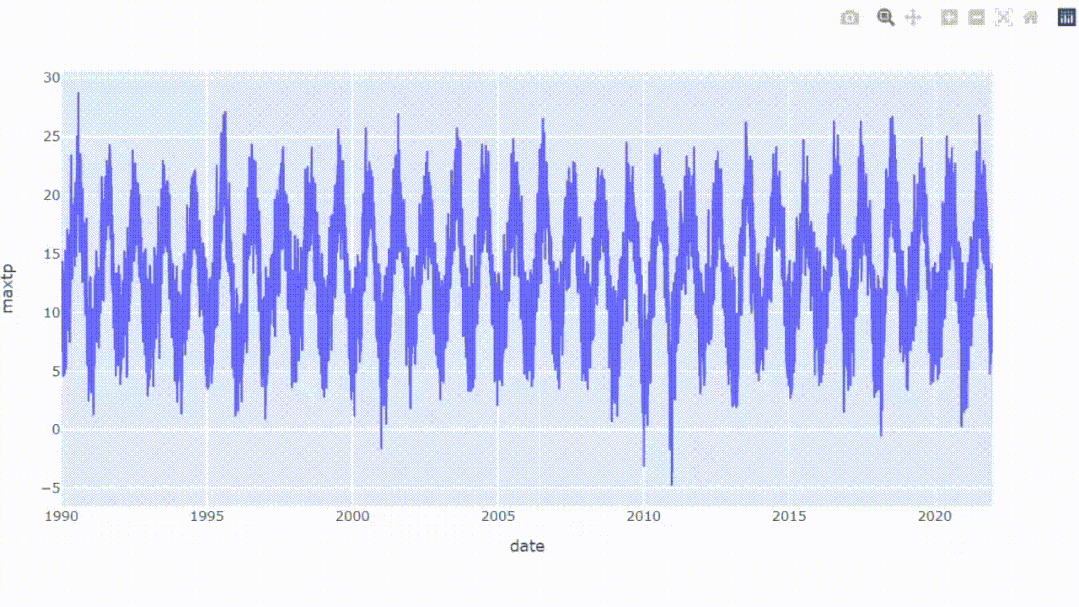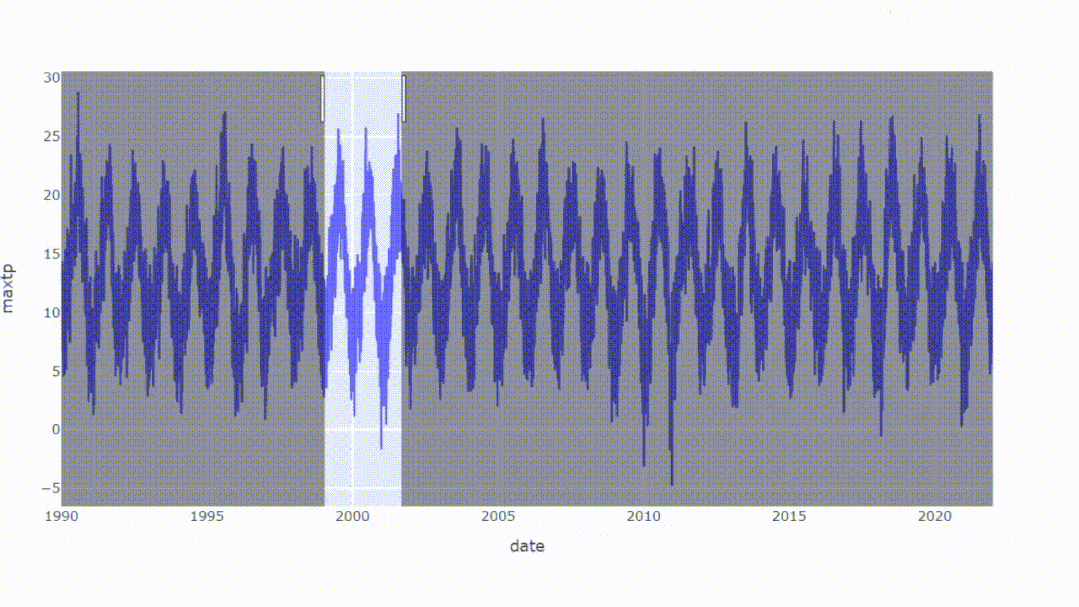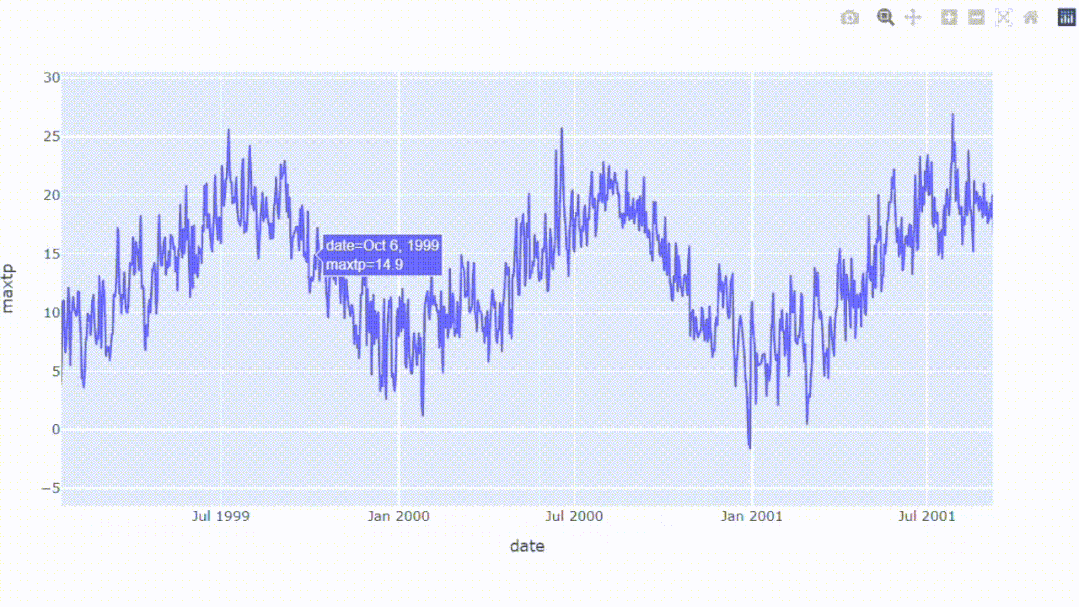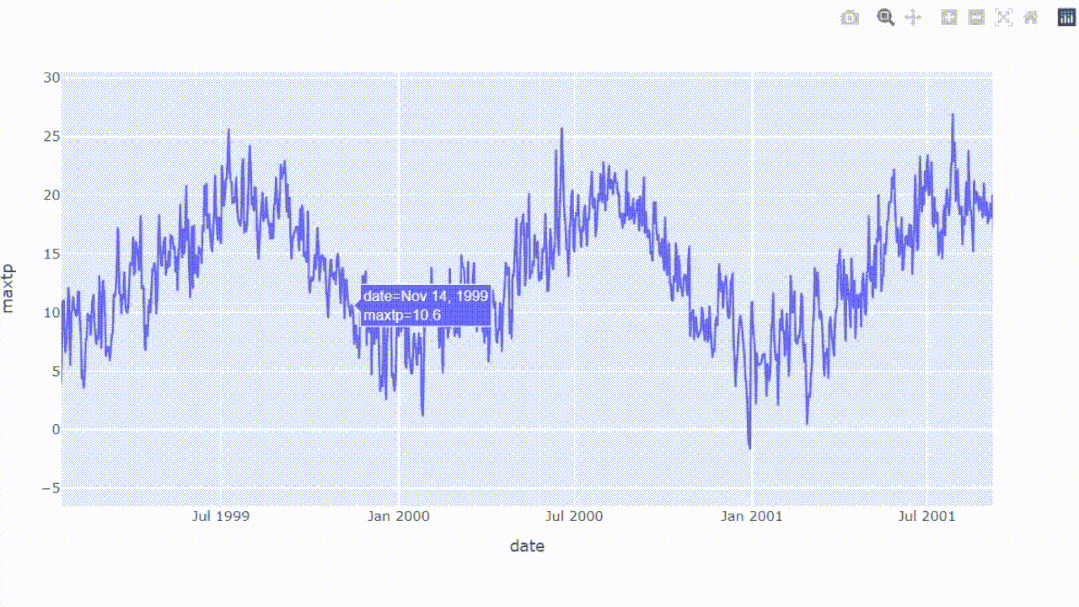
从结果中,我们可以看到整体数据,同时能够放大我们想要扩展的区域,这可能是Plotly唯一一个比matplotlib强的地方
2、突出显示数据点
如果需要注意某些值,可以用标记突出显示数据点。在交互式图中添加散点有助于标记关键的数据点,这时就可以针对性的放大查看更多细节。
现在让我们在之前的交互图中添加散点。例如,我们将分别关注高于20.5°C和低于-5°C的平均温度。
df_dot = df_temp[(df_temp['meantp']>=20.5)|(df_temp['meantp']<=-5)]
fig = px.line(df_temp, x='date', y='meantp')
fig.add_trace(go.Scatter(x =df_dot.date, y=df_dot.meantp,
mode='markers',
marker=dict(color='red', size=6)))
fig.update_layout(showlegend=False)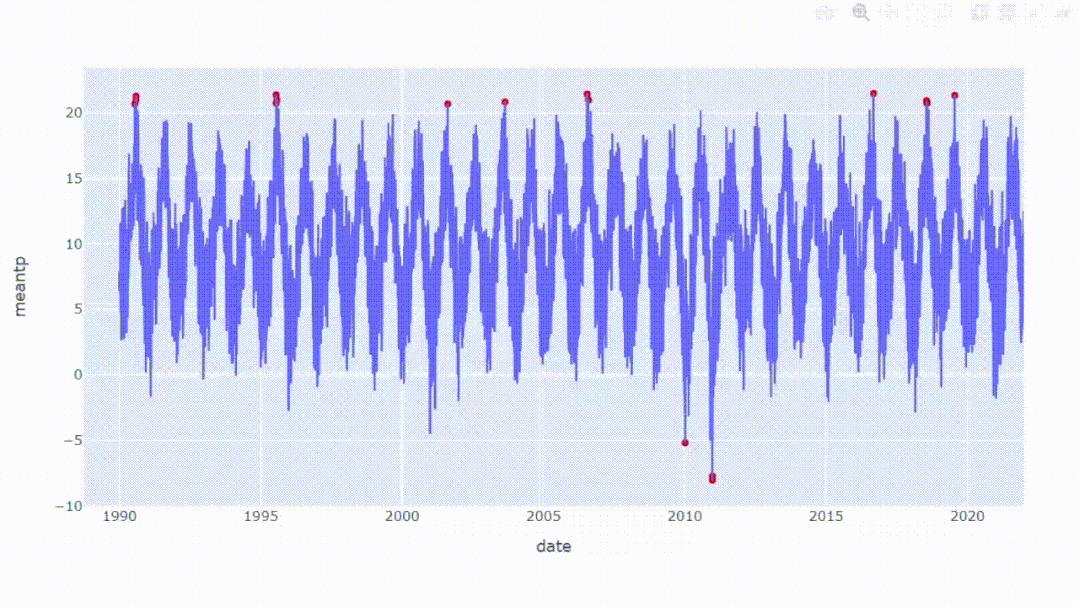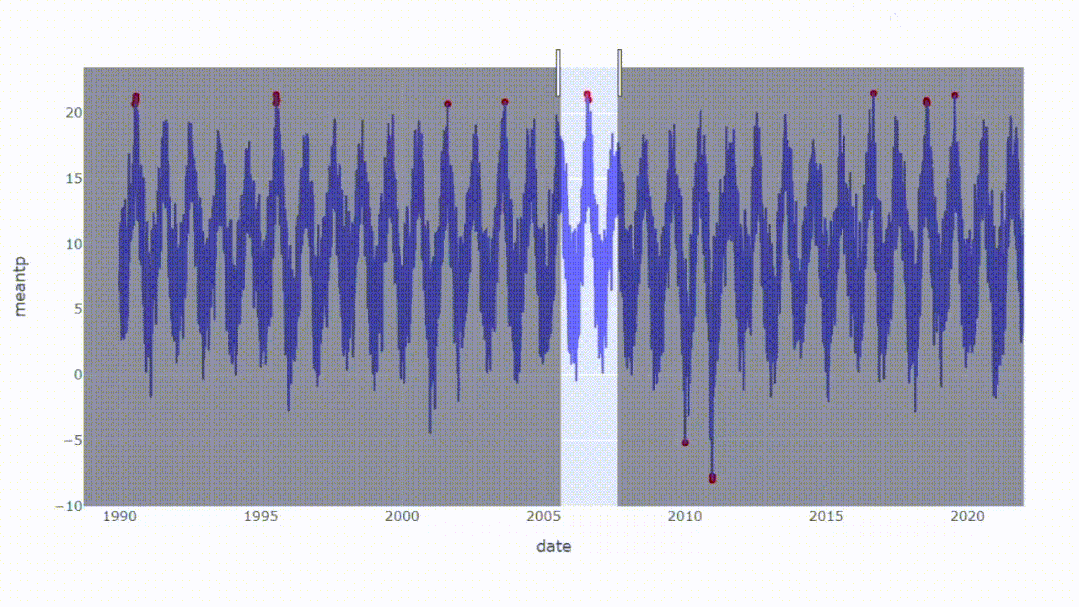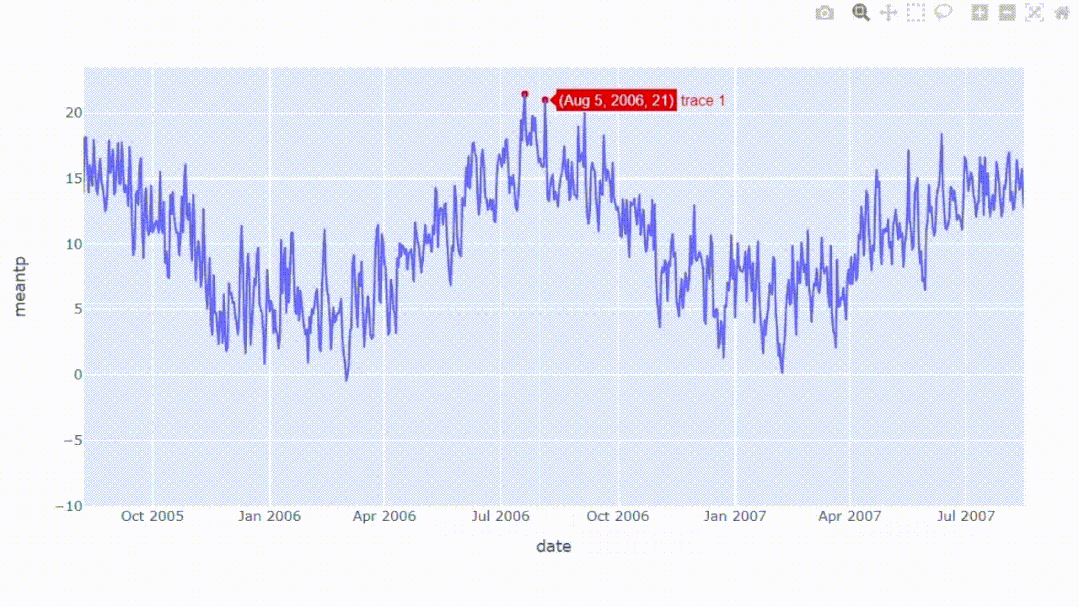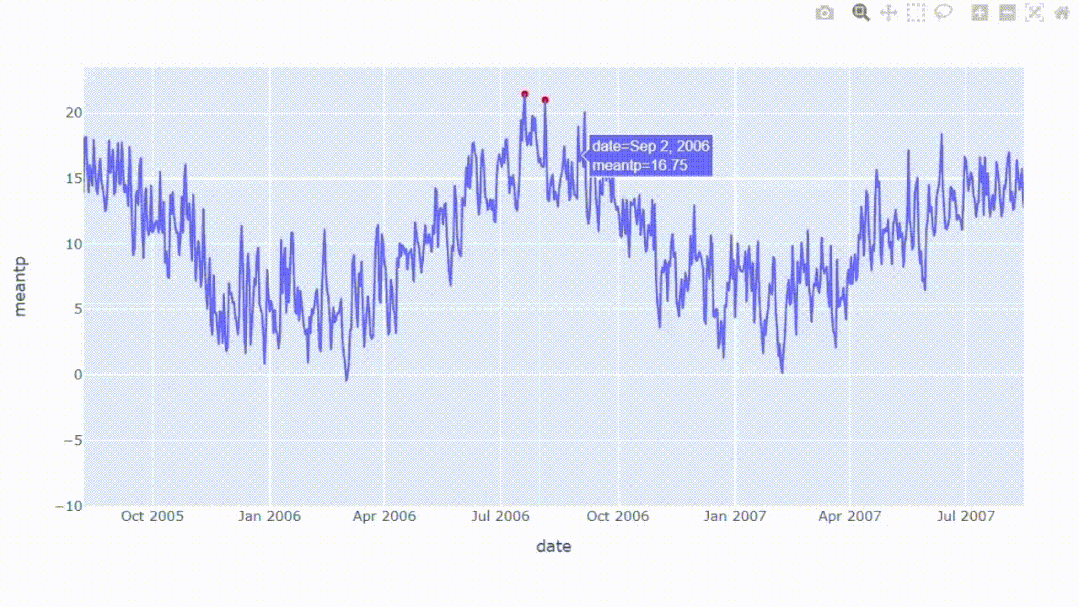
3、添加分割线
如果需要关注某些领域,绘制分割线可以分隔特定的数据值。例如,添加两条线来查看平均温度高于和低于20.5°C和-5°C的一天。
fig = px.line(df_temp, x='date', y='meantp')
fig.add_hline(y=20, line_width=1.5,
line_dash='dash', line_color='red')
fig.add_hline(y=-5, line_width=1.5,
line_dash='dash', line_color='red')
fig.update_layout(showlegend=False)我们可以更加关注线上面或线下面的数据点。
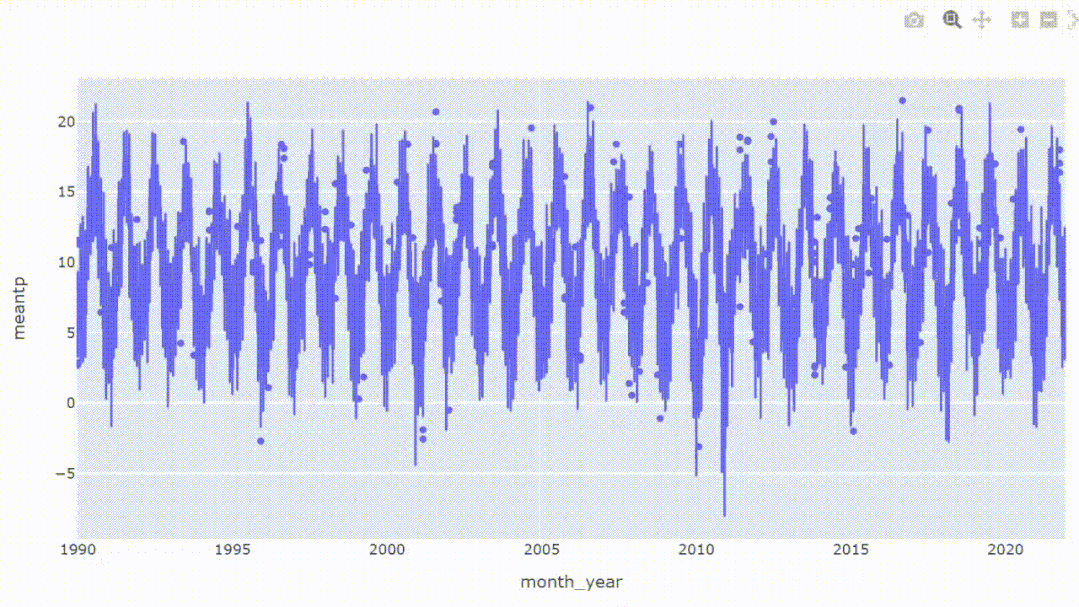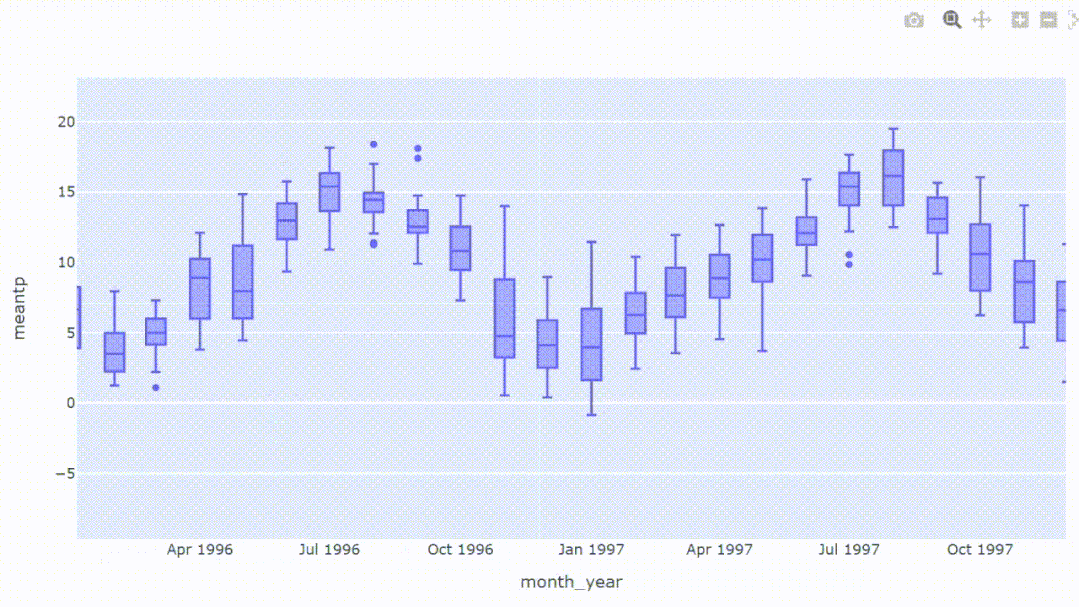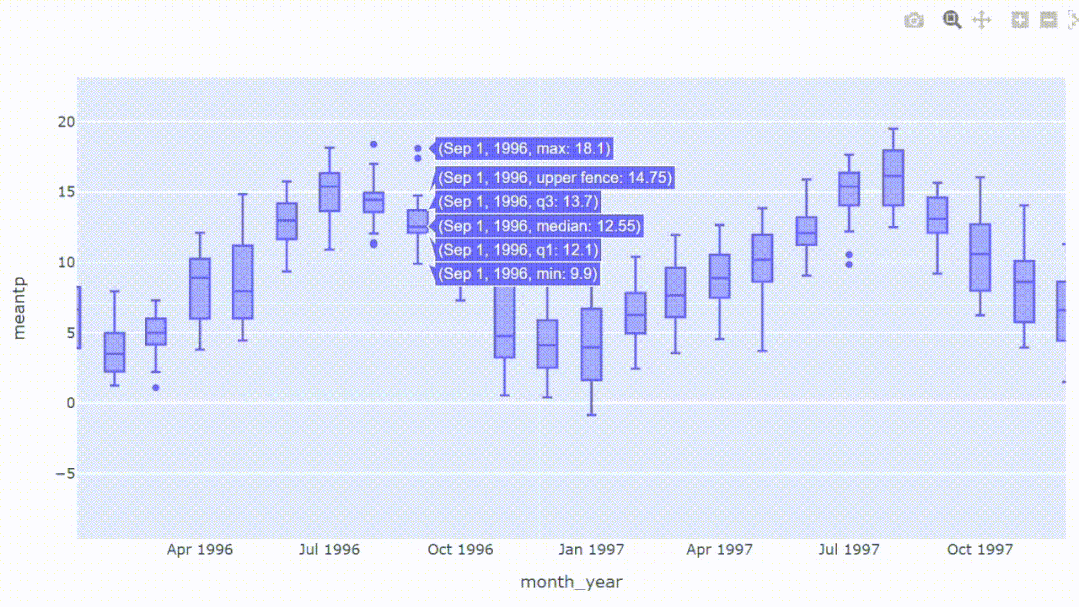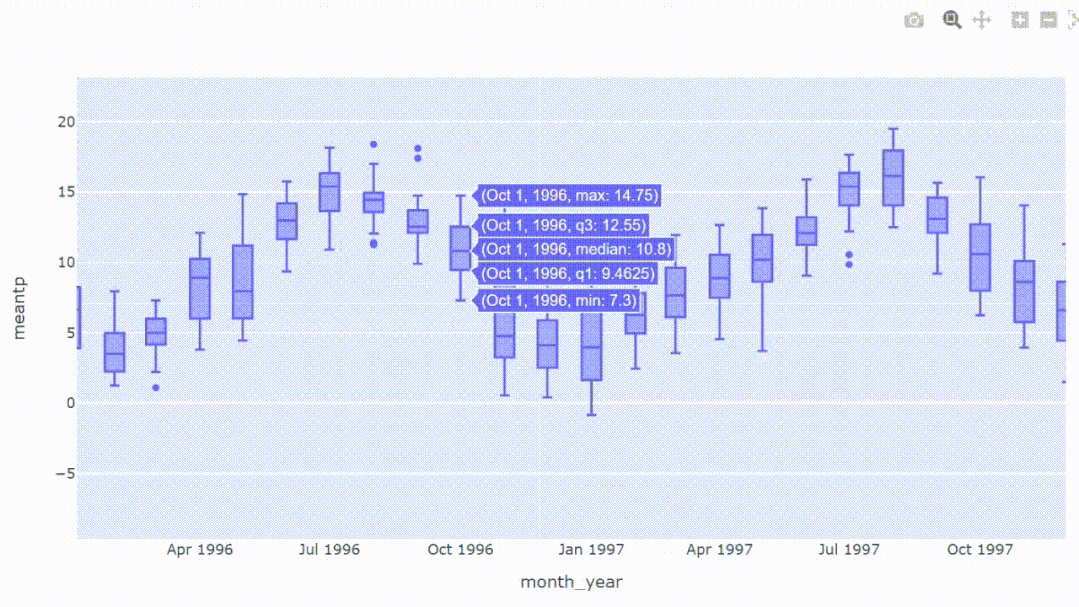
4、查看数据分布
箱形图是一种通过四分位数展示数据分布的方法。箱形图上的信息显示了局部性、扩散性和偏度,它还有助于区分异常值,即从其他观察中显著突出的数据点。我们只需一行代码就可以直接绘箱形图。
px.box(df_temp, x='month_year', y='meantp')
5、分组并显示比例
这种方法可以将时间序列图转换为热图,结果将显示总体平均月温度,并且可以使用颜色标度来比较数据的大小。
为了便于绘图,需要将数据帧转换为二维。首先按年和月对DataFrame进行分组。
df_mean = df_temp.groupby(['year','month']).mean().reset_index()
df_mean.head()
df_cross = df_mean.set_index(['year','month'])['meantp'].unstack()
df_cross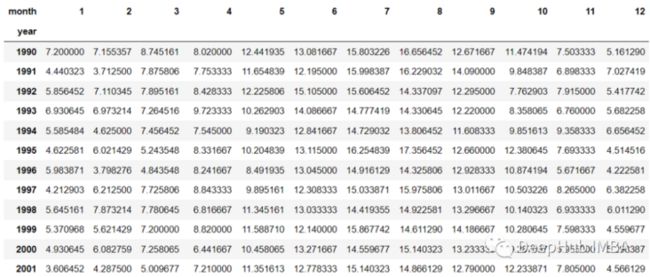
使用Plotly绘制热图也只需要一行代码。
px.imshow(df_cross, height=700, aspect='auto',
color_continuous_scale='viridis')
6、使用雷达图比较月份
在可视化时间序列数据时,通常会考虑随时间移动的连续线。我们可以改变一下观测方式,将这些线画在圆形中,就像在时钟上移动它们一样。雷达图可以用于比较同一类别数据的可视化图。我们可以通过在圆上绘制月份来比较年份同期的数据值。
首先准备一份月份、年份和颜色的列表
months = [str(i) for i in list(set(df_mean.month))] + ['1']
years = list(set(df_mean.year))
pal = list(sns.color_palette(palette='viridis',
n_colors=len(years)).as_hex())使用for循环函数在雷达图上绘制直线。
fig = go.Figure()
for i,c in zip(years,pal):
df = df_mean[df_mean['year']==i]
val = list(df.meantp)*2
fig.add_trace(go.Scatterpolar(r=val, theta=months,
name=i, marker=dict(color=c)))
fig.update_layout(height=800)创建交互式雷达图允许对结果进行过滤,并且可以通过将光标悬停在数据点上来显示信息。
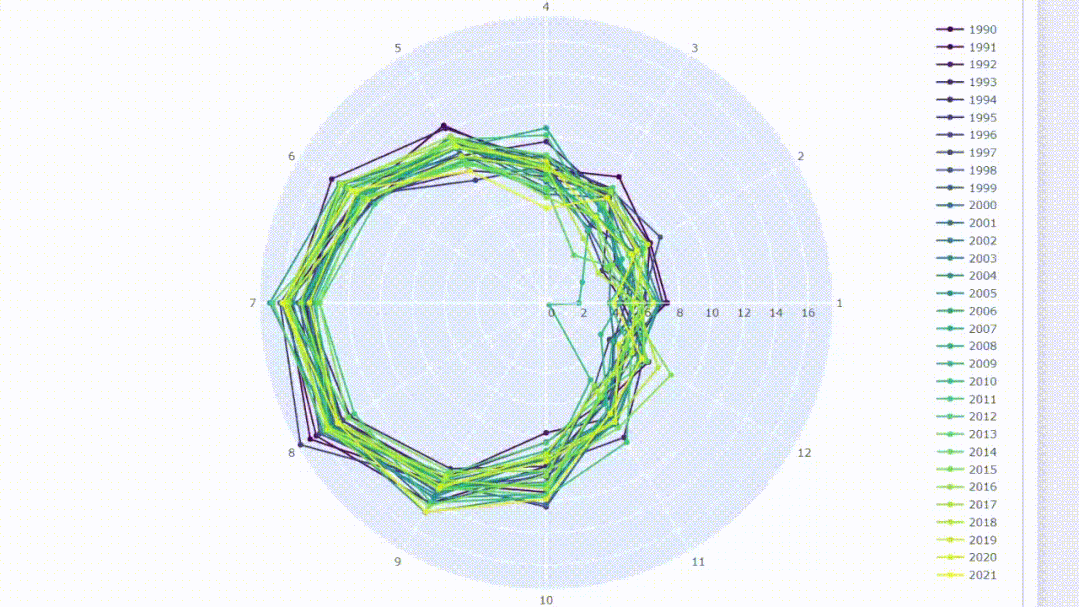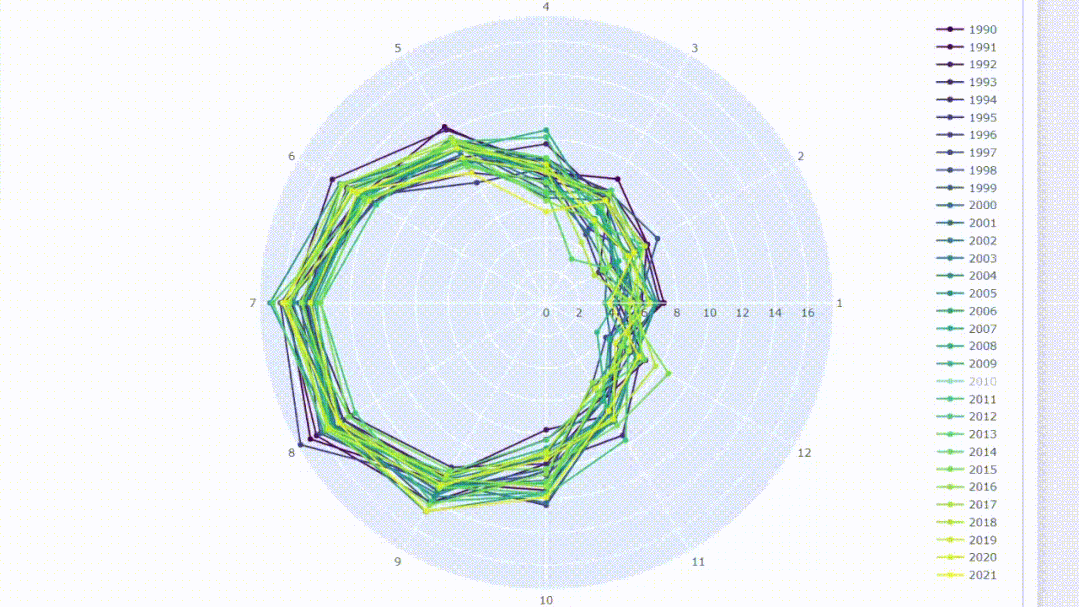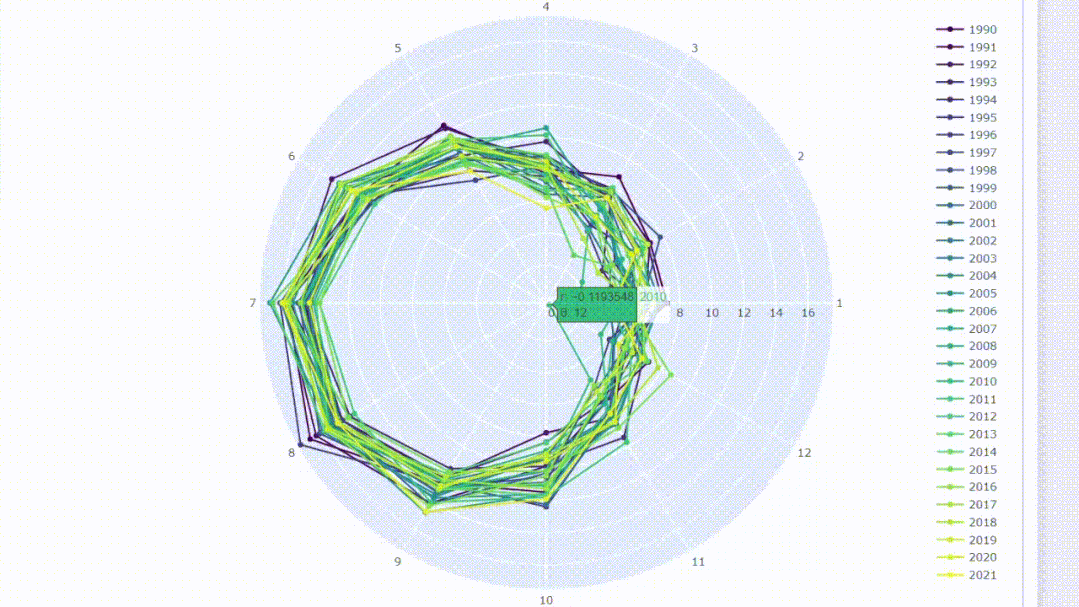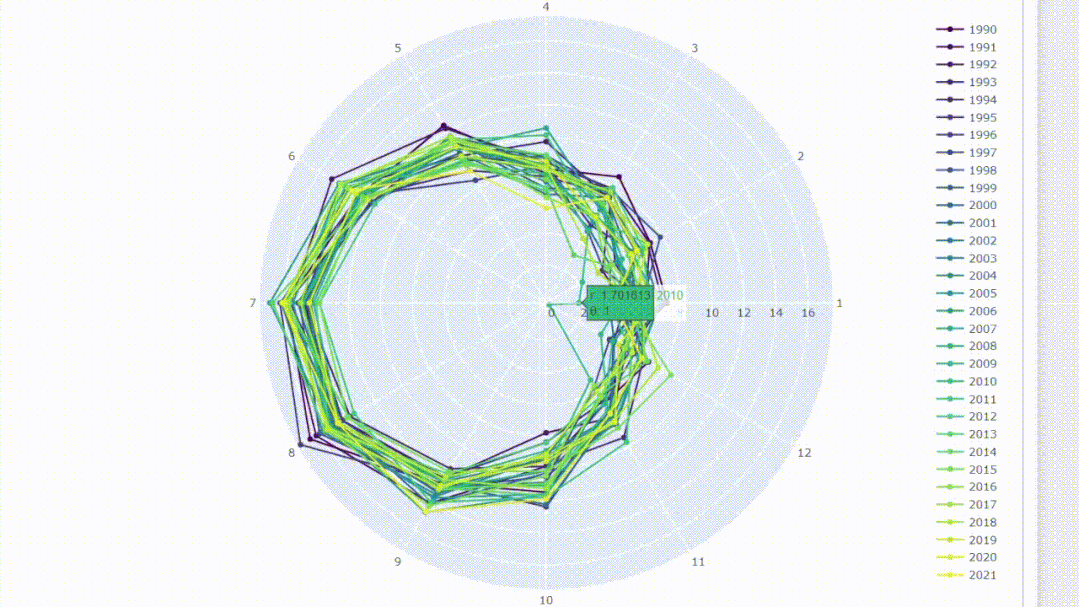
总结
对时间序列进行可视化可以提取趋势或季节效应等信息。使用简单的时间序列图显示超长时间序列数据可能会由于重叠区域而导致图表混乱。
本文展示了6种用于绘制长时间序列数据的可视化方法,通过使用交互函数和改变视角,我可以使结果变得友好并且能够帮助我们更加关注重要的数据点。
最后这些方法只是一些想法。我相信还有其他可视化方法也可以用来解决这个问题。如果有任何建议,请随时留言。
https://avoid.overfit.cn/post/dc059f34ae074a0ba09a63109bdfdf60
作者:Boriharn K