论文笔记:Towards Robust Fine-grained Recognition by Maximal Separation of Discriminative Features
Towards Robust Fine-grained Recognition by Maximal Separation of Discriminative Features
通过 区分特征的最大分离 实现鲁棒的细粒度识别
文章目录
- Towards Robust Fine-grained Recognition by Maximal Separation of Discriminative Features
-
- 摘要
- 1 引言
- 2 相关研究
- 3 预备阶段:解释对抗攻击
- 4 方法
-
- 4.1 架构
- 4.2 区分特征分离
- 5 实验
- 6 结论
摘要
对抗性攻击被广泛研究用于一般分类任务,但在细粒度识别的背景下仍未得到研究,在细粒度图像情况下,类间相似性可促进攻击者的任务。(确实,细粒度图像更相像,假数据更容易混过去)
本文将细粒度识别网络中不同类别的潜在表示的接近程度确定为对抗攻击成功的关键。引入了一种基于注意力的正则化机制,最大程度地区分了不同类别的可区分潜在特征,同时最大程度地减少非区分区域对最终类别预测的影响程度。能够显着提高对抗攻击的鲁棒性,达到匹配甚至超过对抗训练的程度。
1 引言
-
深度网络的性能在对抗性攻击下会下降。对抗攻击在通用目标识别任务得到了广泛研究,但对细粒度识别方面研究很少。期望类间的相似性可以促进攻击者的任务。
-
本文分析了对细粒度识别技术进行对抗攻击成功的原因,并介绍了一种防御机制来提高网络的鲁棒性,并对图像中对分类结果最有权重的图像区域进行了可视化。具体来说,既考虑了与CAM密切相关的基于注意力的框架,又考虑了为细粒度识别而设计的将局部区域和原型关联的原型部分网络(ProtoPNet)。
-
基于如下直觉(每个类的区分区域应与其他类别的区分区域最大程度地分开)引入防御机制。设计了一个注意力意识模型,推开不同类的区分性原型。
不同类的区分区域尽可能推远,非区分区域无所谓并强制它们在最终分类中不起作用。增加了攻击者为成功地将网络的预测远离真实标签而必须执行的潜在空间位移的幅度。
-
本文贡献总结如下:
- 通过研究负责对干净和对抗性示例进行分类的图像区域来分析和解释细粒度识别网络的决策
- 通过限制判别区域的潜在空间,设计了一种可解释的、可引起注意的网络,以实现稳健的细粒度识别。
- 证明了网络鲁棒性达到了与对抗训练相当的水平,而无需访问对抗性样本并且无需权衡干净的准确性
2 相关研究
对抗鲁棒性
深度神经网络很脆弱容易受到攻击和人类无法察觉的干扰。迄今为止,利用局部一阶网络信息来计算指定 l ∞ l_{\infty} l∞范数界内的最大损失增量的投影梯度下降(PGD)被认为是最有效的攻击策略。(咱也看不懂这是啥)
尽管在设计针对对抗攻击的防御机制方面进行了大量研究工作,但当攻击者知道网络架构条件下,大多数此类防御可以轻易地在白盒环境中破坏。该规则的主要例外是对抗训练,模型是与干净的图像及其对手一起训练,并提出了对抗训练的许多变体。但由于PGD对不可见攻击的鲁棒性和泛化能力,基于PGD的对抗训练仍然是选择的方法。
但对抗训练在计算上是昂贵的。与所有对抗训练策略不同,本文方法不需要计算对抗图像,因此不依赖于特定的攻击方案。 相反,它旨在确保不同类别的高关注区域有最大的分离,而且是针对细粒度的识别而量身定制。
可解释性
可视化策略:CAM以及其诸多变体。
细粒度识别任务:BoW启发的表示形式、ProtoPNet、VLAD。尽管这种方法可以突出显示对于分类很重要的图像区域,但它不能为网络的决策提供直观的解释。
ProtoPNet解决了这一问题,该方法提取了特定于类的原型。但是,ProtoPNet学习的特征嵌入对所有图像区域都具有同等的重要性。通过设计注意力感知来解决这个问题。该系统学习在特征空间中靠近高度关注区域的原型,约束来自所有类的非区别区域彼此靠近。这不仅带来了可解释性,而且还带来了对抗攻击的鲁棒性。
3 预备阶段:解释对抗攻击
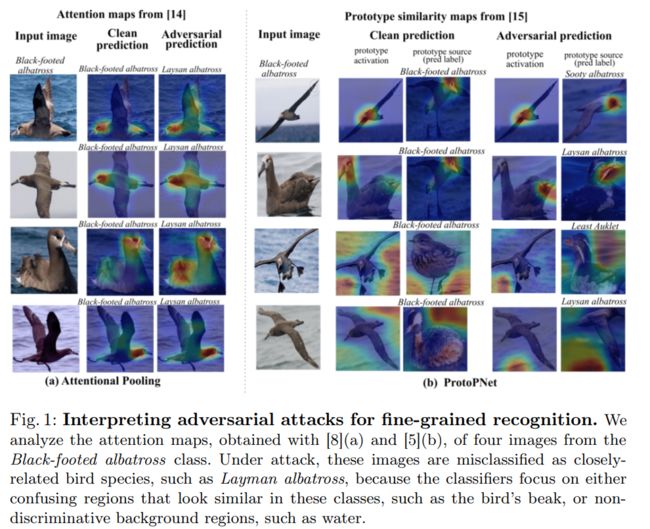
尝试使用两个网络对此分析:二阶注意力池化网络[8]和ProtoPNet[5],它们两者都固有地在其体系结构中编码了一些可解释性的概念,不需要任何后处理。 具体来说,[8]使用类别注意图来计算类别概率,[5]则利用图像区域和特定于类别的原型之间的相似性。下面对Black-footed albatross的四幅图像进行对抗攻击成功分析原因。
| 模型 | 分类错误结果 | 区域 | 结果 |
|---|---|---|---|
| [8]二阶注意力池化网络 | 同一族的一个相似类 | 集中在鸟喙区域 | 易于攻击 |
| [5]ProtoPNet | 不同类 | 不同区域,有的是背景 | 易于攻击 |
本质上是由于两个不同类的可分辨区域在特征空间中相近,或是使用了非区分区域进行分类。 因此:鼓励不同类别的区分区域的特征表示最大程度分开,同时通过注意并鼓励区域中的特征彼此靠近来最小化背景区域的影响。
通过阻止攻击者利用非区分区域并迫使它们在特征空间中进行较大的变化以影响预测,使攻击者的任务复杂化。
4 方法
通过最大程度地分离类的特定区分区域来提高细粒度识别的鲁棒性的方法。该框架由两个模块组成
- 注意力模块,学习关注区分区域的特定于类的过滤器
- 特征正则化模块,其最大程度地将注意力模块认为具有区别性的特定于类别的特征分开。 特征正则化模块,即提供可解释性,又提高了骨干网抵抗对抗性攻击的能力

4.1 架构
原文中有一段:具体来说,原型层计算每个局部特征和每个原型之间的 L 2 L^2 L2距离,并将该距离通过定义为 f ( r ) = log ( ∣ ∣ r ∣ ∣ 2 2 + 1 ∣ ∣ r ∣ ∣ 2 2 + λ ) f(r)=\log(\frac{||r||^2_2+1}{||r||^2_2+\lambda}) f(r)=log(∣∣r∣∣22+λ∣∣r∣∣22+1)的激活函数传递,和图对不起来,不知道添加到哪里。
通过将m个原型划分为K个c个原型,并将原型分支的分类层的权重初始化为+1,以实现原型和类标签之间的正连接,从而使原型类特定化- 负数为0.5。这句也不懂。
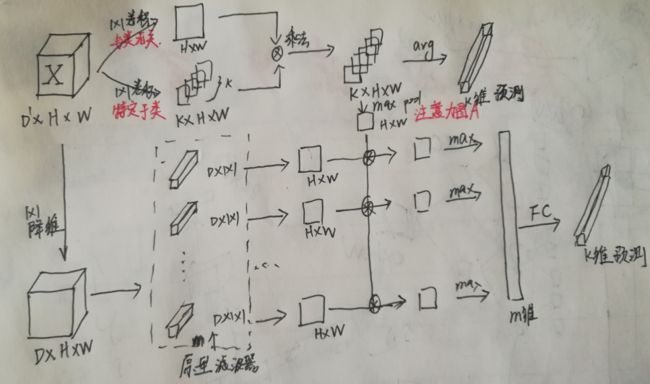
m个原型分割成K组原型,每组c个原型。
4.2 区分特征分离
高响应靠近原型:
L c l s t a t t ( I ) = ∑ t = 1 N a t min l : p l ∈ P y ∣ ∣ x i t − p l ∣ ∣ 2 2 L_{clst}^{att}(I)=\sum^{N}_{t=1}a^t\min_{l:p_l\in P_y}||x^t_i-p_l||^2_2 Lclstatt(I)=t=1∑Natl:pl∈Pymin∣∣xit−pl∣∣22
低响应靠近原型:
L s e p a t t ( I ) = − ∑ t = 1 N a t min l : p l ∉ P y ∣ ∣ x i t − p l ∣ ∣ 2 2 L_{sep}^{att}(I)=-\sum^{N}_{t=1}a^t\min_{l:p_l\notin P_y}||x^t_i-p_l||^2_2 Lsepatt(I)=−t=1∑Natl:pl∈/Pymin∣∣xit−pl∣∣22
重新整理:
L r e g ( I ) = ∑ j = 1 B ∑ t = 1 N λ 1 a j t min l : p l ∈ P y ∣ ∣ x i t − p l ∣ ∣ 2 2 − λ 2 a j t min l : p l ∉ P y ∣ ∣ x i t − p l ∣ ∣ 2 2 L_{reg}(I) = \sum^B_{j=1}\sum^{N}_{t=1}\lambda_1a^t_j\min_{l:p_l\in P_y}||x^t_i-p_l||^2_2-\lambda_2a^t_j\min_{l:p_l\notin P_y}||x^t_i-p_l||^2_2 Lreg(I)=j=1∑Bt=1∑Nλ1ajtl:pl∈Pymin∣∣xit−pl∣∣22−λ2ajtl:pl∈/Pymin∣∣xit−pl∣∣22
最终损失:
L ( I ) = C E a t t ( I ) + C E r e g ( I ) + L r e g ( I ) L(I)=CE_{att}(I)+CE_{reg}(I)+L_{reg}(I) L(I)=CEatt(I)+CEreg(I)+Lreg(I)
5 实验
定量分析:将CUB200上三个骨干网的方法与基线的准确性进行比较

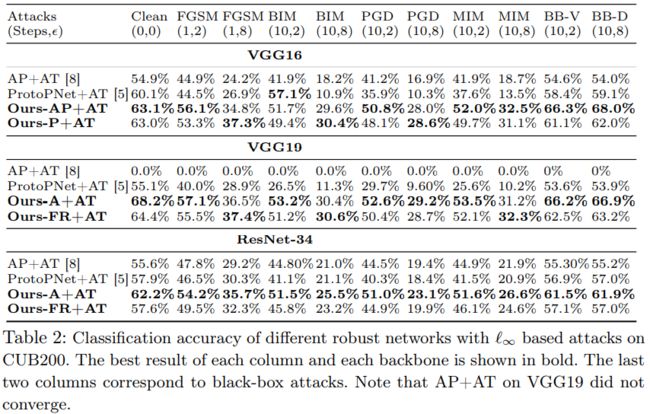
- 在干净的样本上,Our-A在所有主干上均能提供最佳的准确性,而Ours FR通常会超过其非关注性的ProtoPNet。
- 在对抗性攻击下,本文方法在没有和经过对抗性训练的情况下,在几乎所有攻击和骨干网络下都具有更好的鲁棒性。 重要的是,对于扰动较大的攻击,性能提升更大。
- 使用干净样本训练的模型有时甚至优于经过对抗训练的基线。
- 本文方法不会牺牲干净的准确性来获得鲁棒性。
转移性分析:为了评估黑盒攻击的鲁棒性,将从替代网络生成的对抗性样本转移到框架和基线中。作为替代模型,使用VGG-16和DenseNet-121主干,然后使用全局平均池和分类层。
在黑盒设置中的性能优于基线,从而证实了其在学习鲁棒特征方面的有效性。
定性分析

- ProtoPNet学习了多个背景原型,本文方法将所有背景信息编码为一个非区分原型
- ProtoPNet专注于更大的区域,与使用本文方法获得的细粒度区域相比,可以预期该区域的区别性较小。 这是由于使用了注意力,有助于原型将注意力集中在对分类很重要的区域上。
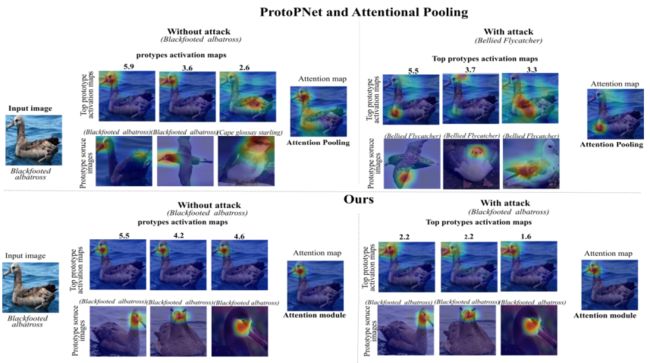
在没有受到攻击的情况下,AP可以激活更大的区域。 此外,ProtoPNet会从其他类激活一个原型,而本文方法仅关注正确的类。表明,通过这些基线学习的特征具有较少的区别性,更容易受到对抗性攻击。
6 结论
- 进行了针对细粒度识别的对抗攻击的第一项研究。分析了细粒度情况下对抗性攻击成功的关键,设计一个基于注意力和基于原型的框架,该框架明确地鼓励原型着重于区分性图像区域。尽管不需要在训练过程中查看对抗性示例,但仍然能够胜任甚至有时超过对抗训练。
- 即使本文方法对攻击具有鲁棒性,但它计算出的相似性得分往往会更低。
- 将来研究是否可以利用它来设计攻击检测机制。