深入底层C源码剖析Redis核心合计原理
目录
1、Redis K-V底层设计原理
2、Redis渐进式rehash及动态扩容机制
3、Redis核心编码结构精讲
4、亿级用户日活统计BitMap实战及源码分析
一、Redis基本特性

二、Redis应用场景
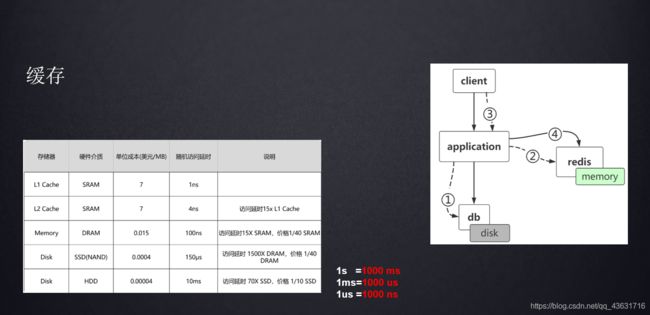
二、Redis的Key存储:SDS
redis中的所有key都是用String类型存储的。

二进制安全的数据结构
Redis中所有的数据最终都会以字节流的形式发送到redis服务器上,所有的key都会被处理成String类型。
我们知道Redis使用C语言实现的,C语言中用char data[] = "key"来表示一个String。
但是Redis底层并没有直接使用C语言中的char数组存储key,而是自己实现了一个Simple Dynamic String(简称SDS)来存储key.
**SDS是一个二进制安全的数据结构**
思考: 为什么Redis要自己实现一个SDS呢?
我们知道,Redis可以支持多种语言,比如java、php,、go等等。 如果我们使用C语言的char数组来接收key, 可能会使得对key的读取出错。因为我们知道,C语言存储一个字符串的时候会自动在后面加上“\0”, 比如key会被表示成:char data[] = “key\0”。 这样如果一些客户端发送过来的数据中本身就包括了\0这个字符,就会导致解释出现问题。
这样,比如存一个客户端传过来的字符:char data[] = “ke\0y”, 用C语言本身的String存储会有问题,如果用SDS存储,结构如下:
sds:
free:13 // 记录这个buffer中还有多少剩余空间,假设总共分配了18个,value占了5个,就还剩13个
len: 5 // SDS会记录这个字符串的长度。
char buf[]= "ke\0y"‘;
SDS是一个二进制安全的数据结构!
提供了内存预分配机制(避免了频繁的内存分配)
如果我们定义了一个字符串,然后增加了内容,如果是C语言实现,会重新申请一个较大的char数组来保存。Redis为了优化,对于我们保存的字符串,SDS中分配的存储数据的空间会比实际的字符串空间大一点,目的就是为了用空间换时间,来减少内容的重新分配。并用一个free字段来描述这个空间的剩余容量。
对于上面的"ke\0y"字符串假设我们现在增加了其内容,我们再来看看SDS的结构:
sds: // 假设总共分配了18个容量
free:10 // 剩余10个
len:8 // 占用欧冠了8个
char buf[]="ke\0yxyz"
那假如我们现在对value新增了非常多的数据,导致整个数据超过了一开始分配的空间18,会怎么样呢?
这时候Redis就会扩容,下面是扩容计算公式:
(len + addlen) * 2
注意:当内存扩大到1024 * 1024的时候,不会在成倍扩大,而是每次增加1M。
兼容C语言的函数库
对于字符串内容,SDS其实会在其末尾自动的加上"\0"来兼容C语言的函数库。
比如key=“xioayan”,会存储成"xiaoyan\0"。

我们可以看到,redis3.2之后对于SDS进行了优化,原因就是我们的Redis存储String的时候,有的value是非常小的,但是这里的len和free这两个字段就占用了很大的空间,所以这里可以进行优化。
会按照value的长度使用不同的存储结构。
下面是判断逻辑:
static inline char sdsReqType(size_t string_size) {
if (string_size < 32)
return SDS_TYPE_5;
if (string_size < 0xff) //2^8 -1
return SDS_TYPE_8;
if (string_size < 0xffff) // 2^16 -1
return SDS_TYPE_16;
if (string_size < 0xffffffff) // 2^32 -1
return SDS_TYPE_32;
return SDS_TYPE_64;
下面是每一种数据类型的结构:
typedef char *sds;
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
........
三、Redis K-V
我们都知道一个重要的函数,hash。
我们使用hash(key)会得到一个很大的自然数;
但是我们通常存储数据的数组一般都是比较小的,比如我们的数据长度现在是4,,那我们就可以使用得到的这个大的hash值对4取模,从而确定这个数的数组中的存储位置。
hash(key) -> 自然数[大] % 4 = [0, arry.zise -1]
这里我们总结一下hash的特性:
1、任意相同的输入,一定能得到相同的输出;
2、不同的输入,有肯能得到相同的结果(hash碰撞)。
hash(k1) % 4 = 0
hash(k2) % 4 = 1
hash(k3) % 4 = 1
学过数据结构的我们应该知道,解决hash冲突有两种方法:寻地址法和拉链法(链地址法)。
我们通常是使用链地址法来解决hash冲突,就是使用一个链表来存储hash值相同的数据。
arr[0] -> (k1, v1, next -> null)
arr[1] -> (k3, v3, next -> k2) (k2, v2, next -> null)
Redis中的Hash优化
我们都知道,使用求模运算来计算hash值对CPU不是很友好,效率较低。
有这样一个规则,对2的指数次幂的求模运算:
任意数 % 2^n == 任意数 & (2^n - 1)
hashMap中的hash也是这样计算的。
四、RedisDb 设计
我们都知道,Redis有16个数据库,分别是0~15.
Redis在C层面使用redisDb来表示数据库,我们来看看redisDb的结构:
typedef struct redisDb {
dict *dict; // 存储Key的数据结构, hashTable
dict *expires; // 过期时间
dict *blocking_keys;
dict *ready_keys;
dict *watched_keys;
int id; // 数据库ID, select 0
long long avg_ttl;
unsigned long expires_cursor;
list *defrag_later;
} redisDb;
dict(dictionary:字典)是专门用来存储key的数据结构,可以理解为hashTable。我们重点来看一下这个dict结构:
typedef struct dict {
dictType *type; // HashTable类型, 不同类型的hashTable有不同的hash函数
void *privdata;
dictht ht[2]; // hashTable
long rehashidx;
unsigned long iterators;
} dict;
//
下面是源码中dictType的结构:
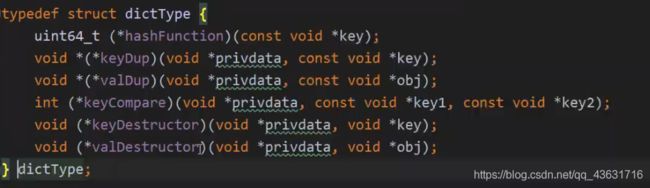
我们来看一下dictht即hashTable的结构:
typedef struct dictht {
dictEntry **table; // 指向一个hashTable
unsigned long size; // 数组长度,容量默认是4
unsigned long sizemask; // size - 1
unsigned long used; // hashTable元素个数 used / size = 1
} dictht;
Redis中也存在和HashMap类似的扩容机制。
我们知道,扩容其实是为了减少hash冲突,防止一个hash槽上生成单链表,使得我们的查询从O(1)退化成O(n). 所以在元素达到一定个数的时候需要扩容,来尽可能的减少hash冲突。
渐进式rehash(incremental rehashing)
Redis存在一种渐进式rehash的功能,什么是渐进式rehash呢?
假如我们的redis中现在存储了非常多的数据,而此时我们的hashTable数据也达到了需要扩容的时候,如果我直接将所有的数据都直接转移到新的,也就是容量扩大2倍的新hashTable中,这个过程无疑是需要耗费大量的性能和时间的。
因为我们需要重新计算每一个数据在新table中的hash, 这样会对我们的客户端请求产生影响。所以,Redis为了解决这个问题,设计了渐进式rehash功能,就是说,我不会一下子将所有的数据都转移到新的table中,而是当我们get的时候,就将这一部分数据进行转移。
而且,redis中还存在一个轮训,会定时的去判断是否有客户端使用redis,如果长时间没有使用,redis也会将其他数据转移到新table中,而不是绝对的等到get的时候再去转移。
如果旧table中的数据被转移完之后,就会删除整个旧table.
所以,每一个dict(dictionary:字典)中都存在两个dictht(hashTable, 一个是旧的,一个是新的) 。
注意:
database的数量默认是16,可以自己在配置文件中修改;
默认的table长度是4.
Redis中K-V键值对
redis中键值对使用dictEntr表示的,我们来看一下结构:
typedef struct dictEntry {
void *key; // key值,就是一个SDS对象,
union {
void *val; // value, 指向一个数据类型,可能是String, list, set
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // next是连接下一个节点的,是为了使用链表解决hash冲突的
} dictEntry;
Redis值存储:RedisObject
Redis中的String, list 和Set等类型的数据不是直接存储的,而是需要做封装。Redis中使用RedisObject来封装这些对象。
typedef struct redisObject {
unsigned type:4; // 表示数据的类型,如String, hash,list, set // 4 bit
unsigned encoding:4; // 表示整个key对应的value在redis底层是要什么数据编码存储 // 4bit
unsigned lru:LRU_BITS; // 淘汰策略 // 24 byte
int refcount; // redis使用引用计数法管理内存, C中内存需要自己管理 // 4 byte
void *ptr; // valude的真实数据存储,指向真实的数据地址 // 8 byte
} robj;
unsigned的作用就是将数字类型无符号化, 例如 int 型的范围:-2^31 ~ 2^31 - 1,而unsigned int的范围:0 ~ 2^32。
- 1、type
假如我们现在使用set设置了一个100的数据,我们知道这时候100就会被标记成一个String类型的:
set 100 100
然后我们使用list结构的命令来试试,就会报错说类型错误。

- 2、encoding
表示整个key对应的value在redis底层是要什么数据编码存,我们可以使用命令"object encoding [key]"来查看一个key对应value的encoding:
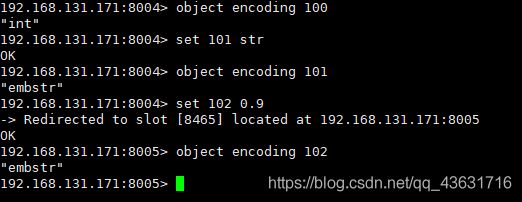
Redis中整型值存储
我们设置set 100 100,这个value的100就会在redis中存储为自己封装的整型。
我们知道整型的大小是固定的,长整型最长是64bit也就是8个字节。我们正好看到存储value的指针*ptr大小正好也是8个字节,所以Redis为了优化,就直接将整型数据的值存储到"*ptr中了。这样对于整型数据,就不需要根据根据地址去内存中load了,可以直接读取出来。
Redis内存中的数据读取
我们知道,现在的CPU从内存中读取数据都是按照缓存行的方式来读取的,一个缓存行大小是64byte.
而一个RedisObject大小是16byte.
typedef struct redisObject {
unsigned type:4; // 表示数据的类型,如String, hash,list, set // 4 bit
unsigned encoding:4; // 表示整个key对应的value在redis底层是要什么数据编码存储 // 4bit
unsigned lru:LRU_BITS; // 淘汰策略 // 24 bit
int refcount; // redis使用引用计数法管理内存, C中内存需要自己管理 // 4 byte
void *ptr; // valude的真实数据存储,指向真实的数据地址 // 8 byte
} robj;
type和rencoding加起来8个bit, 也就是1byte.
LRU占用24bit,也就是3个bype.
然后refcount和ptr分别占4vbyte和8byt。总共加起来一个RedisObject占用16个byte.
这就意味着,CPU每次load内存的时候,每次都可以从Redis中取出4个redisObject. 但是这样好吗?这样多读出来48byte的数据,而且我们也不一定会用到,而且value还需要从ptr中获取。所以说Redis还有进一步的优化:
对于数据量小于44byte的数据,我们可以直接将其value写到这48个byte中,这样只需要一次IO就可以获取到数据内容。
[redisObject: 16byte, 4 byte, 44 byte]。
我们做个试验:
STRLEN largeStr // 可以查看key对应的value占用的字节数
// 我们设置一个byte是44的数据
192.168.131.171:8005> set largeStr 11111111111111111111111111111111111111111111
OK
192.168.131.171:8005> STRLEN largeStr
(integer) 44
// 再来查看一个value的存储类型:
192.168.131.171:8004> object encoding largeStr
-> Redirected to slot [8161] located at 192.168.131.171:8005
"embstr" // embstr 表示这是开辟了一个连续的内存空间,指开辟了一个内存空间,只需要一次IO就可以将数据读取到内存
我们可以将其长度加到45byte,再来证实一下:
192.168.131.171:8005> set largeStr 11111111111111111111111111111111111111111111B
OK
192.168.131.171:8005> STRLEN largeStr
(integer) 45
192.168.131.171:8005> object encoding largeStr
"raw"
192.168.131.171:8005>
可以看到,超过44个byte,数据类型变成了raw. 不再是只存在于一个内存空间中了。
五、剪不断,理还乱:Redis主体数据结构

六、BitMap介绍
饿了么面试题:如何统计亿级用户的日活状态?
我们如果用传统的数据表来统计,效率是不尽人意的。
我们可以考虑使用bitmap。因为用户的状态就是在线和离线,而一个Bit位的值,不是1就是0.
我们可以使用一个bit位表示一个用户,用offset表示用户的id,用1或者0表示用户的状态。这样,2个byte就可以表示16个用户的状态了。
bit为默认值是0.
可以用日期作为总的key.
如果用户id是整型的,就可以直接将userI作为offset.
set user:active:state:bitmap userId 1
eg: setuser:active:state:bitmap 100 0
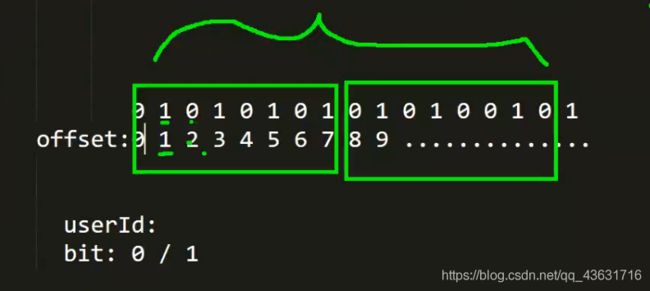
操作bitmap的API
1、设置
// 设置
setbit (key, offset, value(0 | 1)); // set后返回旧值
2、获取
// 获取
getbit key
3、统计bitmap中数据个数(即bit值为1的数据个数)
bitcount key [start_byte] [end_byte] // 统计一段字节中的数据个数
bitcount key // 统注意返回的是bit值为1的数据个数
返回的是bit值为1的数据个数,而不是所有数据个数!!!。
使用:
set a-bit-map 1 1
set a-bit-map 9 1
get a-bit-map 9
饿了么亿级日活用户练习
1、今天是2021-7-4,现在我们要把用户id为100的登录状态设置为在线,即1.
192.168.131.171:8006> setbit login_07_04 100 1
(integer) 0
192.168.131.171:8006>
这里返回的0是旧的值,因为bit默认值为0.
2、查询今天7-14,这个用户是否在线:
192.168.131.171:8006> getbit login_07_04 100
(integer) 1
192.168.131.171:8006>
此时返回值1,表示整个用户的状态是已登录。
3、重置这个用户的登录状态:
192.168.131.171:8006> setbit login_07_04 100 0
(integer) 1
192.168.131.171:8006>
将其值设置为0,即默认值。
4、查看当前登录占用的总大小:
192.168.131.171:8006> strlen login_07_04
(integer) 13
192.168.131.171:8006>
虽然我们将值设成了0,也就是默认值,但是数据依然是存在的。
注意:strlen返回的单位是byte!
那为什么是13呢?我们来一起算算:
我们要知道,分配内存空间的时候是按照字节byte为单位进行分配的。
我们设置的用户id是100,也就是100个bit,转化成字节:100 / 8 = 12.5. 所以需要13个byte。
5、查看一下这个login_07_04类型:
在这里插入代码片192.168.131.171:8006> type login_07_04
string
可以看到,bitmap存储的类型也是String, 既然是String, 那么我们使用get命令会获取到吗?
192.168.131.171:8005> get login_07_04
"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00"
192.168.131.171:8006>
虽然可以拿到,但是内容无法解读。所以还是要使用getbit命令来获取准确的值。
6、统计在线的所有的用户数:
在此之前,我们再添加一些用户:
192.168.131.171:8006> setbit login_07_04 100 0
(integer) 0
192.168.131.171:8005> setbit login_07_04 101 1
(integer) 0
192.168.131.171:8005> setbit login_07_04 102 1
(integer) 0
192.168.131.171:8005> setbit login_07_04 103 1
(integer) 0
192.168.131.171:8005>
然后统计在线用户个数:
192.168.131.171:8006> bitcount login_07_04
(integer) 3
192.168.131.171:8006>
我们设置了100~103工4个用户,只有101 ~ 103是1,满足我们设置的3个在线用户。
7、获取分布在字节12~13之间的活跃用户:
192.168.131.171:8005> bitcount login_07_04 12 13
(integer) 2
192.168.131.171:8005>
问题: 如果一开始我们的用户ID就非常大,这样岂不是分配的bitmap会非常大吗?
可以用id减去最小的用户id,这样最小的就是0了,以此推。
bitmap最大存储
2 ^ 32bit = 4,294,967,296 bit = 536,870,912 byte = 524,288KB = 512 MB
bitmap使用场景
适用于用户量非常大,且ID连续的场景。
如果是用户量比较小,比如现在用户就3个,id分别是1, 3, 2^32-1, 那么一下子就要占用512MB的大小,但是事实上的用户才3个。非常浪费空间。
如何统计用户连续多天的登录情况

我们可以将多个不同日期的bitmap进行与运算,然后再对结果使用bitcount就可以统计出连续登录的用户个数。
我们先添加两天的用户用户登录:
127.0.0.1:6380> setbit login_07_04 101 1
(integer) 0
127.0.0.1:6380> setbit login_07_04 100 0
(integer) 0
127.0.0.1:6380> setbit login_07_04 102 1
(integer) 0
127.0.0.1:6380> setbit login_07_04 103 1
(integer) 0
127.0.0.1:6380> setbit login_07_05 100 1
(integer) 0
127.0.0.1:6380> setbit login_07_05 101 0
(integer) 0
127.0.0.1:6380> setbit login_07_05 102 1
(integer) 0
127.0.0.1:6380> setbit login_07_05 103 1
(integer) 0
127.0.0.1:6380>
然后我们来统计4~5好连续登录的用户个数:
首先需要将多天的用户转移到新的bitmap的login_07_04存储。
// bitop 命令用来吧结果写到新的bitmap中
// login_07_04-05 是用来存储结构的新bitmap
// and 表示的是与运算
// login_07_04 login_07_05是要统计的bitmap的key
//
127.0.0.1:6380> bitop and login_07_04-05 login_07_04 login_07_05
(integer) 13
然后我们真正的获取连续两天的活跃用户:
127.0.0.1:6380> bitcount login_07_04-05
(integer) 2
127.0.0.1:6380>
真正活跃的用户只有2个,即102和103.
如何统计周活用户
多个bitmpa之间做或运算,再对结果使用bitcount进行统计。
我们使用上面的数据,4号和5号的,来统计这两天中登录过的用户数:
// or表示或运算
127.0.0.1:6380> bitop or login_07_04-05:active login_07_04 login_07_05
(integer) 13
127.0.0.1:6380> bitcount login_07_04-05:active
(integer) 4
127.0.0.1:6380>
即我们的4个用户在这两天都活跃过。
七、bitmap源码分析
在server.c文件中有一个’setbitCommand’,我们跟进去看看:



bitoffset >>3 就是除以8,获取到key的位置。