Spring源码分析-Bean生命周期循环依赖和三级缓存
Spring源码分析系列
Spring源码分析-启动流程浅析
Spring源码分析-BeanDefinition
Spring源码分析-Bean管理查找与注册(1)
Spring源码分析-Bean管理查找与注册(2)
Spring源码分析-Bean管理循环依赖和三级缓存
Spring源码分析-Bean生命周期概述
Spring源码分析-Bean生命周期createBean
文章目录
- Spring源码分析系列
- 前言
- 一、循环依赖
-
- 1.1、什么是循环依赖
- 1.2、怎么确定出现循环依赖
- 1.3、如何解决循环依赖
- 二、三级缓存
-
- 2.1、三级缓存概念
- 2.2、为什么需要三级缓存
-
- 2.2.1、三级缓存保存内容
- 2.2.2、三级缓存应用场景
- 2.2.2、代码验证
- 2.3.三级缓存能解决所有的循环依赖吗
- 三、总结
前言
本篇博客将进一步分析bean管理内容,主要内容是循环依赖和三级缓存
一、循环依赖
1.1、什么是循环依赖
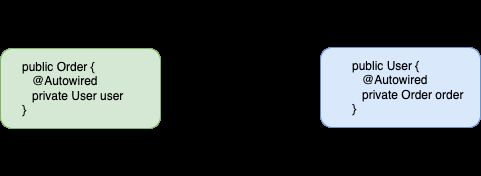
循环依赖:类A中有一个属性是类B,类B中有一个属性是类A,双方互相引用
1.2、怎么确定出现循环依赖
首先一个已完成初始化的bean是可以直接被其他bean进行引用,此时一定不会出现循环依赖,最终得出只有未初始化完成的bean才可能出现循环依赖
判断逻辑:
1)Order正常实例化,属性赋值时发现需要User对象,但是User对象不存在,则转到2)
2)User正常实例化,属性赋值时发现又需要Order对象,由于Order对象在ioc容器中不存在,又转向1)
至此就出现了循环依赖
1.3、如何解决循环依赖
考虑一个问题:当jvm实例化一个对象后,这个对象在被回收之前,内存地址会变吗?答案:当然不会变。这个就是解决循环依赖的关键:将未完成初始化的对象先缓存起来
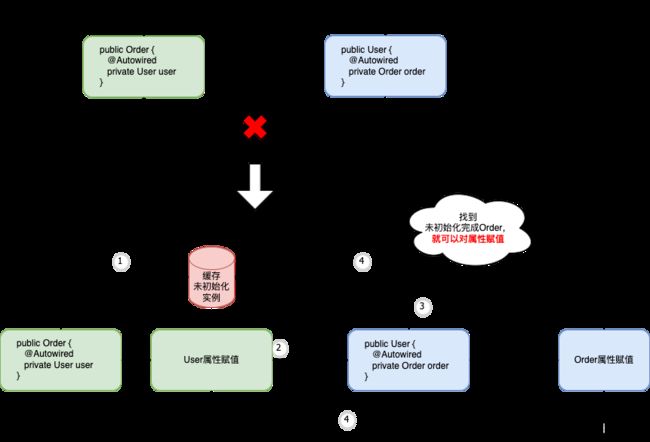
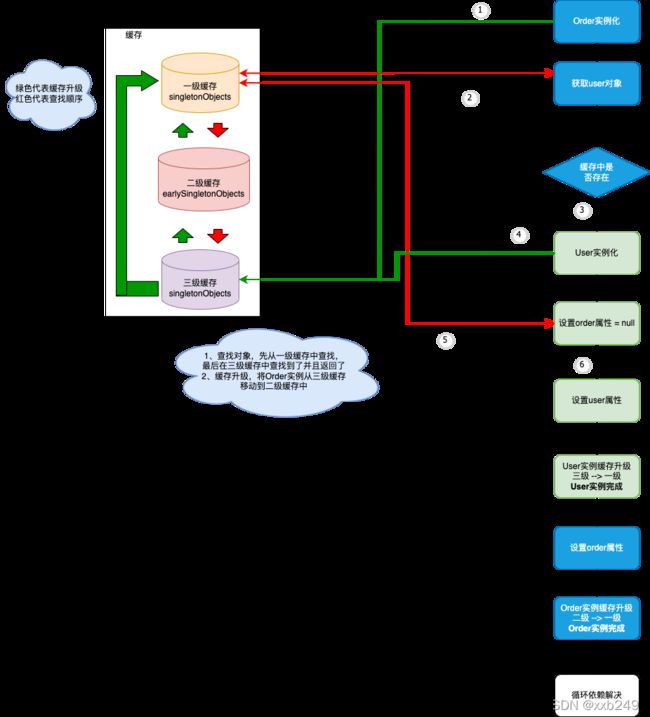
上面这个种方式只是提供了一种解决思路,并不能解决所有场景,所以spring解决方式(三级缓存+缓存升级)如下图所示:
特别说明
对于没有循环依赖的对象,把创建好对象存到三级缓存中,若没有出现循环依赖,bean初始化完成后,会将三级缓存中数据删除(这里是lambda表示)且对象保存到一级缓存中,所以没有二级缓存参与
二、三级缓存
2.1、三级缓存概念
三级缓存听着高大尚,其实本质就是三个map,三级缓存定义在DefaultSingletonBeanRegistry.java,具体是:
/** Cache of singleton objects: bean name to bean instance. */
/** 第一级缓存,存放可用的成品Bean 例如:没有依赖的类对象,可直接放到map中 */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name to ObjectFactory. */
/** 第三级缓存,存的是Bean工厂对象,用以解决动态代理场景下的循环依赖 */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name to bean instance. */
/** 第二级缓存,存放半成品的Bean,半成品的Bean是已创建对象,但是未注入属性和初始化。用以解决循环依赖 */
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
三级缓存体现了一种设计模式:单一职责模式,具体说明:
1)一级缓存singletonObjects,key=bean的名字,value=bean实例对象,这个bean对象是完成了初始后的,是一个完整状态的bean
2)二级缓存,key,value与一级缓存是相同的,但是二级缓存中保存的是未初始化的bean,换句话说只进行了实例化,属性赋值还没有完成。另外二级缓存是为了解决循环依赖的,例如:ObjectA与ObjectB相互依赖,在创建ObjectA的时候,发现ObjectB还没有创建过,则先将ObjectA暂存在二级缓存中,转向创建ObjectB,所以二级缓存里面保存的是一个半成品对象(未完成初始化),不能解决AOP循环依赖问题
3)三级缓存,生成一个包装后的bean对象(本质代理对象),目的解决是AOP场景下的循环依赖问题,value是一个ObjectFactory,在代码中是一个lambda表达式
2.2、为什么需要三级缓存
我在网上搜了很多资料,并没有看到将这个知识点解释的很透彻的博客,所以我力争将其说的透彻一些。
先说一下我的观点:二级缓存,是可以AOP中循环依赖问题,完全不需要三级缓存。我知道我这个观点比较奇葩,和网上说的不一致,但是我会通过原理分析和代码来论证我的观点,如果有人有其他观点,可以留言进行讨论,我会逐一回复。
2.2.1、三级缓存保存内容
三级缓存,保存的是lambda表达式(函数式接口或者回调),代码如下:
//AbstractAutowireCapableBeanFactory.java doCreateBean
//向三级缓存中存lambda表达式
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
// synthetic为true代表BeanDefinition是合成的,通常aop场景下是true
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
//接口SmartInstantiationAwareBeanPostProcessor中getEarlyBeanReference方法,默认直接返回bean对象
//如果配置文件或者注解中开启了AOP则在启动时候会注入 AbstractAutoProxyCreator
//AbstractAutoProxyCreator类中的getEarlyBeanReference将会返回代理对象
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
// exposedObject要么是原始对象要么是代理对象
return exposedObject;
}
我们从三级缓存中能获取到一个lambda表达式,这个表达式返回要么返回原始对象要么返回代理对象,这一点需要牢记。
2.2.2、三级缓存应用场景
场景1)属性赋值前,先将bean对象以lambda表示方式存储到三级缓存中,代码如上一小章节
场景2)在getBean(beanName, true)获取bean对象时,会查三级缓存,若三级缓存中存在bean对象,将bean对象放到二级缓存中且删除三级缓存中数据,代码如下:

思考一个问题:既然三级缓存中生成的对象(原生对象,代理对象),在缓存升级后存到二级中。ok,是不是在存三级的时候,我把对象创建出来,放到二级中,也是可行的?我认为是可行的,这样三级缓存就完全没有作用了。
2.2.2、代码验证
这里需要修改spring的源码,具体修改如下
修改1)注释掉Object getSingleton(String beanName, boolean allowEarlyReference) ,并增加自己写的方法:
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName); //一级缓存获取实例
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
singletonObject = this.earlySingletonObjects.get(beanName); //二级缓存
}
return singletonObject;
}
修改2)修改缓存定义访问权限,由private改成protected,如下:
/** Cache of early singleton objects: bean name to bean instance. */
/** 第二级缓存,存放半成品的Bean,半成品的Bean是已创建对象,但是未注入属性和初始化。用以解决循环依赖 */
protected final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
/** Set of registered singletons, containing the bean names in registration order. */
protected final Set<String> registeredSingletons = new LinkedHashSet<>(256);
修改3) 三级缓存注册的地方改成如下内容:
// AbstractAutowireCapableBeanFactory.java doCreateBean
//先放到 三级缓存 中 这个地方是lambda表达
//注释
//addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
/** add by xuxb 测试代码 需要将缓存声明private 改成 protected */
/** 这里直接获取对象并且注册到二级缓存中 */
Object targetBean = getEarlyBeanReference(beanName, mbd, bean);
earlySingletonObjects.put(beanName, targetBean); //添加二级缓存
registeredSingletons.add(beanName);
以上是spring源码的修改,下面就是验证过程,部分核心代码如下:
@Component
@Aspect
@EnableAspectJAutoProxy
public class MyAspect {
@Before("execution(* com.worker.beans.*.*(..))")
public void before() {
System.out.println("before...");
}
@After("execution(* com.worker.beans.*.*(..))")
public void after() {
System.out.println("after...");
}
}
@Component
public class Orders {
@Autowired
private User user; //互相依赖
public Orders() {
System.out.println("hello orders");
}
public void getOrders() {
System.out.println("Orders is acquired");
}
}
@Component
public class User {
@Autowired
private Orders orders; //互相依赖
public User() {
System.out.println("hello user");
}
public void getName() {
System.out.println("User name is xuxb");
}
}
public class WApp {
public static void main(String[] args) {
try {
//ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("spring.xml");
ApplicationContext context = new AnnotationConfigApplicationContext("com.worker");
User user = context.getBean(User.class);
System.out.println(user);
user.getName();
System.out.println("------------------------");
Orders orders = context.getBean(Orders.class);
System.out.println(orders);
orders.getOrders();
//context.registerShutdownHook();
} catch (Exception e) {
System.out.println(e);
}
}
}
输出结果,是正确的:
> Task :spring-study-01:WApp.main()
hello orders
hello user
com.worker.beans.User@158a8276
before...
User name is xuxb
after...
------------------------
com.worker.beans.Orders@757277dc
before...
Orders is acquired
after...
BUILD SUCCESSFUL in 4s
通过上面的修改,二级缓存应该可以解决AOP循环依赖的问题,但是spring为什么要弄出一个三级缓存呢?
我这里说一下我的想法:spring应该是遵循了一种设计模式:单一职责模式。一级缓存保存的是可直接使用的对象,二级缓存保存的未初始化完成对象,三级缓存用于生成包装bean(代理对象)
2.3.三级缓存能解决所有的循环依赖吗
不能,有一种场景不能解决。那就是在构造方法中出现的循环依赖,具体如下:
@Component
public class User {
public User(Orders orders) {//循环依赖
System.out.println("hello user");
}
public void getName() {
System.out.println("User name is xuxb");
}
}
@Component
public class Orders {
public Orders(User user) {//循环依赖
System.out.println("hello orders");
}
public void getOrders() {
System.out.println("Orders is acquired");
}
}
三、总结
循环依赖是spring面试中常出现的问题,我这里通过理论和分析来进行验证,也许我的观点不正确,若有小伙伴有何疑义欢迎留言讨论。