Matlab实现Kmeans聚类,并利用匈牙利算法Kuhn-Munkres实现对聚类标签和真实标签的映射,对结果进行聚类精度Accuracy评价和标准互信息Nmi评价
Matlab实现Kmeans聚类,并利用匈牙利算法Kuhn-Munkres实现对聚类标签和真实标签的映射,对结果进行聚类精度Accuracy评价和标准互信息Nmi评价
- 思路
- 输入数据为经典MNIST数据集
- 利用Matlab中Kmeans算法对数据进行聚类
- 聚类精度Acc评价
- 标准互信息NMI评价
- 利用Kuhn-Munkres算法实现munkres方法
- 对Kmeans聚类结果进行映射
-
-
- 聚类结果和真实标签进行映射的核心思路
- 将存储点分布的空间矩阵转换为一个行向量的辅助方法
-
- Acc计算实现
- Nmi计算实现
- Kmeans聚类并评价
- 运行结果
思路
- 利用Kmeans算法对数据进行聚类,生成聚类结果
- 将聚类结果的标签和真实标签进行映射,生成映射后标签
- 利用映射后标签和真实标签进行计算Accuracy值
- 利用聚类结果标签和真实标签计算Nmi值
输入数据为经典MNIST数据集
MNIST数据集是机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。
我们选取MNIST数据集中的10类共3000条数据为例。
- 数据下载网址:http://yann.lecun.com/exdb/mnist/
利用Matlab中Kmeans算法对数据进行聚类
clc,clear;
load E:\2019\机器学习\实验一\data\MNIST;
opts = statset('Display','final');
K=10; %将X划分为K类
repN=50; %迭代次数
%K-mean聚类
[Idx,Ctrs,SumD,D] = kmeans(X,K,'Replicates',repN,'Options',opts);
聚类精度Acc评价
聚类精度(Acc):给定一个聚类结果标签 和其对应的指示标签 ,Acc计算公式如下:
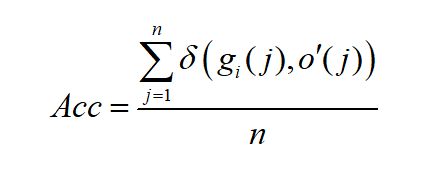
其中:
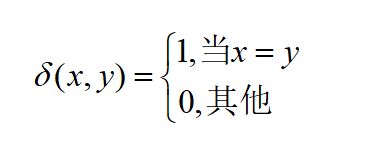
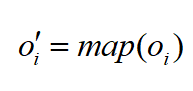
map(oi)是一个映射函数,它以真实标签 gi作为参考标签,然后按照相同的排列方式oi中的标签顺序进行重排。因此, map(oi)是用来解决标签不一致问题。通常可采用经典的Kuhn-Munkres算法实现 的重排。
标准互信息NMI评价
标准互信息(NMI):互信息(MI)是一种堆成的度量方式,他可以衡量两种分布之间相互依赖程度,判断两种分布的一致性。设 cp表示真实标签 c中的第gi 类,c’q表示oi中的第 q类,则对应的MI可定义为:
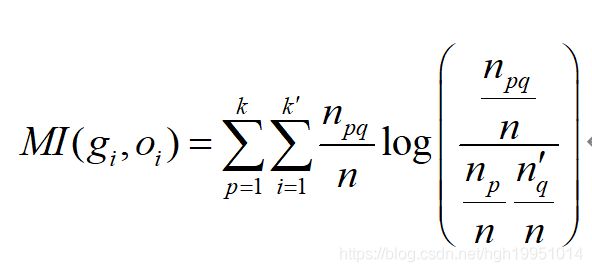
其中k和k’分别表示真实标签和聚类标签对应的类别数。np表示类别cp包含的样本数,n’q表示类别c’q中包含的样本数,npq表示同时出现在类别cp和c’q中的样本数,那么标准互信息可以定义为:
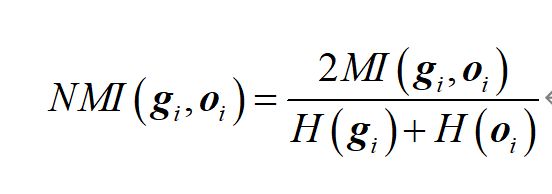
其中H(g)是熵函数。根据上述两式,有:
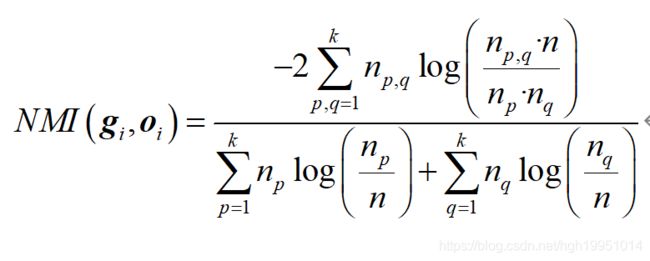
利用Kuhn-Munkres算法实现munkres方法
匈牙利算法很经典,一般用来解决最优分配问题,这里从Matlab论坛上找到一个比较好的实现,网上有很多帖子对匈牙利算法的原理讲的都很不错,这里推荐一个详细官方英文文档讲解:匈牙利算法官网英文文档
function [assignment] = munkres(costMat)
% MUNKRES Munkres Assign Algorithm
%
% [ASSIGN,COST] = munkres(COSTMAT) returns the optimal assignment in ASSIGN
% with the minimum COST based on the assignment problem represented by the
% COSTMAT, where the (i,j)th element represents the cost to assign the jth
% job to the ith worker.
%
% This is vectorized implementation of the algorithm. It is the fastest
% among all Matlab implementations of the algorithm.
% Examples
% Example 1: a 5 x 5 example
%{
[assignment,cost] = munkres(magic(5));
[assignedrows,dum]=find(assignment);
disp(assignedrows'); % 3 2 1 5 4
disp(cost); %15
%}
% Example 2: 400 x 400 random data
%{
n=5;
A=rand(n);
tic
[a,b]=munkres(A);
toc
%}
% Reference:
% "Munkres' Assignment Algorithm, Modified for Rectangular Matrices",
% http://csclab.murraystate.edu/bob.pilgrim/445/munkres.html
% version 1.0 by Yi Cao at Cranfield University on 17th June 2008
assignment = false(size(costMat));
costMat(costMat~=costMat)=Inf;
validMat = costMat<Inf;
validCol = any(validMat);
validRow = any(validMat,2);
nRows = sum(validRow);
nCols = sum(validCol);
n = max(nRows,nCols);
if ~n
return
end
dMat = zeros(n);
dMat(1:nRows,1:nCols) = costMat(validRow,validCol);
%*************************************************
% Munkres' Assignment Algorithm starts here
%*************************************************
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% STEP 1: Subtract the row minimum from each row.
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
dMat = bsxfun(@minus, dMat, min(dMat,[],2));
%**************************************************************************
% STEP 2: Find a zero of dMat. If there are no starred zeros in its
% column or row start the zero. Repeat for each zero
%**************************************************************************
zP = ~dMat;
starZ = false(n);
while any(zP(:))
[r,c]=find(zP,1);
starZ(r,c)=true;
zP(r,:)=false;
zP(:,c)=false;
end
while 1
%**************************************************************************
% STEP 3: Cover each column with a starred zero. If all the columns are
% covered then the matching is maximum
%**************************************************************************
primeZ = false(n);
coverColumn = any(starZ);
if ~any(~coverColumn)
break
end
coverRow = false(n,1);
while 1
%**************************************************************************
% STEP 4: Find a noncovered zero and prime it. If there is no starred
% zero in the row containing this primed zero, Go to Step 5.
% Otherwise, cover this row and uncover the column containing
% the starred zero. Continue in this manner until there are no
% uncovered zeros left. Save the smallest uncovered value and
% Go to Step 6.
%**************************************************************************
zP(:) = false;
zP(~coverRow,~coverColumn) = ~dMat(~coverRow,~coverColumn);
Step = 6;
while any(any(zP(~coverRow,~coverColumn)))
[uZr,uZc] = find(zP,1);
primeZ(uZr,uZc) = true;
stz = starZ(uZr,:);
if ~any(stz)
Step = 5;
break;
end
coverRow(uZr) = true;
coverColumn(stz) = false;
zP(uZr,:) = false;
zP(~coverRow,stz) = ~dMat(~coverRow,stz);
end
if Step == 6
% *************************************************************************
% STEP 6: Add the minimum uncovered value to every element of each covered
% row, and subtract it from every element of each uncovered column.
% Return to Step 4 without altering any stars, primes, or covered lines.
%**************************************************************************
M=dMat(~coverRow,~coverColumn);
minval=min(min(M));
if minval==inf
return
end
dMat(coverRow,coverColumn)=dMat(coverRow,coverColumn)+minval;
dMat(~coverRow,~coverColumn)=M-minval;
else
break
end
end
%**************************************************************************
% STEP 5:
% Construct a series of alternating primed and starred zeros as
% follows:
% Let Z0 represent the uncovered primed zero found in Step 4.
% Let Z1 denote the starred zero in the column of Z0 (if any).
% Let Z2 denote the primed zero in the row of Z1 (there will always
% be one). Continue until the series terminates at a primed zero
% that has no starred zero in its column. Unstar each starred
% zero of the series, star each primed zero of the series, erase
% all primes and uncover every line in the matrix. Return to Step 3.
%**************************************************************************
rowZ1 = starZ(:,uZc);
starZ(uZr,uZc)=true;
while any(rowZ1)
starZ(rowZ1,uZc)=false;
uZc = primeZ(rowZ1,:);
uZr = rowZ1;
rowZ1 = starZ(:,uZc);
starZ(uZr,uZc)=true;
end
end
%生成标签矩阵
assignment(validRow,validCol) = starZ(1:nRows,1:nCols);
%解决标签映射问题不需要计算权重cost,故将其注释
%cost = 0;
%cost = sum(costMat(assignment));
对Kmeans聚类结果进行映射
function [NewLabel] = BestMapping(La1,La2)
%真实标签:La1 聚类结果标签:La2 映射后的标签:NewLabel
Label1=unique(La1');
L1=length(Label1);
Label2=unique(La2');
L2=length(Label2);
%构建计算两种分类标签重复度的矩阵G
G = zeros(max(L1,L2),max(L1,L2));
for i=1:L1
index1= La1==Label1(1,i);
for j=1:L2
index2= La2==Label2(1,j);
G(i,j)=sum(index1.*index2);
end
end
%利用匈牙利算法计算出映射重排后的矩阵
[index]=munkres(-G);
%将映射重排结果转换为一个存储有映射重排后标签顺序的行向量
[temp]=MarkReplace(index);
%生成映射重排后的标签NewLabel
NewLabel=zeros(size(La2));
for i=1:L2
NewLabel(La2==Label2(i))=temp(i);
end
end
聚类结果和真实标签进行映射的核心思路
设真实标签有m类,聚类结果标签有n类,L=max(m,n)。生成一个大小为L*L且元素均为0的矩阵。本文中的聚类结果类别数目和真实标签类别数目一样,即m=n。计算真实标签和聚类标签结果的重复度,并将结果存储在矩阵G中,这个计算过程体现在以下代码里:
for i=1:L1
index1= La1==Label1(1,i);
for j=1:L2
index2= La2==Label2(1,j);
G(i,j)=sum(index1.*index2);
end
end
其中循环结构中分别将真实标签、聚类结果标签中相同类别的点的分布用01列矩阵表示了出来。然后对两个01列矩阵进行点乘求和运算,下面画了一个示意图:
可以看到相同分布的地方经过点乘后会得到1,不同分布的地方点乘后得到0,这样点乘后的矩阵里面的1表示聚类标签和真实标签相同重复的地方,对这一列求和得到的数字就是聚类结果和真实结果的重复度,将这个结果记录在矩阵G里,同理依次求出聚类结果标签m类和真实标签n类的m*n个重复度,分别记录在G中。
按照思路我们直接找出G中每一行中重复度最大的值,确定它的位置就可以了,但是这样的话会出现多个不同行的重复度最大的值在同一列的情况(即真实标签和聚类结果标签的映射不是1对1),这显然是不合理的。
我们发现这个问题其实就是一个最佳分配问题,所以可以利用匈牙利算法解决。这样就可以成功找到真实标签和聚类结果标签1对1的映射。
将存储点分布的空间矩阵转换为一个行向量的辅助方法
%将存储标签顺序的空间矩阵转换为一个行向量
function [assignment] = MarkReplace(MarkMat)
[rows,cols]=size(MarkMat);
assignment=zeros(1,cols);
for i=1:rows
for j=1:cols
if MarkMat(i,j)==1
assignment(1,j)=i;
end
end
end
end
Acc计算实现
function acc = Acc(Label1,Label2)
%Label1:真实标签 Label2:映射后的标签
T= Label1==Label2;
acc=sum(T)/length(Label2);
end
Nmi计算实现
function nmi = Nmi(A,B)
%A:真实标签 B:聚类标签
%NMI Normalized mutual information
% http://en.wikipedia.org/wiki/Mutual_information
% http://nlp.stanford.edu/IR-book/html/htmledition/evaluation-of-clustering-1.html
if length( A ) ~= length( B)
error('length( A ) must == length( B)');
end
total = length(A);
A_ids = unique(A);
A_class = length(A_ids);
B_ids = unique(B);
B_class = length(B_ids);
% Mutual information
idAOccur = double (repmat( A, A_class, 1) == repmat( A_ids', 1, total ));
idBOccur = double (repmat( B, B_class, 1) == repmat( B_ids', 1, total ));
idABOccur = idAOccur * idBOccur';
Px = sum(idAOccur') / total;
Py = sum(idBOccur') / total;
Pxy = idABOccur / total;
MImatrix = Pxy .* log2(Pxy ./(Px' * Py)+eps);
MI = sum(MImatrix(:));
% Entropies
Hx = -sum(Px .* log2(Px + eps),2);
Hy = -sum(Py .* log2(Py + eps),2);
%Normalized Mutual information
nmi = 2 * MI / (Hx+Hy);
% Nmi = MI / sqrt(Hx*Hy); another version of NMI
end
Kmeans聚类并评价
clc,clear;
load E:\2019\机器学习\实验一\data\MNIST;
K=10; %将X划分为K类
repN=50; %迭代次数
opts = statset('Display','final');
%K-mean聚类
[Idx,Ctrs,SumD,D] = kmeans(X,K,'Replicates',repN,'Options',opts);
%打印结果
fprintf('划分成%d类的结果如下:\n',K)
for i=1:K
tm=find(Idx==i); %求第i类的对象
tm=reshape(tm,1,length(tm)); %变成行向量
fprintf('第%d类共%d个分别是%s\n',i,length(tm),int2str(tm)); %显示分类结果
end
%进行映射操作
[NewLabel]=BestMapping(Y,Idx);
%Y:真实标签 Idx:聚类标签 NewLabel:映射重排后的标签
%ACC
acc=Acc(Y,NewLabel);
fprintf('聚类的精度Acc为:%f\n',acc); %显示分类结果
%NMI
nmi=Nmi(Y',Idx');
fprintf('聚类的标准互信息Nmi为:%f\n',nmi); %显示分类结果
运行结果
