数据库---索引和事务
目录
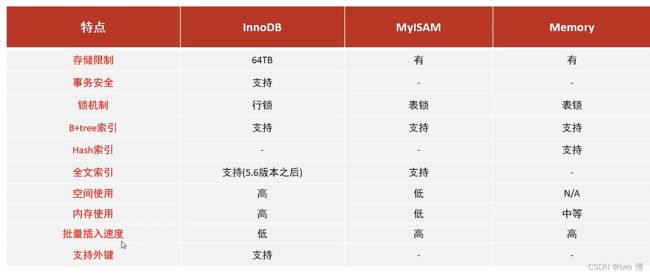
存储引擎
InooDB存储引擎
MyISAM存储引擎
Memory存储引擎
磁盘IO
索引
B树
B+树
B+树为什么更适合于索引结构
索引语法
事务
事务的概念
事务的操作过程
事务操作
方法一:设置手动提交
方法二:借助事务指令
事务的四大特性
并发事务问题
数据库的事务隔离
mysql对事务隔离的操作
存储引擎
存储引擎是数据库中用于存储数据,组织数据,建立数据的实现方式
存储引擎是基于表的
- show create table 表名 :查看某一张表的建表语句
show create table student;

- show engines : 查询当前数据库所支持的存储引擎

- 在创建表的时候指定存储引擎
create table memory
(
id int,
name varchar(20)
)engine=MEMORY;-- 指定存储引擎InooDB存储引擎
是mysql的默认存储引擎
InooDB的特点:

InooDB的逻辑存储结构
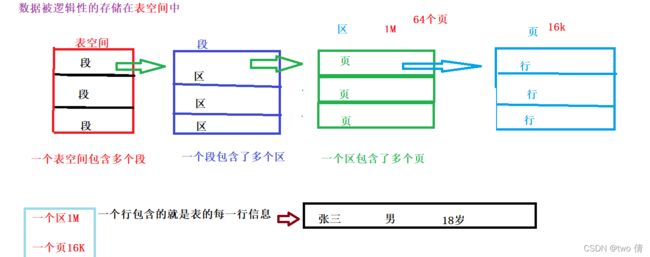
页是数据库存储的最小单位 每页都保存了一行一行的数据,我们按照页为单位将磁盘的数据加载到内存的缓存页中,也是按照页为单位,将内存缓存页的数据存入磁盘
MyISAM存储引擎
 Memory存储引擎
Memory存储引擎

磁盘IO
磁盘的读取操作成为磁盘IO。在数据库中,磁盘的读取操作都是对页的操作
索引
索引是一种用于查找的数据结构
索引存在的目的:增加查找速率 缺点:降低增删改的速度,占用空间
索引是一种数据结构,我们学习的数据结构有顺序表,链表,栈,堆,队列,二叉树,哈希表等,那么用的是哪一种数据结构呢?
顺序表和链表:遍历元素,时间复杂度o(n)栈,队列,都不适合用于查找
二叉树:二叉排序树查找效率较高,但是二叉树在递增或者递减序列中,会变成单分支的树(链表)查找效率低
哈希表:查找效率高,但是查找的是某一个具体的值,不适合范围查找
堆:找到最大或者最小值
那么,没有一个适合索引的数据结构吗?其实是有的,那就是B+树
B+树是大部分存储引擎所支持的索引结构,其次应用较多的是hash索引
了解B+树,得先了解B树
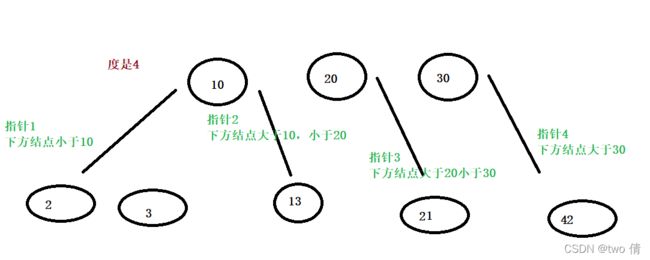
B树
B树的形式:多个分支
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
借助这个网站,动态生成各种数据结构
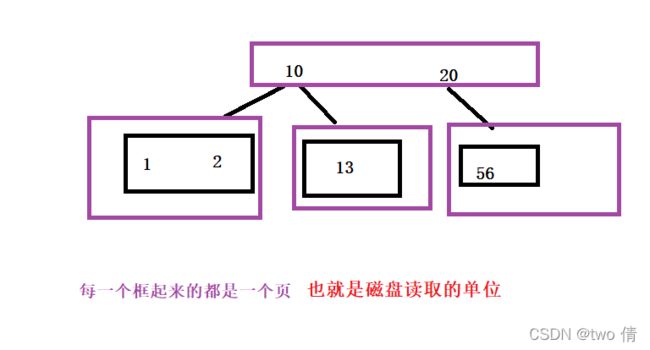
B树的构建过程
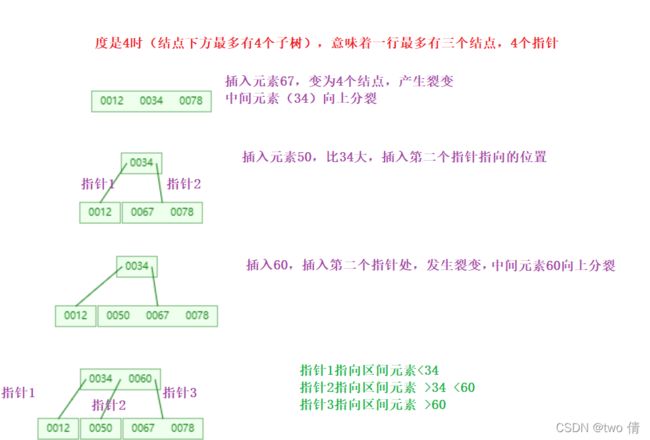
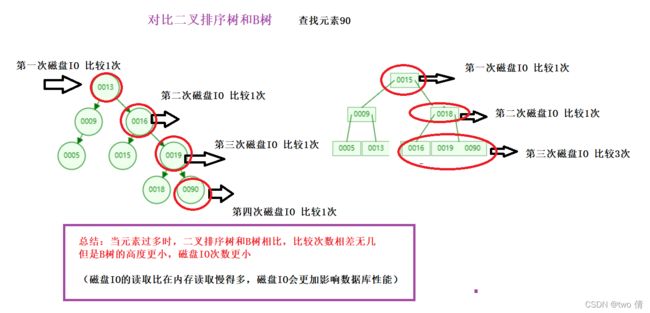
B树的好处: 采用多分支结构,层次更低,减小磁盘IO次数
B+树
B+树在B树的基础上演变而来
B+树的构建过程
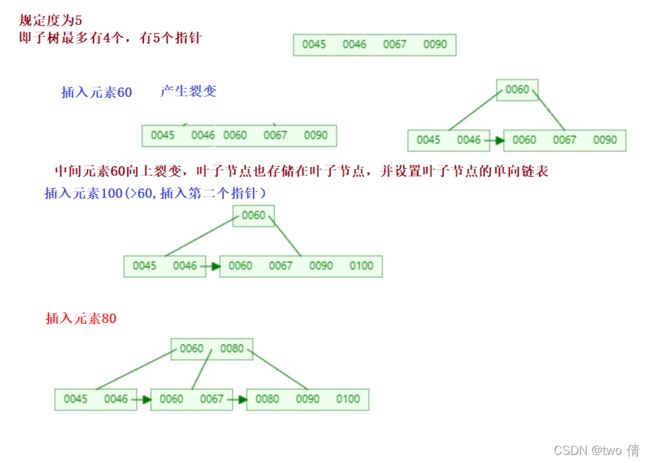
B+树的最终形式类似于:
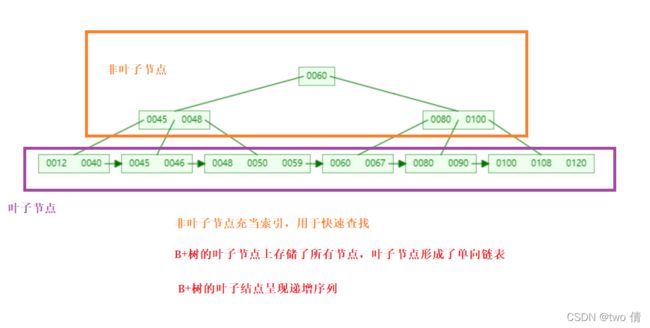
B+树的特点
B+树的叶子节点上存储了所有节点,叶子节点形成了单向链表(且元素递增)
叶子节点存放的不只是索引值,还存储了元素的全部信息(key-value)
B+树为什么更适合于索引结构
相比于二叉树:
1、查找元素时,根据非叶子节点的索引结构来确定查找区间,减少磁盘io次数
相比于B树:
2、叶子节点存储了元素的所有信息,且形成了递增的单向链表,适用于范围查找
3、非叶子节点只是索引结构(相当于只存储key-value的key值),没有实际的存在意义,占用空间小,甚至可以存储在内存中(存放在内存中,表示索引结构不占用磁盘io)
一个页的空间是16k,相比于B树来说,B+树的非叶子节点内存
4、叶子节点保留了所有的元素,查找某一元素最终都会落在叶子节点上,查找效率稳定
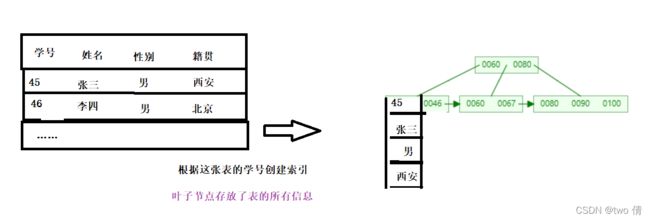
索引分类
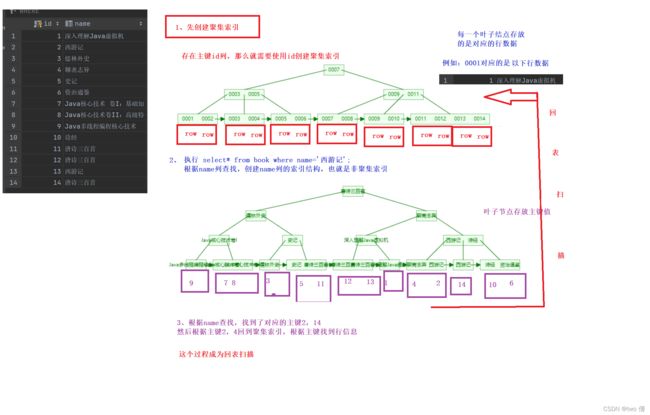
索引可以分成两种存储形式:聚集索引和辅助索引
聚集索引:将索引和数据一起存储,索引结构的叶子节点保留了行数据---》必须有且只有一个
辅助索引:将索引和数据分开存储,索引结构的叶子节点对应了主键---》可以有多个
聚集索引的选取规则:
- 存在主键,则主键是聚集索引
- 没有主键,则选取第一个唯一索引成为聚集索引
- 1,2都不满足,innodb存储引擎会默认生成一个rowid作为默认聚集索引
聚集索引的特点:聚集索引行数据的物理存放和主键的逻辑顺序相同
辅助索引的特点:聚集索引行数据的物理存放和主键的逻辑顺序不一定相同
索引语法
- 查看索引
show index from 表名
- 创建索引
create index 索引名 on 表名(字段名)
创建主键约束(primary key),唯一约束(unique),外键约束(foreign key)时会自动创建对应列的索引
create table s (id int,name varchar(10) unique ,gender char(1), primary key (id));
show index from s;
索引创建
-- 对于student表,name可能重复,为name创建索引
create index idx_student_name on student (name);
show index from student;
加unique修饰
-- 对于student表,id不能重复
create unique index idx_student_id on student(id);
show index from student;
insert student(gender) values('女');
select * from student;
- 删除索引
drop index 索引名 on 表名
drop index idx_student_name on student;
drop index idx_student_id on student;
show index from student;
事务
事务的概念
将所有操作打包在一起,这些操作要么同时成功,要么同时失败
同时失败指将发生异常之前的操作中对数据的更改还原回去(事务回滚)

事务的操作过程
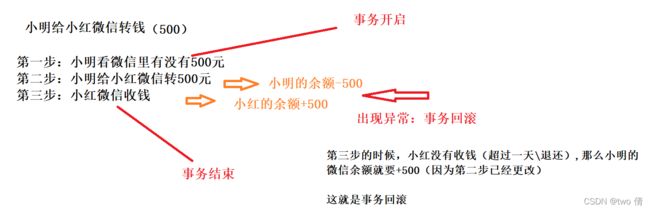
mysql的事务提交是自动提交的
创建一张表,来完成转账操作
create table accout(
id int primary key auto_increment,
name varchar(20),
account int
);
insert accout values(null,"小明",500),(null,"小红",0);
select * from accout;转账成功情况下:
-- 第一步 小明的余额是否超过500
select account from accout where name="小明";
-- 第二步:余额如果超过500,小明余额减500
update accout set account=account-500 where name="小明";
-- 第三步:小红余额加500
update accout set account=account+500 where name="小红";
转账不成功情况下:
假设第三步发生异常
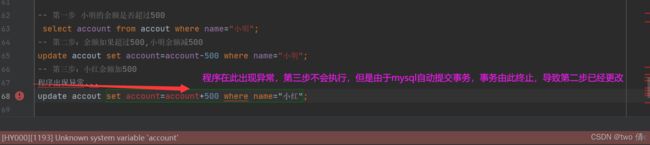
这显然是不合理的,小明的余额应该回溯到之前的余额,这就涉及到了事务回滚
事务操作
- 查看事务的提交方式
select @@autocommit;
结果为1,自动提交,结果为0,手动提交
mysql的事务提交是默认自动提交的

- 修改事务的提交为手动提交
set @@autocommit=0;
set @@autocommit=0;
select @@autocommit;
- 提交事务 关键字:commit
- 回滚事务 关键字:rollback
方法一:设置手动提交
正常执行:
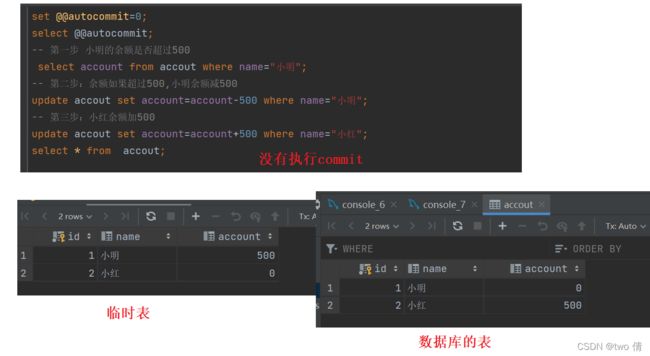
设置手动提交,不执行commit操作,就只是对临时表的修改,也就是查询结果是修改了的,但是数据库中的表并没有被修改
set @@autocommit=0;
select @@autocommit;
-- 第一步 小明的余额是否超过500
select account from accout where name="小明";
-- 第二步:余额如果超过500,小明余额减500
update accout set account=account-500 where name="小明";
-- 第三步:小红余额加500
update accout set account=account+500 where name="小红";
commit;执行了commit操作,数据库的表才会被修改
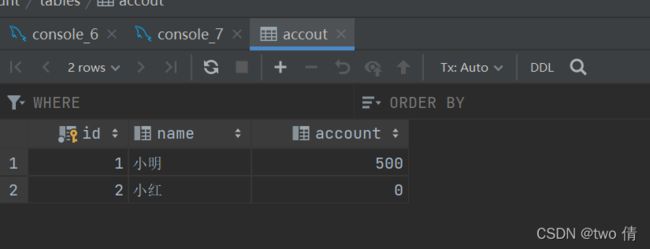
-- 先将数据恢复回去
update accout set account=500 where name="小明" ;
update accout set account=0 where name="小红" ;
commit;设置了手动提交,不在事务内的语句也得执行commit操作,否则数据修改无法提交给数据库
异常执行:
-- 第一步 小明的余额是否超过500
select account from accout where name="小明";
-- 第二步:余额如果超过500,小明余额减500
update accout set account=account-500 where name="小明";
-- 第三步:小红余额加500
程序出现异常...
update accout set account=account+500 where name="小红";
select * from accout; -- 临时表的数据中只有小明的余额减500,小红的没改变 -- 数据库的数据仍然是500,0
rollback ;-- 事务回滚
select * from accout;-- -- 临时表的数据中小明余额500,小红的没改变 -- 数据库的数据仍然是500,0方法一总结:使用方法一设置手动提交,如果不进行commit操作,对所有数据的更改,都只会是对临时表的更改;发生异常,也是对临时表的更改,使用rollback关键字,可以将在异常之前对临时表的更改恢复回去,但是也是对临时表的修改,只要不进行commit操作,都不会影响实际数据
方法二:借助事务指令
- 开启事务 :关键字begin
- 提交事务 关键字:commit
- 回滚事务 关键字:rollback
-- 开启事务
begin ;
-- 第一步 小明的余额是否超过500
select account from accout where name="小明";
-- 第二步:余额如果超过500,小明余额减500
update accout set account=account-500 where name="小明";
-- 第三步:小红余额加500
update accout set account=account+500 where name="小红";
select * from accout;
-- 事务正常进行
commit;
-- 事务异常
rollback ;和方法一的操作一致,异常rollback,正常commit
事物内部仍然是对临时表的修改(需要手动commit )但是在事务之外,仍然是自动提交
事务的四大特性
原子性:一个事务内的操作必须同时成功或者同时失败,意味着事务是不可划分的最小单位
一致性:事务完成时,数据必须保持合理(例如:转账前后两人总和与之前的相等,金额不存在负数等等,数据要合理且正确)
隔离性:数据库系统提供的隔离机制,使得事务之间不会收到并发影响
持久性:数据一旦提交到了数据库中,对数据库中数据的更改是持久的
并发事务问题
从操作系统的角度来理解:并发指的是两个事件或者多个事件在相同的时间间隔内发生,但是在宏观上看来就是两个事件或者多个事件同时进行
程序运行的本质是将程序加载进入内存,并分配cpu
但电脑即使是单核cpu,也可以同时运行多个程序,例如电脑分屏(同时开启两个程序),这就是因为cpu在极小的时间间隔之内轮流给两个程序分配空间,在宏观上产生两个程序同时运行的现象
对于事务来说,也会收到并发性的影响
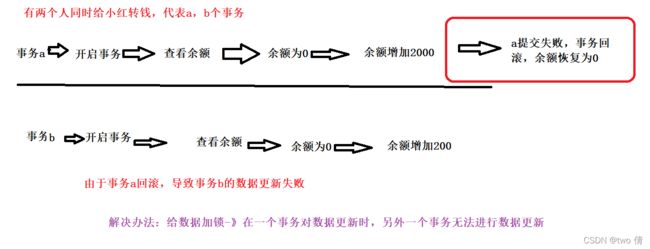
1、丢失更新
两个事务T1和T2读入同一个数据并修改,T2提交的结果覆盖了T1提交的结果,导致T1的修改被丢失。 数据丢失可以避免,在事务修改数据时,不允许其他事务读取数据
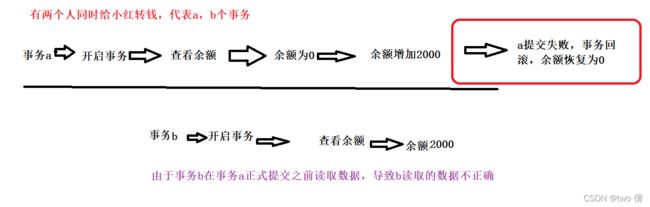
2、脏读
两个事务T1和T2,T2在T1提交数据之前获得了T1的数据,得到了错误数据
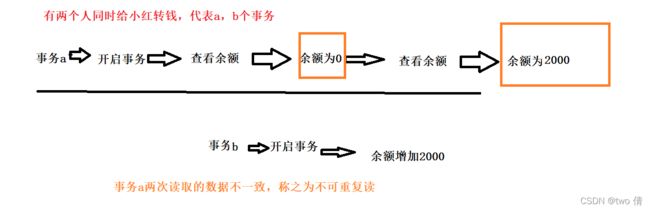
3、不可重复读
T1和T2两个事务,T1多次读取数据,但是T2在之间对T1进行了数据修改,导致两次数据读取不一致
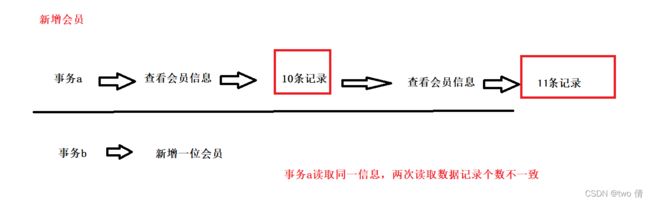
4、幻读
T1,T2两个事务,T1读取事务,T2新增记录,T1再次读取,发现读取的记录多了几条
区别:
丢失更新:一个事务因为另外一个事务,导致数据更新不成功
幻读:一个事务重复读取同一个数据,但是因为另外一个事务对数据进行新增,导致两次读取的数据个数不一致
不可重复读:一个事务重复读取同一个数据,但是因为另外一个事务对数据进行修改,导致两次数据不一致
脏读:一个事务读取到了另外一个事务在没有提交之前修改的数据,导致此事务读取的数据是错误的
丢失更新可以通过设置锁来解决,其他三个问题都是因为不一致导致的,需要进行并发控制,为了兼顾并发效率与异常控制,定义了4种隔离级别
数据库的事务隔离
read uncommitted(读未提交数据)
如果一个事务已经开始写数据,则另外一个事务则不允许同时进行写操作,但允许其他事务读此数据。该隔离级别可以通过“排他写锁”实现。
避免了更新丢失,却可能出现脏读、不可重复读、幻读的情况
read committed(读已提交数据)
如果一个事务正在读取数据,则其他事务也可以读取数据
但是如果一个事务正在写数据,但是还没有提交这个事务,那么不允许其他事务读取这个事务
(事务A事先读取了数据,事务B紧接着更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变:不可重复读)
该隔离级别避免了脏读,更新丢失,但是却可能出现不可重复读、幻读的情况
repeatable read(可重复读)mysql的默认级别
如果一个事务正在读取数据,则其他事务也可以读取数据,但是不允许其他事务修改数据
(一旦事务开始读取,读取完毕不会马上解锁,而是等到事务结束后再解锁:(事务A事先读取了数据,就已经不允许事务B修改这个数据了,就在上一个的基础上解决了不可重复读问题)
如果一个事务正在写数据,则禁止其他事务对这个事务的任何操作
解决了不可重复读和脏读,丢失更新,但是可能出现幻读
serializable(可串行化)
提供严格的事务隔离。它要求事务序列化执行,事务只能一个接着一个地执行,不能并发执行。
解决了幻读,不可重复读和脏读,丢失更新
| 隔离级别 | 丢失更新 | 脏读 | 不可重复读 | 幻读 |
| read uncommitted(读未提交数据) | √ | × | × | × |
| read committed(读已提交数据) | √ | √ | × | × |
| repeatable read(可重复读) | √ | √ | √ | × |
| serializable(可串行化) | √ | √ | √ | √ |
mysql对事务隔离的操作
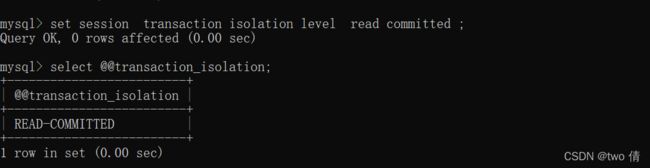
select @@transaction_isolation; 查看当前的事务隔离类别

![]() session:仅对当前会话窗口有效
session:仅对当前会话窗口有效
gloabl:对所有会话窗口有效
set session transaction isolation level read committed ;
select @@transaction_isolation;