从 Reactive 到 WebFlux 1
OK,还记得我开博客的第一篇文章就是想好好学习一下WebFlux,前段时间学习SpringBoot也就是想慢慢的学到这里来,然后和大家分享一下,在讲之前大家可以看看函数式编程基础了解一下。
在讲之前我想提一些问题,我们是否经常在网上看到这样一些关于reactive的讲法:
1.Reactive 是异步非阻塞编程
2.Reactive 能够提升程序性能
3.Reactive 解决传统编程模型遇到的困境
在讲解reactive之前,我们还是从传统的编程模型说起:
传统的编程模型往往是阻塞式的,那么有办法对传统编程模型进行改进吗?一般来说有两种方法
1. parallelize: use more threads and more hardware resources.
2. seek more efficiency in how current resources are used
一种是多线程,另一种就是资源有限(例如CPU)情况下,尽可能最大化CPU。
但是Reactor 认为阻塞可能是浪费的:
1.阻塞导致性能瓶颈和浪费资源
2.增加线程可能会引起资源竞争和并发问题
3.并行的方式不是银弹(不能解决所有问题)
我们看一个阻塞式的编程:

public class DataLoader {
public final void load() {
long startTime = System.currentTimeMillis(); // 开始时间
doLoad(); // 具体执行
long costTime = System.currentTimeMillis() - startTime; // 消耗时间
System.out.println("load() 总耗时:" + costTime + " 毫秒");
}
protected void doLoad() { // 串行计算
loadConfigurations(); // 耗时 1s
loadUsers(); // 耗时 2s
loadOrders(); // 耗时 3s
} // 总耗时 1s + 2s + 3s = 6s
protected final void loadConfigurations() {
loadMock("loadConfigurations()", 1);
}
protected final void loadUsers() {
loadMock("loadUsers()", 2);
}
protected final void loadOrders() {
loadMock("loadOrders()", 3);
}
private void loadMock(String source, int seconds) {
try {
long startTime = System.currentTimeMillis();
long milliseconds = TimeUnit.SECONDS.toMillis(seconds);
Thread.sleep(milliseconds);
long costTime = System.currentTimeMillis() - startTime;
System.out.printf("[线程 : %s] %s 耗时 : %d 毫秒\n",
Thread.currentThread().getName(), source, costTime);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) {
new DataLoader().load();
}
}由于串行执行的关系,导致消耗实现线性累加。Blocking 模式即串行执行 。
那我们变成并行的方式又会怎样呢?
public class ParallelDataLoader extends DataLoader {
protected void doLoad() { // 并行计算
ExecutorService executorService = Executors.newFixedThreadPool(3); // 创建线程池
CompletionService completionService = new ExecutorCompletionService(executorService);
completionService.submit(super::loadConfigurations, null); // 耗时 >= 1s
completionService.submit(super::loadUsers, null); // 耗时 >= 2s
completionService.submit(super::loadOrders, null); // 耗时 >= 3s
int count = 0;
while (count < 3) { // 等待三个任务完成
if (completionService.poll() != null) {
count++;
}
}
executorService.shutdown();
} // 总耗时 max(1s, 2s, 3s) >= 3s
public static void main(String[] args) {
new ParallelDataLoader().load();
}
}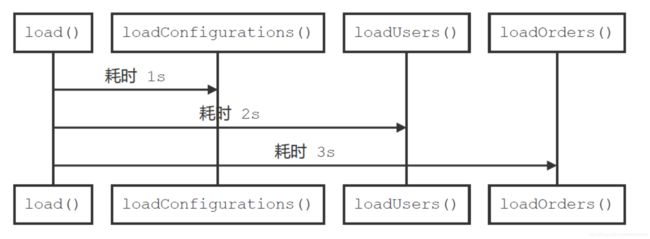
明显地,程序改造为并行加载后,性能和资源利用率得到提升,消耗时间取最大者
延伸思考
1. 如果阻塞导致性能瓶颈和资源浪费的话,Reactive 也能解决这个问题?
2. 为什么不直接使用 Future#get() 方法强制所有任务执行完毕,然后再统计总耗时?
3. 由于以上三个方法之间没有数据依赖关系,所以执行方式由串行调整为并行后,能够达到性能提升的效果。如果方法之间存在依赖关系时,那么提升效果是否还会如此明显,并且如何确保它们的执行顺序?
所以针对上述问题,Reactor 认为异步不一定能够救赎,因为:
1.Callbacks 是解决非阻塞的方案,然而他们之间很难组合,并且快速地将代码引导至 "Callback Hell"的不归路。什么是Callback Hell?就是太多的回调函数,会泛滥成灾,比如在以前的java GUI中,复杂的话会加入一大堆的Listener,吓死人。
2.Futures 相对于 Callbacks 好一点,不过还是无法组合,不过 CompletableFuture 能够提升这方面的不足。
我们在看看眼神思考中的第二个问题:为什么不直接使用 Future#get() 方法强制所有任务执行完毕,然后再统计总耗时?
如果 DataLoader 的 loadOrders() 方法依赖于 loadUsers() 的结果,而 loadUsers() 又依赖于loadConfigurations() ,调整实现:
public class FutureBlockingDataLoader extends DataLoader {
protected void doLoad() {
ExecutorService executorService = Executors.newFixedThreadPool(3); // 创建线程池
runCompletely(executorService.submit(super::loadConfigurations));
runCompletely(executorService.submit(super::loadUsers));
runCompletely(executorService.submit(super::loadOrders));
executorService.shutdown();
}
private void runCompletely(Future future) {
try {
future.get();
} catch (Exception e) {
}
}
public static void main(String[] args) {
new FutureBlockingDataLoader().load();
}
}Future#get() 方法不得不等待任务执行完成,换言之,如果多个任务提交后,返回的多个 Future逐一调用 get() 方法时,将会依次 blocking,任务的执行从并行变为串行。由于 Future 无法实现异步执行结果链式处理,尽管 FutureBlockingDataLoader 能够解决方法数据依赖以及顺序执行的问题,不过它将并行执行带回了阻塞(串行)执行。所以,它不是一个理想实现。不过CompletableFuture 可以帮助提升 Future 的限制:
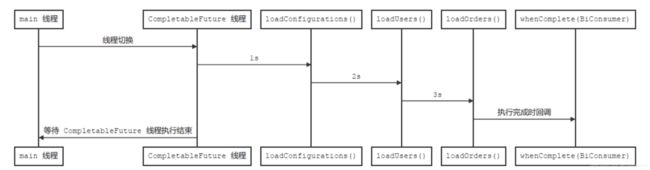
public class ChainDataLoader extends DataLoader {
protected void doLoad() {
// main -> submit -> ...
// sub-thread : F1 -> F2 -> F3
CompletableFuture
.runAsync(super::loadConfigurations)
.thenRun(super::loadUsers)
.thenRun(super::loadOrders)
.whenComplete((result, throwable) -> { // 完成时回调
System.out.println("[线程 :" + Thread.currentThread().getName() + "] 加载完成");
})
.exceptionally(throwable->{
System.out.println("[线程 :" + Thread.currentThread().getName() + "] 加载异常");
return null;
})
.join(); // 等待完成
}
public static void main(String[] args) {
new ChainDataLoader().load();
}
}
通过上面的一堆例子,我们会有这样的疑惑:
1. 如果阻塞导致性能瓶颈和资源浪费的话,Reactive 也能解决这个问题?
2. CompletableFuture 属于异步操作,如果强制等待结束的话,又回到了阻塞编程的方式,那么Reactive 也会面临同样的问题吗?
3. CompletableFuture 让我们理解到异步不一定提升性能,那么 Reactive 也会这样吗?
Reactive Streams JVM 认为异步系统和资源消费需要特殊处理,这是因为流式数据容量难以预判,异步编程复杂,数据源和消费端之间资源消费难以平衡。
讲了这么多,Reactive 是要解决以上所有问题吗?Reactive 到底是什么?Reactive 的使用场景在哪里?Reactive 存在怎样限制/不足?
关于Reactive的定义:
1.Reactive社区说的是:Reactive系统是一种响应的(Responsive)适应性强的(Resilient)弹性的(Elastic)消息驱动的(Message Driven)系统。这个是依据系统来定义的
2.维基百科是这么定义的:reactive编程是一种声明式的编程范式,主要关注数据流,以及流的传播变化(数据变化,比如map之类的)。这种定义侧重描述了reactive的数据模型(数组和事件发射器)以及数据的变化(一系列对流的操作)
3.Spring FrameWork的定义:reactive这个术语是一种编程模式,它可以基于各种事件比如网络事件(ACCEPT,READ)、IO事件做出响应操作,并且是非阻塞的。这种定义说明了reactive是变化响应而且是非阻塞的。
4.Reactor:作为对reactive的一种实现,它认为reactive这种编程模式经常基于面向对象语言并对观察者模式进行了扩展。它侧重于设计模式和数据的获取方式说明了reactive是一种观察者模式的编程,并且呢其数据获取方式是一种推模式而不是迭代器的拉模式。
看到这里,说实话上面四个的定义大家有点晕了,接下来就用一位推特大神andrestaltz王牌级解答来揭开它神秘的面纱:
Reactive programming is programming with asynchronous data streams.
In a way, this isn't anything new. Event buses or your typical click events are really an asynchronous event stream, on which you can observe and do some side effects. Reactive is that idea on steroids. You are able to create data streams of anything, not just from click and hover events. Streams are cheap and ubiquitous, anything can be a stream: variables, user inputs, properties, caches, data structures, etc.
Reactive就是一种响应式编程,而且是使用异步数据流进行编程!我们常用的面向对象编程,这是一种编程模式,命令式编程,也是一种编程模式。同样的,Reactive也是一种编程模式。一方面,这并不是什么新东西。Event buses 或者 Click events 本质上就是异步事件流,你可以监听并处理这些事件。响应式编程的思路大概如下:你可以用包括 Click 和 Hover 事件在内的任何东西创建 Data stream。Stream 廉价且常见,任何东西都可以是一个 Stream:变量、用户输入、属性、Cache、数据结构等等。
关键字:异步(asynchronous )数据流(data streams)并非新鲜事物(not anything new)过于理想化(idea on steroids)
侧重点:并发模型 数据结构 技术本质
reactive编程使用了异步数据流进行编程,它的实现框架有很多,比如:
Java 9 Flow API
RxJava
Reactor
我所学习的webFlux就是基于reactor实现的。有的人可能要问,我经常在网上看到reactive Stream,这个又是啥呢?reactive stream这里我要说两点,一种被认作是reactive Streams JVM规范。还有一种说法是,reactive stream是一种后面我们要讲的具体的数据结构,不过呢前者的说法更多一些。
接下来我们一一讲解下reactive的编程特性:
1.编程模型:可以是响应式编程也可以是函数式编程。那么webflux底层使用了Reactor它又有哪些编程模型呢?
Annotated Controllers: Consistent with Spring MVC and based on the same annotations from the spring-web module.
注解形式的controller,这个是保持了SpringMvc一贯风格
Functional Endpoints: Lambda-based, lightweight, and functional programming model.
函数式编程,基于lambda表达式的轻量级的函数式编程模型
命令式编程作为reactive编程的对立面,采用的是一问一答的方式,也就是说,通过编程命令改变程序状态,这是一种同步阻塞的执行方式,数据需要主动去获取。而响应式编程,是同步或异步非阻塞执行,数据传播被动通知。
2.数据结构
数据结构的核心就是streams,什么是流呢?按照时间排序的事件集合
屏蔽并发编程细节,如线程、同步、线程安全以及并发数据结构。
3.设计模式
Reactive Programming 作为观察者模式(Observer) 的延伸,在处理流式数据的过程中,并非使用传统的命令编程方式( Imperative programming)同步拉取数据,如迭代器模式(Iterator) ,而是采用同步或异步非阻塞地推拉相结合的方式,响应数据传播时的变化。
Spring Framework认为:
reactive和非阻塞不是让程序运行的更快!!!(这是一句大实话)因为它是要解决阻塞浪费资源的问题。另外非阻塞也会增加少量的时间,比如创建callback也会耗费少量的时间。
这里我想给reactive编程做一个总结:
Reactive Programming 作为观察者模式(Observer) 的延伸,不同于传统的命令编程方式( Imperative programming)同步拉取数据的方式,如迭代器模式(Iterator) 。而是采用数据发布者同步或异步地推送到数据流(Data Streams)的方案。当该数据流(Data Steams)订阅者监听到传播变化时,立即作出响应动作。在实现层面上,Reactive Programming 可结合函数式编程简化面向对象语言语法的臃肿性,屏蔽并发实现的复杂细节,提供数据流的有序操作,从而达到提升代码的可读性,以及减少 Bugs 出现的目的。同时,Reactive Programming 结合背压(Backpressure)的技术解决发布端生成数据的速率高于订阅端消费的问题。
reactive编程思想差不多就讲到这里了,接下来我们看看reactive stream规范
Reactive Streams is a standard and specification for Stream-oriented libraries for the JVM that process a potentially unbounded number of elements in sequence,asynchronously passing elements between components,with mandatory non-blocking backpressure.
Reactive stream是处理无限数据元素的面向流的JVM类库规范,它可以使用异步方式在组件之间传输元素,并且还以利用非阻塞的背压来控制数据的传输。
或许定义有些抽象,我们还是分开讲解其中的关键字,首先是组件这个关键词,一共有4个API组件:
1.Publisher 数据发布者
public interface Publisher {
public void subscribe(Subscriber s);
} 只提供了一个方法,而且方法参数中接受的是一个数据的接受者。其中一个比较奇怪的点是,为什么这里的发布者没有发布数据的API呢?
2.Subscriber
数据订阅者,数据上游
public interface Subscriber {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
} 3.Subscription
订阅信号控制
public interface Subscription {
public void request(long n);//request:请求上游元素的数量
public void cancel();//cancel:请求停止发送数据并且清除资源
}
4.Processor
消息发布者和订阅者综合体
public interface Subscription {
public void request(long n);
public void cancel();
}
public interface Processor extends Subscriber, Publisher {
} 下一个关键词背压:
维基百科定义
The term is also used analogously in the field of information technology to describe the buildup of data behind an I/O switch if the buffers are full and incapable of receiving any more data;the transmitting device halts the sending of data packets until the buffers have been emptied and are once more capable of storing information. It also refers to an algorithm for routing data according to congestion gradients (see backpressure routing).
关键字:
I/O 切换(I/O switch ) 发布者往缓冲区写数据,订阅者从缓冲区读数据,当缓冲区无法再接受数据的时候就会出现IO切换
缓冲填满(the buffers are full ) 因为发布者和订阅者不是直接交互而是通过缓冲区或者流来交互的,所以会有缓冲填满
数据无法接受(incapable of receiving any more data) 发布者速率过快导致消费者来不及从缓冲区拿数据了
传输设备(transmitting device ) 发布者
停止发送数据包 (halts the sending of data packets ) 订阅者处理不过来了通知发布者不要再发了(核心!)
Reactor定义:
Propagating signals upstream is also used to implement backpressure, which we described in the assembly line analogy as a feedback signal sent up the line when a workstation processes more slowly than an upstream workstation. The real mechanism defined by the Reactive Streams specification is pretty close to the analogy: a subscriber can work in unbounded mode and let the source push all the data at its fastest achievable rate or it can use the request mechanism to signal the source that it is ready to process at most n elements.
关键字:
Propagating signals upstream(传播上游信号)
无边界模式(unbounded mode)
处理最大元素数量(process at most n elements)
总结背压
假设下游Subscriber工作在无边界大小的数据流水线时,当上游Publisher提供数据的速率快于下游Subscriber的消费数据速率时,下游Subscriber将通过传播信号(request)到上游Publisher,请求限制数据的数量( Demand )或通知上游停止数据生产。
讲了很多的概念了,终于该开始讲讲实战了,为什么要讲这么多概念,而不是直接说API,这是因为我们还是要理解下Reactive的思想,仅仅学API,并不能掌握知识,个人观点而已~
我们先来看看Reactor这个框架中的核心API
Mono
定义:0-1 的非阻塞结果
实现:Reactive Streams JVM API Publisher
类比:非阻塞 Optional

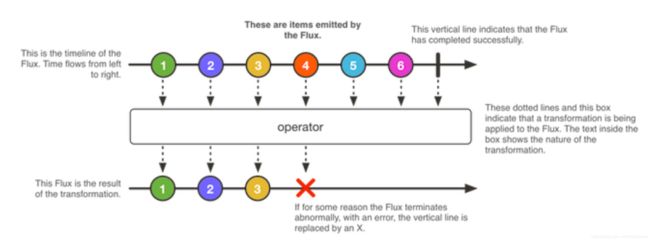
Flux
定义:0-N 的非阻塞序列
实现:Reactive Streams JVM API Publisher
类比:非阻塞 Stream
类似模式
发布者/订阅者模式
Scheduler
定义:Reactor 调度线程池
当前线程: Schedulers.immediate()
等价关系:Thread.currentThread()
单复用线程: Schedulers.single()
内部名称:"single"
线程名称:"single"
线程数量:单个
线程idel时间:Long Live
底层实现:ScheduledThreadPoolExecutor (core 1)
弹性线程池: Schedulers.elastic()
内部名称:"elastic"
线程名称:"elastic-evictor-{num}"
线程数量:无限制(unbounded)
线程idel时间:60 秒
底层实现:ScheduledThreadPoolExecutor
并行线程池: Schedulers.parallel()
内部名称:"parallel"
线程名称:"parallel-{num}"
线程数量:处理器数量
线程idel时间:60 秒
底层实现:ScheduledThreadPoolExecutor
接下来我们使用Reactor来编写一个实例帮助大家理解:
1.maven依赖
io.projectreactor
reactor-core
2.不使用Subscriber时的示例
public class FluxDemo {
public static void main(String[] args) {
println("运行...");
Flux.just("A", "B", "C") // 发布 A -> B -> C
.publishOn(Schedulers.elastic()) // 线程池切换
.map(value -> "+" + value) // "A" -> "+" 转换
.subscribe(
FluxDemo::println, // 数据消费 = onNext(T)
FluxDemo::println, // 异常处理 = onError(Throwable)
() -> { // 完成回调 = onComplete()
println("完成操作!");
},
subscription -> { // 背压操作 onSubscribe(Subscription)
subscription.cancel(); // 取消上游传输数据到下游
subscription.request(Integer.MAX_VALUE); // n 请求的元素数量
}
);
}
private static void println(Object object) {
String threadName = Thread.currentThread().getName();
System.out.println("[线程:" + threadName + "] " + object);
}
}
3.使用Subscriber的示例
public class FluxDemo {
public static void main(String[] args) {
println("运行...");
Flux.just("A", "B", "C") // 发布 A -> B -> C
.map(value -> "+" + value) // "A" -> "+" 转换
.subscribe(new Subscriber() {
private Subscription subscription;
private int count = 0;
@Override
public void onSubscribe(Subscription s) {
subscription = s;
subscription.request(1);
}
@Override
public void onNext(String s) {
if(count==2){
throw new RuntimeException("故意抛异常!");
}
println(s);
count++;
subscription.request(1);
}
@Override
public void onError(Throwable t) {
println(t.getMessage());
}
@Override
public void onComplete() {
println("完成操作!");
}
})
;
}
private static void println(Object object) {
String threadName = Thread.currentThread().getName();
System.out.println("[线程:" + threadName + "] " + object);
}
}