RoBERTa, DeBERTa (v1, v2, v3)
Contents
- RoBERTa: A Robustly Optimized BERT Pretraining Approach
- DeBERTa: Decoding-enhanced bert with disentangled attention
-
- The DeBERTa Architecture
-
- Disentangled Attention: A Two-Vector Approach to Content and Position Embedding
- Enhanced Mask Decoder Accounts for Absolute Word Positions
- Scale Invariant Fine-Tuning (SiFT)
- Experiment
- DeBERTa v2
- DeBERTa v3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing
-
- DeBERTa with Replaced token detection (RTD)
- Gradient-Disentangled Embedding Sharing
-
- Embedding Sharing (ES)
- No Embedding Sharing (NES)
- Gradient-Disentangled Embedding Sharing (GDES)
- Experiment
- References
RoBERTa: A Robustly Optimized BERT Pretraining Approach
- Ref: RoBERTa 模型原理总结
- RoBERTa 是 BERT 更为精细的调优版本。在模型规模、算力和数据上,与 BERT 相比主要有以下几点改进:
- (1) 更大的模型参数量 (论文提供的训练时间来看,模型使用 1024 块 V100 GPU 训练了 1 天的时间)
- (2) 更大 bacth size。RoBERTa 在训练过程中使用了更大的 bacth size。尝试过从 256 到 8000 不等的 bacth size
- (3) 更多的训练数据(包括:CC-NEWS 等在内的 160GB 纯文本。而最初的 BERT 使用 16GB BookCorpus 数据集和英语维基百科进行训练)
- 另外,RoBERTa 在训练方法上有以下改进:
- (1) 去掉下一句预测 (NSP) 任务
- (2) 动态掩码。BERT 依赖随机掩码和预测 token。原版的 BERT 实现在数据预处理期间执行一次掩码,得到一个静态掩码。 而 RoBERTa 使用了动态掩码:每次向模型输入一个序列时都会生成新的掩码模式。这样,在大量数据不断输入的过程中,模型会逐渐适应不同的掩码策略,学习不同的语言表征
- (3) 文本编码。Byte-Pair Encoding (BPE) 是字符级和词级别表征的混合,支持处理自然语言语料库中的众多常见词汇。原版的 BERT 实现使用字符级别的 BPE 词汇,大小为 30K,是在利用启发式分词规则对输入进行预处理之后学得的。Facebook 研究者没有采用这种方式,而是考虑用更大的 byte 级别 BPE 词汇表来训练 BERT,这一词汇表包含 50K 的 subword 单元,且没有对输入作任何额外的预处理或分词
DeBERTa: Decoding-enhanced bert with disentangled attention
- DeBERTa builds on RoBERTa with disentangled attention and enhanced mask decoder training with half of the data used in RoBERTa.
The DeBERTa Architecture
Disentangled Attention: A Two-Vector Approach to Content and Position Embedding
- 在 BERT 中,每个 token 只用一个向量表示,该向量为 word (content) embedding 和 position embedding 之和,而 DeBERTa 则对 token embed 进行解耦,用 content 和 relative position 两个向量来表示一个 token. 对于 token i i i,DeBERTa 将其表示为 { H i } \{H_i\} {Hi} (content) 和 { P i ∣ j } \{P_{i|j}\} {Pi∣j} (relative position)
- token i i i 和 token j j j 之间的 attention score 可以被分解为 4 个部分 (content-to-content, content-to-position, position-to-content, and position-to-position):
 由于使用的是相对位置编码,因此作者认为第 4 项不重要可以省略。具体实现方法如下。设 k = 512 k=512 k=512 为可能的最大相对距离, δ ( i , j ) ∈ [ 0 , 2 k ) \delta(i,j)\in[0,2k) δ(i,j)∈[0,2k) 为 token i , j i,j i,j 的相对距离:
由于使用的是相对位置编码,因此作者认为第 4 项不重要可以省略。具体实现方法如下。设 k = 512 k=512 k=512 为可能的最大相对距离, δ ( i , j ) ∈ [ 0 , 2 k ) \delta(i,j)\in[0,2k) δ(i,j)∈[0,2k) 为 token i , j i,j i,j 的相对距离:
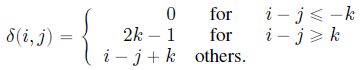 上述相对距离可以用 embed 矩阵 P ∈ R 2 k × d P\in\R^{2k\times d} P∈R2k×d 表示 (shared across all layers)。disentangled self-attention with relative position bias 可以表示为
上述相对距离可以用 embed 矩阵 P ∈ R 2 k × d P\in\R^{2k\times d} P∈R2k×d 表示 (shared across all layers)。disentangled self-attention with relative position bias 可以表示为
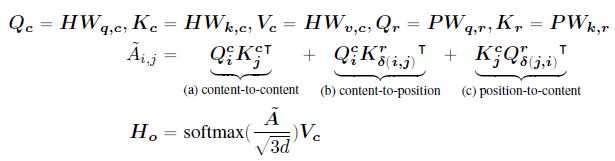 其中, H ∈ R N × d H\in\R^{N\times d} H∈RN×d, P ∈ R 2 k × d P\in\R^{2k\times d} P∈R2k×d 分别为 content vectors 和 relative pos vectors, N N N 为 token 数。 W q , c , W k , c , W v , c ∈ R d × d W_{q,c},W_{k,c},W_{v,c}\in\R^{d\times d} Wq,c,Wk,c,Wv,c∈Rd×d 为 projected content vectors Q c , K c , V c ∈ R N × d Q_c,K_c,V_c\in\R^{N\times d} Qc,Kc,Vc∈RN×d 对应的投影矩阵, W q , r , W k , r ∈ R d × d W_{q,r},W_{k,r}\in\R^{d\times d} Wq,r,Wk,r∈Rd×d 为 projected relative position vectors Q r , K r ∈ R N × d Q_r,K_r\in\R^{N\times d} Qr,Kr∈RN×d 对应的投影矩阵
其中, H ∈ R N × d H\in\R^{N\times d} H∈RN×d, P ∈ R 2 k × d P\in\R^{2k\times d} P∈R2k×d 分别为 content vectors 和 relative pos vectors, N N N 为 token 数。 W q , c , W k , c , W v , c ∈ R d × d W_{q,c},W_{k,c},W_{v,c}\in\R^{d\times d} Wq,c,Wk,c,Wv,c∈Rd×d 为 projected content vectors Q c , K c , V c ∈ R N × d Q_c,K_c,V_c\in\R^{N\times d} Qc,Kc,Vc∈RN×d 对应的投影矩阵, W q , r , W k , r ∈ R d × d W_{q,r},W_{k,r}\in\R^{d\times d} Wq,r,Wk,r∈Rd×d 为 projected relative position vectors Q r , K r ∈ R N × d Q_r,K_r\in\R^{N\times d} Qr,Kr∈RN×d 对应的投影矩阵

Handling long sequence input
- 由于采用了相对距离嵌入向量,DeBERTa 可以处理任意长度的输入向量,当 maximum relative distance 设为 k k k 时,在同一层内的 token 可以直接与最多 2 k − 1 2k-1 2k−1 个 token 进行交互,通过堆叠 Transformer 层,第 l l l 层的 token 可以直接或间接地与最多 ( 2 k − 1 ) l (2k-1)l (2k−1)l 个 token 进行交互

Enhanced Mask Decoder Accounts for Absolute Word Positions
- 对于预测任务而言,除了 content 和 relative position 以外,absolute position 信息也很重要,例如对于句子 “a new store opened beside the new mall”,store 和 mall 含义差不多,但它们所处位置不同,因此语法意义也不同,这里 store 是句子主语
- 为了弥补 absolute position 信息,DeBERTa 在做 masked token prediction 时直接将 absolute word position embeddings 加到了 softmax 前 (softmax 用于在 MLM 中输出 masked token 为各个单词的概率)
Scale Invariant Fine-Tuning (SiFT)
- DeBERTa 在微调时使用了一种新的对抗训练算法 Scale-invariant-Fine-Tuning (SiFT)
- 在 NLP 任务中,对抗训练通常是加在 word embedding 上,然而,不同 token 对应的 word embedding 的 norm 各不相同,并且模型参数越大 norm 的方差也就越大,这会使得训练过程不稳定。为此,SiFT 先将 word embeddings 归一化为概率向量,然后在归一化的 word embeddings 上添加扰动
Experiment
Ablation study
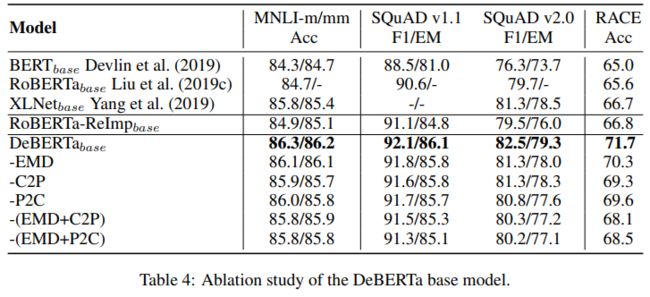
base model
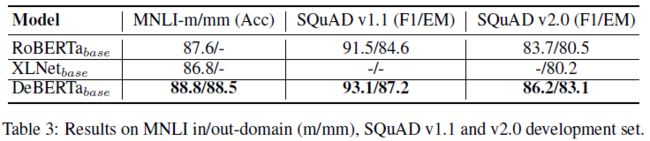
Large model

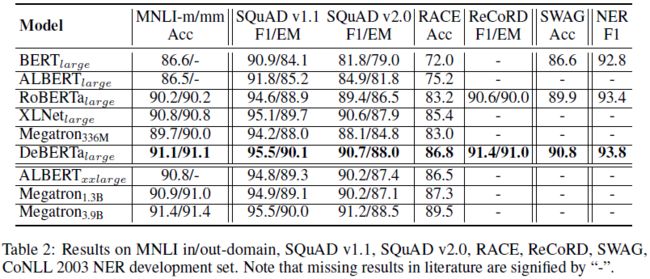
Scale up to 1.5 billion parameters

DeBERTa v2
- (1) Vocabulary In v2 the tokenizer is changed to use a new vocabulary of size 128K built from the training data. Instead of a GPT2-based tokenizer, the tokenizer is now sentencepiece-based tokenizer.
- (2) nGiE(nGram Induced Input Encoding) The DeBERTa-v2 model uses an additional convolution layer aside with the first transformer layer to better learn the local dependency of input tokens.
- (3) Sharing position projection matrix with content projection matrix in attention layer Based on previous experiments, this can save parameters without affecting the performance.
- (4) Apply bucket to encode relative positions The DeBERTa-v2 model uses log bucket to encode relative positions similar to T5.
- (5) 900M model & 1.5B model Two additional model sizes are available: 900M and 1.5B, which significantly improves the performance of downstream tasks.
DeBERTa v3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing
DeBERTa with Replaced token detection (RTD)
- DeBERTaV3 用 RTD 替代了 MLM. RTD 是 ELECTRA 提出的一种预训练任务。RTD 任务包含 generator 和 discriminator 两个 transformer encoders
- generator θ G \theta_G θG 使用 MLM 进行训练,用于生成替换 masked tokens 的 ambiguous tokens,损失函数如下:
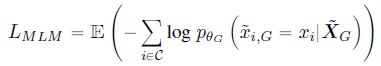 其中, C \mathcal C C 为输入序列在 masked tokens 的序号集合, X ~ G \tilde X_G X~G 为含有 15% masked tokens 的 generator 输入
其中, C \mathcal C C 为输入序列在 masked tokens 的序号集合, X ~ G \tilde X_G X~G 为含有 15% masked tokens 的 generator 输入 - discriminator θ D \theta_D θD 使用 RTD (Replaced Token Detection) 进行训练,用于检测输入序列中由 generator 生成的伪造 tokens。它的输入序列 X ~ D \tilde X_D X~D 由 generator 的输出序列构造得到:
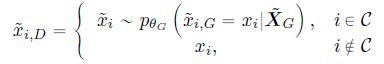 对于 generator 生成的序列,如果 token i i i 不属于 masked token,则保留 token i i i,如果 token i i i 属于 masked token,则根据 generator 生成的概率分布采样出一个伪造的 token,最终可以得到 discriminator 的生成序列。discriminator 的损失函数为:
对于 generator 生成的序列,如果 token i i i 不属于 masked token,则保留 token i i i,如果 token i i i 属于 masked token,则根据 generator 生成的概率分布采样出一个伪造的 token,最终可以得到 discriminator 的生成序列。discriminator 的损失函数为:
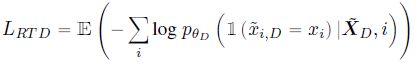 也就是将 generator 伪造的错误 tokens 看作负样本,真实 tokens 看作正样本进行二分类
也就是将 generator 伪造的错误 tokens 看作负样本,真实 tokens 看作正样本进行二分类 - 总的损失函数为
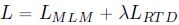
Gradient-Disentangled Embedding Sharing
Embedding Sharing (ES)
- 在 RTD 预训练时,ELECTRA 的 generator 和 discriminator 是共享 token embeddings E E E 的,因此 E E E 的梯度为
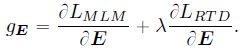 这相当于是在进行 multitask learning,但 MLM 倾向于使得语义相近的 tokens 对应的 embed 也比较接近,而 RTD 则倾向于使得语义相近的 tokens 对应的 embed 相互远离 (方便进行区分),这会使得训练的收敛速度很慢
这相当于是在进行 multitask learning,但 MLM 倾向于使得语义相近的 tokens 对应的 embed 也比较接近,而 RTD 则倾向于使得语义相近的 tokens 对应的 embed 相互远离 (方便进行区分),这会使得训练的收敛速度很慢

No Embedding Sharing (NES)
- 为了验证上述猜想,作者实现了不共享 token embeddings 的模型版本。在训练的一个迭代中,先用前向+后向传播 ( L M L M L_{MLM} LMLM) 训练 generator,再用前向+后向传播 ( λ L R T D \lambda L_{RTD} λLRTD) 训练 discriminator
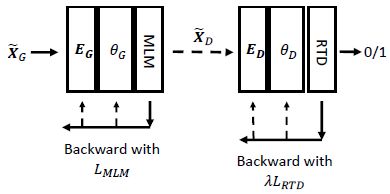
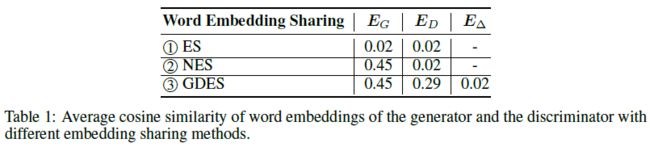
- 在对 generator 和 discriminator 的 token embed 解耦后可以看到, E G E_G EG 的 token embed 之间比较接近,而 E D E_D ED 的 token embed 之间彼此远离,这证明了之前的猜想
 实验也进一步证明,不共享 token embeddings 可以有效提高模型收敛速度
实验也进一步证明,不共享 token embeddings 可以有效提高模型收敛速度
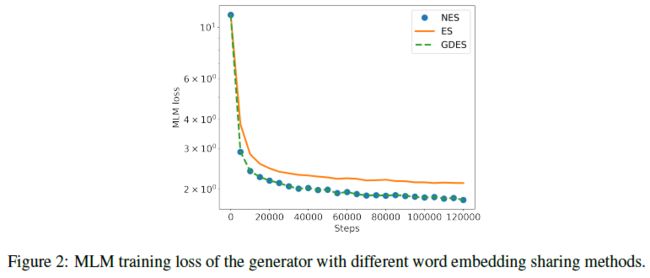
- 然而,不共享 token embeddings 却损害了模型性能,这证明了 ELECTRA 论文中所说的 ES 的好处,除了 parameter-efficiency 以外,generator embed 能使得 discriminator 更好
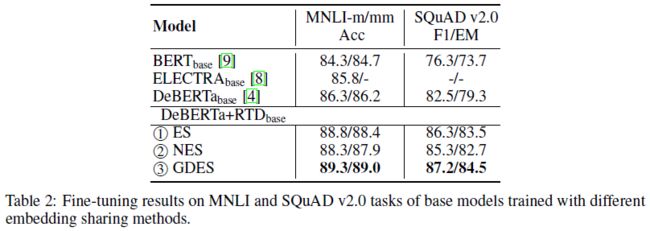
Gradient-Disentangled Embedding Sharing (GDES)
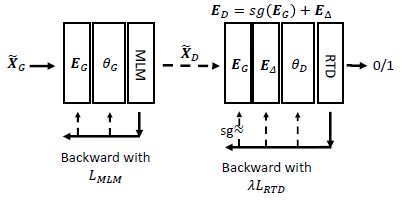
- 为了结合 ES 和 NES 各自的优点,作者提出了 GDES. GDES 和 ES 一样,共享了 token embeddings,但只使用 L M L M L_{MLM} LMLM 而不使用 λ L R T D \lambda L_{RTD} λLRTD 去更新 E G E_G EG,从而使得训练更加高效的同时还能利用 E G E_G EG 去提升 discriminator 的性能。此外,作者还引入了一个初始化为 zero matrix 的 E Δ E_\Delta EΔ 去适配 E G E_G EG:
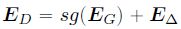
- 在训练的一个迭代中,GDES 先用前向+后向传播 ( L M L M L_{MLM} LMLM) 训练 generator ,并更新共享的 token embed E G E_G EG,再用前向+后向传播 ( λ L R T D \lambda L_{RTD} λLRTD) 训练 discriminator (只更新 E Δ E_\Delta EΔ,不更新 E G E_G EG). 模型训练完后,discriminator 最终的 token embed 即为 E G + E Δ E_G+E_\Delta EG+EΔ
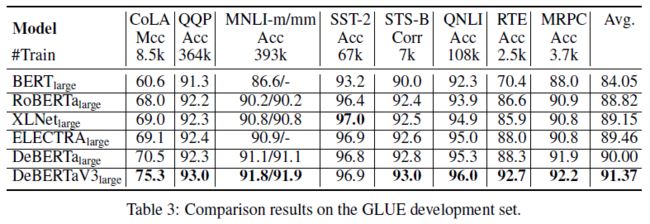
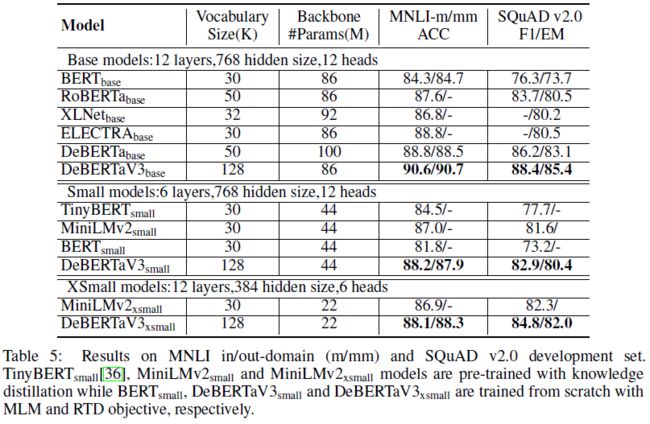
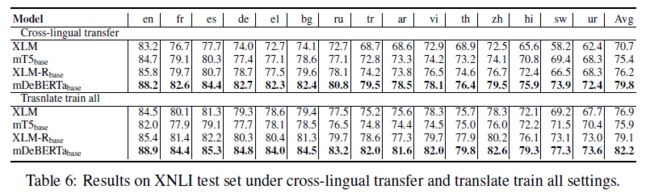
Experiment

References
- Liu, Yinhan, et al. “Roberta: A robustly optimized bert pretraining approach.” arXiv preprint arXiv:1907.11692 (2019).
- He, Pengcheng, et al. “Deberta: Decoding-enhanced bert with disentangled attention.” (ICLR 2021).
- DeBERTa v2
- He, Pengcheng, Jianfeng Gao, and Weizhu Chen. “Debertav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing.” arXiv preprint arXiv:2111.09543 (2021).
- code: https://github.com/pytorch/fairseq (RoBERTa), https://github.com/microsoft/DeBERTa
- HuggingFace Transformers: https://github.com/huggingface/transformers (code), https://huggingface.co/models?filter=deberta, https://huggingface.co/models?other= deberta-v3 (model)