Kubernetes技术与架构-12
1 前言
2 Kubernetes定义
3 Kubernetes架构
4 Kubernetes技术
4.1 容器化技术
4.1.1 cgroups技术
4.1.2 Docker容器运行环境
4.1.3 containerd容器运行环境
4.1.4 Pod的基本概念
4.1.5 Pod的调度策略
4.1.6 Pod的资源编排
4.1.6.1Deployments
4.1.6.2ReplicaSet
4.1.6.3StatefulSets
4.1.6.4DaemonSet
4.1.6.5Jobs
Job是用于编排任务,一个Job创建一个或者多个Pod执行任务,直到这些任务被终止或者执行完成,也就是,Job时刻追踪这些Pod对应任务的执行轨迹,指定数量Pod完成任务,则Job也完成任务。Job被删除,则Job对应的Pod任务将全部被删除,Job被暂停,则Job对应的活跃的Pod任务将全部被删除,直到Job恢复执行。
例如,用户编排一个对应只运行一个Pod任务的Job,则Job需要保证该Pod可靠地完成任务的执行,如果Pod任务在执行过程中出现异常或者被删除(硬件发生错误或者节点重启),则Job将会新建一个Pod继续完成任务的执行。另外,用户可以编排Job并行地执行多个Pod任务,也可以使用CronJob(后续章节中详细描述)定时地、定期地、定时间间隔地执行单个任务或者并行地执行多个任务。
Job示例
如下所示,编排一个Job,运行该Job对应的Pod任务计算π并输出2000位:

运行该任务之后,使用如下命令行查看任务状态信息:
kubectl describe job pi
(或者kubectl get job pi -o yaml)
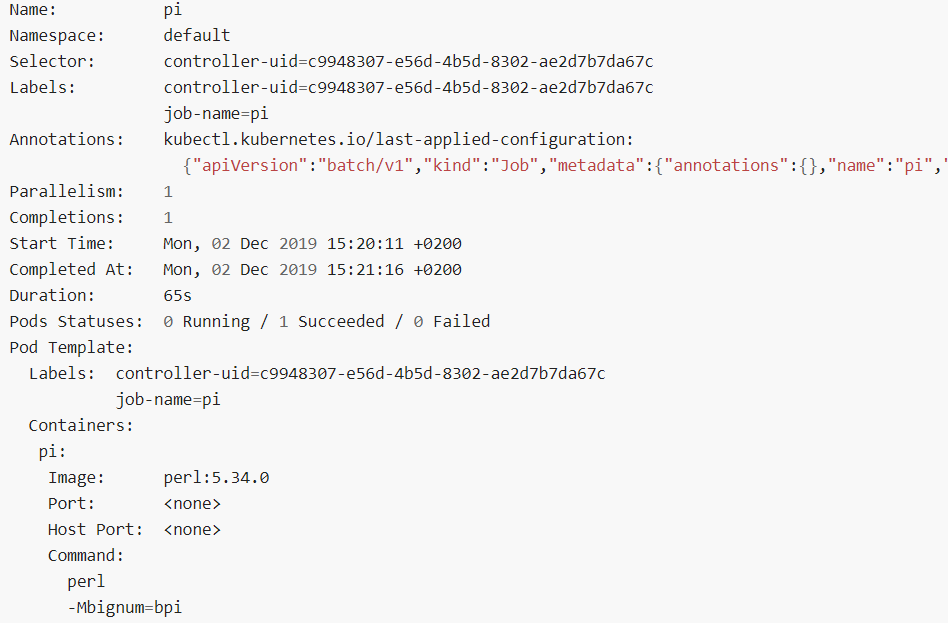
任务运行信息的简要描述如下所示:
| Start Time |
| 任务执行的开始时间 |
| Completed At 任务执行的完成时间 |
| Duration 任务执行的持续时间 |
| Pods Statuses: 0 Running / 1 Succeeded / 0 Failed 对应Pod的运行状态,其中,0 运行中/1 运行成功/0 运行失败 |
| Pod Template 对应Pod的模板 |
| Events 与任务控制器相关的事件信息 |
用户可以使用如下所示的命令行查看Job对应的所有Pod任务列表:
pods=
$(kubectl get pods
--selector=job-name=pi
--output=jsonpath=
'{.items[*].metadata.name}')
echo $pods
其中,--output是设置输出信息的过滤或者匹配规则(类似正则表达式)。
用户可以使用如下所示的命令行查看执行任务的输出信息:
kubectl logs $pods
Job的基本信息
与其他编排规范相同,需要定义apiVersion、kind,、metadata这些基本的属性域,需要定义.spec.template模板相关的属性域,需要定义.spec.selector选择器相关的属性域。
Job的任务类型
Job提供三种任务类型,如下所示:
| 1非并行任务
2并行任务(固定任务完成数)
3 并行任务(与工作队列协作) 该任务类型适用于生产者与消费者模式的使用场景,工作队列是生产者,Pod任务是消费者,消费完成可以退出或者由用户制定消费规则
|
对于以上的任务类型,其设置建议如下所示:
| 对于非并行任务 用户不用设置配置域.spec.completions配置域.spec.parallelism 在不设置的情况下,默认值是1 |
| 对于固定任务数的并行任务 只设置配置域.spec.completions指定需要完成的任务数 也可以设置配置域.spec.parallelism,或者不设置,默认值是1 |
| 对于工作队列的并行任务 只设置配置域.spec.parallelism,不用设置配置域.spec.completions |
控制并行度
并行度是由配置域.spec.parallelism指定,默认值是1,如果指定为0,则对应的Job被暂停执行,直到该值被修改为大于0的值。在实际的运行环境中,实际运行的Pod任务数是大于或者小于并行度指定的值(不一致),其原因如下所示:
|
任务完成的模式
对于固定任务数的任务类型,在配置域.spec.completions值不为空的时候,用户可以使用配置域.spec.completionMode指定Pod任务执行的模式,其设置方式如下所示:
| NonIndexed(默认值) 固定任务数的Pod任务执行完成,则Job执行完成。也就是,所有Pod任务是相应的,当固定任务数是0,则使用此默认值 |
| Indexed Job中的每个Pod任务对应一个任务完成的索引标识,从0到.spec.completions-1,该索引值与以下三个方面有关系:
每个索引值标识与Pod任务是一对多的关系,因而,只要Job中每个索引值标识对应的其中一个Pod任务成功完成,则Job成功完成,也就是,每个索引值标识可以对应多个Pod任务,但是只有一个成功完成的Pod任务参与任务完成总数的统计。 |
处理Pod与容器异常
在实际的运行环境中,Pod中运行的容器实例发生异常的原因有很多,其中包括错误码退出、内存资源不足而引起进程的非法退出,在异常出现的情况下,如果用户设置重启策略是
.spec.template.spec.restartPolicy = "OnFailure",
则控制器会在相同的节点中重启容器。用户也可以设置重启策略是.spec.template.spec.restartPolicy = "Never",
则控制器不会重启容器,而是新建一个Pod任务。
在实际的运行环境中,Pod实例发生异常的原因也有很多,其中包括节点更新、重启、删除而引起运行在其中的Pod自动退出,如果用户设置配置域.spec.template.spec.restartPolicy = "Never",
Pod中运行的容器发生异常,则Pod也被认为是发生异常。在Pod重启过程中,往往涉及到业务应用的可用性问题,需要用户根据实际业务需求处理业务应用重启的问题,例如数据重新加载问题或者分布式锁问题。
如果用户设置了以下所示三个配置域的值,则业务应用也存在启动两次的可能性:
.spec.parallelism = 1
.spec.completions = 1
.spec.template.spec.restartPolicy = "Never"
如果用户设置了以下所示的配置域的值,Job控制器会同时启动多个Pod任务,则需要用户根据实际业务需求处理业务应用因并发性而引起资源争夺的问题:
.spec.parallelism > 1
.spec.completions > 1
Pod错误补偿策略
Pod错误补偿策略是用于Job控制器在Pod任务发生异常的时候,继续尝试重启Pod任务N次之后,Pod任务还不能恢复正常的运行,则Job控制器认为Job启动失败,对应N的次数是由配置域.spec.backoffLimit的值确定,其默认值是6,每次重试的时间间隔是以10秒为单位的指数级增长,例如,10秒、20秒…,其总时间延迟的上限是6分钟,用于统计重试次数的Pod状态或者Pod中容器状态的规则如下所示:
|
Job终止与清理
当一个Job完成,则不再创建新的Pod任务,已终止运行的旧Pod任务也不会被删除,用户可以查看旧Pod任务的日志信息用于检查业务应用的错误、告警或者其他的诊断信息,Job对应的元数据信息也不会被删除,用户可以查看Job对象的状态,Job完成之后由用户自行删除,用户可以使用以下的命令行自行删除Job:
kubectl delete jobs/pi或者
kubectl delete -f ./job.yaml
当用户使用该命令行删除Job,则Job对应的旧Pod也将被删除。
默认的情况下,Job是由集群统一调度,在不受外部干涉的情况下,自动地执行该Job的任务,如果Pod发生异常或者运行在Pod中的容器发生异常,则对Pod或者对运行在Pod中的容器执行恢复重试策略,如果重试恢复的执行次数达到限制的次数之后,Job还没有恢复正常执行,则最终Job被认为是失败的,然后,Job中所有的Pod任务将被终止执行。
用户也可以设置Job的执行截止时间终止Job的执行,对应配置域
.spec.activeDeadlineSeconds,不管Job的状态、Job中Pod的状态、运行在Pod中的容器状态如何,只要Job执行的总时间达到该截止时间,则Job立刻被终止执行,则其对应的全部Pod任务也将被终止执行,此时Job的状态是type: Faile,原因是reason: DeadlineExceeded。该优先级比Pod错误重试次数的优先级更高,也就是,即使错误重试次数未达到限制的次数,但是只要截止时间到期,则Job立刻被终止执行。
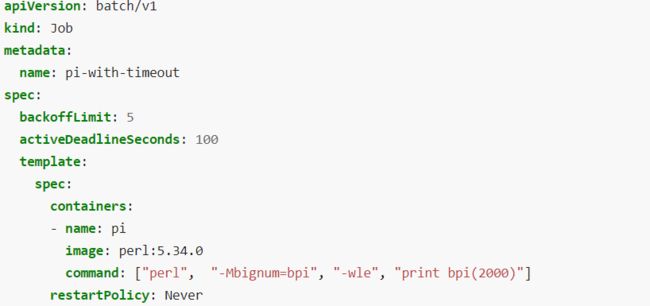
由以上的分析可知,配置域restartPolicy重启策略是用于Pod的,而不是用于Job,一旦Job被终止,则Job永远不会被恢复。Job的终止机制包括配置域.spec.activeDeadlineSeconds与配置域.spec.backoffLimit,Job终止之后,需要人工干涉。
(未完待续)