Node.js基础常用知识点全总结
-
- 一.认识Node.js
-
- 1. Node.js的特性
- 2. 浏览器和Node.js环境对比
- 3.开发环境安装和搭建
- 二.commonJS、包以及npm
-
- 1. CommonJS规范
- 2. npm包管理工具的用法详解
- 三.Node.js的常用内置模块
-
- 1. http模块
- 2. http模块简单案例实践
- 3. url模块
- 4. querystring模块
- 5. http模块补充知识点
- 6. event事件模块
- 7. fs文件操作模块
- 8. stream流模块
- 9. zlib模块
- 10. crypto模块
- 11. 路由小练习
- 12. path路径模块
- 13. os操作系统模块
- 14. Buffer二进制缓冲区
从这一节开始,我就要系统地总结Node.js的知识点了,我打算把它写成一个系列专栏。这一篇是系列的开始,我会由浅入深、循序渐进地总结归纳Node.js的知识点。本篇博客会总结Node.js的一些模块和API,本篇这些内容都是Node.js的常用基础知识点,是后面深入学习Node.js的基石,个人认为非常重要,一定要掌握。因为Node.js其实整个知识体量还挺大,这篇博客截稿时都已经3万多字了,Node.js每个内置模块都有大量的方法,但我这并不是api文档,我并不能全都归纳进来,只能归纳常用的方法,目的是认识常用模块,对常用模块的用法有印象。
一.认识Node.js
Node.js是一个javascript运行环境。它让javascript可以开发后端程序,实现几乎其他后端语言实现的所有功能,可以与PHP、Java、Python、.NET、Ruby等后端语言平起平坐。
Node.js是基于V8引擎,V8引擎是Google发布的开源JavaScript引擎,V8引擎被应用在Chrome、Nodejs和其他应用中。
1. Node.js的特性
(1) Nodejs语法完全是js语法,只要你懂js基础就可以学会Nodejs后端开发。
(2) Node.js超强的高并发能力,能够实现高性能服务器。
(3) 开发周期短、开发成本低、学习成本也低
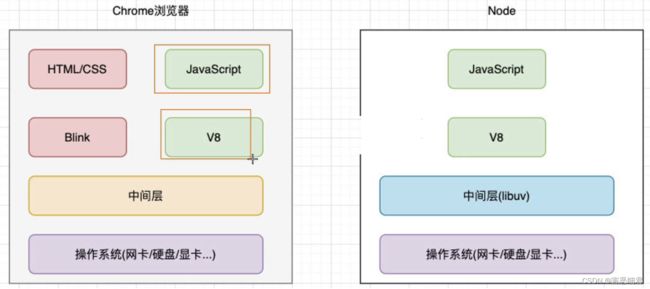
2. 浏览器和Node.js环境对比
下图中,在左边Chrome浏览器环境中,V8引擎用于解析JS代码,而Blink引擎是浏览器的排版引擎,用于处理网页的html、css和DOM操作。
而右边的Node环境中,只有V8引擎,用于处理JS代码,所以Node.js中,访问DOM和BOM是无法实现的。但Node.js因为有libuv中间层加持,能够实现浏览器所不能实现的一些功能。
Node.js 可以解析JS代码(没有浏览器安全级别的限制)提供很多系统级别的API,例如(现在看不懂没关系):
文件的读写 (File System)
const fs = require('fs')
fs.readFile('./test.txt', 'utf-8', (err, content) => {
console.log(content)
})
进程的管理 (Process)
function main(argv) {
console.log(argv)
}
main(process.argv.slice(2))
网络通信 (HTTP/HTTPS)
const http = require("http")
http.createServer((req,res) => {
res.writeHead(200, {
"content-type": "text/plain"
})
res.write("hello nodejs")
res.end()
}).listen(3000)
3.开发环境安装和搭建
大家点击http://nodejs.cn/download/ 这个网址下载长期支持版的Node.js。
这个是国内的网站,大家不用担心进不去。同时也建议大家收藏Node.js中文网这个网站,还有Node.js的API文档
安装也没啥好说的,你只要下一步下一步就可以了。安装好后,在任意地方打开命令行窗口,运行node -v ,如果能打印出Node.js的版本号的话,则说明安装成功了。
二.commonJS、包以及npm
1. CommonJS规范
在node.js环境中,默认支持模块系统,该模块系统遵循CommonJs规范。
一个 JavaScript 文件就是一个模块,在模块文件中定义的变量和函数默认只能在模块文件内部使用,如果需要在其他文件中使用,必须显式声明将其进行导出。
CommonJS模块规范主要分为模块导出(也叫模块定义)、模块引用两个部分。
模块导出(module.exports或exports)
CommonJS中定义模块的规定:
我们把公共功能抽离成一个单独的js文件作为一个模块。默认情况下,里面的方法和属性是外面无法访问的。如果想要让外面能够访问到里面的属性和方法,就必须要通过 module.exports 或exports暴露属性和方法。
在每一个模块文件中,都会存在一个 module 对象,即模块对象。在模块对象中保存了和当前模块相关信息。
不信我们在test.js中编写如下代码:
console.log(module);
在当前目录下面的命令行中运行node .\test.js ,会打印如下的结果:
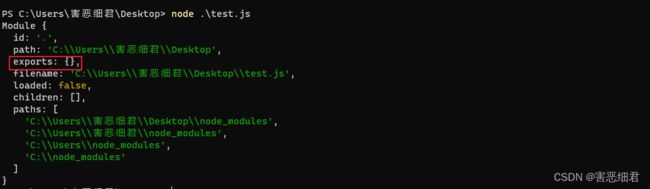
在模块对象中有一个属性 exports,它的值是一个对象,模块内部需要被导出的成员都应该存储在到这个对象中。
可以用module.exports给test.js模块系统添加属性:
const url = "https://blog.csdn.net/";
function log(message){
console.log(message);
}
module.exports.endPoint = url; //给module下的exports添加url属性
module.exports.log = log; //给module下的exports添加log属性
console.log(module);
或者用exports给test.js模块系统添加属性:
const url = "https://blog.csdn.net/";
function log(message){
console.log(message);
}
exports.endPoint = url; //给module下的exports添加url属性
exports.log = log; //给module下的exports添加log属性
console.log(module);
或者用module.exports = { }把属性组合成一个对象后导出:
const url = "https://blog.csdn.net/";
function log(message){
console.log(message);
}
module.exports = {
url : url,
log : log
}
console.log(module);

模块导入(require)
在其他文件中通过 require 方法引入模块,require 方法的返回值就是对应模块的 module.exports 对象。在导入模块时,模块文件后缀 .js 可以省略,文件路径不可省略。
(1) require 方法属于同步导入模块,模块导入后可以立即使用。
(2) 导入其他模块时,建议使用 const 关键字声明,防止模块被重置。
我们创建一个require.js文件,里面导入上面的test.js:
const test = require('./test')
console.log(module);
会发现打印的第二个module的children属性会多一些信息:

2. npm包管理工具的用法详解
npm介绍:npm是世界上最大的开放源代码的生态系统,我们可以通过npm下载各种包。npm是随同Node.js一起安装的包管理工具,能解决Node.js代码部署上的很多问题。
常见的使用场景有以下几种
(1) 允许用户从NPM服务器下载别人编写的第三方包到本地使用。
(2) 允许用户从NPM服务器下载并安装别人编写的命令行程序到本地使用。
(3) 允许用户将自己编写的包或命令行程序上传到NPM服务器供别人使用。
npm常用命令
初始化项目:
npm init --yes
使用 npm 命令安装模块:
npm install 包名@版本号
全局安装与本地安装:
npm install 包名 # 本地安装
npm install 包名 -g # 全局安装
查看所有全局安装的模块:
npm list -g
卸载模块:
npm uninstall 包名
更新模块:
npm update 包名
package.json 和 package-lock.json 区别
(1) package.json 是在运行 “ npm init ”时生成的,主要记录项目依赖,主要有以下结构:
name:项目名,也就是在使用npm init 初始化时取的名字.
main:入口文件,一般都是 index.js
description:描述信息,有助于搜索。
version:版本号。
keywords:关键字,有助于在人们使用 npm search搜索时发现你的项目。
scripts:支持的脚本,默认是一个空的 test。
license :默认是 MIT。
dependencies:指定了项目运行时(生产环境)所依赖的模块。
devDependencies:指定项目开发时所需要的模块,也就是在项目开发时才用得上,一旦项目打包上线了,就将移除这里的第三方模块。
(2) package-lock.json 是在运行 “npm install” 时生成的一个文件,用于记录当前状态下项目中实际安装的各个 package 的版本号、模块下载地址、及这个模块又依赖了哪些依赖。
为什么有了package.json,还需要 package-lock.json 文件呢?
当项目中已有 package-lock.json 文件,在安装项目依赖时,将以该文件为主进行解析安装指定版本依赖包,而不是使用 package.json 来解析和安装模块。
因为 package 只是指定的版本不够具体,而package-lock 为每个模块及其每个依赖项指定了安装的版本,位置和完整性哈希,所以它每次创建的安装都是相同的。
无论你使用什么设备,或者将来安装它都无关紧要,每次都应该给你相同的结果。
npm install安装模块时的一些选项
使用npm install安装依赖时,可以使用--save和--save-dev。
使用--save安装的依赖,安装的包会被写到package的dependencies属性里面去。dependencies 是运行时依赖(生产环境),可以简化为参数 -S。
而使用--save-dev 则添加到 package.json 文件 devDependencies 键下,devDependencies 是开发时的依赖。即 devDependencies 下列出的模块,是开发时用的 ,生产环境会移除,可以简化为参数 -D。
版本号的命名规则
在 Node.js 中所有的版本号都有3个数字:x.y.z。
第一个数字是主版本。第二个数字是次版本。第三个数字是补丁版本。
^:只会执行不更改最左边非零数字的更新。 如果写入的是 ^0.13.0,则当运行 npm update 时,可以更新到 0.13.1、0.13.2 等,但不能更新到 0.14.0 或更高版本。 如果写入的是 ^1.13.0,则当运行 npm update 时,可以更新到 1.13.1、1.14.0 等,但不能更新到 2.0.0 或更高版本。
~:如果写入的是 〜0.13.0,则当运行 npm update 时,会更新到补丁版本:即 0.13.1 可以,但 0.14.0 不可以。
>:接受高于指定版本的任何版本。
>=:接受等于或高于指定版本的任何版本。
<=:接受等于或低于指定版本的任何版本。
<:接受低于指定版本的任何版本。
=:接受确切的版本。
-:接受一定范围的版本。例如:2.1.0 - 2.6.2。
||:组合集合。例如 < 2.1 || > 2.6。
三.Node.js的常用内置模块
下面开始总结Node.js的内置模块了,如果你是入门学习的话,推荐按照本文顺序来学,学习思路会更清晰。如果你只是要查阅相关模块的用法,可以从目录索引导航到那一个模块。
1. http模块
http模块是 Node.js 网络的关键模块。可以使用以下代码引入:
const http = require('http')
该模块提供了一些属性、方法、以及类。我们要学习的就是一些常用的属性、方法、以及类的使用。
常用方法:
(1) http.createServer() :用于返回 http.Server 类的新实例。
用法:
const server = http.createServer((req, res) => {
//使用此回调处理每个单独的请求。
})
(2) http.request() :用于发送 HTTP 请求到服务器,并创建 http.ClientRequest 类的实例。
(3) http.get() :类似于 http.request(),但会自动地设置 HTTP 方法为 GET,并自动地调用 req.end()。
常用属性:
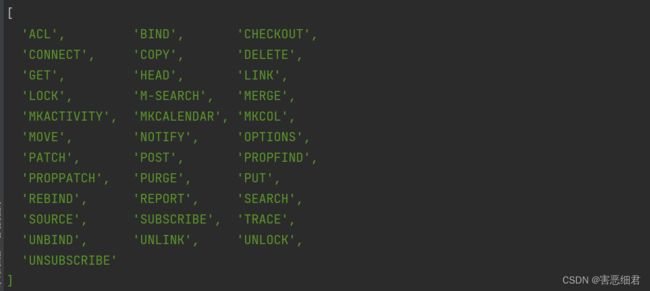
(1) http.METHODS :此属性列出了所有支持的 HTTP 方法。像什么GET、POST、DELETE等等。
const http=require('http');
console.log(http.METHODS)
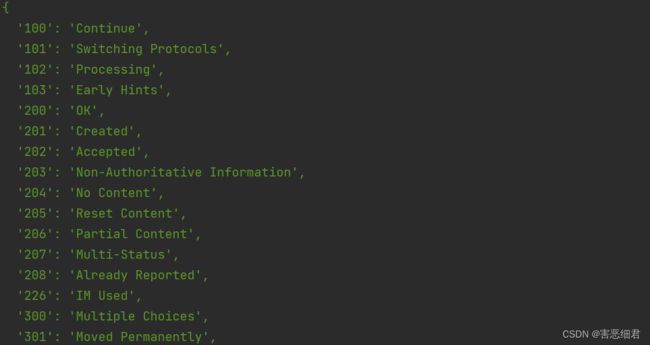
(2) http.STATUS_CODES :此属性列出了所有的 HTTP请求的状态代码及其描述。
const http=require('http');
console.log(http.STATUS_CODES)
常用类:
HTTP 模块提供了5 个很常用的类,分别如下:
(1) http.Agent :Node.js 会创建 http.Agent 类的全局实例,以管理 HTTP 客户端连接的持久性和复用,这是 Node.js HTTP 网络的关键组成部分。该对象会确保对服务器的每个请求进行排队并且单个 socket 被复用,它还维护一个 socket 池。
(2) http.ClientRequest :当 http.request() 或 http.get() 被调用时,会创建 http.ClientRequest 对象。当响应被接收时,则会使用响应(http.IncomingMessage 实例作为参数)来调用 response 事件。返回的响应数据可以通过以下两种方式读取:
- 可以调用 response.read() 方法。
- 在 response 事件处理函数中,可以为 data 事件设置事件监听器,以便可以监听流入的数据。
(3) http.Server : 当使用 http.createServer() 创建新的服务器时,通常会实例化并返回此类。拥有服务器对象后,就可以访问其方法:
close()停止服务器不再接受新的连接。listen()启动 HTTP 服务器并监听连接。
(4) http.ServerResponse :由 http.Server 创建,并作为第二个参数传给它触发的 request 事件。通常在代码中用作 res:
const server = http.createServer((req, res) => {
//res 是一个 http.ServerResponse 对象。
})
这个类的以下这些方法用于与 HTTP 消息头进行交互:
| 方法名 | 作用 |
|---|---|
| getHeaderNames() | 获取已设置的 HTTP 消息头名称的列表。 |
| getHeaders() | 获取已设置的 HTTP 消息头的副本。 |
| setHeader(‘headername’, value) | 设置 HTTP 消息头的值。 |
| getHeader(‘headername’) | 获取已设置的 HTTP 消息头。 |
| removeHeader(‘headername’) | 删除已设置的 HTTP 消息头。 |
| hasHeader(‘headername’) | 如果响应已设置该消息头,则返回 true。 |
| headersSent() | 如果消息头已被发送给客户端,则返回 true。 |
在处理消息头之后,可以通过调用 response.writeHead()(该方法接受 statusCode 作为第一个参数,可选的状态消息和消息头对象)将它们发送给客户端。
若要在响应正文中发送数据给客户端,则使用 write()。 它会发送缓冲的数据到 HTTP 响应流。
如果消息头还未被发送,则使用 response.writeHead() 会先发送消息头,其中包含在请求中已被设置的状态码和消息,可以通过设置 statusCode 和 statusMessage 属性的值进行编辑:
response.statusCode = 500
response.statusMessage = '内部服务器错误'
(5) http.IncomingMessage
该类的对象可通过这两种方式创建:http.Server,当监听 request 事件时。http.ClientRequest,当监听 response 事件时。
它可以用来访问响应:
使用 statusCode 和 statusMessage 方法来访问状态。
使用 headers 方法或 rawHeaders 来访问消息头。
使用 method 方法来访问 HTTP 方法。
使用 httpVersion 方法来访问 HTTP 版本。
使用 url 方法来访问 URL。
使用 socket 方法来访问底层的 socket。
2. http模块简单案例实践
创建一个server.js,我们一点一点来用这个http模块:
const http=require('http')
// 创建服务器
http.createServer((req,res)=>{
//接收浏览器传的参数,返回渲染的内容,都在这个回调函数里面来做
//req是接收的浏览器的参数,res是返回给浏览器渲染的内容。
}).listen(3000,()=>{
console.log("server start")
})
/* listen()方法的第一个参数是端口号,第二个参数是一个回调函数,这个回调函数是服务器创建成功后执行的函数 */
命令行运行node server.js ,会看到server start打印在控制台了,并且光标在闪动,这表示服务创建成功,并监听了这个服务。现在浏览器访问http://localhost:3000/,浏览器还访问不到任何东西,因为我们没有返回任何数据。
我们可以在createServer()的回调里面调用res.write()对浏览器进行输出,res.write()可以调用多次,都会输出在浏览器上。但要注意,最后一定要掉用res.end()。不然浏览器会一直等,直到超时。
const http=require('http')
// 创建服务器
http.createServer((req,res)=>{
//接收浏览器传的参数,返回渲染的内容,都在这个回调函数里面来做
//req是接收的浏览器的参数,res是返回给浏览器渲染的内容。
//可以用res.write()方法,向浏览器输出内容,并且可以写多个
res.write("hello world")
res.write(" abc")
//但要注意,最后一定要掉用res.end()。不然浏览器会一直等,直到超时。但end()后不能再进行其他操作了
res.end()
}).listen(3000,()=>{
console.log("server start")
})
/* listen()方法的第一个参数是端口号,第二个参数是一个回调函数,这个回调函数是服务器创建成功后执行的函数 */
我们改完代码记得重新运行node server.js,重启服务,例如访问http://localhost:3000/。

res.end()里面也可以传东西,也会在浏览器输出显示,如输出字符串。
const http=require('http')
// 创建服务器
http.createServer((req,res)=>{
//接收浏览器传的参数,返回渲染的内容,都在这个回调函数里面来做
//req是接收的浏览器的参数,res是返回给浏览器渲染的内容。
//可以用res.write()方法,向浏览器输出内容,并且可以写多个
res.write("hello world")
res.write(" abc")
//但要注意,最后一定要掉用res.end()。不然浏览器会一直等,直到超时。但end()后不能再进行其他操作了
res.end("[1,2,3]")
}).listen(3000,()=>{
console.log("server start")
})
/* listen()方法的第一个参数是端口号,第二个参数是一个回调函数,这个回调函数是服务器创建成功后执行的函数 */

res.write()方法可以返回html标签,浏览器会渲染成html格式:
const http=require('http')
// 创建服务器
http.createServer((req,res)=>{
//接收浏览器传的参数,返回渲染的内容,都在这个回调函数里面来做
//req是接收的浏览器的参数,res是返回给浏览器渲染的内容。
//res.write()方法可以返回html标签,浏览器会渲染成html格式
res.write(`
hello world
你好害恶细君
`)
//但要注意,最后一定要掉用res.end()。不然浏览器会一直等,直到超时。但end()后不能再进行其他操作了
res.end()
}).listen(3000,()=>{
console.log("server start")
})
/* listen()方法的第一个参数是端口号,第二个参数是一个回调函数,这个回调函数是服务器创建成功后执行的函数 */

虽然res.write()能在浏览器上生成html标签,但是却出现了一个问题,就是中文乱码。我们要通过使用res.writeHead()方法来给浏览器返回消息响应头
const http=require('http')
// 创建服务器
http.createServer((req,res)=>{
//接收浏览器传的参数,返回渲染的内容,都在这个回调函数里面来做
//req是接收的浏览器的参数,res是返回给浏览器渲染的内容。
//使用res.writeHead()方法来给浏览器返回消息响应头
res.writeHead(200,{"Content-Type": "text/html; charset=utf-8"})
//res.write()方法可以返回html标签,浏览器会渲染成html格式
res.write(`
hello world
你好害恶细君
`)
//但要注意,最后一定要掉用res.end()。不然浏览器会一直等,直到超时。但end()后不能再进行其他操作了
res.end()
}).listen(3000,()=>{
console.log("server start")
})
/* listen()方法的第一个参数是端口号,第二个参数是一个回调函数,这个回调函数是服务器创建成功后执行的函数 */
此时,重启服务再访问浏览器时会就发现不会中文乱码了。

我们再来研究一下createServer()的回调里面的req,我们可以控制台打印一下这个req对象,会打印出非常多的东西,其中就有一个url属性,我们打印一下看看:
const http=require('http')
// 创建服务器
http.createServer((req,res)=>{
//打印一下req.url
console.log(req.url)
res.writeHead(200,{"Content-Type": "text/html; charset=utf-8"})
res.end()
}).listen(3000,()=>{
console.log("server start")
})
我们运行后,在浏览器里面访问http://localhost:3000/haiexijun 等路径,会发现req.url打印的就是这个路径:

到这里,我们就可以实现一个通过不同url路径来返回浏览器不同内容的功能:
const http=require('http')
// 创建服务器
http.createServer((req,res)=>{
res.writeHead(renderStatus(req.url),{"Content-Type": "text/html; charset=utf-8"})
res.write(renderHTML(req.url))
res.end()
}).listen(3000,()=>{
console.log("server start")
})
function renderHTML(url){
switch (url){
case '/haiexijun':
return `
你好害恶细君
`
case '/world':
return `
你好世界
`
default :
return `
404 not found
`
}
}
function renderStatus(url){
var arr=["/haiexijun","/world"]
return arr.includes(url)?200:404
}
上面案例中,只有访问 /haiexijun和/world 时才能访问到正确的页面,访问其他的路径时,就都会显示404 not found 的页面,并且状态码也会为404.

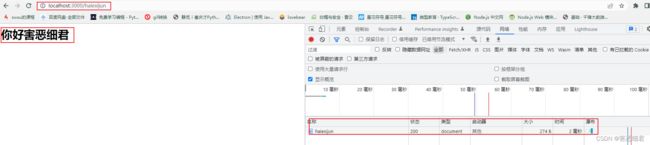
这里稍微体验一下就好,后面会学路由的模块和一些框架,http模块暂时就玩到这里。
3. url模块
我们发现请求的url带有 ?等传参的时候,我们要学习的是对这个传来的参数的处理,这就要用到本小节的url模块了。
parse( ) 方法
url模块的parse()方法会对请求的url进行解析,解析成一个Url对象
const url = require('url')
const urlString = 'https://www.baidu.com:443/ad/index.html?id=8&name=mouse#tag=110'
//parse()方法会对请求的url进行解析,解析成一个Url对象
const parsedStr = url.parse(urlString)
console.log(parsedStr)
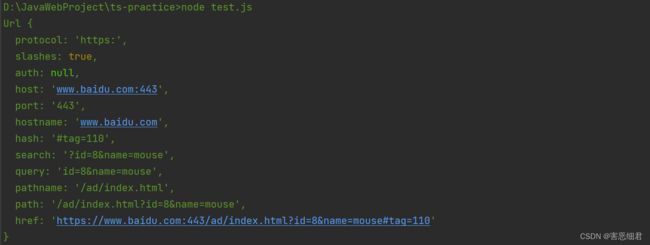
我们看到Url对象里的属性有非常多,我们通过这些属性就可以对路径和参数进行操作。
format( ) 方法
如果你有一个Url对象的话,url的format( ) 方法就可以把这个对象格式化成url地址。
const url = require('url')
const urlObject = {
protocol: 'https:',
slashes: true,
auth: null,
host: 'www.baidu.com:443',
port: '443',
hostname: 'www.baidu.com',
hash: '#tag=110',
search: '?id=8&name=mouse',
query: { id: '8', name: 'mouse' },
pathname: '/ad/index.html',
path: '/ad/index.html?id=8&name=mouse'
}
const parsedObj = url.format(urlObject)
console.log(parsedObj)
![]()
resolve( ) 方法
resolve( ) 方法的作用是可以进行url的拼接。
const url = require('url')
// 注意结尾加 / 和不加 / 的区别
let a = url.resolve('/one/two/three', 'four')
let b = url.resolve('/one/two/three/', 'four')
let c = url.resolve('http://example.com/', '/one')
let d = url.resolve('http://example.com/one', '/two')
console.log(a + "," + b + "," + c)
![]()
上面这些是Node.js旧版url模块的API,很多方法都被遗弃了,我们下面学习一下新版API的用法。
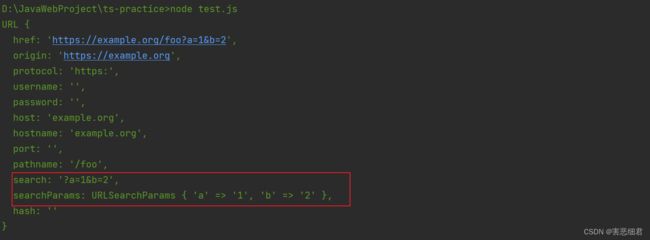
new URL( )
传入两个参数,第一个参数是要解析的绝对或相对的输入网址。如果第一个路径是相对的,则需要 第二个参数。第二个阐述为基本的url地址。
const myURL = new URL('/foo?a=1&b=2', 'https://example.org/');
console.log(myURL)
4. querystring模块
querystring 模块提供了用于解析和格式化网址查询字符串的实用工具。 querystring API 被视为旧版的,官方还在维护。它既然存在过,我们也有必要来学习一下这个模块。
parse( ) 方法
这个方法可以把查询字符串,转化为一个对象
const querystring = require('querystring')
let qs = 'x=3&y=4'
let parsed = querystring.parse(qs)
console.log(parsed)
![]()
stringify( ) 方法
这个方法和上面的parse()方法的用法相反
const querystring = require('querystring')
let qo = {
x: 3,
y: 4
}
let parsed = querystring.stringify(qo)
console.log(parsed)
5. http模块补充知识点
json形式的接口
我们上面案例里面用res.write() 向浏览器返回html标签数据,其实我们还可以向浏览器返回json数据的。
const http = require('http')
const url = require('url')
const app = http.createServer((req, res) => {
let urlObj = url.parse(req.url, true)
switch (urlObj.pathname) {
case '/api/user':
res.end(`{"name": "haiexijun","age":"20"}`)
break
default:
res.end('404 not found')
break
}
})
app.listen(8080, () => {
console.log('start server')
})

跨域:CORS
res.writeHead(200, {
'content-type': 'application/json;charset=utf-8',
'Access-Control-Allow-Origin': '*'
})
执行 GET 请求
有些时候,前端无法跨域去请求数据。而Node.js却可以实现跨域请求数据。所以Node.js常常位于前端和后端中间,帮前端请求后端数据。所以node.js往往用于做中间层。这样就跨域去请求别人网站上的数据,然后为自己所用,比如爬虫等。
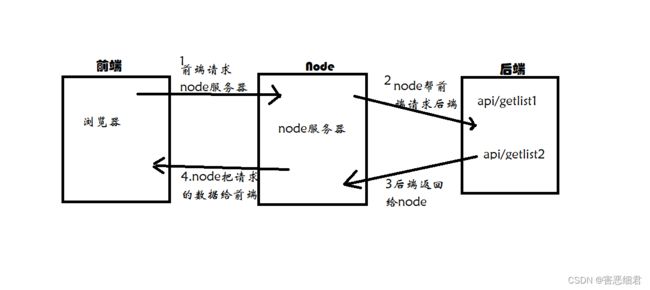
下面我们来用Node.js来get请求获取数据:
const https = require('https')
let datas = ''
//因为要请求的数据时https的,所以也要用https模块请求
https.get("https://img-home.csdnimg.cn/data_json/toolbar/toolbar1105.json",response => {
//node.js是对数据一部分一部分获取的
//请求数据,触发node.js的data事件时,会调用后面定义的回调函数对数据进行拼接
response.on('data',(chunk)=>{
datas += chunk
})
//当Node.js请求完数据时,会触发end事件,调用后面定义的的回调函数。
response.on('end',()=>{
console.log(datas)
})
})
我们启动服务后看到控制台输出了请求过来的数据:
POST请求其实大同小异,只是用的方法不一样而已,POST请求用https.request方法进行请求。
const https = require('https')
//请求的数据要转成json格式
const datas = JSON.stringify({
todo: '做点事情'
})
const options = {
hostname: 'nodejs.cn',
port: 443,
path: '/todos',
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Content-Length': data.length
}
}
const req = https.request(options, res => {
res.on('data', (chunk) => {
dada+=chunk
})
})
req.on('end', () => {
console.error(error)
})
//请求的数据datas要writey发出去哦!!
req.write(data)
req.end()
其实除了用Node.js的内部模块发http请求意外,还可以用第三方模块来发送请求,比如我们常用的axios。
6. event事件模块
events 模块为提供了 EventEmitter 类,这是在 Node.js 中处理事件的关键。
const EventEmitter = require('events')
//new EventEmitter()构造函数来创建event对象
const event = new EventEmitter();
//on()添加当事件被触发时调用的回调函数。
event.on('play',()=>{
console.log("play事件触发了")
})
// emit()触发事件, 按照事件被注册的顺序同步地调用每个事件监听器。
event.emit("play")
EventEmitter 对象还有很多方法,这里就不多解释了。你只要知道event模块能干什么就好,用到的时候再去查吧。
7. fs文件操作模块
要对文件进行操作,先要引入fs模块。
const fs = require('fs')
文件夹的操作
(1) 创建新的文件夹 :使用 fs.mkdir() 或 fs.mkdirSync() 可以创建新的文件夹。
const fs = require('fs')
//方法传入两个参数,第一个参数是路径,可以是绝对路径,也可以是相对路径
//第二个参数是错误时的回调
fs.mkdir("./test",(err)=>{
console.log(err)
})
fs.mkdirSync() 是同步的版本,要用try catch捕获异常,而不是回调:
const fs = require('fs')
const folderName = './test'
try {
if (!fs.existsSync(folderName)) {
fs.mkdirSync(folderName)
}
} catch (err) {
console.error(err)
}
(2) 查看文件夹或文件是否存在:使用fs.existsSync( )传入文件或文件夹的名称就好了。会返回一个布尔值。
const fs = require('fs')
isExist=fs.existsSync("./test")
console.log(isExist)
(3) 读取目录的内容 :使用 fs.readdir() 或 fs.readdirSync() 可以读取目录的内容。
下面这段代码会读取文件夹的内容(全部的文件和子文件夹),并返回它们的相对路径:
const fs = require('fs')
const path = require('path')
const folderPath = './test'
console.log(fs.readdirSync(folderPath))
(4) 重命名文件夹 :使用 fs.rename() 或 fs.renameSync() 可以重命名文件夹。 第一个参数是当前的路径,第二个参数是新的路径。
const fs = require('fs')
fs.rename('./test', './haiexijun', err => {
if (err) {
console.error(err)
return
}
})
fs.renameSync() 是同步的版本,要用try catch捕获异常,而不是回调:
const fs = require('fs')
try {
fs.renameSync('./test', './haiexijun')
} catch (err) {
console.error(err)
}
(5) 删除文件夹 :使用 fs.rmdir() 或 fs.rmdirSync() 可以删除文件夹。
删除包含内容的文件夹可能会更复杂。在这种情况下,最好安装 fs-extra 模块,该模块非常受欢迎且维护良好。 它是 fs 模块的直接替代品,在其之上提供了更多的功能。
使用以下命令安装:
npm install fs-extra
并像这样使用它:
const fs = require('fs-extra')
const folder = './test'
fs.remove(folder, err => {
console.error(err)
})
也可以与 promise 一起使用:
fs.remove(folder)
.then(() => {
//完成
})
.catch(err => {
console.error(err)
})
或使用 async/await:
async function removeFolder(folder) {
try {
await fs.remove(folder)
//完成
} catch (err) {
console.error(err)
}
}
const folder = '/Users/joe'
removeFolder(folder)
文件操作
(1)写内容到文件里 使用fs.writeFile()
const fs = require('fs')
// 写内容到文件里
fs.writeFile(
'./test/test2.txt',
'hello',
// 错误的回调函数
(err) => {
if (err) {
console.log(err.message)
} else {
console.log('文件创建成功')
}
}
)
另外,也可以使用同步的版本 fs.writeFileSync():
const fs = require('fs')
const content = '一些内容'
try {
const data = fs.writeFileSync('./test/test.txt', content)
//文件写入成功。
} catch (err) {
console.error(err)
}
默认情况下,此 API 会替换文件的内容(如果文件已经存在)。可以通过指定标志来修改默认的行为:
const fs = require('fs')
// 写内容到文件里
fs.writeFile(
'./test/test2.txt',
'hello',
{
flag:"a+"
},
// 错误的回调函数
(err) => {
if (err) {
console.log(err.message)
} else {
console.log('文件创建成功')
}
}
)
常用的标志有,其他用到再查:
r+ 打开文件用于读写。
w+ 打开文件用于读写,将流定位到文件的开头。如果文件不存在则创建文件。
a 打开文件用于写入,将流定位到文件的末尾。如果文件不存在则创建文件。
a+ 打开文件用于读写,将流定位到文件的末尾。如果文件不存在则创建文件。
(2)删除文件 :可以使用fs.unlink()删除文件
const fs = require('fs')
fs.unlink('./test/test2.txt', (err) => {
console.log('done.')
})
(3) 批量写文件
const fs = require('fs')
for (let i = 0; i < 10; i++) {
fs.writeFile(`./test/log-${i}.txt`, `log-${i}`,{flag:"a+"}, (err) => {
console.log('done.')
})
}
(4) 读取文件
在 Node.js 中读取文件最简单的方式是使用 fs.readFile() 方法,向其传入文件路径、编码、以及会带上文件数据(以及错误)进行调用的回调函数:
const fs = require('fs')
fs.readFile('./test/test.txt', 'utf8' , (err, data) => {
if (err) {
console.error(err)
return
}
console.log(data)
})
另外,也可以使用同步的版本 fs.readFileSync():
const fs = require('fs')
try {
const data = fs.readFileSync('./test/test.txt', 'utf8')
console.log(data)
} catch (err) {
console.error(err)
}
fs.readFile() 和 fs.readFileSync() 都会在返回数据之前将文件的全部内容读取到内存中。
这意味着大文件会对内存的消耗和程序执行的速度产生重大的影响。
在这种情况下,更好的选择是使用流来读取文件的内容。我们下面马上就会讲到流模块。
在fs模块中,提供同步方法是为了方便使用。那我们到底是应该用异步方法还是同步方法呢?
由于Node环境执行的JavaScript代码是服务器端代码,所以,绝大部分需要在服务器运行期反复执行业务逻辑的代码,必须使用异步代码,否则,同步代码在执行时期报错或阻塞,服务器将停止响应,因为JavaScript只有一个执行线程。
服务器启动时如果需要读取配置文件,或者结束时需要写入到状态文件时,可以使用同步代码,因为这些代码只在启动和结束时执行一次,不影响服务器正常运行时的异步执行。
8. stream流模块
stream是Node.js提供的又一个仅在服务区端可用的模块,目的是支持“流”这种数据结构。
什么是流?流是一种抽象的数据结构。想象水流,当在水管中流动时,就可以从某个地方(例如自来水厂)源源不断地到达另一个地方(比如你家的洗手池)。我们也可以把数据看成是数据流,比如你敲键盘的时候,就可以把每个字符依次连起来,看成字符流。这个流是从键盘输入到应用程序,实际上它还对应着一个名字:标准输入流。
如果应用程序把字符一个一个输出到显示器上,这也可以看成是一个流,这个流也有名字:标准输出流。流的特点是数据是有序的,而且必须依次读取,或者依次写入,不能像Array那样随机定位。
有些流用来读取数据,比如从文件读取数据时,可以打开一个文件流,然后从文件流中不断地读取数据。有些流用来写入数据,比如向文件写入数据时,只需要把数据不断地往文件流中写进去就可以了。
在Node.js中,流也是一个对象,我们只需要响应流的事件就可以了:data事件表示流的数据已经可以读取了,end事件表示这个流已经到末尾了,没有数据可以读取了,error事件表示出错了。
const fs = require('fs');
// 打开一个流:
let rs = fs.createReadStream('./test/test.txt', 'utf-8');
rs.on('data', function (chunk) {
console.log('DATA:')
console.log(chunk);
});
rs.on('end', function () {
console.log('END');
});
rs.on('error', function (err) {
console.log('ERROR: ' + err);
});


要注意,data事件可能会有多次,每次传递的chunk是流的一部分数据。但是上面案例文件的内容太少了,所以一次就读出来了。
要以流的形式写入文件,只需要不断调用write()方法,最后以end()结束:
const fs = require('fs');
let ws1 = fs.createWriteStream('./test/test.txt', 'utf-8');
ws1.write('使用Stream写入文本数据...\n');
ws1.write('1111111111111111111111111111\n');
ws1.write('22222222222222222222222222222\n');
ws1.write('END.');
ws1.end();
如果要实现一个文件一边读一边写入呢?可以用到pipe
pipe 就像可以把两个水管串成一个更长的水管一样,两个流也可以串起来。一个Readable流和一个Writable流串起来后,所有的数据自动从Readable流进入Writable流,这种操作叫pipe。
在Node.js中,Readable流有一个pipe()方法,就是用来干这件事的。
让我们用pipe()把一个文件流和另一个文件流串起来,这样源文件的所有数据就自动写入到目标文件里了,所以,这实际上是一个复制文件的程序:
const fs = require('fs')
const readstream = fs.createReadStream('./1.txt')
const writestream = fs.createWriteStream('./2.txt')
readstream.pipe(writestream)
9. zlib模块
大家都知道,我们的浏览器要想去加载一个html的过程是由服务器读取文件后返回给浏览器的,在这个过程中,文件可能挺大的,我们可以在传输时打包压缩,到了浏览器中时,浏览器再对其解压缩后显示出来就可以了。很多网站中,我们会发现他们很多都是通过gzip这种方式把原来的那些静态资源文件,给压缩成gzip来传给浏览器,浏览器再解压出来的。
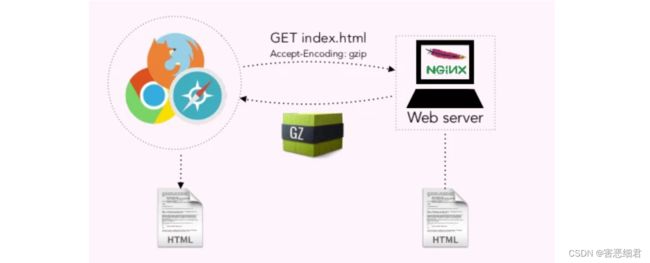
我们先写一个不用压缩技术的程序,给浏览器传一个js文件,看看文件的大小:
const fs = require('fs')
const http = require('http')
http.createServer((req, res) =>{
//创建可读流
let readStream=fs.createReadStream("./index.js")
res.writeHead(200,{"Content-Type": "application/x-javascript;charset=utf-8"})
//把可读流通过管道,送到res可写流当中去
readStream.pipe(res)
}).listen(3000,()=>{
console.log("server start")
})
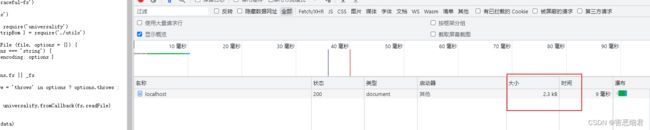
在没有压缩的情况下传输,大小为2.3 KB。
下面我们对程序改一个,采用gzip的压缩方式传输:
const fs = require('fs')
const zlib = require('zlib')
const http = require('http')
//通过zlib创建gzip对象
const gzip = zlib.createGzip();
http.createServer((req, res) =>{
//创建可读流
let readStream=fs.createReadStream("./index.js")
//gzip传输文件,响应头要加上"Content-Encoding":"gzip" ,不然浏览器无法解析gzip的文件
res.writeHead(200,{
"Content-Type": "application/x-javascript;charset=utf-8",
"Content-Encoding":"gzip"
})
//把可读流通过管道时先经过gzip压缩后,在送到res可写流当中去
readStream.pipe(gzip).pipe(res)
}).listen(3000,()=>{
console.log("server start")
})

这时浏览器再访问,发现大小居然变成190 B了。
10. crypto模块
crypto模块的目的是为了提供通用的加密和哈希算法。用纯JavaScript代码实现这些功能不是不可能,但速度会非常慢。Nodejs用C/C++实现这些算法后,通过crypto这个模块暴露为JavaScript接口,这样用起来方便,运行速度也快。
MD5是一种常用的哈希算法,用于给任意数据一个“签名”。这个签名通常用一个十六进制的字符串表示:
const crypto = require('crypto');
const hash = crypto.createHash('md5');
//可以用update方法把一段字符给加密
hash.update("hello csdn")
//digest()该函数可以传入两个参数:hex(十六进制)或 base64 ,表示以什么形式输出
console.log(hash.digest("base64"))
![]()
update()方法默认字符串编码为UTF-8,也可以传入Buffer。
如果要计算SHA1,只需要把'md5'改成'sha1',就可以得到SHA1的结果1f32b9c9932c02227819a4151feed43e131aca40。
Hmac算法也是一种哈希算法,它可以利用MD5或SHA1等哈希算法。不同的是,Hmac还需要一个密钥:
const crypto = require('crypto');
//密钥
let secretKey="32332fd22fd"
const hmac = crypto.createHmac('sha256', secretKey);
hmac.update('Hello, nodejs!');
console.log(hmac.digest('hex'));
只要密钥发生了变化,那么同样的输入数据也会得到不同的签名,因此,可以把Hmac理解为用随机数“增强”的哈希算法。
AES是一种常用的对称加密算法,加解密都用同一个密钥。crypto模块提供了AES支持,但是需要自己封装好函数,便于使用:
const crypto = require("crypto");
//加密的方法
//key,iv必须是16个字节
function encrypt (key, iv, data) {
//加密和解密都要用同一种算法,这里是aes-128-cbc
let decipher = crypto.createCipheriv('aes-128-cbc', key, iv);
return decipher.update(data, 'binary', 'hex') + decipher.final('hex');
}
//解密的方法
function decrypt (key, iv, crypted) {
crypted = Buffer.from(crypted, 'hex').toString('binary');
let decipher = crypto.createDecipheriv('aes-128-cbc', key, iv);
return decipher.update(crypted, 'binary', 'utf8') + decipher.final('utf8');
}
//测试加密和解密
let key = "abcdef1234567890"
let iv = "djfiuchfbd887766"
let data = "hello world"
//加密
let encry = encrypt(key,iv,data)
console.log(encry)
//解密
let decry = decrypt(key,iv,encry)
console.log(decry)

可以看出,加密后的字符串通过解密又得到了原始内容。
11. 路由小练习
路由就是服务器对前端访问传来的不同路径的处理的一种机制就叫路由。我们这一节就慢慢打造一个路由,来检验我们上面知识的学习成果。注意,这里只是模拟写,有一些细节问题勿喷。
我们项目下新建一个static文件夹,里面提前创建好home.html 、login.html 、404.html 。然后创建一个server.js创建服务器。
先来写一个最笨的路由版本:
server.js代码:
const http=require("http")
const fs=require("fs")
http.createServer((req, res) => {
let myURL = new URL(req.url,"http://127.0.0.1");
switch (myURL.pathname) {
case "/login":
res.writeHead(200,{
"Content-Type":"text/html;charset=utf-8",
});
res.write(fs.readFileSync("./static/login.html","utf8"));
break
case "/home":
res.writeHead(200,{
"Content-Type":"text/html;charset=utf-8",
});
res.write(fs.readFileSync("./static/home.html","utf8"));
break
default :
res.writeHead(404,{
"Content-Type":"text/html;charset=utf-8",
});
res.write(fs.readFileSync("./static/404.html","utf8"));
break
}
res.end()
}).listen(3000,()=>{
console.log("server start")
})
我们发现上面的写法是不是很麻烦很冗杂啊?我们其实可以把switch单独拿到一个router.js文件中,用module.exports导出。
server.js:
const http=require("http")
const router =require("./router")
http.createServer((req, res) => {
let myURL = new URL(req.url,"http://127.0.0.1");
router(res,myURL.pathname);
res.end()
}).listen(3000,()=>{
console.log("server start")
})
router.js:
const fs=require("fs")
function router(res,pathname){
switch (pathname) {
case "/login":
res.writeHead(200,{
"Content-Type":"text/html;charset=utf-8",
});
res.write(fs.readFileSync("./static/login.html","utf8"));
break
case "/home":
res.writeHead(200,{
"Content-Type":"text/html;charset=utf-8",
});
res.write(fs.readFileSync("./static/home.html","utf8"));
break
default :
res.writeHead(404,{
"Content-Type":"text/html;charset=utf-8",
});
res.write(fs.readFileSync("./static/404.html","utf8"));
break
}
}
module.exports = router;
虽然小小地改造了一下,但我还是对改造不怎么满意,我们发现switch写得还是太复杂了。
我们再代码进行改造:
router.js:
const fs = require("fs")
const path = require("path")
//把重复的方法封装成一个函数
function render(res, path) {
res.writeHead(200, { "Content-Type": "text/html;charset=utf8" })
res.write(fs.readFileSync(path, "utf8"))
res.end()
}
const router = {
"/login": (req, res) => {
render(res, "./static/login.html")
},
"/home": (req, res) => {
render(res, "./static/home.html")
},
"/404": (req, res) => {
res.writeHead(404, { "Content-Type": "text/html;charset=utf8" })
res.write(fs.readFileSync("./static/404.html", "utf8"))
}
}
module.exports = router;
server.js:
const http=require("http")
const router =require("./router")
http.createServer((req, res) => {
let myURL = new URL(req.url,"http://127.0.0.1");
try {
router[myURL.pathname](req,res);
}catch (e){
router["/404"](req,res);
}
}).listen(3000,()=>{
console.log("server start")
})
12. path路径模块
path 模块提供了许多非常实用的函数来访问文件系统并与文件系统进行交互,是非常重要的一个模块。
我们无需安装,它作为 Node.js 核心的组成部分,可以通过简单地引用来使用它:
const path = require('path')
该模块提供了 path.sep(作为路径段分隔符,在 Windows 上是 \,在 Linux/macOS 上是 /)和 path.delimiter(作为路径定界符,在 Windows 上是 ;,在 Linux/macOS 上是 :)。
path模块有如下常用的方法:
(1) path.basename()
用于返回路径的最后一部分。 第二个参数可以过滤掉文件的扩展名:
const path = require('path')
console.log(path.basename('/test/something'));//something
console.log(path.basename('/test/something.txt')); //something.txt
console.log(path.basename('/test/something.txt', '.txt'));//something

(2) path.dirname()
用于返回路径的目录部分。
const path = require('path')
console.log(path.dirname('/test/something'));// test
console.log(path.dirname('/test/something/file.txt')); // test/something
![]()
(3) path.extname()
返回路径的扩展名部分。
const path = require('path')
console.log(path.extname('/test/something')) // ''
console.log(path.extname('/test/something/file.txt')) // .txt
(4) path.isAbsolute()
判断是否为绝对路径,如果是绝对路径,则返回 true。
const path = require('path')
console.log(path.isAbsolute('/test/something')) // true
console.log(path.isAbsolute('./test/something')) // false
(6) path.join()
连接路径的两个或多个部分
const path = require('path')
const name = 'haiexijun'
console.log(path.join('/', 'users', name, 'notes.txt')) // \users\haiexijun\notes.txt
(7) path.normalize()
当包含类似 .、.. 或双斜杠等相对的说明符时,则尝试计算实际的路径:
const path = require('path')
console.log(path.normalize('/users/haiexijun/..//test.txt')) // \users\test.txt
(8) path.parse()
解析对象的路径为组成其的片段:
const path = require('path')
console.log(path.parse('/users/test.txt')) // \users\test.txt

root: 根路径。
dir: 从根路径开始的文件夹路径。
base: 文件名 + 扩展名
name: 文件名
ext: 文件扩展名
(9) path.relative()
接受 2 个路径作为参数。 基于当前工作目录,返回从第一个路径到第二个路径的相对路径。
const path = require('path')
console.log(path.relative('/Users/haiexijun', '/Users/haiexijun/test.txt')) // test.txt
console.log(path.relative('/Users/haiexijun', '/Users/haiexijun/something/test.txt')) // something\test.txt
(10) path.resolve()
可以使用 path.resolve() 获得相对路径的绝对路径计算。
const path = require('path')
console.log(path.resolve('test.txt')) // D:\JavaWebProject\ts-practice\test.txt
通过指定第二个参数,resolve 会使用第一个参数作为第二个参数的基准:
const path = require('path')
console.log(path.resolve('tmp', 'test.txt')) // D:\JavaWebProject\ts-practice\tmp\test.txt
如果第一个参数以斜杠开头,则表示它是绝对路径:
const path = require('path')
console.log(path.resolve('/tmp', 'test.txt')) // D:\tmp\test.txt
(11) __dirname和__filename 内置常量
内置的意思就是不需要额外去定义它,它的作用就是表示当前所在的地址
__dirname:用来动态获取当前文件模块所属目录的绝对路径
__filename:用来动态获取当前文件的绝对路径
const path = require('path')
console.log(__dirname) // D:\JavaWebProject\ts-practice
console.log(__filename) // D:\JavaWebProject\ts-practice\server.js
13. os操作系统模块
该模块提供了许多函数,可用于从底层的操作系统和程序运行所在的计算机上检索信息并与其进行交互。
const os = require('os')
os 提供的主要方法:
(1) os.arch()
返回标识底层架构的字符串,例如 arm、x64、arm64。
(2) os.cpus()
返回关于系统上可用的 CPU 的信息。
(3) os.freemem()
返回代表系统中可用内存的字节数。
(4) os.homedir()
返回到当前用户的主目录的路径。
(5) os.hostname()
返回主机名。
(6) os.loadavg()
返回操作系统对平均负载的计算。
(7) os.networkInterfaces()
返回系统上可用的网络接口的详细信息。
(8) os.platform()
返回为 Node.js 编译的平台有:darwin、freebsd、linux、openbsd、win32
(9) os.release()
返回标识操作系统版本号的字符串。
(10) os.tmpdir()
返回指定的临时文件夹的路径。
(11) os.totalmem()
返回表示系统中可用的总内存的字节数。
(12) os.type()
标识操作系统:在macOS 上为Darwin,在Windows 上为 Windows_NT。
(13) os.uptime()
返回自上次重新启动以来计算机持续运行的秒数。
(14) os.userInfo()
返回包含当前 username、uid、gid、shell 和 homedir 的对象。
14. Buffer二进制缓冲区
Buffer 对象用于表示固定长度的字节序列,可以将 buffer 视为存储二进制数据的数组,每个整数代表一个数据字节。
Buffer 被引入用以帮助开发者处理二进制数据,在此生态系统中传统上只处理字符串而不是二进制数据。
Buffer 与流紧密相连。 当流处理器接收数据的速度快于其消化的速度时,则会将数据放入 buffer 中。
一个简单的场景是:当观看 哔哩哔哩 的 视频时,白线超过了观看点:即下载数据的速度比查看数据的速度快,且浏览器会对数据进行缓冲。
使用Buffer不用引入模块,直接使用就可以了。使用 Buffer.from()、Buffer.alloc() 和Buffer.allocUnsafe()方法可以创建 buffer。
let str = "hello"
let buf = Buffer.from(str);
console.log(buf);

我们上面不是说,Buffer 是以二进制数据存储的吗?这里为什么不是二进制呢?但其实计算机里是以二进制数据存储,但显示时会以十六进制去显示,这是因为二进制太长了。
我们要创建指定字节的空的Buffer , 可以用Buffer.alloc() 和Buffer.allocUnsafe()
let buf1 = Buffer.alloc(1024)
let buf2 = Buffer.allocUnsafe(1024)
虽然 alloc 和 allocUnsafe 均分配指定大小的 Buffer(以字节为单位),但是 alloc 创建的 Buffer 会被使用零进行初始化,而 allocUnsafe 创建的 Buffer 不会被初始化。 这意味着,尽管 allocUnsafe 比 alloc 要快得多,但是分配的内存片段可能包含可能敏感的旧数据。
当 Buffer 内存被读取时,如果内存中存在较旧的数据,则可以被访问或泄漏。 这就是使 allocUnsafe 不安全的原因,在使用它时必须格外小心。
let buf = Buffer.alloc(10)
buf[0] = 88 //可以存16进制
buf[1] = 0xaa;//可以存8进制
//可以使用 toString() 方法打印 buffer 的全部内容:
console.log(buf.toString())
//使用 length 属性获取 buffer 的长度
console.log(buf.length)
要注意Buffer的长度大小一旦确定,就不可以修改了,Buffer其实是对底层内存的直接操作。
当然,还有非常多的方法,这里就不一 一例举了。大家看到这里知道Buffer的作用就好了。

篇尾总结:Node.js涉及的知识点太多了,到这里已经3万多字了。我无法一口气总结完所有的知识点,故本片总结一些Node.js的基础常用知识点,学完这些知识点,你对Node.js也会有一定的认识了,恭喜你,可以说是入门啦。进阶一些Node.js的衍生框架应该不成问题了。至于我本节遗漏的那些Node内置模块和方法,我将来再慢慢总结。我在这里求一个关注、点赞、收藏、评论。拜托了,这对我真的很重要!