谷歌翻译结束了中国大陆业务;投资炼金术!用户投资交易辅助系统;矢量搜索应用指南与最佳实践;可调整参数的AI绘图插件;前沿论文 | ShowMeAI资讯日报

日报合辑 | 电子月刊 | 公众号下载资料 | @韩信子
因使用率过低,Google Translate 结束中国大陆区域的翻译服务
日前不少用户在 Reddit 网站上反馈国内无法正常使用谷歌翻译。随后谷歌发言人通过电子邮件回复 TechCrunch 媒体,承认谷歌结束了其在中国大陆的翻译业务,原因是『使用率低』。
根据用户反馈与网站档案,9月末的某个时间点,谷歌将 translate.google.cn 的翻译界面换成了一个普通的搜索页面,并将访问者重定向到其香港的域名 translate.google.com.hk。
此做法与此前谷歌搜索、谷歌地图等功能退出中国大陆时一致。早在 2010 年谷歌宣布退出中国之后,仅仅保留了谷歌翻译和谷歌地图两款服务。2020 年 2 月 3 日起,谷歌地图在国内停止服务,现在,最后的谷歌翻译服务也关闭了。
目前谷歌在国内仍然提供部分可被访问的功能,包括谷歌广告、开发者社区、Android 开发者社区等,主要为开发者和客户提供支持。

工具&框架
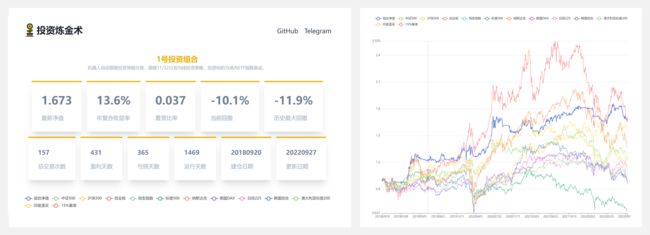
『Invest Alchemy』投资炼金术用户投资交易辅助系统
https://github.com/bmpi-dev/invest-alchemy
https://money.bmpi.dev/
为了满足上班族或业余投资者简单长期的投资需求,作者开源了这个投资炼金术这个辅助用户投资交易的系统。

系统可以从投资组合整体的角度评价交易策略的风险与收益,而不像大多量化投资软件,解决了交易策略在模拟回测与投资组合实践中差距过大的问题。
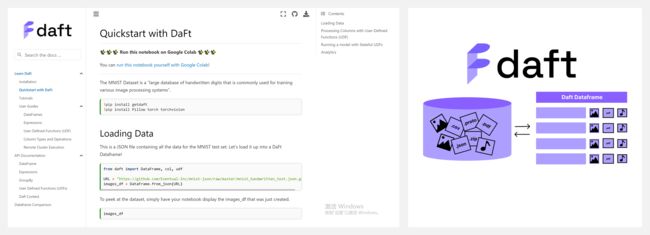
『Daft』为机器学习与复杂数据设计的快速可扩展数据库
https://github.com/Eventual-Inc/Daft
https://getdaft.io/
Daft 是一个快速和可扩展的开源数据框架库,为 Python 和复杂数据/机器学习工作负载而构建。处理复杂的数据(如图像/音频/点云),通常需要加速几何或机器学习算法的计算,其中大部分是利用Python/C++生态系统的现有工具。然而,许多工作负载,如分析、模型训练数据整理和数据处理,往往也需要加载/过滤/连接/聚合的关系查询操作。Daft可以很好地支持这些功能。
『VR-Baseline』视频恢复工具包
https://github.com/linjing7/VR-Baseline
VR-Baseline 是一个视频恢复工具包,包括超分辨率、去模糊、压缩视频质量提等功能实现。
『DataSloth』基于GPT-3的自然语言查询工具
https://github.com/ibestvina/datasloth
DataSloth 是一个基于 GPT-3 的自然语言查询工具,它可以搭配 pandas dataframe 格式的数据,基于自然语言描述进行数据查询。
『txt2img2img for Stable Diffusion』Stability Diffusion插件
https://github.com/ThereforeGames/txt2img2img
txt2img2img 是 AUTOMATIC1111 的 Stable Diffusion Web UI 的一个实验性插件,它简化了通过 txt2img 运行提示的过程,然后使用预先定义的参数通过 img2img 运行其输出。除了能够定义你自己的关键词和预设之外,txt2img2img 还可以根据 txt2img 的输出结果,智能地自动调整 img2img 阶段的参数。
博文&分享
『Vector Search』矢量搜索应用指南
https://github.com/esteininger/vector-search
矢量搜索引擎为开发人员提供了存储围绕某些算法(即KNN)的向量的能力,并提供了计算相似向量(如余弦距离)的引擎来确定矢量相关的矢量。Repo 提供了包括教程、指南、最佳实践和扩展学习的矢量搜索景观的全面概述。

数据&资源
『Ethics Union Bibliography』伦理相关资源列表
https://github.com/acl-org/ethics-reading-list
为自然语言处理和计算语言学的研究人员和从业者提供的伦理相关资源列表。这是由现任 ACL 道德委员会主持的公开名单。

研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.09.16 『异常检测』 A Deep Moving-camera Background Model
- 2022.09.15 『点云分割』 Can We Solve 3D Vision Tasks Starting from A 2D Vision Transformer?
- 2022.09.16 『知识蒸馏』 Deliberated Domain Bridging for Domain Adaptive Semantic Segmentation
⚡ 论文:A Deep Moving-camera Background Model
论文时间:16 Sep 2022
领域任务:Anomaly Detection, Change Detection,异常检测
论文地址:https://arxiv.org/abs/2209.07923
代码实现:https://github.com/bgu-cs-vil/deepmcbm
论文作者:Guy Erez, Ron Shapira Weber, Oren Freifeld
论文简介:Moreover, existing MCBMs usually model the background either on the domain of a typically-large panoramic image or in an online fashion./此外,现有的MCBMs通常是在典型的大型全景图像领域或以在线方式对背景进行建模。
论文摘要:在视频分析中,背景模型有很多应用,如背景/前景分离、变化检测、异常检测、跟踪等等。然而,虽然在静态摄像机拍摄的视频中学习这样的模型是一项相当成熟的任务,但在移动摄像机背景模型(MCBM)的情况下,由于摄像机运动所带来的算法和可扩展性的挑战,其成功率要低得多。因此,现有的MCBM在其范围和支持的相机运动类型方面是有限的。这些障碍也阻碍了在这种无监督的任务中采用基于深度学习(DL)的端到端解决方案。此外,现有的MCBMs通常在典型的大型全景图像领域或以在线方式对背景进行建模。不幸的是,前者产生了几个问题,包括可扩展性差,而后者则妨碍了对摄像机重新访问场景中以前看到的部分的识别和利用。本文提出了一种新的方法,称为DeepMCBM,它消除了所有上述的问题,并取得了最先进的结果。具体来说,首先我们确定了与一般视频帧的联合对齐相关的困难,特别是在DL环境下。接下来,我们提出了一个新的联合对齐策略,让我们使用一个空间变换器网,既没有正则化,也没有任何形式的专门(和非差异化)的初始化。再加上一个以非扭曲的稳健中心矩为条件的自动编码器(从联合对齐中获得),这就产生了一个端到端的无正则化的MCBM,它支持广泛的相机运动并能优雅地扩展。我们在各种视频上证明了DeepMCBM的实用性,包括其他方法无法解决的问题。我们的代码可在 https://github.com/BGU-CS-VIL/DeepMCBM
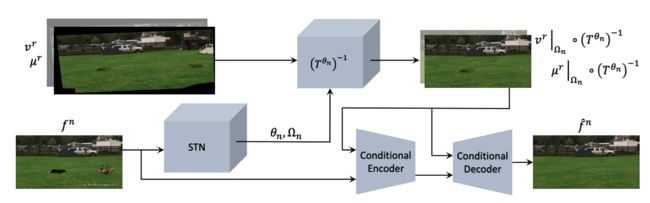
⚡ 论文:Can We Solve 3D Vision Tasks Starting from A 2D Vision Transformer?
论文时间:15 Sep 2022
领域任务:Point Cloud Segmentation,点云分割
论文地址:https://arxiv.org/abs/2209.07026
代码实现:https://github.com/VITA-Group/Simple3D-Former , https://github.com/reimilia/simple3d-former
论文作者:Yi Wang, Zhiwen Fan, Tianlong Chen, Hehe Fan, Zhangyang Wang
论文简介:Vision Transformers (ViTs) have proven to be effective, in solving 2D image understanding tasks by training over large-scale image datasets; and meanwhile as a somehow separate track, in modeling the 3D visual world too such as voxels or point clouds./视觉变换器(ViTs)已被证明是有效的,通过对大规模图像数据集的训练来解决二维图像理解任务;同时,作为一个独立的轨道,在三维视觉世界的建模方面也是如此,如体素或点云。
论文摘要:事实证明,视觉Transformers(ViTs)通过对大规模图像数据集的训练,在解决二维图像理解任务方面是有效的;同时,作为一个独立的方向,在对三维视觉世界(如体素或点云)建模方面也是如此。然而,随着人们越来越希望转化器能够成为异质数据的 "通用 "建模工具,用于二维和三维任务的ViTs到目前为止已经采用了截然不同的架构设计,几乎无法转移。这就引出了一个(过于)雄心勃勃的问题:我们能否缩小二维和三维ViT架构之间的差距?作为一项试验性研究,本文展示了理解3D视觉世界的诱人前景,使用标准的2D ViT架构,只需在输入和输出层面进行最小的定制,而无需重新设计管道。为了从其二维兄弟姐妹中建立一个三维ViT,我们 "膨胀 "了补丁嵌入和标记序列,同时还设计了新的位置编码机制以匹配三维数据的几何结构。由此产生的 "极简 "3D ViT被命名为Simple3D-Former,与高度定制的3D特定设计相比,它在流行的3D任务中表现得非常稳健,如物体分类、点云分割和室内场景检测。因此,它可以作为新的三维ViTs的一个强有力的基线。此外,我们注意到,追求一个统一的2D-3D ViT设计,除了科学上的好奇心,还有实际意义。具体来说,我们证明了Simple3D-Former能够自然地利用来自大规模现实二维图像(如ImageNet)的预训练权重,这些权重可以被 "免费"插入以提高三维任务的性能。

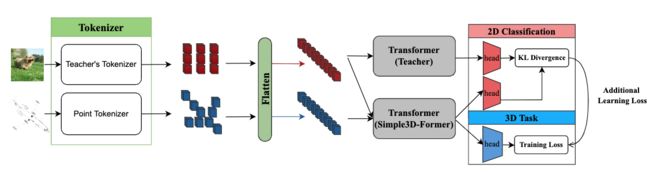
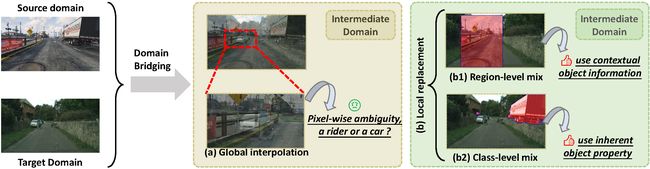
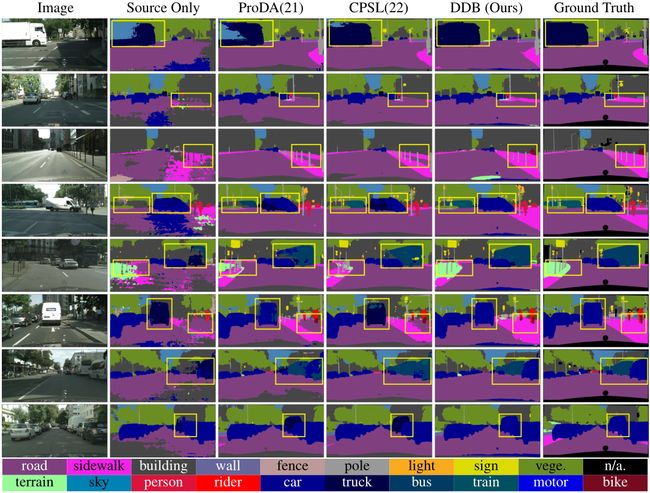
⚡ 论文:Deliberated Domain Bridging for Domain Adaptive Semantic Segmentation
论文时间:16 Sep 2022
领域任务:Knowledge Distillation, Semantic Segmentation, 知识蒸馏,语义分割
论文地址:https://arxiv.org/abs/2209.07695
代码实现:https://github.com/xiaoachen98/DDB
论文作者:Lin Chen, Zhixiang Wei, Xin Jin, Huaian Chen, Miao Zheng, Kai Chen, Yi Jin
论文简介:In this work, we resort to data mixing to establish a deliberated domain bridging (DDB) for DASS, through which the joint distributions of source and target domains are aligned and interacted with each in the intermediate space./在这项工作中,我们借助于数据混合,为DASS建立了一个商议的领域桥接(DDB),通过它,源域和目标域的联合分布被对齐,并在中间空间相互作用。
论文摘要:在无监督领域适应(UDA)中,直接从源域适应到目标域通常会出现明显的差异并导致不充分的对齐。因此,许多UDA工作试图通过各种中间空间逐渐柔和地消除领域差距,即所谓的领域桥接(DB)。然而,对于密集的预测任务,如领域适应性语义分割(DASS),现有的解决方案大多依赖于粗糙的风格转移,如何优雅地桥接领域仍未得到充分的探索。在这项工作中,我们借助于数据混合,为DASS建立了一个深思熟虑的领域桥接(DDB),通过它,源域和目标域的联合分布在中间空间被对齐并相互作用。DDB的核心是一个双路径领域桥接步骤,使用粗略和精细的数据混合技术生成两个中间域,同时还有一个跨路径知识蒸馏步骤,将在生成的中间样本上训练的两个互补模型作为 “教师”,以多教师蒸馏的方式培养一个优秀的 “学生”。这两个优化步骤以交替的方式工作并相互加强,从而产生了具有强大适应能力的DDB。对不同设置的自适应分割任务进行的广泛实验表明,我们的DDB明显优于最先进的方法。代码可在 https://github.com/xiaoachen98/DDB.git 查看。
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。
