YOLOv5代码解析(二)
requirements.txt下载安装库
pip install -r requirements.txt
# pip install -r requirements.txt
# base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow
PyYAML>=5.3.1
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
# logging -------------------------------------
tensorboard>=2.4.1
# wandb
# plotting ------------------------------------
seaborn>=0.11.0
pandas
# export --------------------------------------
# coremltools>=4.1
# onnx>=1.8.1
# scikit-learn==0.19.2 # for coreml quantization
# extras --------------------------------------
thop # FLOPS computation
pycocotools>=2.0 # COCO mAPdetect.py这是运行yolov5模型的目标检测代码:
看一些核心代码:
if __name__ == '__main__':
parser = argparse.ArgumentParser()
#训练好的模型yolov5s.pt,可以可以从网络下载yolov5m.pt
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')
#网络的一个输入,检测图片和视频,检测视频的时候直接写个图片地址就好
# parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--source', type=str, default='data/video/牛车水拥有错综复杂的狭窄街道.mp4', help='source') # file/folder, 0 for webcam
#图片默认是在640上进行训练
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
#置信度区间,只有一个物体概率大于0.25的时候,我才确定他是一个物体
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
#iou就是(俩个图片的交集/俩个图片的并集),达到一个阈值,就选择这个框,设置0表示框和框之间没有交集产生
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
#自己去检测设备,默认
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
# 命令行指定参数python detect.py --view-img,就会变为true,结束运行直接展示结果,实时的看到检测效果
parser.add_argument('--view-img', action='store_true', help='display results')
#保存标签结果
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
#保存置信度
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
#不要保存图片和视频
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
#保存和展示指定结果,--class 0 2 3 需要展示的class一下,不需要的,不要写
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
#增强的MNS,设置之后NMS会更加的强大
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
#去掉网络参数,只保留预测模型
parser.add_argument('--update', action='store_true', help='update all models')
#结果保存什么位置
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
#保存文件的问价夹名字
parser.add_argument('--name', default='exp', help='save results to project/name')
#如果设置true,识别结果都不保存在一个文件夹下
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()
print(opt)
check_requirements(exclude=('pycocotools', 'thop'))
with torch.no_grad():
if opt.update: # update all models (to fix SourceChangeWarning)
for opt.weights in ['yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt']:
detect()
strip_optimizer(opt.weights)
else:
detect()
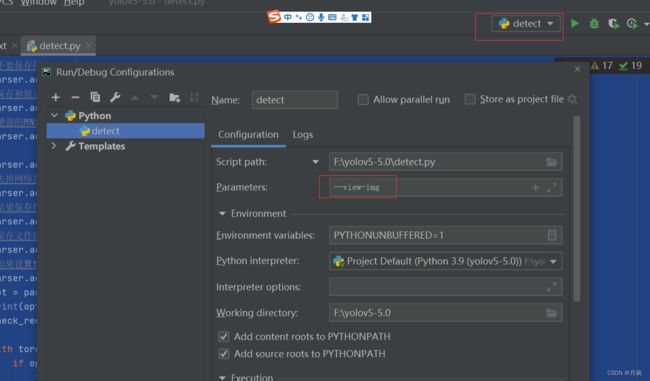
如果要默认运行这些代码可以在pycharm设置:--view -img表示可以查看训练过程的图片和视频
train.py这是训练模型的代码:
if __name__ == '__main__':
parser = argparse.ArgumentParser()
#训练好的模型yolov5s.pt作为训练模型参数的初始化(5s,5m,5l,5x)
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
#训练好的模型结构存放在model下yolov5s.yaml(小模型)yolov5m.yaml(中性)yolov5l.yaml(大模型)yolov5x.yaml(超大)
#仿照那个模型进行训练
# parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
#指定训练数据集(哪里下载,下载到哪里)
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')
#超参数列表
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
#训练多少轮
parser.add_argument('--epochs', type=int, default=300)
#多少数据会组成一个批次batch默认是16个数据是一批次
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')
#设置训练集,测试集的大小
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
#训练图片选择一个正方形
parser.add_argument('--rect', action='store_true', help='rectangular training')
#是否在最近训练的模型基础上进行训练
# parser.add_argument('--resume', nargs='?', const=True, default="填写已经训练过模型存储位置", help='resume most recent training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
#设置为true只保存训练最后一次的模型的参数
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
#设置为true在最后一轮的训练模型上进行测试
parser.add_argument('--notest', action='store_true', help='only test final epoch')
#锚点和锚框
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
#参数净化,寻找最优参数,默认没开启
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
#做着把一些东西放到google云盘上了,现在没必要了
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
#是否进行缓存图片进行更快的训练
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
#那些图片在测试过程中效果不是太好,在下一次训练的时候加一些权重
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
#设备检索
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
#图片尺寸进行变换
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
#训练的数据集是单类别还是多类别
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
#优化函数选择,true选择adam,false默认梯度下降
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
#如果有多个显卡,可以采用ddp分布式训练
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
#ddp的参数,不要随意修改
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
#运行的进程数,建议设置成0,设置比较大,会存在很多问题
# parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--workers', type=int, default=0, help='maximum number of dataloader workers')
#保存训练数据集
parser.add_argument('--project', default='runs/train', help='save to project/name')
#W&B库
parser.add_argument('--entity', default=None, help='W&B entity')
#保存文件名
parser.add_argument('--name', default='exp', help='save to project/name')
#设置了就会只保存到exp里面,不设置会出现exp1,exp2,exp3。。。。。
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
#数据加载dataloader yolov4的一个新功能
parser.add_argument('--quad', action='store_true', help='quad dataloader')
#学习率设置
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
#标签平滑,防止过拟合
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
#上传数据集
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
#
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
#没装W&B设置成-1
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
#无用参数
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
opt = parser.parse_args()以上俩个代码设置好之后都可以直接运行代码
yolov5的模型介绍:4个模型
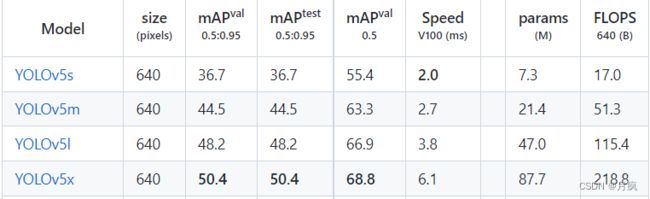
yolov5s、 yolov5m、yolov5l 、 yolov5x(分别是训练2、4、6、8天对应的模型)
下面是我对一个视频文件的目标检测:下载视频放到默认目录下