ElasticSearch入门学习
ElasticSearch
分布式全文搜索引擎
6.X和7.X区别特别大
1、入门
大数据需要解决的两个问题:存储、计算
Google和Hadoop技术对比
| Hadoop | |
|---|---|
| GFS | HDFS |
| MapReduce | MapReduce |
| BidTable | HBase |
回归主题
Lucene是一套信息检索工具包,是jar包
不包含搜索引擎系统!
包含以下功能:
- 索引结构
- 读写索引的工具
- 排序
- 搜索规则
Lucene和ES的关系
ES是基于Lucene的,在Lucene上做了一些封装和增强
1.1、ES概述
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
Elasticsearch、Logstash、Kibana
1.2、ES和Solr对比及选型
功能:全文搜索、结构化搜索、分析
ES和Solr对比
- 单纯对已有的数据,Solr的速度快
- 简历索引时,Solr会产生I/O阻塞
- 数据量增加,Solr效率变低
- Solr使用Zookeeper进行分布式管理,ES自带分布式协调管理工具
- Solr支持JSON、XML、CSV,ES只支持JSON
- Solr比较成熟,ES相对开发维护着较少,更新快,学习使用成本高
1.3、ES安装和head插件安装
官网下载:https://www.elastic.co/start
目录结构
bin # 启动文件
config # 配置文件
-log4j2.properties
-jvm.options
-elasticsearch.yml
默认9200端口
jdk # 环境
lib # 相关jar包
logs # 日志
modules # 功能模块
plugins # 插件
修改jvm.options文件的内存参数
-Xms256m
-Xmx256m
启动elasticsearch.bat文件,默认访问9200端口,通信端口9300
访问127.0.0.1:9200得到json字符串
{
"name" : "DESKTOP-HQU412E",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "ct067Y-dRqejNoOwIvqDog",
"version" : {
"number" : "7.6.2",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date" : "2020-03-26T06:34:37.794943Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
ES8.x
问题
- 配置文件配置内存参数换地方了
- 需要在jvm.options.d中新建一个xxx.options来配置内存参数
- 需要使用https进行访问,且第一次启动时,自动生成elastic用户的密码
elastic-head插件
环境需求:需要npm、node.js和python2
初始化并启动elastic-head
cd elasticsearch-head-master
npm install
npm run start
启动后访问9100端口,要连接elasticsearch,必须解决跨域问题(跨端口、跨IP、跨网站)
配置跨域
配置elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
重启elasticsearch.bat,9100上连接

将elastic-head当作可视化工具,不要用它来查询,后续使用Kibana来做
1.4、Kibana安装
了解ELK
Elasticsearch、Logstash、Kibana
收集清洗数据 => 分析 => 数据展示
一般提到ELK,就是日志分析架构技术栈总称
下载
官网下载压缩包后解压
注意:Elasticsearch和Kibana必须一致!
启动
点击bin\kibana.bat启动服务
默认端口5601
选择测试工具
使用Kibana测试工具
汉化Kibana
config\kibana.yml下配置国际化,然后重启服务器
#i18n.locale: "en"
i18n.locale: "zh-CN"
1.5、ES核心概念
Elasticsearch面向文档,关系型数据库和ES可以进行客观地对比
| RDB | Elasticsearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types |
| 行(rows) | documents |
| 字段(columns) | fields |
Elasticsearch中一切都是JSON
索引 > 类型 > 文档
Elasticsearch集群分布
Elasticsearch-head中新建索引默认分片是5
分片即每个碎片分布在不同的集群中

倒排索引
Lucene底层采用的就是倒排索引,这种结构适用于快速的全文搜索
| trem | doc_1 | doc_2 |
|---|---|---|
| to | √ | × |
| forever | √ | √ |
| total | 2 | 1 |
例如博客文章
| 博客文章(原始数据) | 索引列表(倒排索引) | ||
| 博客文章ID | 标签 | 标签 | 博客文章ID |
| 1 | python | python | 1,2,3 |
| 2 | python | linux | 3,4 |
| 3 | linux,python | ||
| 4 | linux | ||
一个Elasticsearch索引是多个Lucene索引组成的
1.6、IK分词器
什么是IK分词器?
即把一段中文划分成一个个的关键字,IK分词器是一个插件
分词算法
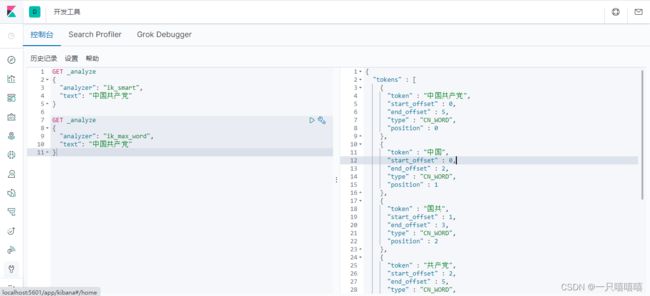
IK提供了两个分词算法
- ik_smart:最少切分
- ik_max_word:最细粒度切分
GitHub下载地址:https://github.com/medcl/elasticsearch-analysis-ik
使用步骤
-
什么版本的ES就下载什么版本的ik
-
下载的压缩包有两种类型,一种未打包的源代码,一种打包好的
-
以下情况为未打包的源代码
- 下载后解压,并执行maven命令打包
mvn clean package - 打包好后进入目录target\releases下,解压里面的压缩包到ES的plugins文件夹下
- 下载后解压,并执行maven命令打包
-
重启ES
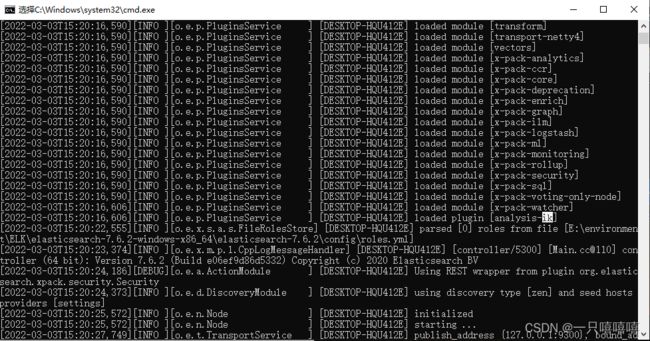
可以使用命令行确认是否载入插件
E:\environment\ELK\elasticsearch-7.6.2\bin>elasticsearch-plugin list
future versions of Elasticsearch will require Java 11; your Java version from [E:\environment\java\JDK\jre] does not meet this requirement
ik
测试使用
配置自定义扩展字典
ik/config/目录下新建自己的字典文件
hu.dic
狂神说
IKAnalyzer.cfg.xml
<properties>
<comment>IK Analyzer 扩展配置comment>
<entry key="ext_dict">hu.dicentry>
<entry key="ext_stopwords">entry>
properties>
重启ES测试
1.7、Rest风格操作索引
关于索引的基础操作
使用Kibana创建索引
PUT /索引名/类型名/文档id
{
请求体
}
例如
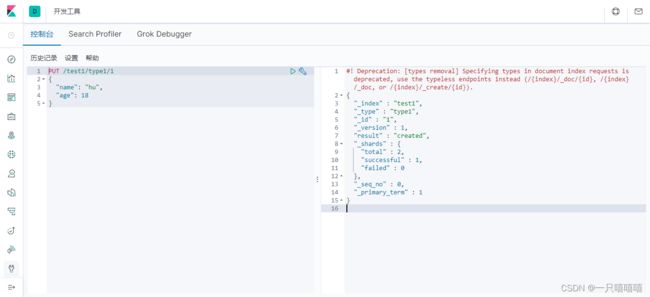
PUT /test1/type1/1
{
"name": "hu",
"age": 18
}
1.7.1、创建索引
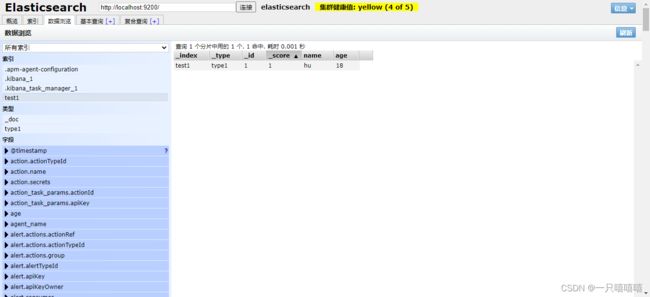
1.7.2、查看索引
数据类型
- 字符串
- text:可以被分词
- keyword:不可分词
- 数值
- byte
- short
- integer
- long
- float
- half float
- scaled float
- 日期
- date
- te布尔值
- boolean
- 二级制
- binary
- …
指定字段的类型
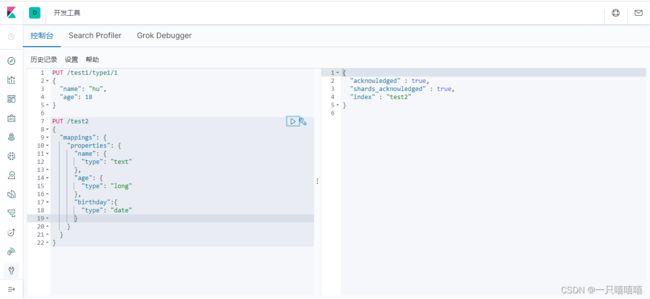
创建索引并设置规则
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
},
"birthday":{
"type": "date"
}
}
}
}
执行
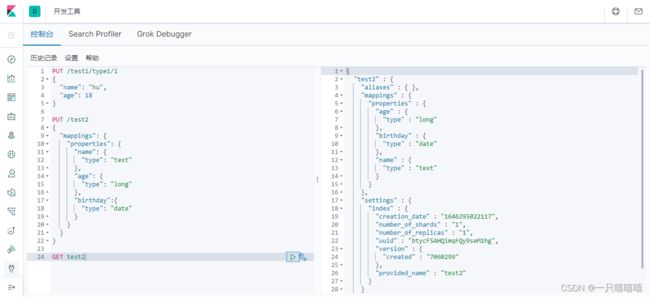
获得规则
GET test2
其他命令
GET _cat/health # 获取ES健康状态
GET _cat/indices?v # 查看索引信息
1.7.3、修改索引
# 以前的方法
PUT /test1/type1/1
{
"name": "hu123",
"age": 18123
}
# 现在的方法
POST /test1/type1/1/_update
{
"doc": {
"name": "hu123",
}
}
修改索引后,版本version会增加,result变为update
1.7.4、删除索引
DELETE test2/_doc/1
{
"acknowledged" : true
}
注意
- 若不写文档类型,则必须使用POST
- restful风格不允许url为驼峰
1.8、回顾上节
添加数据
PUT /user_list/user/1
{
"name": "hu",
"age": 18,
"desc": "一顿操作猛如虎",
"tags": ["技术宅","暖"]
}
PUT /user_list/user/2
{
"name": "张三",
"age": 23,
"desc": "法外狂徒",
"tags": ["打人","狠"]
}
PUT /user_list/user/3
{
"name": "李四",
"age": 19,
"desc": "无",
"tags": ["唱","跳","rap"]
}
查询数据
GET user_list/user/3 # 简单查询
GET user_list/user/_search?q=name:hu # 条件查询
修改数据
POST /user_list/user/3/_update
{
"doc": {
"name": "李四233",
}
}
1.9、花式查询
文档复杂查询——构建查询方式
1、模糊查询文档匹配所有的数据
GET user_list/user/_search
{
"query": {
"match": { # match匹配条件
"name": "李"
}
}
}

注意:中文可以分词,模糊检索,拼音不会分词
hits:对应Java中的对象Hits
score:权重
source:数据
2、模糊查找documents的部分fields
GET user_list/user/_search
{
"query": {
"match": {
"name": "李"
}
},
"_source": [
"name",
"desc"
]
}
3、排序
"sort": [
{
"age": {
"order": "desc"
}
}
]
4、分页
从第0条数据开始,一页显示2条数据
GET user_list/user/_search
{
"query": {
"match": {
"name": "李"
}
},
"_source": [
"name",
"desc"
],
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 2
}
5、布尔查询
多条件精确查询
GET user_list/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "hu"
}
},
{
"match": {
"age": "18"
}
}
]
}
}
}
- must:所有的条件都要符合
- must_not:所有条件都不符合
- should:或,满足一个即可
6、过滤器
GET user_list/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "hu"
}
}
],
"filter": { # 过滤
"range": {
"age": { # field
"gte": 3, # 大于等于
"lte": 18 # 小于等于
}
}
}
}
}
}
7、多条件匹配
模糊查询
满足其中一个条件即可被查询出
GET user_list/user/_search
{
"query": {
"match": {
"tags": "唱 rap 跳"
}
}
}
精确查询
term使用倒排索引精确查询
关于分词
- term直接精确查询
- match会使用分词器解析
GET user_list/user/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"age": {
"value": "18"
}
}
},
{
"term": {
"age": {
"value": "23"
}
}
}
]
}
}
}
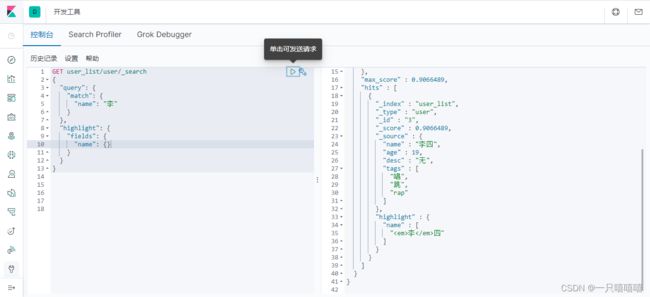
8、高亮查询
GET user_list/user/_search
{
"query": {
"match": {
"name": "李"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
自动增加html标签高亮显示
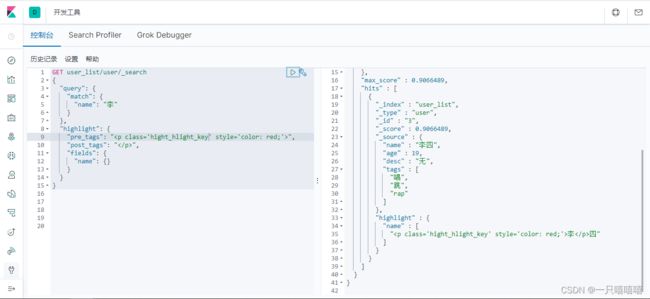
自定义标签样式
GET user_list/user/_search
{
"query": {
"match": {
"name": "李"
}
},
"highlight": {
"pre_tags": ""
,
"post_tags": "",
"fields": {
"name": {}
}
}
}
2、进阶
2.1、SpringBoot集成ES
- 查看官方文档:https://www.elastic.co/guide/index.html
- 找到客户端Clients链接
- 推荐使用Java REST Client
- 选择高级客户端(新版本的全都只有高级客户端)
原生maven依赖
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
<version>7.6.2version>
dependency>
SpringBoot依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
初始化

RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http"),
new HttpHost("localhost", 9201, "http")));
client.close();
配置基本的项目
-
新建SpringBoot项目,并添加ES依赖
-
一定要保证SpringBoot下的依赖和ES版本一致,这边使用的是7.6.2
-
修改默认版本
<properties> <java.version>1.8java.version> <elasticsearch.version>7.6.2elasticsearch.version> properties> -
创建ES配置类,注入bean
package com.kuangshen.elaticsearch.config; import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class ElasticSearchClientConfig { @Bean public RestHighLevelClient restHighLevelClient(){ RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost("localhost", 9200, "http") )); return client; } }
2.2、索引API操作

创建空索引
@Test
void createIndexTest() throws IOException {
// 创建索引请求
CreateIndexRequest request = new CreateIndexRequest("text_index");
// 获得请求响应体
CreateIndexResponse response = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
System.out.println(response);
}
判断索引是否存在
@Test
void existsIndexTest() throws IOException {
GetIndexRequest request = new GetIndexRequest("text_index");
boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
删除索引
@Test
void deleteIndexTest() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("text_index");
AcknowledgedResponse response = restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
}
2.3、文档API操作
创建实体类
package com.kuangshen.elaticsearch.dto;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.stereotype.Component;
@Data
@NoArgsConstructor
@AllArgsConstructor
@Component
public class User {
private String name;
private int age;
}
创建文档
@Test
void createDocumentTest() throws IOException {
User user = new User("xiaoming", 3);
// 请求索引
IndexRequest request = new IndexRequest("text_index");
// 文档id
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
// 文档内容
request.source(JSON.toJSONString(user), XContentType.JSON);
// 客户端发送请求
IndexResponse indexResponse = restHighLevelClient.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.status());
System.out.println(indexResponse.toString());
}
判断文档是否存在
@Test
void existsDocumentTest() throws IOException {
GetRequest request = new GetRequest("text_index","1");
// 不获取_source上下文,判断效率更高
request.fetchSourceContext(new FetchSourceContext(false));
// 设置字段
request.storedFields("_none_");
boolean exists = restHighLevelClient.exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
获取文档的信息
@Test
void getDocumentTest() throws IOException {
GetRequest request = new GetRequest("text_index", "1");
restHighLevelClient.exists(request, RequestOptions.DEFAULT);
GetResponse response = restHighLevelClient.get(request, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());
System.out.println(response);
}
结果
{"age":3,"name":"xiaoming"}
{"_index":"text_index","_type":"_doc","_id":"1","_version":1,"_seq_no":0,"_primary_term":1,"found":true,"_source":{"age":3,"name":"xiaoming"}}
修改文档信息
@Test
void updateDocumentTest() throws IOException{
UpdateRequest request = new UpdateRequest("text_index", "1");
request.timeout("1s");
request.doc(JSON.toJSONString(new User("xiaohong",3)),XContentType.JSON);
UpdateResponse response = restHighLevelClient.update(request, RequestOptions.DEFAULT);
System.out.println(response.toString());
}
删除文档
@Test
void deleteDocumentTest() throws IOException {
DeleteRequest request = new DeleteRequest("test_index", "1");
request.timeout("1s");
DeleteResponse response = restHighLevelClient.delete(request, RequestOptions.DEFAULT);
System.out.println(response.status());
}
插入多条数据
@Test
void batchInsertDocumentTest() throws IOException {
BulkRequest request = new BulkRequest();
request.timeout(ElasticSearchConstants.TIME_OUT);
ArrayList<User> userList = new ArrayList<>();
userList.add(new User("小红", 3));
userList.add(new User("小明", 35));
userList.add(new User("小刚", 23));
userList.add(new User("小芳", 18));
userList.add(new User("小键", 50));
userList.forEach((user) -> {
request.add(new IndexRequest(ElasticSearchConstants.ES_INDEX).source(JSON.toJSONString(user), XContentType.JSON));
});
BulkResponse responses = restHighLevelClient.bulk(request, RequestOptions.DEFAULT);
System.out.println(!responses.hasFailures() ? responses.toString() : null);
}
复杂查询
@Test
void searchDocumentTest() throws IOException {
SearchRequest request = new SearchRequest(ElasticSearchConstants.ES_INDEX);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.timeout(new TimeValue(1, TimeUnit.SECONDS));
sourceBuilder.query(QueryBuilders.termQuery("name", "小红"));
/*sourceBuilder.from();
sourceBuilder.size();
sourceBuilder.highlighter();*/
request.source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
JSON.toJSONString(response.getHits());
System.out.println("===============循环遍历===============");
for (SearchHit hit : response.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
3、实战
京东搜索
项目搭建
新建一个SpringBoot项目
导入依赖
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.6.4version>
<relativePath/>
parent>
<groupId>com.kuangshengroupId>
<artifactId>elasticsearchartifactId>
<version>0.0.1-SNAPSHOTversion>
<name>elasticsearchname>
<description>仿京东搜索description>
<properties>
<java.version>1.8java.version>
<elasticsearch.version>7.6.2elasticsearch.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-thymeleafartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.62version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
exclude>
excludes>
configuration>
plugin>
plugins>
build>
project>
配置文件
server.port=9090
spring.thymeleaf.cache=false
测试项目启动
爬取数据
数据哪里来?
- 数据库获取
- 消息队列中获取
- 爬虫
爬取数据:获取请求返回的页面信息,筛选出我们想要的数据
导入jsoup,可以解析网页,不能解析视频,tiki包可以
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.10.2version>
dependency>
创建工具类测试
public static void main(String[] args) throws IOException {
String url = "https://search.jd.com/Search?keyword=java";
// 返回js页面对象,可以调用js的所有方法
Document document = Jsoup.parse(new URL(url), 30000);
document.getElementById("J_goodsList")
.getElementsByTag("li")
.forEach((element) -> {
// 关于图片多的网站,所有的图片都是延迟加载的
String image = element.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = element.getElementsByClass("p-price").eq(0).text();
String title = element.getElementsByClass("p-name").eq(0).text();
System.out.println(image + "\t" + price + "\t" + title);
System.out.println("========================================");
});
}
爬取成功,进行项目准备工作
配置类
package com.kuangshen.elasticsearch.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")
));
return client;
}
}
创建实体类
package com.kuangshen.elasticsearch.dto;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.stereotype.Component;
@Data
@NoArgsConstructor
@AllArgsConstructor
@Component
public class Content {
private String title;
private String price;
private String img;
}
创建工具类方法
package com.kuangshen.elasticsearch.utils;
import com.kuangshen.elasticsearch.dto.Content;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
@Component
public class HtmlParseUtil {
public List<Content> parseJD(String keyword) throws IOException {
String url = "https://search.jd.com/Search?keyword=" + keyword;
Document document = Jsoup.parse(new URL(url), 30000);
ArrayList<Content> goodList = new ArrayList<>();
document.getElementById("J_goodsList")
.getElementsByTag("li")
.forEach((element) -> {
// 关于图片多的网站,所有的图片都是延迟加载的
String image = element.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = element.getElementsByClass("p-price").eq(0).text();
String title = element.getElementsByClass("p-name").eq(0).text();
goodList.add(new Content(title,price,image));
});
return goodList;
}
}
业务编写
Service层
package com.kuangshen.elasticsearch.service;
import com.alibaba.fastjson.JSON;
import com.kuangshen.elasticsearch.dto.Content;
import com.kuangshen.elasticsearch.utils.HtmlParseUtil;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
@Service
public class ContentServiceImpl {
@Autowired
private HtmlParseUtil htmlParseUtil;
@Autowired
private RestHighLevelClient restHighLevelClient;
public boolean parseContent(String keyword) throws IOException {
List<Content> contents = htmlParseUtil.parsejd(keyword);
BulkRequest request = new BulkRequest();
request.timeout("2m");
contents.forEach((content) -> {
request.add(new IndexRequest("jd_good").source(JSON.toJSONString(content), XContentType.JSON));
});
BulkResponse response = restHighLevelClient.bulk(request, RequestOptions.DEFAULT);
return !response.isFragment();
}
public List<Map<String, Object>> searchPage(String keyword, int page, int size) throws IOException {
if (page < 1){
page = 1;
}
SearchRequest request = new SearchRequest("jd_good");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
sourceBuilder.query(QueryBuilders.termQuery("title",keyword));
sourceBuilder.from(page);
sourceBuilder.size(size);
request.source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
ArrayList<Map<String, Object>> list = new ArrayList<>();
for (SearchHit hit : response.getHits().getHits()) {
list.add(hit.getSourceAsMap());
}
return list;
}
}
Controller层
package com.kuangshen.elasticsearch.controller;
import com.kuangshen.elasticsearch.service.ContentServiceImpl;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
import java.util.List;
import java.util.Map;
@RestController
public class ContentController {
@Autowired
ContentServiceImpl contentService;
@GetMapping("/parse/{keyword}")
public boolean parse(@PathVariable String keyword) throws IOException {
return contentService.parseContent(keyword);
}
@GetMapping("/search/{keyword}/{page}/{size}")
public List<Map<String, Object>> searchPage(@PathVariable String keyword,
@PathVariable int page,
@PathVariable int size) throws IOException {
return contentService.searchPage(keyword, page, size);
}
}
前后端交互
本地下载vue.js和axios.js并导入项目
npm init
npm install vue
npm install axios
导入html文件、css、images等静态文件
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8"/>
<title>狂神说Java-ES仿京东实战title>
<link rel="stylesheet" th:href="@{/css/style.css}"/>
head>
<body class="pg">
<div class="page" id="app">
<div id="mallPage" class=" mallist tmall- page-not-market ">
<div id="header" class=" header-list-app">
<div class="headerLayout">
<div class="headerCon ">
<h1 id="mallLogo">
<img th:src="@{/images/jdlogo.png}" alt="">
h1>
<div class="header-extra">
<div id="mallSearch" class="mall-search">
<form name="searchTop" class="mallSearch-form clearfix">
<fieldset>
<legend>天猫搜索legend>
<div class="mallSearch-input clearfix">
<div class="s-combobox" id="s-combobox-685">
<div class="s-combobox-input-wrap">
<input v-model="keyword" type="text"
autocomplete="off" value="dd" id="mq"
class="s-combobox-input"
aria-haspopup="true">
div>
div>
<button type="submit" id="searchbtn"
@click.prevent="search()">搜索
button>
div>
fieldset>
form>
<ul class="relKeyTop">
<li><a>狂神说Javaa>li>
<li><a>狂神说前端a>li>
<li><a>狂神说Linuxa>li>
<li><a>狂神说大数据a>li>
<li><a>狂神聊理财a>li>
ul>
div>
div>
div>
div>
div>
<div id="content">
<div class="main">
<form class="navAttrsForm">
<div class="attrs j_NavAttrs" style="display:block">
<div class="brandAttr j_nav_brand">
<div class="j_Brand attr">
<div class="attrKey">
品牌
div>
<div class="attrValues">
<ul class="av-collapse row-2">
<li><a href="#"> 狂神说 a>li>
<li><a href="#"> Java a>li>
ul>
div>
div>
div>
div>
form>
<div class="filter clearfix">
<a class="fSort fSort-cur">综合<i class="f-ico-arrow-d">i>a>
<a class="fSort">人气<i class="f-ico-arrow-d">i>a>
<a class="fSort">新品<i class="f-ico-arrow-d">i>a>
<a class="fSort">销量<i class="f-ico-arrow-d">i>a>
<a class="fSort">价格<i class="f-ico-triangle-mt">i><i
class="f-ico-triangle-mb">i>a>
div>
<div class="view grid-nosku">
<div class="product" v-for="result in results">
<div class="product-iWrap">
<div class="productImg-wrap">
<a class="productImg">
<img :src="result.img">
a>
div>
<p class="productPrice">
<em>{{result.price}}em>
p>
<p class="productTitle">
<a v-html="result.title">a>
p>
<div class="productShop">
<span>店铺: 狂神说Java span>
div>
<p class="productStatus">
<span>月成交<em>999笔em>span>
<span>评价 <a>3a>span>
p>
div>
div>
div>
div>
div>
div>
div>
<script th:src="@{/js/vue.js}">script>
<script th:src="@{/js/axios.js}">script>
<script>
let vm = new Vue({
el: '#app',
data: {
keyword: '',
results: [],
},
methods: {
search() {
let keyword = this.keyword;
axios.get('/parse/' + keyword);
axios.get('search/highlight/' + keyword + '/1/10').then((re) => {
this.results = re.data;
// console.log(this.results)
});
}
}
})
script>
body>
html>
关键字高亮
public List<Map<String, Object>> searchPageHighlight(String keyword, int page, int size) throws IOException {
if (page < 1) {
page = 1;
}
SearchRequest request = new SearchRequest("jd_good");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
sourceBuilder.query(QueryBuilders.termQuery("title", keyword));
sourceBuilder.from(page);
sourceBuilder.size(size);
// 高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
// highlightBuilder.requireFieldMatch(false);
highlightBuilder.preTags("");
highlightBuilder.postTags("");
sourceBuilder.highlighter(highlightBuilder);
request.source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
ArrayList<Map<String, Object>> list = new ArrayList<>();
for (SearchHit hit : response.getHits().getHits()) {
// 解析高亮字段
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField title = highlightFields.get("title");
Map<String, Object> map = hit.getSourceAsMap();
if (title != null) {
StringBuilder highlightTitle = new StringBuilder();
for (Text fragment : title.getFragments()) {
highlightTitle.append(fragment);
}
map.put("title", highlightTitle.toString());
}
list.add(map);
}
return list;
}
<a v-html="result.title">a>
总结
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。
Elasticsearch只支持JSON格式,可以搭分布式集群,大数据下高性能,基于Lucene的倒排索引,查询效率很高
Service层优化
package com.kuangshen.elasticsearch.service;
import com.alibaba.fastjson.JSON;
import com.kuangshen.elasticsearch.dto.Content;
import com.kuangshen.elasticsearch.utils.HtmlParseUtil;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
@Service
public class ContentServiceImpl {
@Autowired
private HtmlParseUtil htmlParseUtil;
@Autowired
private RestHighLevelClient restHighLevelClient;
public boolean parseContent(String keyword) throws IOException {
List<Content> contents = htmlParseUtil.parsejd(keyword);
BulkRequest request = new BulkRequest();
request.timeout("2m");
contents.forEach((content) -> {
request.add(new IndexRequest("jd_good").source(JSON.toJSONString(content), XContentType.JSON));
});
BulkResponse response = restHighLevelClient.bulk(request, RequestOptions.DEFAULT);
return !response.isFragment();
}
public List<Map<String, Object>> searchPage(String keyword, int page, int size) throws IOException {
SearchRequest request = new SearchRequest("jd_good");
SearchSourceBuilder sourceBuilder = searchRequest(keyword, page, size);
request.source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
ArrayList<Map<String, Object>> list = new ArrayList<>();
for (SearchHit hit : response.getHits().getHits()) {
list.add(hit.getSourceAsMap());
}
return list;
}
public List<Map<String, Object>> searchPageHighlight(String keyword, int page, int size) throws IOException {
SearchRequest request = new SearchRequest("jd_good");
// 高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.requireFieldMatch(false);
highlightBuilder.preTags("");
highlightBuilder.postTags("");
SearchSourceBuilder sourceBuilder = searchRequest(keyword, page, size);
sourceBuilder.highlighter(highlightBuilder);
request.source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
ArrayList<Map<String, Object>> list = new ArrayList<>();
for (SearchHit hit : response.getHits().getHits()) {
// 解析高亮字段
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField title = highlightFields.get("title");
// 不高亮的结果
Map<String, Object> map = hit.getSourceAsMap();
if (title != null) {
// 这边使用StringBuilder不会出现使用+=的字符串串联
StringBuilder highlightTitle = new StringBuilder();
for (Text fragment : title.getFragments()) {
highlightTitle.append(fragment);
}
map.put("title", highlightTitle.toString());
}
list.add(map);
}
return list;
}
private SearchSourceBuilder searchRequest(String keyword, int page, int size){
if (page < 1) {
page = 1;
}
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 超时时间
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
// 精确查询
sourceBuilder.query(QueryBuilders.termQuery("title", keyword));
// 分页
sourceBuilder.from(page);
sourceBuilder.size(size);
return sourceBuilder;
}
}
本文是观看狂神说Java总结的,有兴趣的可以去B站看看他的视频,全部免费而且非常棒
B站链接:https://www.bilibili.com/video/BV17a4y1x7zq?p=20&spm_id_from=pageDriver