深度学习教程(1) | 深度学习概论(吴恩达·完整版)

- 作者:韩信子@ShowMeAI
- 教程地址:https://www.showmeai.tech/tutorials/35
- 本文地址:https://www.showmeai.tech/article-detail/212
- 声明:版权所有,转载请联系平台与作者并注明出处
- 收藏ShowMeAI查看更多精彩内容

本系列为吴恩达老师《深度学习专项课程(Deep Learning Specialization)》学习与总结整理所得,对应的课程视频可以在这里查看。
1.欢迎(Welcome)

深度学习改变了传统互联网业务,例如网络搜索和广告。但是深度学习同时也使得许多新产品和企业以很多方式帮助人们,从获得更好的健康关注。
深度学习在医疗(读取X光图像)、个性化教育、精准化农业、自动驾驶等等方面表现都有着不错的表现。
有很多人想要学习深度学习的这些工具,并应用它们来完成一些智能化应用,吴恩达老师的《深度学习专业课程》是一个非常好的资源和学习起点。

AI是新的生产力。大约在一百年前,我们社会的电气化改变了每个主要行业,从交通运输行业到制造业、医疗保健、通讯等方面,如今我们见到了AI明显的令人惊讶的能量,带来了同样巨大的转变。显然,AI的各个分支中,发展的最为迅速的就是深度学习。因此现在,深度学习是在科技世界中广受欢迎的一种技术。
以下为吴恩达老师深度学习系列课程,系列课程对应几门课程,它们主要内容和收益如下:

1.1 第一门课要点
专项课程中第1门课是神经网络和深度学习,内容主要是神经网络的基础知识,可以学习到:
- 如何建立神经网络(包含一个深度神经网络)
- 如何在数据上面训练他们
- 一个小案例:用一个深度神经网络进行辨认猫
对应的ShowMeAI总结文章为:
- 2.神经网络基础
- 3浅层神经网络
- 4.深层神经网络
1.2 第二门课要点
专项课程中第2门课是深度学习方面的实践,学习严密地构建神经网络,如何真正让它表现良好,可以学习到:
- 超参数调整
- 正则化技术
- 诊断偏差和方差
- 高级优化算法(如Momentum和Adam优化算法)
对应的ShowMeAI总结文章为:
- 5.深度学习的实用层面
- 6.神经网络优化算法
- 7.网络优化:超参数调优、正则化、批归一化和程序框架
1.3 第三门课要点
专项课程中第3门课是结构化机器学习工程,会涵盖构建机器学习系统的策略。可以学习到:
- 切分数据的方式(训练集、验证集,测试集)
- 实验与诊断方法
- 端对端深度学习
- 改善深度学习的一些方法
对应的ShowMeAI总结文章为:
- 8.AI应用实践策略(上)
- 9.AI应用实践策略(下)
1.4 第四门课要点
专项课程中第4门课是卷积神经网络,涵盖计算机视觉中最常用的神经网络结构CNN(s),可以学习到:
- 卷积神经网络结构
- 典型CNN模型
- 计算机视觉图像分类
- 计算机视觉目标检测
- 人脸识别
- 图像风格转换
对应的ShowMeAI总结文章为:
- 10.卷积神经网络解读
- 11.经典CNN网络实例详解
- 12.CNN应用:目标检测
- 13.CNN应用:人脸识别和神经风格转换
1.5 第五门课要点
专项课程中第5门课是序列建模,涵盖RNN神经网络及自然语言处理问题和解决方案。可以学习到:
- 序列建模
- RNN循环神经网络
- 词嵌入(word2vec、GloVe)
- 情感分析
- 注意力机制
- 机器翻译
对应的ShowMeAI总结文章为:
- 14.序列模型与RNN网络
- 15.自然语言处理与词嵌入
- 16.Seq2seq序列模型和注意力机制
2.什么是神经网络?(What is a Neural Network)

我们常常用深度学习这个术语来指训练神经网络的过程。有时它指的是特别大规模的神经网络训练。
2.1 房价预测案例
吴恩达老师的课程从一个房价预测的例子开始。
假设我们有一个数据集,它包含了六栋房子的信息(房屋面积和房屋价格)。我们想要拟合一个函数,根据房屋面积来预测房屋价格。
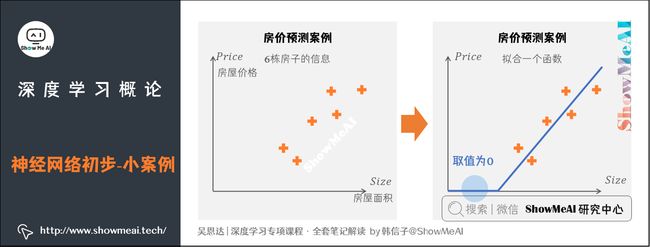
通过线性回归简单的实现方式是一条直线。因为价格永远不会是负数,因此我们调整一下直线,让它弯曲一点,最终在原点结束。这条粗的蓝线就是最终的函数,可以根据房屋面积预测价格。可以看到,函数的一部分取值为0,而另一部分的直线对数据的拟合效果很好。
2.2 ReLU激活函数
我们把房屋面积(Size)作为输入( x x x),通过一个节点(一个小圆圈)最终输出了房屋价格(Price, y y y)。这个小圆圈实现了上面的折线表达式,视作一个单独的神经元(neuron),这就是最简单的神经网络。
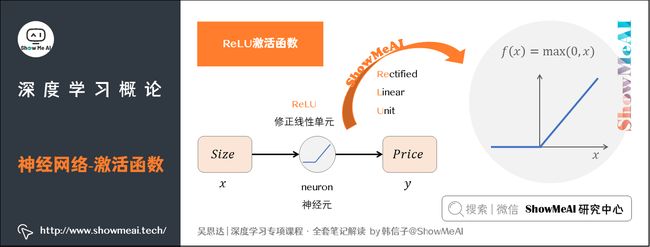
这个折线表达式就被称作ReLU激活函数,全称为Rectified Linear Unit(修正线性单元),其中rectify(修正)可以理解成 f ( x ) = m a x ( 0 , x ) f(x) = max(0,x) f(x)=max(0,x)。在后续的神经网络教程中,大家会频繁地看到这个函数。
上图所示为最简单的神经网络,更复杂的网络可以通过这个结构堆叠得到。你可以把这些神经元想象成单独的乐高积木,通过「搭积木」的方式可以完成一个更复杂的神经网络。
2.3 房价预测案例 <更多特征>
假如问题更复杂一些,我们有房子的更多信息:
- 房屋面积(Size)
- 卧室数量(#Bedrooms)
- 邮政编码(Zip Code)
- 周边富裕程度(Wealth)
那么问题升级为下图所示的情况:
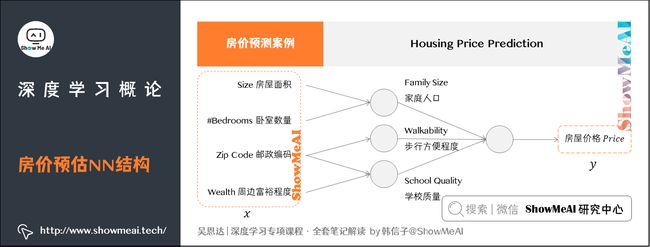
图上每一个小圆圈都可以是ReLU的一部分,也就是修正线性单元,或者其它非线性的函数。
- 基于房屋面积和卧室数量,可以估算家庭人口(Family Size)。
- 基于邮编,可以估测步行方便程度(Walkability)或者学校质量(School Quality)。
在这个情景里,家庭人口、步行方便程度以及学校质量都能帮助预测房屋价格。
我们把上图的神经元叠加在一起,就有了一个稍微大一点的神经网络。其中, x x x是4个特征输入(房屋大小、卧室数量、邮政编码和富裕程度), y y y是尝试预测的价格。
2.4 隐藏单元(Hidden Units)
我们注意到,这个网络中的隐藏单元(图示橙色的小圆圈),每个都是从4个输入特征来获得自身的输入。
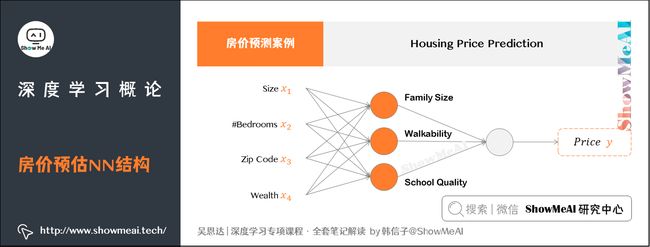
网络中第一个橙色结点代表家庭人口。注意,我们不会说这个结点取决于 x 1 x_1 x1和 x 2 x_2 x2,而是由神经网络自己决定这个结点是什么,是由4个输入进行计算得到的。
当我们给到足够多的 x x x和 y y y数据(也就是足够多的训练样本)时,神经网络可以精准地学习从 x x x到 y y y的映射函数。
3.用神经网络进行监督学习(Supervised Learning with Neural Networks)

上面的任务是典型的监督学习,我们的数据中包含特征 x x x和标签 y y y(详见 图解机器学习 | 机器学习基础知识)。房价预测的例子中, x x x是房屋特征, y y y是房屋价格。
同样的监督学习方法,借助于神经网络结构,已经被高效应用到很多场景,如下图所示:

3.1 应用

(1) Online Advertising 在线广告
如今应用深度学习获利最多的一个领域,就是在线广告。
神经网络非常擅长预测你是否会点开推荐的网页/视频广告,通过广告与用户信息建模,推荐最有可能点击的广告,进而给大型的在线广告公司带来丰厚的收入。
(2) Photo tagging 照片识别打标
得益于深度学习,计算机视觉在过去的几年里也取得了长足的进步。目前大家的相册照片,可以使用自动标注和智能识别的功能。
(3) Speech recognition 语音识别
深度学习最近在语音识别方面的进步也极其巨大,如今语音识别可以做到很好的一个效果程度,大家日常用的手机语音助手,都是它的典型应用。
(4) Machine translation 机器翻译
得益于深度学习,机器翻译也有很大的发展。如今大家可以轻松地借助于机器翻译,阅读不同语种的信息内容。
(5) Autonomous driving 无人驾驶
未来AI的一个极大应用场景就是自动驾驶技术,可以通过训练一个神经网络,来告诉汽车在马路上面具体的位置,进而帮助自动驾驶系统来判断和控制。
3.2 神经网络的类型
实际神经网络有着不同的结构,而这些典型的结构,也适用于不同的场景,例如:
(1) 对于房地产和在线广告来说,可能是相对标准一些的神经网络(比如全连接的前馈神经网络,或者wide&deep这种组合网络)。
(2) 对于图像应用,我们经常在神经网络上使用卷积(Convolutional Neural Network),通常缩写为CNN。
(3) 对于序列数据(例如音频和文本,含有时间成分),经常使用RNN,一种递归神经网络(Recurrent Neural Network)。
- 音频随时间播放,所以音频被表示为一维时间序列(one-dimensional time series,或称one-dimensional temporal sequence)
- 语言(英语的字母或汉语的汉字)都是逐个出现的,所以语言最自然的表达方式也是序列数据,通常此类问题会使用更复杂的RNNs结构。
(4) 对于更复杂的应用(比如自动驾驶),其中的图片任务可以使用CNN卷积神经网络结构。但是雷达信息却需要使用不同的网络结构,这些结构可能是定制的、复杂的或混合的神经网络结构。
3.3 结构图示
上面提到的典型的几类网络,结构示意图如下。
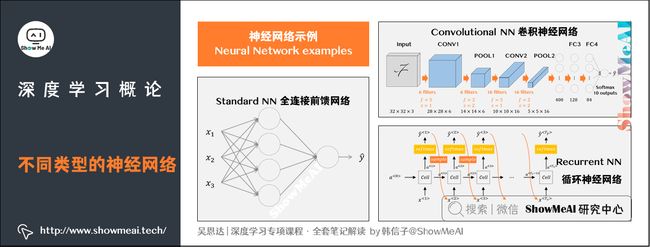
- 上图左:一个标准的神经网络
- 上图右上:一个卷积神经网络(CNN通常用于图像数据)
- 上图右下:循环神经网络(RNN通常用于序列数据)
3.4 结构化数据与非结构化数据
AI算法的有效应用,依赖于数据,我们先对数据做一个了解。首先数据可以分为结构化数据和非结构化数据。
(详见 机器学习实战 | Python机器学习算法应用实践 对于两类数据的不同建模处理方式和 机器学习实战 | 机器学习特征工程最全解读 中对于结构化和非结构化数据的区分处理)
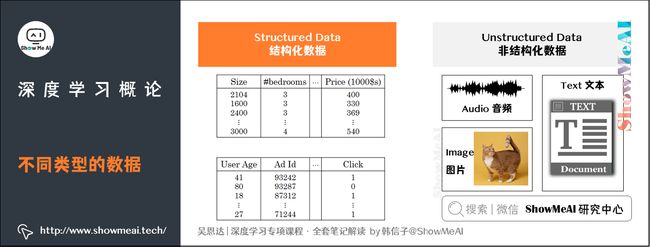
(1) 结构化数据
结构化数据通常指的是行列表格状的数据,一般存储在数据库中。
- 例如在房价预测中,数据库中存储的数据集,有专门的几列数据字段指代卧室的大小和数量,这就是结构化数据。
- 或预测用户是否会点击广告,你可能会得到关于用户的信息,比如年龄以及关于广告的一些信息,然后对你的预测分类标注。
这就是结构化数据,意思是每个特征(比如说房屋大小卧室数量,或者是一个用户的年龄)都有一个很好的定义。
(2) 非结构化数据
非结构化数据是指比如音频、图像或文本等数据内容。这里的原始特征可能是图像中的像素值或文本中的单个单词。
处理非结构化数据是相对较难的。传统的机器学习模型处理起来效果有限,而深度学习神经网络非常擅长做这个事情。计算机借助神经网络能更好地理解和解释非结构化数据。语音识别、图像识别、自然语言文字处理,这些领域的应用都有翻天覆地的提升。
4.为什么深度学习会兴起?(Why is Deep Learning taking off?)

推动深度学习变得如此热门的主要因素包括数据规模、计算能力及算法模型的创新。
4.1 为什么深度学习能够如此有效?
为什么深度学习能够如此有效呢?要回答这个问题,可以从数据量说起。如下图,横轴画一条直线,绘制出所有任务的数据量(Amount of Data);竖轴画出机器学习算法的性能(Performance),例如垃圾邮件过滤、广告点击预测、自动驾驶时位置判断等任务的准确率。

根据图像可以发现,一个传统机器学习算法的性能,作为数据量的函数,是一条曲线。如图中所示,一开始,算法性能会随着数据的增多而上升;但一段变化后,它的性能就会达到瓶颈而难以提升。过去十年,我们遇到的很多问题只有相对较少的数据量。但假设横轴拉得很长很长,算法将不知道如何处理规模巨大的数据。
数字化社会带来了巨大的数据量提升。相比于传统机器学习模型,深度学习神经网络更能在海量数据上发挥作用。下图展示的是不同的算法在不同数据规模下的表现:

- 如果你训练一个小型的神经网络(Small NN),那么这个性能可能会像黄色曲线表示那样。
- 如果你训练一个稍微大一点的神经网络,比如说一个中等规模的神经网络(Medium NN),它在某些数据上面的性能也会更好一些,如蓝色曲线。
- 如果你训练一个非常大的神经网络(Large NN),它就会变成绿色曲线那样,并且保持变得越来越好。
因此,想获得橙色点较好的性能体现,需要具备以下两个条件:
- 需要训练一个规模足够大的神经网络,以发挥数据规模巨大的优点
- 需要海量的数据支撑
我们经常说「规模驱动着深度学习的进步(Scale Drives Deep Learning Progress)」,这里的「规模」同时也指神经网络的规模——我们需要一个带有许多隐藏单元的神经网络,以及许多的参数及关联性。就如同需要大规模的数据一样。
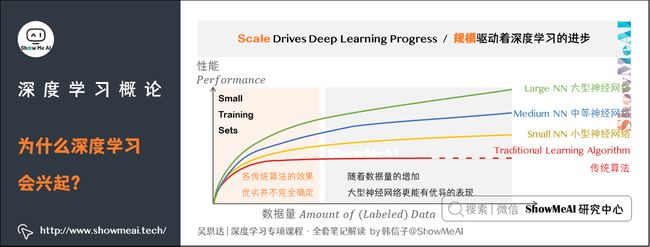
我们再回到上面这个图,在这个图形区域的左边(Small Training Sets),各种算法之间的效果优劣并不完全确定,最终的效果很多时候取决于工程构建特征的能力以及算法处理方面的一些细节(详见 机器学习实战 | 机器学习特征工程最全解读)。
而在上图的右边区域,我们可以看到随着数据量的增加,很多时候有着庞大参数的大型神经网络更能有优异的表现。
在深度学习萌芽的初期,数据的规模以及算力/计算量,局限在我们对于训练一个特别大的神经网络的能力,无论是在CPU还是GPU上面,那都使得我们取得了巨大的进步。但是渐渐地,尤其是在最近这几年,我们也见证了算法方面的极大创新。许多算法方面的创新,一直是在尝试着使得神经网络运行的更快。
4.2 sigmoid → ReLU
讲一个具体的例子,神经网络方面的一个巨大突破是从Sigmoid函数转换到ReLU函数。
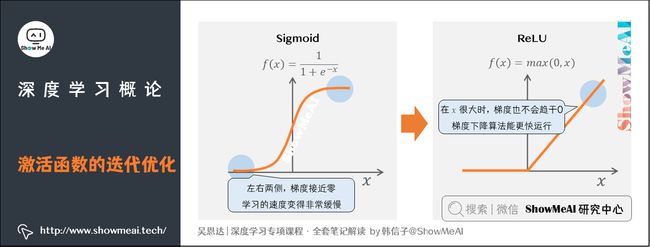
我们在过往的深度学习神经网络中,经常会使用Sigmoid函数,这个函数在左右两侧的位置梯度会接近零,所以学习的速度会变得非常缓慢,而通过改变这个被叫做激活函数的ReLU函数(修正线性单元)可以很大程度解决这个问题。
ReLU它的梯度对于所有输入的负值都是零,因此梯度更加不会趋向逐渐减少到零。能够使得我们训练神经网络的梯度下降(gradient descent)算法运行的更快。
这是一个简单的算法创新例子。但是根本上算法创新所带来的影响,实际上是对计算带来的优化。所以有很多像这样的例子,我们通过改变算法,使得代码运行的更快,这也使得我们能够训练规模更大的神经网络。
我们实际应用神经网络的过程,和下图比较一致:

- idea:凭借积累和直觉,对神经网络架构有新的想法。
- code:尝试写代码实现。
- experiment:在实验环境下测试它的效果,通过参考这个结果再返回去修改你的神经网络里面的一些细节。
我们不断的重复上述操作,往复循环直到得到好的效果的模型网络。
5.关于这门课(About this Course)

吴恩达老师的专项有五门课程,目前正处于第一门课,关于第一门课的一些细节如下:
- 第一周:关于深度学习的介绍。在每一周的结尾也会有十个多选题用来检验自己对材料的理解。
- 第二周:关于神经网络的编程知识,了解神经网络的结构,逐步完善算法并思考如何使得神经网络高效地实现。从第二周开始做一些编程训练(付费项目),自己实现算法。
- 第三周:在学习了神经网络编程的框架之后,你将可以编写一个隐藏层神经网络,所以需要学习所有必须的关键概念来实现神经网络的工作。
- 第四周:建立一个深层的神经网络。
ShowMeAI系列教程推荐
- 大厂技术实现:推荐与广告计算解决方案
- 大厂技术实现:计算机视觉解决方案
- 大厂技术实现:自然语言处理行业解决方案
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读
推荐文章
- ShowMeAI 深度学习教程(1) | 深度学习概论
- ShowMeAI 深度学习教程(2) | 神经网络基础
- ShowMeAI 深度学习教程(3) | 浅层神经网络
- ShowMeAI 深度学习教程(4) | 深层神经网络
- ShowMeAI 深度学习教程(5) | 深度学习的实用层面
- ShowMeAI 深度学习教程(6) | 神经网络优化算法
- ShowMeAI 深度学习教程(7) | 网络优化:超参数调优、正则化、批归一化和程序框架
- ShowMeAI 深度学习教程(8) | AI应用实践策略(上)
- ShowMeAI 深度学习教程(9) | AI应用实践策略(下)
- ShowMeAI 深度学习教程(10) | 卷积神经网络解读
- ShowMeAI 深度学习教程(11) | 经典CNN网络实例详解
- ShowMeAI 深度学习教程(12) | CNN应用:目标检测
- ShowMeAI 深度学习教程(13) | CNN应用:人脸识别和神经风格转换
- ShowMeAI 深度学习教程(14) | 序列模型与RNN网络
- ShowMeAI 深度学习教程(15) | 自然语言处理与词嵌入
- ShowMeAI 深度学习教程(16) | Seq2seq序列模型和注意力机制
