计算摄影——图像去噪(二)
这一章来整理下图像去噪相关的内容,主要包括:噪声类型,评估方法,传统去噪方法,深度学习去噪方法,常用数据集,这一章主要讲后两部分。前面的内容可以参考:计算摄影——图像去噪(一)_Turned_MZ的博客-CSDN博客
常用去噪数据集
目前去噪数据集的建立方法主要有3种:
- 从现有图像数据集获取高质量图像,然后做图像处理(线性变化、亮度调整等)并根据噪声模型添加人工合成的噪声,生成噪声图像。但是这种方法由于噪声是人工合成的,与真实场景中的噪声有差异,故在真实场景下效果欠佳。
- 针对同一图像,拍摄低感光度图像作为真值,高感光度图像作为噪声图像,并调整曝光参数来实两张图像亮度一致。这一类方法直接使用低感光度图像作为真值,难免会有噪声残留,并且与噪声图像也可能存在亮度差异和不对齐的问题。
- 对同一场景连续拍摄多张图像,然后通过图像配准等方式合成一张真值,这种方式需要拍摄大量图像,工作量比较大,但是最终得到的真值质量比较高。
常见数据集与对应论文:
| 数据集 | GT | 场景数量 | 图片对数 | 主要领域 | 说明 | 相关论文 |
|---|---|---|---|---|---|---|
| RENIOR | 低ISO | 120 | 240 | 低光 | 拍摄了120个暗光场景,包含室内和室外场景。每个场景约4张图像,包含2张有噪声图像和两张低噪图像。 |
RENOIR - A Dataset for Real Low-Light Image Noise Reduction |
| Nam-CC15 | 均值 | 11 | 17 | 物品 | 包含11个场景,且多是相似物体和纹理。针对这11个场景共拍摄了500张JPEG图像。 | A Holistic Approach to Cross-Channel Image Noise Modeling and its Application to Image Denoising |
| Nam-CC60 | 均值 | 11 | 60 | 物品 | - | - |
| DND | 低ISO | 50 | 50 | 室内外 | 拍摄50个场景,包括室内和室外场景。 | Benchmarking Denoising Algorithms with Real Photographs |
| PolyU | 均值 | 40 | 40 | 室内外 | 拍摄了40个场景,包括室内正常光照场景和暗光场景,室外正常光照场景。对每个场景连续拍摄了500次 | Real-world Noisy Image Denoising: A New Benchmark |
| SIDD | 均值 | 200 | 400 | 多领域 | 用5个相机(Google Pixel、iPhone 7、Samsung Galaxy S6 Edge、Motorola Nexus 6、LG G4)在四种相机参数下拍摄了10个场景,200个场景实例,每个场景连续拍摄了150张图像。其中160个场景实例作为训练集,40个场景实例作为测试集(the benchmark)。 | A High-Quality Denoising Dataset for Smartphone Cameras |
| High-ISO | 均值 | 28 | 110 | 高ISO | http://cwc.ucsd.edu/sites/cwc. | |
| NIND | 低ISO | 101 | 606 | 多级ISO | ||
| IOCI | 均值 | - | 200 | 多种相机 | https://arxiv.org/pdf/2011.0346 |
深度学习去噪方法
估计噪声残差
Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising
在信息处理领域中,学习信号的改变量往往比学习原始信号更加简单,这种思想被用于非常有效的残差网络。DnCNN模型则借鉴了该思路,它不是直接输出去噪图像,而是预测残差图像,即观察噪声图像和潜在的无噪声图像之间的差异。
CNN在VGG的基础上进行修改,网络结构是(卷积、BN、ReLU)级联的结构,模型内部并不像ResNet一样存在跳远连接,而是在网络的输出使用残差学习。结构如下:

该网络的特点主要有:
- 网络分为三部分,第一部分为Conv+Relu(一层),第二部分为Conv+BN+Relu(若干层),第三部分为Conv(一层),网络层数为17或者20层。
- 网络学习的是图像残差,也就是带噪图像和无噪图像差值,损失函数采用的MSE。
- 论文中强调了batch normalization的作用
噪声估计模型
Toward Convolutional Blind Denoising of Real Photographs
CBDNet模型是一个真实图像非盲去噪模型,对于RAW格式的图像,它的噪声模型如下:
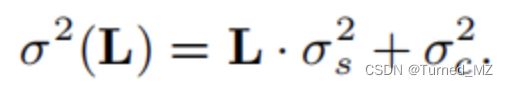 含真实噪声图像=图像信号L+真实噪声信号n(L)。CBDNet模型使用了一个噪声估计子网络估计出噪声水平,然后与原输入图像一起输入基于跳层连接的非盲去噪子网络,其结构如下:
含真实噪声图像=图像信号L+真实噪声信号n(L)。CBDNet模型使用了一个噪声估计子网络估计出噪声水平,然后与原输入图像一起输入基于跳层连接的非盲去噪子网络,其结构如下:
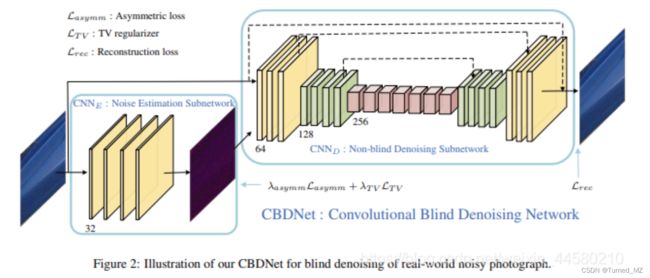
1、噪声估计子网络将噪声观测图像转换为估计的噪声水平图像,然后和原图一起输入,使用非盲去噪子网络得到最终的去噪结果,除此之外,噪声估计子网络允许用户在估计的噪声水平图像输入非盲去噪子网络之前对齐调整,其提出了一种简单的策略,即y = ay,即线性缩放,这给模型提供了一种交互式的去噪运算能力。
盲去噪是指在去噪过程中,用于去噪的基础是从有噪声的样本本身学习来的。换句话说,无论我们构建什么样的深度学习体系结构,都应该学习图像中的噪声分布并去噪。所以和往常一样,这都取决于我们提供给深度学习模型的数据类型。非盲去噪则相反。
2、噪声估计子网络损失函数:非对称损失函数( asymmetric loss)+全变差损失函数( total variation)
2.1、非对称损失函数,计算噪声估计图和噪声ground truth的平方差: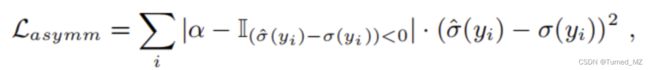
其中,  为惩罚值,当噪声估计图值小于噪声ground truth值的时候,惩罚值大,当噪声估计图值大于噪声ground truth值的时候,惩罚值小。(非对称)目的是避免低估噪声值。
为惩罚值,当噪声估计图值小于噪声ground truth值的时候,惩罚值大,当噪声估计图值大于噪声ground truth值的时候,惩罚值小。(非对称)目的是避免低估噪声值。
2.2、全变差损失函数,目的是限制噪声估计图的平滑度(梯度大小反映平滑程度):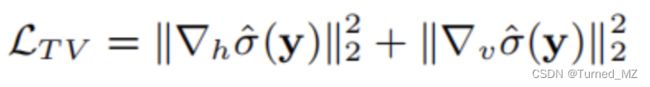 其中,
其中,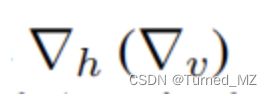 计算噪声估计图水平方向梯度(噪声估计图垂直方向梯度)
计算噪声估计图水平方向梯度(噪声估计图垂直方向梯度)
2.3、非盲降噪子网络损失函数:计算输出图像与输入图像像素级均方误差MSE:
网络的总损失函数为三部分乘上权重相加: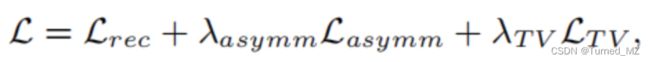
3、该算法学习的是更接近于真实噪声的高斯泊松噪声,而前面两篇论文都是学习高斯噪声;并且结合使用合成和真实噪声数据来训练模型,提高模型泛化能力,可以更好地对真实场景进行降噪;
RIDNet
Real Image Denoising with Feature Attention
RIDNet中,作者提出了一种新的修复模块,学习特征并进一步增强网络的功能。 作者团队通过关注通道之间的依赖关系来关注特征,以重新调整通道级的特征。 还使用LSC,SSC和SC来绕过低频信息,因此网络可以专注于残余学习。网络结构如下:
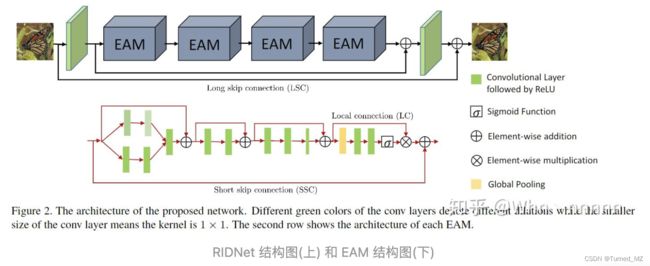
该网络的特点主要有:
1、这个网路的结构设计得相对复杂,主要包括三部分:特征提取、4个EMA组成的残差模型、重建。其中特征提取和重建模块都是卷积层+ReLU层。EMA的结构如上图中下半部分框图所示:
(1)首先是两个空洞卷积分支,用来增加感受野,然后进行拼接并进行卷积融合
(2)然后是两个类似残差学习的结构,用于进行特征的提取
(3)最后是注意力机制,主要由一系列1x1的卷积核构成,结构如下图所示:
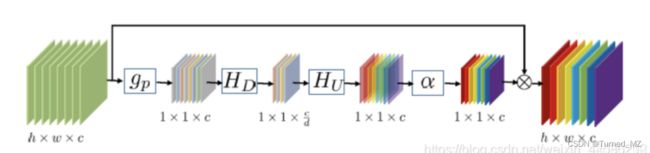
2、该网络的损失函数为L1损失函数:
PMRID
Practical Deep Raw Image Denoising on Mobile Devices
这篇论文是2020 CVPR上旷视提出来的一篇非常elegant的算法,该算法的特点网络结构比较小,通过一个k-sigma变换来解决小网络在不同增益噪声下的鲁棒性问题,网络结构如下图所示:

该论文提出了k-sigma变换,使用标定的k和sigma按照k-sigma公式变换后,原始的噪声分布就只和没有噪声的数据x ∗ 有关,因此就可以避免不同增益下噪声不同带来的负担。其具体原理可以参考:你手机中的夜景降噪算法-Raw域k-Sigma Transform - 知乎
基于GAN的模型
获取成对的噪声图像和无噪声图像是非常困难的,因此有研究者使用了生成对抗网络(GAN)来生成成对图像用于训练模型,首先,训练GAN网络,通过含噪声的图像去学习噪声分布并生成噪声样本,以此来模拟真实场景下的噪声图像,解决HR图像缺少对应LR的问题;其次,训练CNN网络,利用上一步采样的噪声块来构建成对的训练数据集,该数据集用于训练CNN来对给定的图像去噪。网络结构如下:

从噪声图像中估计
https://arxiv.org/pdf/1803.04189.pdf
既然噪声图像和无噪声图像很难获取,那么是否可以只使用噪声图像就可以训练出好的噪声模型呢?由此研究者们提出了Noise2Noise模型,其原理其实很简单:
本来我们做图像降噪,需要输入的噪音图像 x,和 “干净样本” y。例如,x 是路径跟踪渲染用少数光束渲染的图片,y 是长期渲染后的图片。那么如果用 y 作为训练目标,生成 y 是个非常费时费力的过程。但其实你如果仔细想想,可以用另一次快速渲染生成的另一个噪音图像(它相当于 y + 另一个不同的噪音)作为训练目标(所以叫Noise2Noise)。只要训练样本够多,最终也相当于用 y 作为训练目标。原因是简单的统计学原理。
参考链接
图像去噪数据集 - 知乎
图像降噪算法——DnCNN / FFDNet / CBDNet / RIDNet / PMRID / SID_Leo-Peng的博客-CSDN博客_dncnn
深度学习——CBD-Net_浮生若梦,为欢几何耶的博客-CSDN博客_cbdnet噪声水平图估计怎么实现
图像盲去噪|GAN|GCBD - 知乎
图像去噪之 Noise2Noise 和 Noise2Void_涑月听枫的博客-CSDN博客_noise2noise
书籍:《深度学习之摄影图像处理》