抢票系统之高可用(3)-存储高可用
抢票系统之高可用(3)-存储高可用
1.存储高可用之主从
1.1主备
冷备一天备份一次,主库不可用,使用备份,但是数据丢失严重,而且启动速度很慢,可以当作一种保底的方式。但是基本上不满足一线互联网公司的需求,
1.2主从
主从是实时同步的,恢复的时间非常快,当主节点出现问题的时候从节点可以快速的切换过来,主库从库都是在线运行的,都是支持业务的,只不过主库一般作为写库在用,从库是作为读库在用
当业务量从10W上升到100W之后,数据库的压力不断上升,可以增加节点提升读写的效率,一般的业务读的压力要远远大于写的比重,这样通过增加节点实现读写分离
主库的数据引擎进行数据更改操作之后,写入一个二进制文件,从库的的数据引擎创建了节点之后,创建一个IO线程,IO线程去读二进制文件,之后将更新的数据写入到数据库中。 原理和redis的同步形式一样(全量同步:所有数据都会同步,已经同步的会被覆盖,效率低下,增量同步:根据偏移量同步,只更新新增的)
数据库默认的日志就是(Binary Log),当MySQL引入Innodb有(Read Log)MQ,ZK等中间件都是使用的这套数据同步技术,通过建立链接同步数据,数据追平之后就可以切换
引入两个数据源,写和读分别调用不同的数据源

1.2主从—技术实践
步骤:
1.设置服务的唯一编号
2.开启binlog功能
1.2.1 binlog 的格式
binlog 有三种格式:
- Statement(Statement-Based Replication,SBR):每一条会修改数据的 SQL 都会记录在 binlog 中。
- Row(Row-Based Replication,RBR):不记录 SQL 语句上下文信息,仅保存哪条记录被修改。
- Mixed(Mixed-Based Replication,MBR):Statement 和 Row 的混合体。
Statement
Statement 模式只记录执行的 SQL,不需要记录每一行数据的变化,因此极大的减少了 binlog 的日志量,避免了大量的 IO 操作,提升了系统的性能。
但是,正是由于 Statement 模式只记录 SQL,而如果一些 SQL 中 包含了函数,那么可能会出现执行结果不一致的情况。比如说 uuid() 函数,每次执行的时候都会生成一个随机字符串,在 master 中记录了 uuid,当同步到 slave 之后,再次执行,就得到另外一个结果了。
所以使用 Statement 格式会出现一些数据一致性问题。
缺点:易出现数据的偏差,记录的是一个范围,
优点:记录的日志的量较少
Row
从 MySQL5.1.5 版本开始,binlog 引入了 Row 格式,Row 格式不记录 SQL 语句上下文相关信息,仅仅只需要记录某一条记录被修改成什么样子了。
Row 格式的日志内容会非常清楚地记录下每一行数据修改的细节,这样就不会出现 Statement 中存在的那种数据无法被正常复制的情况。
不过 Row 格式也有一个很大的问题,那就是日志量太大了,特别是批量 update、整表 delete、alter 表等操作,由于要记录每一行数据的变化,此时会产生大量的日志,大量的日志也会带来 IO 性能问题。
优势:记录的是没一条记录更新的详细信息,信息比较安全
缺点:日志的量较大
Mixed
从 MySQL5.1.8 版开始,MySQL 又推出了 Mixed 格式,这种格式实际上就是 Statement 与 Row 的结合。
在 Mixed 模式下,系统会自动判断 该 用 Statement 还是 Row:一般的语句修改使用 Statement 格式保存 binlog;对于一些 Statement 无法准确完成主从复制的操作,则采用 Row 格式保存 binlog。
Mixed 模式中,MySQL 会根据执行的每一条具体的 SQL 语句来区别对待记录的日志格式,也就是在 Statement 和 Row 之间选择一种。
3.采用minimal模式减少日志记录的内容,只记录受影响的列
4.指定需要复制的数据库的名字
5从库的配置和主库的配置大体相同,只是通过服务的唯一编号确定主从
6执行同步命令,设置要链接的主服务器的地址,要同步的数据库的名称,账号密码,二进制文件的名称和一个初始位置,这个位置会随之数据的备份不断改变,用来观察主从之间的差距,有多少数据待同步,如果主库开启令牌验证会给从库颁发令牌之后才能链主库(适用于不安全的外部数据库)
7start slave 开启从库
8.看到 slave_SQL_Running:yes
slave_TO_Running:yes
1.4 主主
两个都是主库,数据库之间会产生熵值(数据需要同步的部分),两个库都会产生数据,在数据同步的时候会产生数据被覆盖的情况,也就导致了数据的丢失,这样主主模式就只适合在一些数据要求不高的业务场景,允许一部分的丢失,对数据的容忍度比较高,分析数据,日志数据,这时候比主从更具有优势,都可以支持读写。也就是说只有只有一个主库的情况下可以实现数据的一致性,主库拥有绝对的话语权,可以把数据同步到各个从库当中
2.存储高可用之分区
数据量达到百万千万,数据库的链接数和存储空间都会不够,官方提示数据达到500w之后,数据库索引的效率就会下降,实际上超过1000w瓶颈就很明显,500w开始准备
多节点后性能提升,某个节点出现不可用,还有其他的节点可用,
2.1分片规则

1.索引本身也是数据当数据的量增加的时候数据库的索引也会增加,占用的空间也会很大,分解数据库之后索引的压力也会变小,提升了数据库尽力索引的效率,和命中索引的概率
2.随着用户的增加,系统的吞吐量增加,建立的链接也会增加,之前的资源池也能缓解这个压力,但是为了防止数据库收到限制,穿透,可以通过增加实例的方式提升数据库的吞吐率。
3.倾向于在JDBC层做分库分表,这一层是无感的 ,sql语句是逻辑语句,经过JDBC层的分片规则后明确和那一个物理数据库对接 ,包含sql解析路由,同时一个节点的数据库可以预留更多的资源,也可以建立多个数据库
2.2 分区拆分策略垂直切分

优点:
1.根据不同的业务进行解耦,对于不同的业务拆分开管理,不同业务之间互相的影响比较大,不利于针对某个业务进行单独的扩展,容易影响到其他的业务。
2.进行分库后也提升了数据库的节点个数,一定程度上增加了链接数,提升了数据库的吞吐率,增加了数据层的可用性,进而提升系统的可用性。
缺点:
1.提高了开发的复杂度,同一个库的不同表可以通过JDBC直接访问,现在需要通过多个系统间不同的接口做一个聚合,开发的复杂度随之上升。
2.分布式的事物的管理难度也会随之上升,涉及到两个库之后,也就涉及到了数据库的分布式的事物,TCC等一致性服务
3.数据库仍存在但表数据量过大的问题,仍需要通过水平拆分来提升数据库的提供服务的能力

优点:
1.数据库单表的上限官方数据是500w左右,超过500w数据库的性能肯定是收到影响的,会产生两个瓶颈(1.单表的数据量是瓶颈。2.数据库的链接数也是瓶颈)使用水平拆分可以稳定的提升系统稳定性和负载能力
2,业务改造的工作量不是很大
缺点:
1.一致性的问题
2.会产生两个库的关联查询
3.扩容的难度和维护的量较大,突然增加一个库,需要对数据进行搬运,数据打散,会面临很大的挑战
2.3 分区—算法range
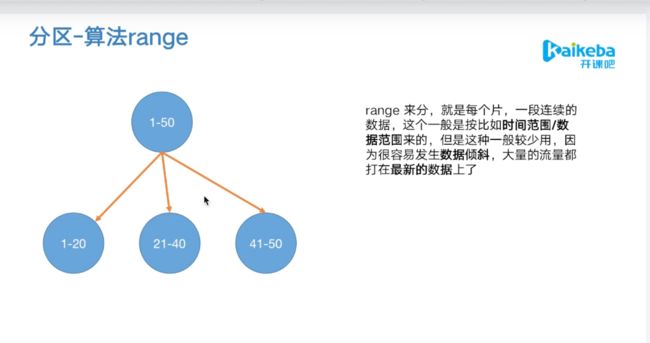
可以是根据id、时间
缺陷:(用时间)可能出现数据倾斜的问题,数据不平均
2.4 分区hash取模

较为常见的分区路由算法
缺陷:
无论是增加还是删除一个节点都会出现大量的迁移操作,例如增加一个节点,原先每个节点都需要迁移出来一部分数据到新的节点中,删除一个节点,被删除的节点的数据会分摊到其他的节点当中。
2.5分区-一致性哈希


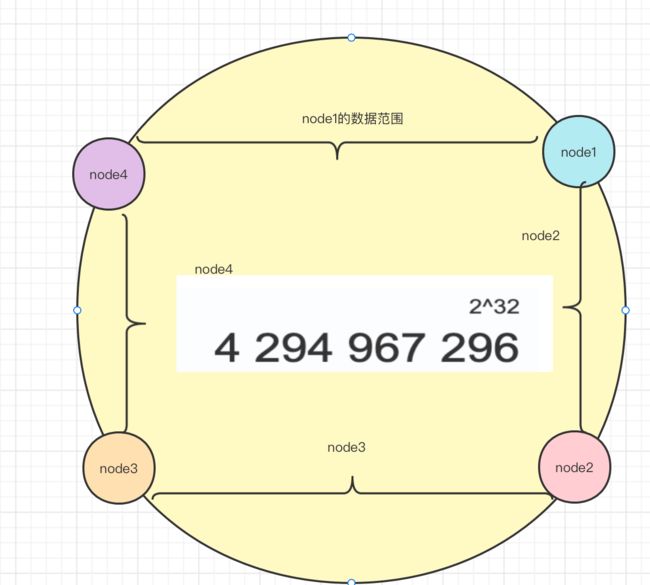
当node1出现问题的时候,只有25%的数据会收到影响,node1的数据会被放到node2节点上,极大的保证了命中率不会有大幅度的下降
缺陷:
会出现雪崩,node1出现问题后,如果node2不能承载node1的数据,相继出现问题会导致整个数据库雪崩
解决办法:
在整个环上都增加一些虚拟节点,让node1出现问题后,将原来的数据分散到各个节点当中,减少了因为某个节点的故障而导致其他的数据节点收到冲击 。同时也会增加命中率。
虚拟节点是算法中配置的,随机打散到数据环上。
2.6分区-技术实践 sharding-jdbc
大厂会有自己的jdbc中间件
2.6.1 pom依赖引用

2.6.2 配置多个数据源

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4TDtWmob-1650002249439)(/Users/zhaokaijie/Library/Application Support/typora-user-images/image-20220414152755521.png)]

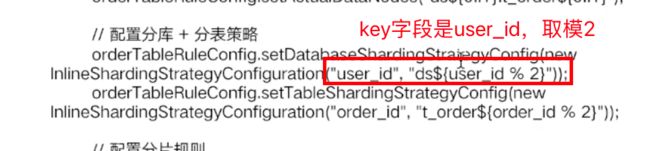
一个是解决命中库的问题,一个解决命中表的问题
3.存储高可用之容灾

主库突然宕机,数据库不可用后怎能保证业务的快速恢复,分钟级的恢复,业务允许数据丢失的情况才可以允许使用从库快速恢复业务,(账务、支付、库存),容灾是主库挂了情况下,如何不依赖主库的情况下,快速的恢复业务,
3.1 容灾-技术选型

流水型:存储的是增量数据(订单、支付),实现相对简单,可能丢失历史数据但是不影响新的数据的产生
状态型:支付宝余额,花呗额度,对数据的一致性要求很高的,当前的数据不存在,或者和宕机的时刻不一样,业务就会产生问题(是否可以采取双写的办法,保证强一致性)
3.2 容灾-流水型-技术方案
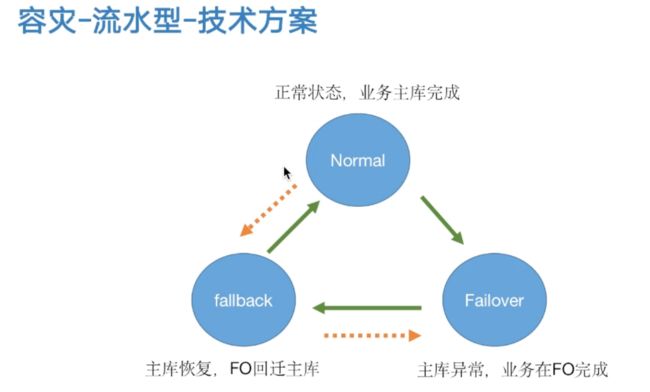
Normal:主库正常提供业务的状态
Failover:主库出现异常的状态,业务迁移到Fo库执行,记录状态
Fallback:主库已经恢复的状态,可以将Fo数据库的
如果从Fo迁移回主库的时候出现问题,可以重新返回到Fo状态,同样如果从Rollback状态改变成为Normal状态的时候出现问题,发现数据的完整性有问题,也可以从新切回到Fallback状态,重新进行数据回迁。
这里的Fo库是可以理解为备库的
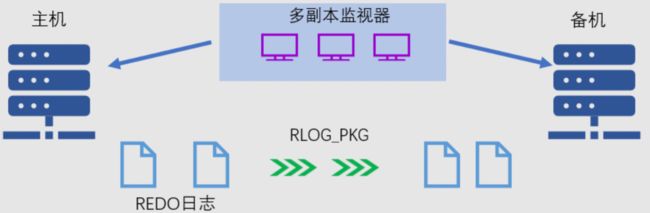
redo log 重做日志
日志的迁移可以使用mq,也可以使用数据迁移工具
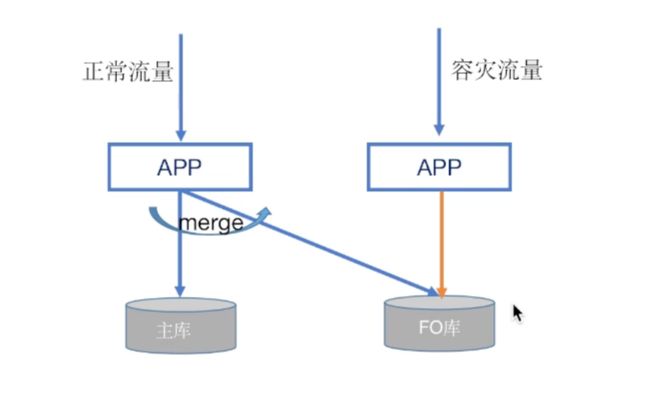
正常状态下数据是从用户直接到主库的,出现问题数据会存储到FO库,之后在fallback阶段是数据需要mock两个数据库的数据,只有完成数据迁移切换为Normall状态才可以正常切换数据
3.3 容灾-状态型-技术设计
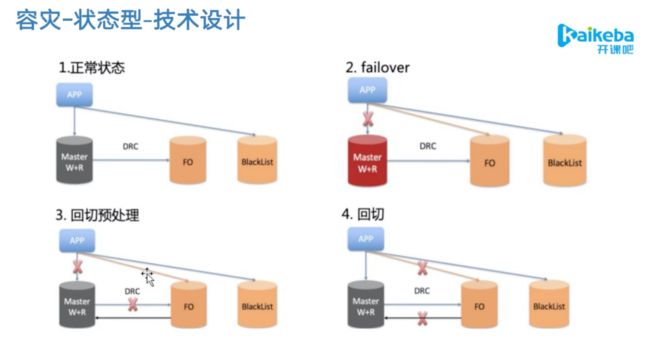
状态型容灾的难点在于数据一直性的要求很高,但是不能做到100%的一致性,只能保证大部分可用,因为数据会存在延时丢失等问题存在
1.正常状态下,没有问题的数据会存放在Master中,有问题的数据会存放在BlackList,在黑名单中的用户将不能继续完成业务,同时主节点和Fo之间是存在实时的同步的,但是仍有延迟。
2.failover状态下,数据不能进入Master会切换到Fo库,但是前提是不BlackList里面的数据
3.回切预处理,当主库恢复之后需要把Fo库中的数据迁移到主库当中
4.回切,当数据同步到主库后,恢复到正常的状态
关于Fo库,就是一个灾备库,可以是机房内的,同城机房,甚至是异地机房,机房内可以预防单个服务器出现问题,同城机房可以预防,机房断电,异地机房,可以预防 一个区域内的断电,地震等自然灾害

这里关键的技术点是如何保证事物的强一致性,要是用分布式事务(MQ的事物型消息,保证一致性,保证了在数据库宕机的瞬间也是有拿到同样的数据的,通过分布式缓存的客户端把数据维护到分布式缓存当中,临时存储起来)已知主库和读库之间通过binlog同步是有3s的延迟,这样吧redis的延迟设置到10分钟-20分钟是完全可以覆盖到主库宕机时的数据的
其次是黑名单的确定,首先获取一个快照,把还在redis中的数据放到黑名单,因为这些数据是还没有被处理的数据,黑名单内的数据就不能处理Fo读写库,
这里主库和FO库采用的是一个双写的模式,保证了数据的强一致性
也就是说黑名单的数据就是宕机时,来不及处理的积压的数据
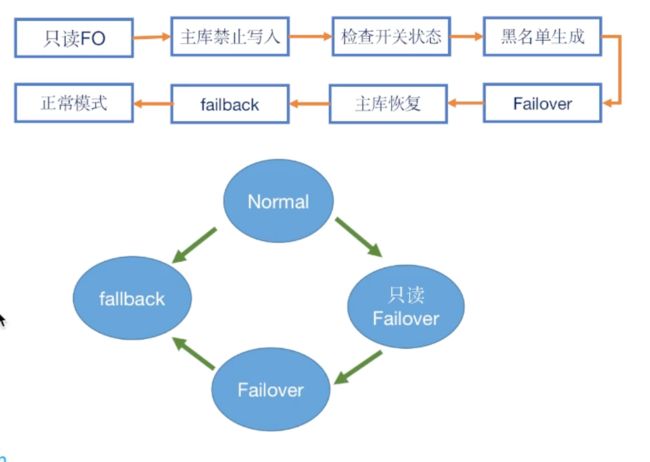
Failover防止主库假死的状态,保证数据假死状态时有数据写入,产生脏数据,要保证整个服务中对于主库是只读模式 ,对主库禁写的
1.只读FO,整个服务都要切换到对主库只读状态。
2.主库禁止写入,所有的数据主库都精致写入,DBA要保证主库此时是完全禁写的状态,DBA反复核实,每个节点需要专业的人去check
3.检查开关的状态,使用zk和阿波罗去推送一些状态的时候,不同的节点推送和完成的不一致,要检查所有的开关已经置为制度状态
4.形成黑名单,获取一个快照,把还在redis中的数据放到黑名单
5.Failover模式正式开启,数据可以进入FO库
6.主库进行恢复
7.failback,主库已经恢复,可以将Fo的数据迁回到主库当中
8.所有数据迁移完成就库切为正常模式
时间轴
