机器学习A-Z学习笔记(使用最新的库,超详细)1. 数据预处理模板
2022.10.09
人应该有力量,揪着自己的头发把自己从困境沼泽里拔出来。
在此特别鸣谢东川大佬,用于一些库的更新,受时间限制这个课程里对于库的运用方法老旧。
我于茫茫信息流中找到东川的个人网站,解决了我的燃眉之需。在信息化的时代里,需要这样优秀的学习分享者。在此,我秉持分享的精神,我对所有正在学习这么课的小白,推荐东川的个人网站,相信会解决你们的燃眉之需。
https://vccyb.gitee.io/myblog/
数据预处理与机器学习
在现实生活问题中,我们得到的原始数据往往非常混乱、不全面,机器学习模型往往无法有效地识别,并提取信息。在采集完数据后,为保证数据的可靠性和有效性,机器学习建模的首要步骤便是数据预处理。
数据的预处理Data Preprocessing
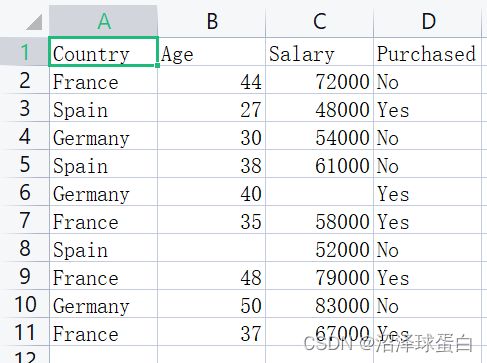
1. 简介数据集
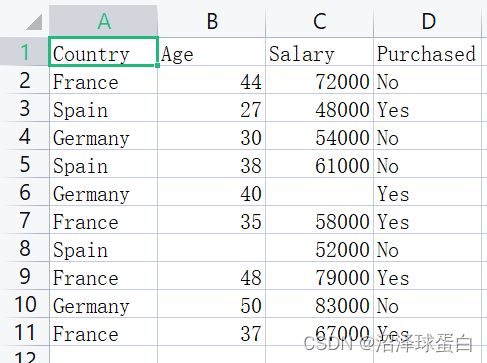
我们要处理的数据集是:
该图为某公司客户信息,希望通过已有的数据创建一个机器学习模型来预测新客户是否会购买产品。

purchased —> 购买记录 salary —> 薪水
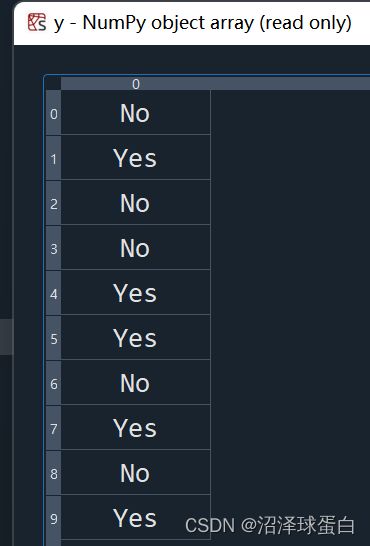
在每一个机器学习模型里,都会存在自变量x与因变量y,拟合的模型会通过自变量来预测因变量。此次模型中的因变量为第0,1,2列,是否购买是因变量。
2. 导入标准库Importing the Libraries
标准库相当于一个工具包,包含已经编写好的工具(对应很多处理数据方法)
# Importing the libraries
import numpy as np #import --> 导入
import matplotlib.pyplot as plt
import pandas as pd
数据预处理常用的三个标准库
- numpy 包含了很多的数学工具
- matplotlib的子库pyplot 方便在python里画出漂亮的图像
- pandas 方便导入数据集,并对数据集进行必要操作
3. 导入数据集Importing the Dataset
1. 设置工作路径,工作路径导向的文件夹必须包含数据集

spyder开发环境中左上方的files里打开包含数据集的文件夹
2.
-
# Importing the dataset dataset = pd.read_csv('Data.csv') #利用pd标准库导入原始数据集Data.csv X = dataset.iloc[:, :-1].values #创建矩阵X,包含自变量,处理X。 #icloc表示取数据集的某些行和列。 #在中括号里逗号左边代表行号,右边代表列数。(单独一个:表示取所有的行数或列数)(-1代表不会取最后一列,:-1代表取除去最后一列的其他列) y = dataset.iloc[:, 3].values #以向量y,包含因变量(想要预测的值) #只取第3列(从0开始计列数)运行结果如下:

在python中,数据集的行数和列数从0开始,在R语言中是从1开始的。
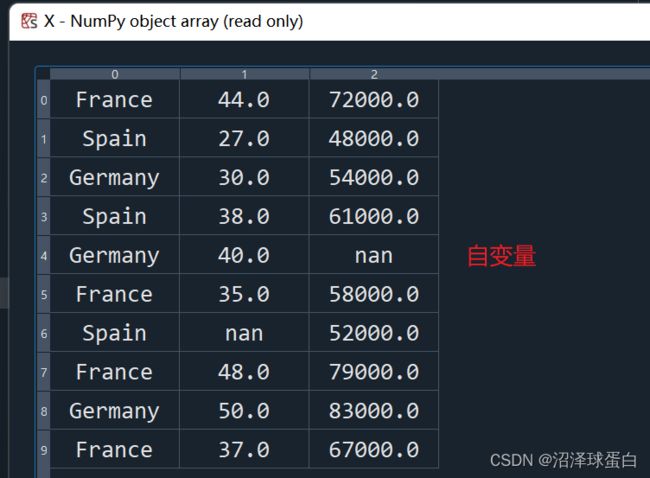
4. 处理缺失数据 Missing Data
我们的daraset缺失了两个数据,位于第1列和第2列
我们常用到sklrean,这个建立在pandas上的机器学习工具,进行数据挖掘与数据分析。
处理缺失数据的方法:
-
直接把一整行数据删除,但存在缺失重要信息的风险
-
用一列相同特征的数据的某值代替这个数据
进行缺失数据的处理,我们会用到sklrean.preprocess这个子库里的Imputer类。
可利用的Imputer类的参数 (在sypder里点击 “ctil+i” 查看帮助)
missing_values参数是来辨认缺失数据

strategy参数代表策略,即如何处理数据

mean–>平均值 median–>中位数 most_frequent–>取相同特征的其他数据最常出现的值
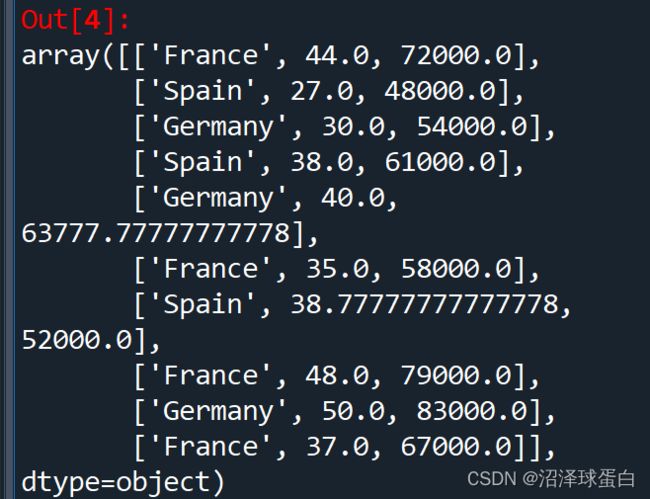
# Taking care of missing data
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer = imputer.fit(X[:,1:3]) #fit是拟合的意思 *#1:3代表1到2*
X[:,1:3] = imputer.transform(X[:,1:3])
运行结果如下:
5. 分类数据 Categorical Data
首先有一个问题,在机器学习中,大多数算法只能处理数值型数据不能处理文字。尤其是使用sklearn里的工具时,大多只能输入数组、矩阵或向量。
为了让数据适应sklrean库,必须把文字数据进行编码转换,从而为数值型。
1. 首先使用sklrean.preprocessing里的LabelEncoder类,可以将不同的名称转义为数字(有权重)
from sklearn.preprocessing import LabelEncoder
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[:, 0]) #fit_transform来进行拟合和转化
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y) #y是一个向量
运行如下:

这个结果明显是不准确的,因为国家这个特征里的三个数据类别之间没有数值的先后排序之分。
然而012存在一个数值多少的区分为解决这个问题我们要进行:
2.使用sklrean.preprocessing里的OneHotEncoder类,进行独热编码
虚拟编码(变量)

根据同一特征里的文字型变量的类别数量,只使用二进制编码无权重地区分不同类别的文字型变量。
OneHotEncoder类的参数 categories参数

categories就是说要告诉它,这个特征有几个类别的数据。auto就是说让它自己看着办
默认auto,所以不需要在()中写出
from sklearn.preprocessing import OneHotEncoder #import独热编码类
enc = OneHotEncoder(categories='auto')
enc.fit(X[:,0].reshape(-1,1)) #拟合数据
result = enc.transform(X[:,0].reshape(-1,1)).toarray() #toarray是说请帮我变成数组
X = np.column_stack((result,X[:,1:])) #np.column_stack这个工具就是把两个矩阵合并
#注意重复运行会增加01数量
矩阵result是
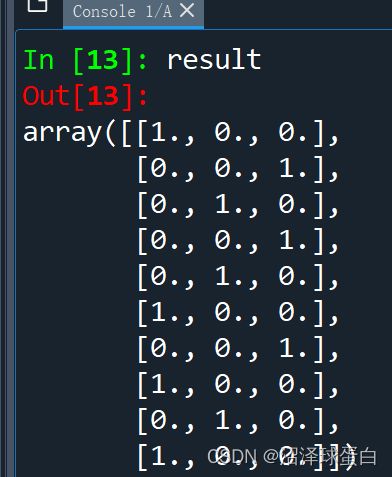
最终矩阵X为

6. 将数据分成训练集和测试集 Splitting the Dataset into Training set and Test set
为什么要把数据集分成测试集和训练集两部分?
首先介绍一下 拟合的概念:在机器学习过程中,我们的机器会学习训练集的因变量和自变量之间的关系,并且运用到改进数学模型中。这个过程叫拟合。
我们用训练集的数据来拟合模型,运用这个数学模型来尝试预测测试集的因变量(结果),再比较预测结果和实际结果,我们可以得到很多信息。
操作
这里我们利用train_test_split这个类,以下为这个类的参数

- arrays: 代表我们要输入,我们要划分的数据
- test_size: 表示测试集所占比重(0.0~1.0)。(一般来说比较好的比重是0.2或0.25,这里默认为0.25)
测试集的比重很少出现0.4以上,我们的模型需要足够的数据进行学习
- random_state: 决定了随机数生成方式。(因为我们需要随机选取数据分配到训练集和测试集里面)
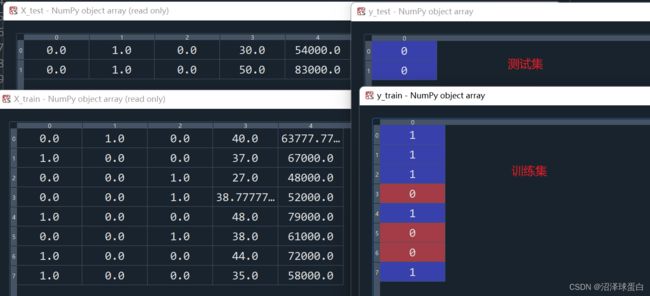
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state = 0)
运行结果如下:
什么叫过度拟合
当我们发现拟合出来的模型,对于训练集的预测结果很好,但对于测试集的预测比较一般,此时发生了过渡拟合。这意味着在机器学习训练集时,学的太多了,最后生成的模型里充斥着非常多只属于训练集的信息。这明显是不合适的。
7. 特征缩放 Feature Scaling
什么是特征缩放?为什么对数据进行特征缩放?
-
特征缩放,就是将不同数量级的数据缩放到同一个数量级
-
- 当数据集里不同特征的数据的数量级不同时,不进行特征缩放,会导致数量级较小的特征对模型拟合的影响变小。
- 许多机器学习的常见算法都需要用到距离函数,其中欧式距离应该算得上其中“最简单”和“最直观”的距离函数了。如果不进行特征缩放,在用到欧式距离时,明显看到,age特征对距离的影响不大。

对于虚拟变量,我们是否要进行特征缩放?
取决于实际情况,不进行大多情况是可以的,但进行了会增强模型性能
在这里,我对所有变量进行特征缩放
# 特征缩放 将不同数量级的数据缩放到同一个数量级
from sklearn.preprocessing import StandardScaler #import这个类
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train) #先拟合后转化
X_test = sc_X.transform(X_test) #对象sc_X已经被上一步拟合好了
运行结果如下:

此模型不需要对因变量做特征缩放
8. 在学习数据预处理的原理过后,我们可以创建一个属于个人数据预处理模板,来方便我们之后进行数据预处理。
但再学习过程中,我发现由于太多的库更新,就无法使用原来模板代码了