Machine Learning A-Z学习笔记
Machine Learning A-Z学习笔记
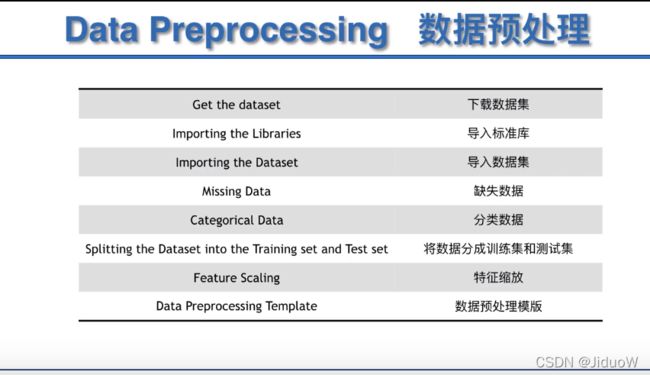
第一章 数据预处理
1.导入标准库
import numpy as npnumpy 数学工具库
import matplotlib.pyplot as pltmatplotlib.pyplot 绘图库
import pandas as pdpandas 方便导入数据集,对数据集做必要的操作
2.导入数据集
dataset = pd.read_csv('Data.csv')Data.csv为数据集路径
3.设置自变量和因变量
X = dataset.iloc[:,:-1].values
y = dataset.iloc[:,3].values
iloc.读取数据集中的某一些行列
格式:iloc[行,列]
-1代表除去最后一列
values获取数据,返回一个numpy
4.缺失数据的处理方法
缺失数据的处理
(1)直接删除:如果数据量很大,那么可以直接删除
(2)如果数据量很小或者确实数据中其他参数含有比较重要的信息那么该方法会造成很大误差 根据未缺失数据填充
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values='NaN', strategy='mean', axis=0)#将标记为NaN的数据认为缺失数据,strategy表明填充策略,本例子采用均值,axis指定取均值的位置
imputer = imputer.fit(X[:,1:3]) #通过fit方法可以计算矩阵缺失的相关值的大小,以便填充其他缺失数据矩阵时进行使用。
X[:,1:3] = imputer.transform(X[:,1:3])#之后给定一个X矩阵,通过transform方法进行转换
Imputer用来对缺失数据进行处理
一般我们实际使用时,对于给定的数据,直接使用fit_transform方法进行计算以及填充
5.分类数据
将数据中不为数字(字符串等)的数据进行标记
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder()
X[:,0] = labelencoder_X.fit_transform(X[:,0])# 对第一列的数据用十进制数进行标记
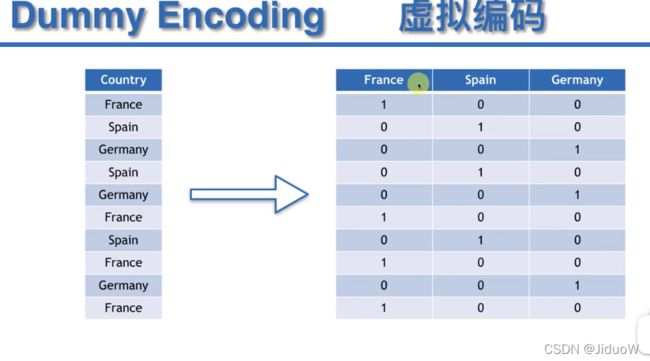
onehotencoder = OneHotEncoder(categorical_features=[0])# 将数据编码为one-hot形式虚拟编码直接labelencoder数据会让数据带有大小区别,而且会在不同数据之间建立联系,one-hot标记可以生成虚拟编码可以使欧式距离的计算更加方便
X = onehotencoder.fit_transform(X).toarray()# 将数据转化为numpy
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
6.将数据集切分为训练集和测试集
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)# 将数据切分为训练和测试集,比例通过test_size指定,random_state=0保证随机结果一直不变
7.特征缩放
特征缩放是用来标准化数据特征的范围,将不同数量级的数据缩放到同一个数量级
为什么特征缩放:训练模型的过程中,经常会用到欧氏距离,如果两组数据不在一个维度,另一个特征基本上可以忽略不计。或者不用欧式距离,但收敛速度会很快。
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
8.数据预处理模板
#数据预处理模板
导入库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
#导入数据
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[:,:-1].values
y = dataset.iloc[:,3].values
#处理缺失数据的模板代码,此处用平均值代替
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = 'NaN', strategy = 'mean', axis = 0)
imputer = imputer.fit(X[:, 1:3])
X[:, 1:3] = imputer.transform(X[:, 1:3])
#处理分类数据的模板代码,虚拟编码
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[:, 0])
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
#训练集和测试集划分模板代码
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
#特征缩放模板代码
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)