聚类算法之K-Means和FCM
目录
K-Means
FCM
聚类有效性指标——CH
K-Means
K-Means算法是一种无监督的学习算法,是划分聚类算法的代表算法。一般采用欧式距离来衡量数据对象之间的相似度,相似度与数据对象间的距离成反比,相似度越大,距离越小。
K-Means算法是一个不断迭代的过程,其核心思想是:
(1)从包含 个数据点
个数据点 的数据集中随机选择
的数据集中随机选择 个数据点作为聚类中心(cluster centroids)。如果数据集为一幅图像,那么数据点就是图像中的像素点;
个数据点作为聚类中心(cluster centroids)。如果数据集为一幅图像,那么数据点就是图像中的像素点;
(2)对于数据集中的数据点,计算与个中心点的距离,使用的距离度量方法是欧氏距离,即计算两数据点的直线距离。如果数据集为一幅图像,那么数据点与中心点的距离就是两像素点数值差的平方和。将数据点与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一簇;
(3)计算每一簇中数据点的平均值,如果数据集为一幅图像,那么每一簇中数据点的平均值就是每一簇中像素点数值和的平均值,将该簇所关联的中心点移到平均值的位置;
(4)进行下一次迭代,直至中心点不再变化或达到最大迭代次数停止迭代。
K-Means算法的流程图如下图所示:

K-Means算法代码(适用于图像) :
import numpy as np
import random
def classifier(X, C, k):
X_cp = np.copy(X)
[N, p] = X_cp.shape
a = X_cp * X_cp
a = np.reshape(a, newshape=(N, 1))
d = np.ones(shape=(1, k))
e = C * C
e = np.reshape(e, newshape=(k, 1))
f = np.ones(shape=(1, N))
g = 2 * np.dot(X_cp, C.T)
h = np.dot(a, d)
i = np.dot(e, f)
dist = h + i.T - g
# 根据距离进行聚类
labels = np.argmin(dist, axis=1)
return labels
def randomInitialCenters(X, k):
X_cp = np.copy(X)
[N, p] = X_cp.shape
# 随机初始聚类中心 的 索引
initial_center_index = [i for i in range(N)]
random.shuffle(initial_center_index)
initial_center_index = initial_center_index[:k]
# 随机选取聚类中心
C = []
for i in range(k):
C.append(X_cp[initial_center_index[i]])
C = np.array(C)
labels = classifier(X_cp, C, k)
return labels, C
def KMeans(X, k, threshold):
X_cp = np.copy(X)
[N, p] = X_cp.shape
labels, C = randomInitialCenters(X_cp, k)
for i in range(k):
tmp = np.where(labels == i)
if len(X_cp[tmp]) == 0:
labels, C = randomInitialCenters(X_cp, k)
J = []
iter = 0
while True:
iter = iter + 1
preC = C.copy()
# 聚类中心的更新
# 新的聚类中心,同一簇样本的均值
for i in range(k):
temp = np.where(labels == i)
C[i] = sum(X_cp[temp]) / len(X_cp[temp])
# 各样本到各聚类中心的距离
# (a-b)^2=a^2+b^2-2ab
# 根据距离进行聚类
labels = classifier(X_cp, C, k)
# 目标函数的计算
J_cur = np.sum((np.array(C) - np.array(preC))**2)
J.append(J_cur)
# 当聚类中心的位置不再变化 【或 到达最大迭代次数】
if J_cur <= threshold:
break
# print('iteration: %d, objective function: %g' % (iter, J_cur))
return C, labels, J
# np.where(condition, x, y)
# 满足条件(condition),输出x,不满足输出y。
# 如果是一维数组,相当于[xv if c else yv for (c,xv,yv) in zip(condition,x,y)]
# np.where(condition)
# 只有条件 (condition),没有x和y,则输出满足条件 (即非0) 元素的坐标 (等价于numpy.nonzero)。
# 这里的坐标以tuple的形式给出,通常原数组有多少维,输出的tuple中就包含几个数组,分别对应符合条件元素的各维坐标。
调用K-Means算法对图像进行聚类:
from pylab import *
from PIL import Image
import numpy as np
from Clustering import KMeans
import clusterValidityIndex
import showImg
'''
归一化
'''
def norm(img):
minimg = np.min(img)
maximg = np.max(img)
data1 = img - minimg
data2 = maximg - minimg
img = data1/data2
return img
if __name__ == "__main__":
infile = '../data/0000.tif'
im = np.array(Image.open(infile))
# im = norm(im)
# print(im)
# 针对灰度图,获取图像的宽度、高度,将二维数组变为一维数组
m, n = im.shape
I = np.reshape(im, (m*n, 1))
k = 3
threshold = 0
C, labels, J = KMeans.KMeans(I, k, threshold)
labels = np.reshape(labels, (m, n))
# 绘制 迭代次数 与 损失函数 的 关系图
x = [i for i in range(len(J))]
plt.plot(x, J)
plt.xlabel('iterations')
plt.ylabel('objective function')
plt.show()
# 显示并保存聚类结果图
# showSingleImg()为自己编写的函数
showImg.showSingleImg(labels, '../data/', 'KMeans_0000', False)
# 计算聚类后的CH值
# CH()为自己编写的函数
CH = clusterValidityIndex.CH(im, labels, C, k)
print('CH: %g' % CH)FCM
模糊C均值算法(Fuzzy C-Means,FCM)是一种无监督的学习算法,是划分聚类算法的算法。FCM融合了模糊理论的精髓,相较于K-Means算法的硬聚类(各个样本所属类别的非此即彼),它提供了更灵活的聚类结果。大部分情况下,数据集中的对象不能划分成为明显分离的簇,生硬指派一个对象到某一个簇中可能会出错。FCM对数据集中的每个对象对于每个簇赋予一个权值,即隶属度。FCM聚类算法的实现方法是根据图像像素和聚类中心的加权相似性测度,对目标函数进行迭代优化以确定最佳聚簇。
将数据集![]() 分为
分为 类,
类,![]() 为个聚类中心点集,
为个聚类中心点集,![]() 为数据集中样本
为数据集中样本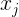 对聚类中心
对聚类中心![]() 的隶属度,模糊隶属度矩阵
的隶属度,模糊隶属度矩阵![]() 表示聚类结果,
表示聚类结果,![]() 为样本与聚类中心
为样本与聚类中心![]() 间的欧几里得距离,
间的欧几里得距离, 为模糊加权指数,控制数据划分过程中的模糊程度,当时
为模糊加权指数,控制数据划分过程中的模糊程度,当时![]() ,模糊聚类就退化为K-Means聚类。Pal N R等人的研究表明,的经验取值区间范围为[1.5,2.5],通常的理想取值为2。
,模糊聚类就退化为K-Means聚类。Pal N R等人的研究表明,的经验取值区间范围为[1.5,2.5],通常的理想取值为2。
FCM算法是一个不断迭代的过程,其核心思想是:
(1)初始化聚类个数和模糊加权指数,随机初始化隶属矩阵![]() ;
;
(2)更新聚类中心,新的聚类中心在全部样本属于该簇的隶属度加权平均更新公式如下:

(3)计算数据集中数据点隶属于簇的程度,计算式如下:

(4)进行下一次迭代,直至中心点不再变化或达到最大迭代次数停止迭代。
(5)数据集中每个样本的标签为隶属度最大的簇的索引值。
FCM是通过最小化隶属度矩阵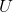 和聚类中心矩阵的目标函数
和聚类中心矩阵的目标函数![]() 来实现的:
来实现的:

FCM算法代码(适用于图像)(Matlab版本):
function [C, dist, J] = FCM(X, k, b)
iter = 0;
[N, p] = size(X);
% 从kmeans各个样本所属类别 的非此即彼(要么是0要么是1,如果建立一个归属矩阵N?k,N?k每一行表示样本的归属情况,则会得到,其中一个entry是1,其他是0),
% 到走向模糊(Fuzzy),走向不确定性(此时的归属(fuzzy membership)阵P(μi|xj)i∈1,…k,j∈1,…NP(μi|xj)i∈1,…,k,j∈1,…,N,每个元素都会是[0-1]之间的概率值,行和要求为1)。
% 模糊加权指数b:控制数据划分过程的模糊程度(不同类别的混合程度的自由参数),b的经验取值区间范围为[1.5,2.5],通常取b=2,当 b=1时,模糊聚类就退化为硬C均值聚类
% 距离的度量:dij=||xj?μi||^2 每个样本值-聚类中心的平均值
% 欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。
% 在二维和三维空间中的欧氏距离就是两点之间的实际距离。
% 目标函数:Jfuz=∑i=(1,N)∑j=(1,c)【P(μi|xj)^b * dij】
% 隶属度函数P(μi|xj),表征样本xj隶属类别(cluster)μi的程度,即允许一个样本隶属于多个类别,只不过程度不同而已。
% 初始并【归一化】隶属函数P(μi|xj) N代表样本个数,即图像的总像素点数
P = rand(N, k); % 生成一个0~1之间的随机数 shape=(N,k) 每个样本隶属于每个聚类中心的概率
P = P./(sum(P, 2)*ones(1, k)); % 使每行值加起来和为1 sum(P, 2)按行计算:shape=(N,1) (N,1)*(1,k)=(N,k) (N,k)./(N,k)=(N,k)
J_prev = inf; J = [];
while true
iter = iter + 1;
% 聚类中心的更新
% 新的聚类中心,全部样本的属于该类别(编号)的加权【平均】。
t = P.^b; % shape=(N,k) 模糊的隶属矩阵
C = (X'*t)'./(sum(t)'*ones(1, p)); % X'*t:每个样本值 * 对应的模糊的隶属矩阵,p为图像的通道数 (X'*t)'=(k,p)
% (p,N)*(N,k)=(p,k)加权求和 当p=1,k=3:(1,N)*(N,3)
% sum(t):同一类所有样本(模糊的)概率值相加
% sum(t)=(1,k) sum(t)'=(k,1) (k,1)*(1,p)=(k,p)当k=3,p=3:每个通道的隶属度一样
% (k,p)./(k,p)=(k,p)
% 各样本到各聚类中心的距离
% (a-b)^2=a^2+b^2-2ab
dist = sum(X.*X, 2)*ones(1, k) + (sum(C.*C, 2)*ones(1, N))'-2*X*C'; % X.*X=(N,p)样本值的平方 sum(X.*X,2)=(N,1)各通道的值相加 (N,1)*(1,k)=(N,k) 当k=3:(N,3)
% C.*C=(k,p)聚类中心值的平方 sum(C.*C,2)=(k,1) (k,1)*(1,N)=(k,N) (k,N)'=(N,k)
% 2*X*C'=(N,p)*(p,k)=(N,k)
% 隶属函数P(μi|xj)的更新
% 隶属度与距离成反比
t2 = (1./dist).^(1/(b-1)); %1/(b-1)中的1 (N,k)
P = t2./(sum(t2, 2)*ones(1, k)); % 到各聚类中心的(模糊)距离相加(N,1) (N,1)*(1,k)=(N,k)求到各聚类中心的占比
% 目标函数的计算
J_cur = sum(sum((P.^b).*dist))/N; %(N,k).*(N,k)=(N,k)->(1,k)->(1,1)除以样本数
J = [J J_cur];
% NORM(X,'fro') is the Frobenius norm, sqrt(sum(diag(X'*X))).
test1 = J_cur-J_prev;
test2 = norm(J_cur-J_prev, 'fro');
if norm(J_cur-J_prev, 'fro') < 1e-3
break;
end
fprintf('#iteration: %03d, objective function: %f\n', iter, J_cur);
J_prev = J_cur;
end调用K-Means算法对图像进行聚类(Matlab版本):
clear ;
close all;
I = imread('./0000.tif');
rng('default');
[m, n] = size(I);
I = double(I);
X = reshape(I, m*n, 1);
k = 3;
b = 2;
[C, dist, J] =FCM(X, k, b);
% a是一个矩阵,1:列或2:行求最小
% [Y,U]=max(A):返回行向量Y和U,Y向量记录A的每列的最大值,U向量记录每列最大值的行号。
[~, label] = min(dist, [], 2);
figure
imshow(uint8(reshape(C(label, :), m, n)))
figure
plot(1:length(J), J, 'r-*'), xlabel('#iterations'), ylabel('objective function')FCM算法代码(适用于图像)(Python版本):
import numpy as np
# threshold=1e-3
def FCM(X, k, b, threshold=1e-12):
[N, p] = X.shape
# 从kmeans各个样本所属类别 的非此即彼(要么是0要么是1,如果建立一个归属矩阵N∗k,N∗k每一行表示样本的归属情况,则会得到,其中一个entry是1,其他是0),
# 到走向模糊(Fuzzy),走向不确定性(此时的归属(fuzzy membership)阵P(μi|xj)i∈1,…k,j∈1,…NP(μi|xj)i∈1,…,k,j∈1,…,N,每个元素都会是[0-1]之间的概率值,行和要求为1)。
# 初始并【归一化】隶属函数P(μi|xj) N代表样本个数,即图像的总像素点数
# 模糊加权指数b:控制数据划分过程的模糊程度(不同类别的混合程度的自由参数),b的经验取值区间范围为[1.5,2.5],通常取b=2,当 b=1时,模糊聚类就退化为硬C均值聚类
# 距离的度量:dij=||xj−μi||^2 每个样本值-聚类中心的平均值
# 欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。
# 在二维和三维空间中的欧氏距离就是两点之间的实际距离。
# 目标函数:Jfuz=∑i=(1,N)∑j=(1,c)【P(μi|xj)^b * dij】
# 隶属度函数P(μi|xj),表征样本xj隶属类别(cluster)μi的程度,即允许一个样本隶属于多个类别,只不过程度不同而已。
P = np.random.rand(N, k) # 生成一个0~1之间的随机数 shape=(N,k) 每个样本隶属于每个聚类中心的概率
# P = P./(sum(P, 2)*ones(1, k))
a = np.sum(P, 1)
a = np.reshape(a, newshape=(N, 1))
d = np.ones(shape=(1, k))
e = np.dot(a, d)
P = np.divide(P, e)
# print(P)
# P = np.divide(P, np.dot(np.sum(P, 1), np.ones(1, k)))
# 使每行值加起来和为1 sum(P, 1)按行计算:shape=(N,1) (N,1)*(1,k)=(N,k) (N,k)./(N,k)=(N,k)
J_prev = np.inf # float('Inf')
J = []
iter = 0
while True:
iter = iter + 1
# 聚类中心的更新
# 新的聚类中心,全部样本的属于该类别(编号)的加权【平均】。
# t = P.^b
t = P**b # shape=(N,k) 模糊的隶属矩阵
# C = (X'*t)'./ (sum(t)'*ones(1, p))
a = np.dot(X.T, t).T
d = np.sum(t, 0).T
d = np.reshape(d, newshape=(k, 1))
e = np.ones(shape=(1, p))
f = np.dot(d, e)
C = np.divide(a, f)
# C = np.divide(np.dot(X.T, t).T, np.dot(np.sum(t, 0).T, np.ones(shape=(1, p))))
# X'*t:每个样本值 * 对应的模糊的隶属矩阵,p为图像的通道数 (X'*t)'=(k,p)
# (p,N)*(N,k)=(p,k)加权求和 当p=1,k=3:(1,N)*(N,3)
# sum(t):同一类所有样本(模糊的)概率值相加
# sum(t)=(1,k) sum(t)'=(k,1) (k,1)*(1,p)=(k,p)当k=3,p=3:每个通道的隶属度一样
# (k,p)./(k,p)=(k,p)
# 各样本到各聚类中心的距离
# (a-b)^2=a^2+b^2-2ab
# dist = sum(X.*X, 2)*ones(1, k) + (sum(C.*C, 2)*ones(1, N))'-2*X*C'
a = X*X
a = np.reshape(a, newshape=(N, 1))
d = np.ones(shape=(1, k))
e = C*C
e = np.reshape(e, newshape=(k, 1))
f = np.ones(shape=(1, N))
g = 2*np.dot(X, C.T)
h = np.dot(a, d)
i = np.dot(e, f)
dist = h + i.T - g
# dist = np.dot(np.sum(X*X, 1), np.ones(shape=(1, k))) + np.dot(np.sum(C*C, 1), np.ones(shape=(1, N))) - 2*np.dot(X, C.T)
# X.*X=(N,p)样本值的平方 sum(X.*X,2)=(N,1)各通道的值相加 (N,1)*(1,k)=(N,k) 当k=3:(N,3)
# C.*C=(k,p)聚类中心值的平方 sum(C.*C,2)=(k,1) (k,1)*(1,N)=(k,N) (k,N)'=(N,k)
# 2*X*C'=(N,p)*(p,k)=(N,k)
# 隶属函数P(μi|xj)的更新
# 隶属度与距离成反比
# t2 = (1./dist).^(1/(b-1))
t2 = (1/dist) ** (1 / (b-1)) #1/(b-1)中的1 (N,k)
# P = t2./(sum(t2, 2)*ones(1, k))
a = np.sum(t2, 1)
a = np.reshape(a, newshape=(N, 1))
d = np.ones(shape=(1, k))
e = np.dot(a, d)
P = t2 / e
# P = t2 / np.dot(np.sum(t2, 1), np.ones(shape=(1, k)))
# 到各聚类中心的(模糊)距离相加(N,1) (N,1)*(1,k)=(N,k)求到各聚类中心的占比
# 目标函数的计算
# J_cur = sum(sum((P.^b).*dist))/N
a = P ** b
d = a * dist
e = np.sum(d)
J_cur = e / N
# J_cur = e
# print(J_cur)
J.append(J_cur)
tmp = J_cur-J_prev
# print(tmp)
a = tmp ** 2
# print(a)
f = np.sqrt(a)
# 代价函数收敛
if f < threshold:
break
# print('iteration: %d, objective function: %g' % (iter, J_cur))
J_prev = J_cur
return C, dist, J
# np.random.rand(d0,d1,d2……dn):
# 通过本函数可以返回一个或一组服从"0~1"均匀分布的随机样本值。随机样本取值范围是[0,1),不包括1。
# np.sum()函数:
# 不传参数就是所有元素的和
# axis=1以后就是将一个矩阵的每一行向量相加
# axis取多少,就表明在哪个维度上求和
# axis=None 表示对所有元素求和
# axis=0 表示在第1个维度上求和 [1,n]
# axis=1 表示在第2个维度上求和 [n,1]
# axis=0 对行(上下)进行计算操作
# axis=1 对列(左右)进行计算操作
# #2x2 矩阵,矩阵相乘
# print(" a mul b:\n", a.dot(b.T))
#
# #2x3矩阵,矩阵点乘
# print(" a dot b: \n", a*b)
#
# #2x3矩阵,矩阵点除
# print("a/b \n:", a/np.linalg.inv(b))调用FCM算法对图像进行聚类(Python版本):
from pylab import *
from PIL import Image
import numpy as np
from Clustering import FCM
import clusterValidityIndex
import showImg
'''
归一化
'''
def norm(img):
minimg = np.min(img)
maximg = np.max(img)
data1 = img - minimg
data2 = maximg - minimg
img = data1/data2
return img
if __name__ == "__main__":
infile = '../data/0000.tif'
im = np.array(Image.open(infile))
im = im.astype(np.float32)
im = norm(im)
# print(im)
m, n = im.shape
I = np.reshape(im, (m*n, 1))
k = 3
b = 2
C, dist, J = FCM.FCM(I, k, b)
labels = np.argmin(dist, axis=1)
labels = np.reshape(labels, (m, n))
x = [i for i in range(len(J))]
plt.plot(x, J)
plt.xlabel('iterations')
plt.ylabel('objective function')
plt.show()
showImg.showSingleImg(labels, '../data/', 'FCM_0000', False)
CH = clusterValidityIndex.CH(im, labels, C, k)
print('CH: %g' % CH)展示保存图像的代码,链接:显示图像(Python版)
聚类有效性指标——CH
为了清楚地介绍CH指标,给出如下定义:在欧式空间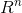 中,数据集
中,数据集 包含个样本:
包含个样本:![]() ,聚类算法将数据集划分为个互不相交的聚簇
,聚类算法将数据集划分为个互不相交的聚簇![]() ,各个聚簇对应的聚类中心
,各个聚簇对应的聚类中心![]() 为及数据集的全局中心为
为及数据集的全局中心为 。对于各个聚簇
。对于各个聚簇 中样本点的数量用
中样本点的数量用![]() 表示。样本点
表示。样本点 和之间的欧式距离为:
和之间的欧式距离为:![]()

CH指标是众多聚类有效性指标中性能较好的指标之一。它通过计算各个聚类中心与数据集中心(数据集的均值)的欧式距离的平方和度量数据集的分离度,通过计算各个聚簇中样本点与对应的聚类中心的欧式距离的平方和来度量类间的紧密度。CH值越大,意味着类与类之间越分散,类自身越紧密,即更优的聚类结果。
图像聚类结果的CH值计算代码:
import numpy as np
'''
X: [m,n]
labels:[m,n]
'''
def CH(X, labels, C, k):
X_cp = np.copy(X)
[m, n] = X.shape
# 数据集中心(数据集的中心)
center = np.sum(X_cp) / (m * n)
# print(center)
pixel_distance = [] # 每个像素与对应的聚类中心的距离
# 计算每个像素与对应的聚类中心的【差平方】
for i in range(k):
temp = np.where(labels == i)
dist = np.sum((X_cp[temp] - C[i]) ** 2)
pixel_distance.append(dist)
# print(pixel_distance)
center_distance = []
# 每个簇的均值 与 数据集的均值 的距离
for i in range(k):
n = np.sum(labels == i)
distance = (center - C[i]) ** 2
t = n * distance
center_distance.append(t)
# print(n, distance, t)
pixel_distance = sum(pixel_distance)
center_distance = sum(center_distance)
CH = center_distance / pixel_distance
return CH参考链接:
基于K-means聚类算法的图像分割
模式识别经典算法——FCM图像聚类分割(最简matlab实现)
参考文献:
李志梅,肖德贵.快速模糊C均值聚类的图像分割方法[J].计算机工程与应用,2009,45(12):187-189.