Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
动机:
为啥挑这篇文章,因为效果炸裂,各种改款把各种数据集霸榜了:语义分割/分类/目标检测,前10都有它

Swin Transformer, that capably serves as a general-purpose backbone for computer vision.
【CC】接着VIT那篇论文挖的坑,transfomer能否做为CV领域的backbone,VIT里面只做了分类的尝试,留了检测/语义分割的坑,这篇文章直接回答swin transfomer可以
Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images. To address these differences, we propose a hierarchical Transformer whose representation is computed with Shifted windows
【CC】CV领域对transfomer有两个困难:各种各样的图片尺度, 高分辨率的图片(需要处理的数据量太大). 这个Shifted windows很像一个Conv Block;果然被人称为披着CNN 的 transfomer。
解题思路
Designed for sequence modeling and transduction tasks, the Transformer is notable for its use of attention to model long-range dependencies in the data
【CC】transfomer设计初衷是为了搞定序列模型里面大跨度间元素依赖关系
visual elements can vary substantially in scale, a problem that receives attention in tasks such as object detection. In existing Transformer-based models, tokens are all of a fifixed scale, a property unsuitable for these vision applications.
【CC】在目标检测任务中,各个物体的尺度大小差异非常大;跟NLP里面一个token就是一个词/或者字差别比较大. 所以,现有按照固定尺度作为token去处理图像不太合适,说的就是vit啊!~
There exist many vision tasks such as semantic segmentation that require dense prediction at the pixel level, and this would be intractable for Transformer on high-resolution images, as the computational complexity of its self-attention is quadratic to image size.
【CC】对于语义分割一类的任务,做像素集的估计对transfomer来说计算量太大,为图像分辨率的平方,不可行
To overcome these issues, we propose a general purpose Transformer backbone, called Swin Transformer, which constructs hierarchical feature maps and has linear computational complexity to image size
【CC】这里点明了swim transfomer的计算复杂度相对图片分辨率是线性的

Swin Transformer constructs a hierarchical representation by starting from small-sized patches (outlined in gray) and gradually merging neighboring patches in deeper Transformer layers. The linear computational complexity is achieved by computing self-attention locally within non-overlapping windows that partition an image (outlined in red).
【CC】通过类似FPN的方式对不同的分辨率进行attetion计算,这种层次结构避免了平方级的计算,其大体思路跟FPN非常像
The number of patches in each window is fifixed, and thus the complexity becomes linear to image size. These merits make Swin Transformer suitable as a general-purpose backbone for various vision tasks
【CC】每个需要计算attention的区域*(红色区域)中patch个数是固定的(77),即意味着一个sequcence中的token数是固定的,方便transformer block处理;另外,这种层次结构能够适应不同分辨率的尺度
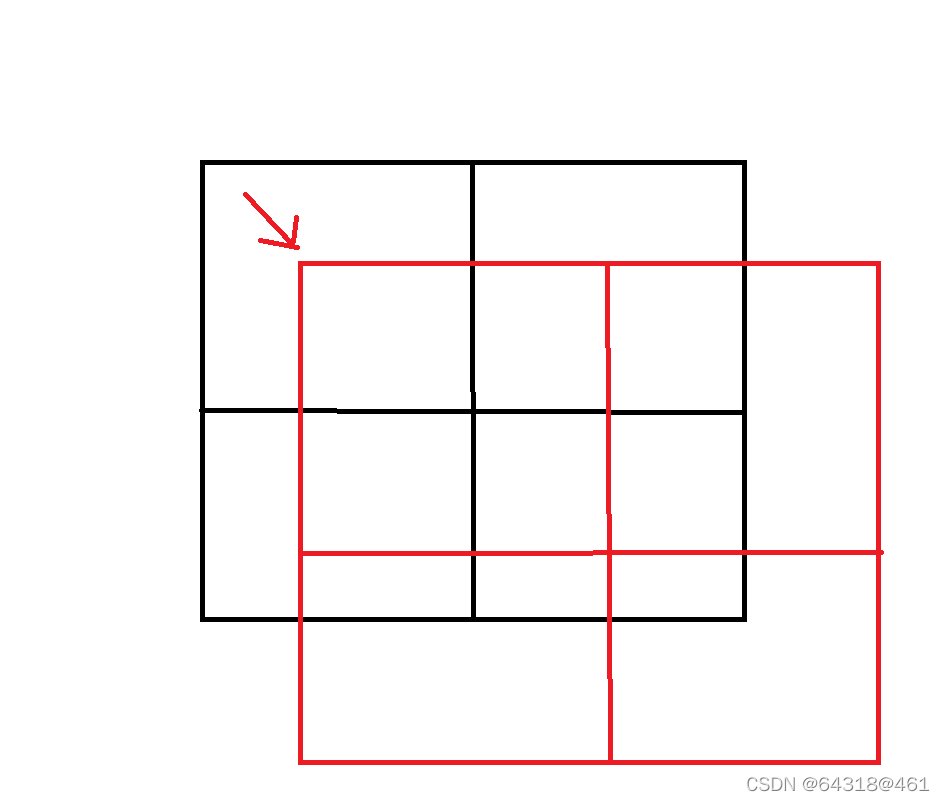
A key design element of Swin Transformer is its shift of the window partition between consecutive self-attention layers, as illustrated in Figure 2. The shifted windows bridge the windows of the preceding layer, providing connections among them that signifificantly enhance modeling power
【CC】Shift window的方式能够提供attention block间交互的能力,提升模型能力

An illustration of the shifted window approach for computing self-attention in the proposed Swin Transformer architecture. In layer l (left), a regular window partitioning scheme is adopted, and self-attention is computed within each window. In
the next layer l + 1 (right), the window partitioning is shifted, resulting in new windows. The self-attention computation in the new windows crosses the boundaries of the previous windows in layer l, providing connections among them.
【CC】L-> L+1层可以形象理解为:在L层切成了4个attention block的patten向右下挪了两个patch的距离,就变成L+1的样子,参见下图
shifted window approach has much lower latency than the sliding window method, yet is similar in modeling power
【CC】作者也试过silding window的方式,对模型能力上差不多,但是shifted window的时延更低,因为在内存上有局部性,方便硬件加速
We hope that Swin Transformer’s strong performance on various vision problems can drive this belief deeper in the community and encourage unifified modeling of vision and language signals.
【CC】作者的这句话不敢苟同,对于NLP和CV的模型同一:更存粹应该是VIT, 这里的变体更像是披着CNN的transfomer
相关工作
The results of ViT on image classification are encouraging, but its architecture is unsuitable for use as a general-purpose backbone network on dense vision tasks or when the input image resolution is high, due to its low-resolution feature maps and the quadratic increase in complexity with image size
【CC】想都能想到肯定要更VIT去做对比,作者在这里Diss VIT确实没毛病:高分辨率处理困难 & 高计算复杂度;论文本身也说了Vit需要大数据训练的问题,个人觉得不是问题的本质;但通过这点提醒我们,使用shift window方式就利用了CNN类似inductive bias: 局部性
Overall Architecture

It first splits an input RGB image into non-overlapping patches by a patch splitting module, like ViT. Each patch is treated as a “token” and its feature is set as a concatenation of the raw pixel RGB values. In our implementation, we use a patch size of 4 × 4 and thus the feature dimension of each patch is 4 × 4 × 3 = 48. A linear embedding layer is applied on this raw-valued feature to project it to an arbitrary dimension (denoted as C).
【CC】一个patch的大小是44,带上RGB 3通道 为 443 = 48, 直接把这48维拉成vector,这一步就把图像分辨率从HW -> H/4 *W/4 , 作为一个token,塞到linear project,得到一个预期长度为C的vector
To produce a hierarchical representation, the number of tokens is reduced by patch merging layers as the network gets deeper. The first patch merging layer concatenates the features of each group of 2 × 2 neighboring patches, and applies a linear layer on the 4C-dimensional concatenated features. This reduces the number of tokens by a multiple of 2×2 = 4 (2× downsampling of resolution), and the output dimension is set to 2C.
【CC】patch merging类似pooling,进行了下采样,降低了分辨率:合并邻近的22个patch,如果不做特征丢失那么通道C应该变成4C,但这里进行了下采样,把通道层应该给出的4C->2C。注意,后边swin transformer block是不进行任何上/下采样的, 另1,这没有像VIT进行postion embeding, 另2 像vit 加上cls token 用来给后面header做输出,如果要做backbone就能这么干,也没必要,直接加全局池化层就好了

【CC】举例说明:一张标准的ImageNet图片为:2242243, 通过本文设置44的patch大小,被patch patition打成了565648的一推token, 送到Linear Emebedding里面将维度变成NN预设的C,这里C= 96,所以,Linear Emebedding出来的是313696的tokens,整个过程类似VIT里面的patch proejct是直接通过Conv完成的;3136这个长度肯定不是普通transfomer能够接纳的,所以这里划定了需要计算attention的区域*(红色区域)中patch个数是固定的(77),那么就有3136/49 = 64个attention block,但是不管怎么算attention transfomer不会对通道维度进行缩放,所以,出来的还是3136*96个vector。这里Stage1就做完了
patch merging

【CC】patch merging的过程如上图
Swin Transformer Blocks

where zˆland zl denote the output features of the (S)WMSA module and the MLP module for block l, respectively; MSA module and the MLP module for block l, respectively; W-MSA and SW-MSA denote window based multi-headself-attention using regular and shifted window partitioning configurations, respectively.
【CC】一个标准的swim tranfomer block形式化描述如上
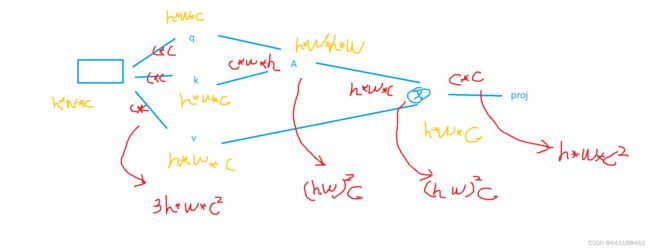
Efficient modeling
Supposing each window contains M × M on an image of h × w patches,M is fixed (set to 7 by default)

【CC】明显W-MSA计算复杂度是要远小于普通MSA的,怎么推导出来的呢? MSA的推导,见下图,W-MSA的推导,把HW换成M即可,不再画了,麻烦
Shift Window & Mask

【CC】想办法把每次计算attention 的area大小保持一致这样计算更高效,移位后A/B/C各自所在的area不应该再计算attention,所以设计了mask达到这个目的;记得计算完了以后再挪回去,因为相对位置的语义信息不能被破坏

【CC】上图是以shift后 左下部分 计算过程分下 mask应该如何设计

【CC】上图是论文作者在git答疑时画出来的4个mask模板
相对位置编码:
二维相对位置编码有机会再介绍
源码参考链接:
https://github.com/microsoft/Swin-Transformer.