构建病毒宿主关系知识图谱
文章目录
- 前言
- 一、图数据库是什么
- 二、数据处理
-
- 2.1 数据下载
- 2.2 数据处理
- 2.3 数据导入
- 三、图的构建
- 四、Reference
前言
大家好✨,这里是bio。世界是由关系构成的。在马克思关于人的定义中提到:“人的本质是一切社会关系的总和”,严格意义上没有任何关系的人类不能成为人类,可见关系的重要性。随着社会的发展,每天都有海量的数据产生,例如:疫情下每天的人口流动,阳性患者密接者分布等。但是传统数据库很难处理关系运算,图数据库应运而生!
看完本文你将了解到:
1.什么是图数据库
2.数据处理的一些方法
3.如何构建你自己的图
一、图数据库是什么
图数据库(Graph DataBase,GDB) 并不是以图片的形式来存储数据,而是以图的形式来存储数据。它是基于图论实现的一种NoSQL数据库,其数据储存结构和数据查询方式都是以图论为基础的。在维基百科中关于图数据库的定义是:
图数据库是一种使用图结构进行语义查询的数据库,用边、节点和属性表示和存储数据。图(或节点或关系)是这个系统的关键概念。图将存储在内的数据与节点和边的集合联系起来,边代表节点之间的关系。这些关系允许存储在内的数据直接联系在一起,在许多实列中,检索只需要一个操作。
举个简单的例子,运行下列语句在Neo4j中,可以得到一个简单的图数据结构。
CREATE (c:Car {name:"BMW"});
CREATE (p:Person {name:"Juliet"});
CREATE (p:Person {name:"Joney"});
MATCH (p:Person {name:"Juliet"}), (x:Car {name:"BMW"}) CREATE (p)-[:DRIVES]->(x);
MATCH (p:Person {name:"Joney"}), (x:Car {name:"BMW"}) CREATE (p)-[:DRIVES]->(x);
MATCH (p:Person {name:"Joney"}), (x:Car {name:"BMW"}) CREATE (p)-[:OWNS]->(x);
MATCH (p:Person {name:"Joney"}), (x:Person {name:"Juliet"}) CREATE (p)-[:LOVES]->(x);
MATCH (p:Person {name:"Joney"}), (x:Person {name:"Juliet"}) CREATE (x)-[:LOVES]->(p);

二、数据处理
2.1 数据下载
数据来源于Virion database。 Virion 是脊椎动物-病毒网络图册,由病毒学家、生态学家和数据科学家组成的跨学科团队建造和筹办的。为预测什么病毒能感染人类、什么动物能被某病毒寄生、什么时候病毒可能在什么地方爆发做出了一份努力。下载链接
完整的代码可以在我的GitHub查看(只包括数据处理,不包括下载代码)。
2.2 数据处理
下载完成后可以看到这是一个巨大的csv文件,如果你的电脑内存较小的话,可能打不开这个文件。里面包含宿主和病毒的TaxID以及是否在NCBI中。所以在开始之前,需要先对数据进行过滤,例如除去TaxID为空和未保存在NCBI中的数据。

数据过滤的代码如下,这只是简单的过滤,为了使后续的操作能够进行。使用二进制读入的原因是因为文件较大,读入速度快。然后对数据进行解码,构建一个方便后续处理的数据框。
import pandas as pd
# you need to input your workpath to utilize the codes
with open('/your_workpath/Virion.csv','rb') as f:
lines = f.readlines()
data_procession = []
for line in lines:
if len(line) < 34:
continue
else:
# use 'ISO-8859-1' to decode
data = line.decode('ISO-8859-1').strip('\n').split('\t')
# filter
if data[3] == '' or data[4] == "FALSE" or data[4] == '':
continue
else:
data_procession.append(data)
# construct a dataframe
data = pd.DataFrame(data_procession[1:-1],columns=data_procession[0])
简单处理之后,提取出VirusTaxID和HostTaxID的列,对其进行去重,利用taxonkit获得对应的物种分类信息。
import os
import pandas as pd
virus_ID = data[['VirusTaxID']]
Host_ID = data[['HostTaxID']]
virus_ID.to_csv('Virus_ID.csv',index=None,header=None)
Host_ID.to_csv('Host_ID.csv',index=None,header=None)
# taking advantage of os.system, you can run bash command in python
os.system('sort Virus_ID.csv | uniq | /home/bio_kang/software/anaconda3/envs/bio/bin/taxonkit reformat -I 1 -f "{p};{c};{o};{f};{g};{s}" -F -t > Virus_taxid.txt')
os.system('sort Host_ID.csv | uniq | /home/bio_kang/software/anaconda3/envs/bio/bin/taxonkit reformat -I 1 -f "{p};{c};{o};{f};{g};{s}" -F -t > Host_taxid.txt')
结果为TaxID后跟随分类信息,而后是分类信息对应的TaxID。而后将其存入csv文件中,最后的结果如下图所示。
with open('Virus_taxid.txt','r') as f:
lines = f.readlines()
virus_taxon_info = {}
virus_taxon_taxid_info = {}
for line in lines:
line = line.strip('\n').split('\t')
taxon = line[1].split(';')
taxid = line[2].split(';')
if len(taxon) !=6:
continue
else:
virus_taxon_info[line[0]] = taxon
if len(taxid) != 6:
continue
else:
virus_taxon_taxid_info[line[0]] = taxid
# write file
write_taxon = pd.DataFrame(virus_taxon_info).T.reset_index()
write_taxon.columns = ['Virus_ID','Phylum','Class','Order','Family','Genus','Species']
write_taxon.to_csv('/home/bio_kang/Learning/graduation/Virus_taxon.csv',index=False)
write_taxid = pd.DataFrame(virus_taxon_taxid_info).T.reset_index()
write_taxid.columns = ['Virus_ID','Phylum_ID','Class_ID','Order_ID','Family_ID','Genus_ID','Species_ID']
write_taxid.to_csv('/home/bio_kang/Learning/graduation/Virus_taxid.csv',index=False)


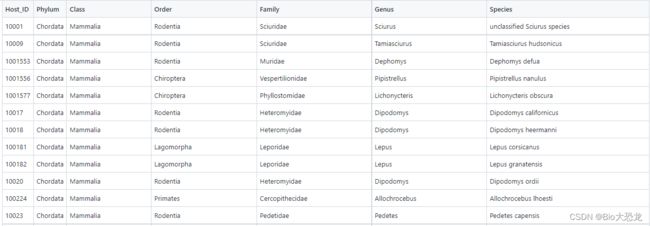
2.3 数据导入
接下来将数据导入Neo4j中。这一步十分的容易,只需要在选中你的Local DBMS→Open folder→Import,然后将你的文件都拖进即可。在拖进之前要将文件全部处理成一一对应的模式,我这一步是在excel中操作的。没有使用函数,只是一些简单的去重工作,同样你可以在python中完成这步工作。

经过处理之后,使用R对得到的信息统计,进行可视化展示。在图七中我们能看到所有的宿主都来自于同一个phylum(门),这是因为Virion数据库中只包含脊椎动物门的宿主数据。而本次获得的数据中包含病毒9456种,宿主3669种。
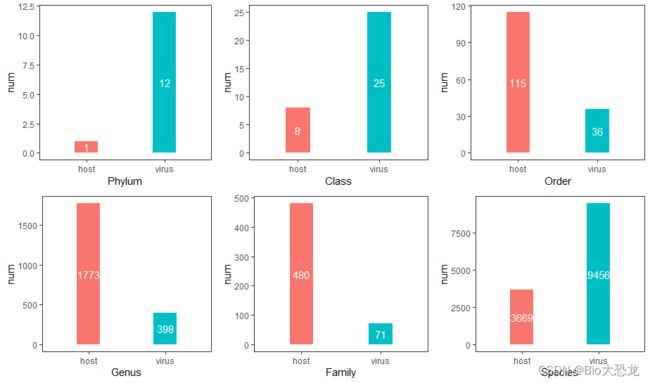
三、图的构建
将处理好的文件置于指定文件夹后,接下来需要将其导入到Neo4j中。因为命令都是类似的,故不赘述。
# you need depend on your data formart
CREATE CONSTRAINT ON (h:Host) ASSERT h.name IS UNIQUE
LOAD CSV WITH HEADER FROM "file:///name.csv" AS row MERGE (n:name {name:row.name})
然后设置关系,就完成了本次任务。
LOAD CSV WITH HEADERS FROM 'file:///host_connections.tsv' AS row MERGE (t:Taxon {name: row.from}) MERGE (v:Taxon {name: row.to}) MERGE (t)-[r:HAS_TAXON]->(v);
四、Reference
1. wiki百科图数据库介绍
2. Carlson CJ, Gibb RJ, Albery GF, Brierley L, Connor R, Dallas T, Eskew EA, Fagre AC, Farrell MJ, Frank HK, de Lara Muylaert R. The Global Virome in One Network (VIRION): an atlas of vertebrate-virus associations. bioRxiv. 2021 Jan 1.
3. taxonkit 教程