文本挖掘之情感分析在网络视频弹幕的应用 ——以《都挺好》弹幕数据为例
文本挖掘之情感分析在网络视频弹幕的应用
——以《都挺好》弹幕数据为例
- 数据爬取
- 1.1数据定位
以腾讯视频《都挺好》为元数据材料,选取2019年3月1日开播以来到2019年4月15日46集的所有弹幕数据为研究对象。打开chrome,F12审查元素,其中以“danmu”开头的数据便是要爬取的元数据。选取所需字段ID,upcount,upername和userVIP_degree。

1.2弹幕网址规律分析
源弹幕网址https://mfm.video.qq.com/danmu?otype=json&callback=jQuery19109123255549841207_1553922882824×tamp=45&target_id=3753912718%26vid%3Dt00306i1e62&count=80&second_count=5&session_key=558401%2C8142%2C1553922887&_=1553922882831,用浏览器打开显示

https://mfm.video.qq.com/danmu?otype=json×tamp=15&target_id=3753912718%26vid%3Dt00306i1e62&count=80,其中timetamp值控制页数的变量,实际表明30秒更新一次弹幕,只需构造步长为30的变化变量来替换timestamp的参数实现批量访问。 - 1.3弹幕内容解析
采用headers伪装,访问页面,如图所示。

图2解析弹幕代码段删去多余的内容及时间戳,最后得到精简的网址内容。遍历所需要的关键数据,如下图所示,得到单集弹幕数据。 图3获取弹幕代码段

-1.4弹幕爬取要
自动爬取每一集,必须先找到构造网址的target_id和后缀的ID。任意一集网页中都能直接找到所有剧集的后缀ID,基于已经爬到的后缀ID,去循环访问每一集,拿到单集对应的target_id,构造出完整的弹幕网页所需的ID。循环爬取target_id:

集齐构成单页弹幕网址所需的target_id,后缀ID,只需要构造两个循环就可以实现完整的弹幕爬取,得到数据集。(其详细代码请见附件1)遍历爬取弹幕历史文件,存入csv中,保存格式为:[‘集数’,‘用户名’,‘会员等级’,‘评论id’,‘内容’,’评论时间点’,‘点赞数’]


数据清洗**
对于缺失数据进行去噪处理,缺失数据所占比例较少(0.61%)直接采用暴力去除方式df=df.loc[df[‘用户名’].notnull(),:]清洗之后,还剩下 117484 个用户发送的 392051 条弹幕,人均发送弹幕量 3.34 条。

图4 缺失弹幕数据(部分)
- 数据可视化
利用python、RStudio、Excel简单的对数据进行可视化分析。

其中发送三条弹幕以下的人数占比83.73%,可以看出大多数人对于弹幕发送都是浅尝辄止,蜻蜓点水。累计贡献了 133331 条弹幕,占到弹幕总数的 34.01%。发送6条以上的弹幕数据占比已经不再攀升。筛选出累积发送弹幕top10的用户(代码见附件二)
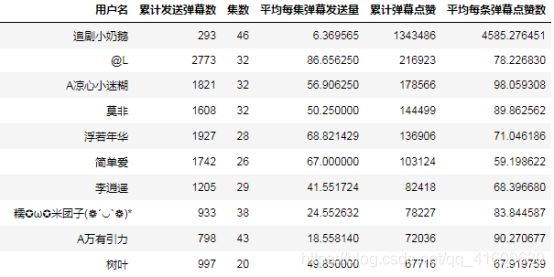
表3 累积发送弹幕top10

用户@L在 46 集的电视剧中,累计发射 2773 条弹幕,平均每集发送 86.66 条。top10的用户累积发送弹幕量都达到了上千条,平均每集发送弹幕数竟达到了40条以上。关于@L弹幕情感向导制作云图可视化,分析他对于电视剧剧情发展的想法。

根据每个用户累计点赞量排序,得到弹幕点赞 TOP10 排行榜,如图所示。前十榜每集基本平均发送20多条数据,其累计点赞量也达到了6万以上。
对高赞的弹幕进行云图可视化分析,分析大家对于电视剧内容发展导向有什么情感共鸣。大家对苏大强热论其人物性格和剧情。弹幕评论紧跟剧情变化,观众可以通过弹幕内容得到情感的共鸣。

高赞弹幕数据,大家原生家庭、重男轻女、苏大强的行为生活和态度议论纷纷,当然也有高赞丽丽是个好媳妇。符合剧情的发展,引起共鸣。弹幕数据也可以反映观看《都挺好》观众的地域分布,一定程度上可以看出中国经济的发展,获取其发送弹幕源数据的定位地址,基于echart图表做空间分析。
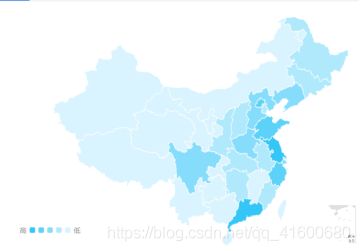

结果表明广东、四川、沿海一带的弹幕评论人数最多,内陆一带弹幕评论人数呈递减的趋势,其中处于top10的弹幕评论省份有广东省、江苏省、北京市、山东省、浙江省、上海市、河南省、辽宁省、河北省、四川省。从实际经济发展状况来看,这些省份的经济实力情况也是较雄厚的。
- 实验模型架构
本文构建了多维情感分类下的弹幕情感词典, 在此基础上参考句子级别的文本情感分析过程, 提出弹幕评论情感分析实验模型,
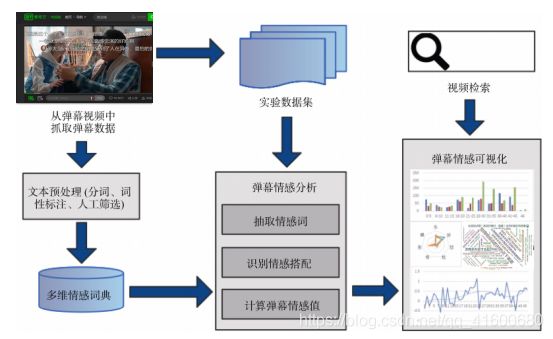
- 构建弹幕多维情感词典
在情感词典构建方面,采用7分类的标准构建弹幕情感词典,情感维度分别是:乐(快乐、安心),好(赞扬、喜爱、感动),怒,愁(悲伤、失望、愧疚、郁闷、尴尬、无奈),惊,恶(厌恶、贬责、烦、讽刺)和惧(慌、恐惧)。其中,“乐”和“好”属于正向情感类,“怒”、“愁”、“惊”、“恶”、“惧”属于负向情感类。情感词实例是从实验数据集中随机抽取的10 000条弹幕评论文本析取而来。首先对弹幕评论文本进行分词处理,并在分词的基础上为每个有效的分词结果标注词性,完成词典语料文本的预处理工作。其次,从形容词、动词和感叹词中筛选出具有明确情感表达的词或短语,按照7种情感维度进行分类。为了确保情感词对弹幕情感的识别效果,暂不考虑情感类别不明确或情感强度较低的情感词。部分弹幕多维情感词典如表所示:

- 抽取情感词
情感词又称评价词语、极性词, 指带有情感倾向性的词语。在句子级别的文本情感分析过程中,提取句子中的情感词是识别主观情感句的关键。本文采用基于多维情感词典的方法对弹幕评论文本中的情感词进行抽取及判别。具体过程包括:参照情感词典对弹幕评论文本中的情感词进行匹配,记录各视频弹幕评论中包含该情感词的弹幕数,即该情感词的词频;根据情感词在多维情感词典中的类别,将其替换为对应的情感类别符号,如表所示:

举例说明, 情感词“渣”形容行为、动作或思想不符合常规伦理道德, 属于情感类别中的“恶”(厌恶、贬责、烦、讽刺)。利用 Excel 表格的“匹配”功能, 在弹幕评论文本中对“渣”进行匹配并记录下该情感词的词频; 通过表格的“替换”功能将弹幕评论文本中的“渣”全部替换为情感类别符
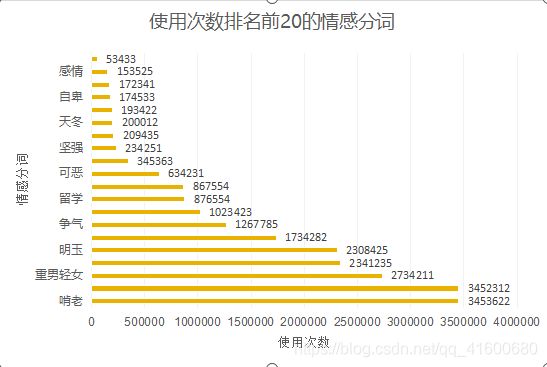
号“【恶】”。选取弹幕中高频出现的人物代号,

简单的加载提取出的情感分词做云图,观察情感导向。(具体代码间附件4)

- 基于情感分析的弹幕数量统计
从实验数据集的评论文本中抽取情感词,计算出每一条主观弹幕句的情感值。根据情感分类和量化的结果对弹幕进行数量统计: 统计实验数据集中的主、客观弹幕数量。各集主观弹幕数所占的比例都集中在20%-35%区间,第11集的主观弹幕比例最高,约占32%;第46集的主观弹幕数比例最低,约占22%,

根据正负情感值对主观弹幕评论进行分类统计。各视频中情感值为0的弹幕所占比例很接近,都小于6%,但正情感值评论和负情感值评论所占比例差异较大。第1集、第31集和第46集中,正负情感值的弹幕数量基本持平;第11集和第44集中, 正情感值的弹幕较多,
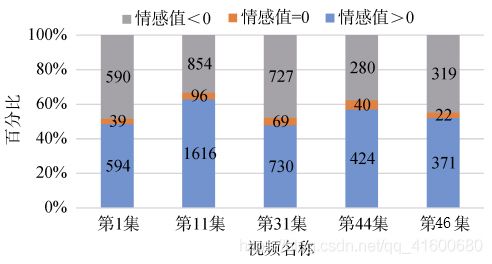
l 根据多维情感类别对主观弹幕评论进行分类统计, 如表

- 情感趋势线
为研究各集视频中弹幕评论的情感趋势,绘制横轴为时间、纵轴为二元情感值的“时间–弹幕情感值”曲线。时间轴的单位为分钟,曲线上各点的取值为对应分钟内所有主观弹幕的情感平均值。第1集、第11集、第31集和第44集视频评论的情感值曲线如图
第1集

第11集

第31集&&44集

对每一条评价的内容进行情感打分,用情感分值来验证上述问题(分值在 0-1 之间,越靠近 0 负面倾向越强,越接近 1 则情感越情面)。

l 大强开局不错,和明玉持平,但凭借倪老师“作死小能手”的实力诠释,让情感分值迅速走低,11 集的低点正式印证了大强的“癫疯之作”,之后分值在 0.38 左右徘徊。随着“蔡根花宝贝”梗的出现,“嘲讽”替代了指责,让分值略微上浮(情感打分对于高级黑式嘲讽难以准确判断)。最后老年痴呆发病后大强对明玉的爱让分值一举超过 0.5,达到历史峰值,成功上岸。
l 明玉是原生家庭的受害者,也是一个靠自己成功的女强人,前期爱恨分明,情感分值一度飙到 0.59(超过其他所有角色),18 集开始的买房纷争,网友纷纷表示强烈同情(例:明玉不能像十年前一样别理他们吗?情感分值只有 0.041),这让明玉相关的情感分值严重走低,随后弹幕主旋律仍以叫好和同情为主。
l 明成的情感分值走势更有意思,开局最低,靠欺负妹妹让分值迅速降低,可谓“人人喊打”,后面则分值飙升,一度追上明玉,主要是因为明成期望值已经极低,但是他宠老婆的行为得到观众认可。中期本色挨骂,降至低谷。27 集明成情感分值再次超过 0.5,竟然是因为明成想吓走大强进行的一系列骚操作(尤其是广场舞)。再后来就是明成幡然悔悟,走上正轨,分值在稳定在 0.45 左右,也算成功洗白。按照不同人物相关联系与出场顺序做情感分析图。