fliebeat+kafka ELK日志分析平台实战
一、ELK Stack 架构
1、ELK Stack简介
ELK 不是一款软件,而是 Elasticsearch、Logstash 和 Kibana 三种软件产品的首字母缩写。这三者都是开源软件,通常配合使用,而且又先后归于 Elastic.co 公司名下,所以被简称为 ELK Stack。根据 Google Trend 的信息显示,ELK Stack 已经成为目前最流行的集中式日志解决方案。
Elasticsearch:分布式搜索和分析引擎,具有高可伸缩、高可靠和易管理等特点。基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储、搜索和分析操作。通常被用作某些应用的基础搜索引擎,使其具有复杂的搜索功能;
Logstash:数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置;
Kibana:数据分析和可视化平台。通常与 Elasticsearch 配合使用,对其中数据进行搜索、分析和以统计图表的方式展示;
Filebeat隶属于Beats。目前Beats包含以下几种种工具:
- filebeat(搜集日志文件)
- Metricbeat(将系统和服务的指标和统计数据(例如 CPU、内存、Redis 等等)发送至 Elasticsearch(或 Logstash))
- Packetbeat(搜集网络流量数据)
- Winlogbeat(搜集 Windows 事件日志数据)
- Auditbeat(收集 Linux 审计框架数据,对消息进行解析和标准化,并检测文件的完整性)
- Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
- Heartbeat(通过主动探测来监控服务可用性)
- Functionbeat(针对云端数据的无服务器式全新采集器)
redis缓存或中间件本次没有添加,如果您的业务需要,自己加入即可,主要功能解耦、异步提高效率。也可以对 Kubernetes 集群进行日志的收集,具体的应用,请查阅K8S专栏。
免费且开放的搜索:Elasticsearch、ELK 和 Kibana 的开发者 | Elastic
Elasticsearch官网:
Elasticsearch:官方分布式搜索和分析引擎 | Elastic
Elasticsearch Reference [5.6] | Elastic
Kibana官网:
Kibana:数据的探索、可视化和分析 | Elastic
Kibana User Guide [5.5] | Elastic
Logstash官网:
Logstash:收集、解析和转换日志 | Elastic
Logstash Reference [5.6] | Elastic
Filebeat官网:
Filebeat:轻量型日志分析与 Elasticsearch | Elastic
Filebeat Reference [5.6] | Elastic
elasticsearch中文社区:
Elastic 中文社区
2、Elastic Stack
Elastic Stack 是 原 ELK Stack 在 5.0 版本加入 Beats 套件后的新称呼。
Elastic Stack 在最近两年迅速崛起,成为机器数据分析,或者说实时日志处理领域,开源界的第一选择。和传统的日志处理方案相比,Elastic Stack 具有如下几个优点:
- 处理方式灵活。Elasticsearch 是实时全文索引,不需要像 storm 那样预先编程才能使用;
- 配置简易上手。Elasticsearch 全部采用
JSON接口,Logstash 是 Ruby DSL 设计,都是目前业界最通用的配置语法设计; - 检索性能高效。虽然每次查询都是实时计算,但是优秀的设计和实现基本可以达到全天数据查询的秒级响应;
- 集群线性扩展。不管是 Elasticsearch 集群还是 Logstash 集群都是可以线性扩展的;
- 前端操作炫丽。Kibana 界面上,只需要点击鼠标,就可以完成搜索、聚合功能,生成炫丽的仪表板。
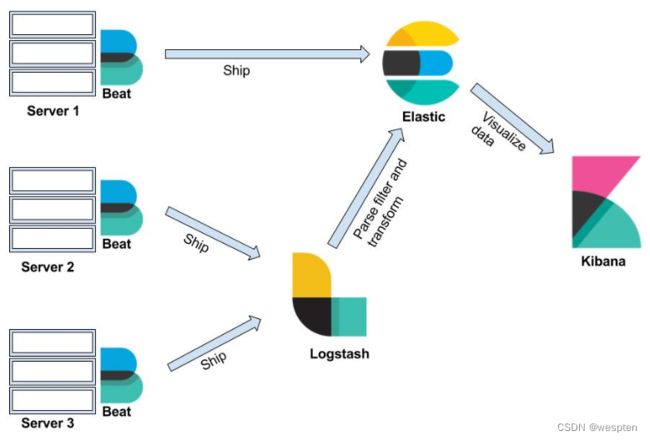
图样功能展示:
3、ELK Stack 常见架构
1)最简单架构
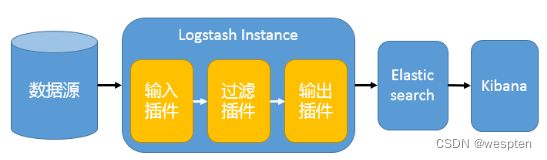
这是最简单的一种ELK架构方式。优点是搭建简单,易于上手。缺点是Logstash耗资源较大,运行占用CPU和内存高。另外没有消息队列缓存,存在数据丢失隐患。建议供学习者和小规模集群使用。
在这种架构中,只有一个 Logstash、Elasticsearch 和 Kibana 实例。Logstash 通过输入插件从多种数据源(比如日志文件、标准输入 Stdin 等)获取数据,再经过滤插件加工数据,然后经 Elasticsearch 输出插件输出到 Elasticsearch,通过 Kibana 展示。
2)Logstash作为日志搜集器
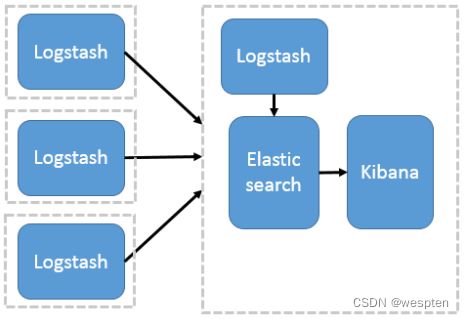
这种架构是对上面架构的扩展,把一个 Logstash 数据搜集节点扩展到多个,分布于多台机器,将解析好的数据发送到 Elasticsearch server 进行存储,最后在 Kibana 查询、生成日志报表等。
这种架构,通过logstash收集日志,Elasticsearch分析日志,然后在Kibana(web界面)中展示。这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,往往在生产中很少使用,比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。
3)Elasticsearch + Logstash + filebeat + Kibana
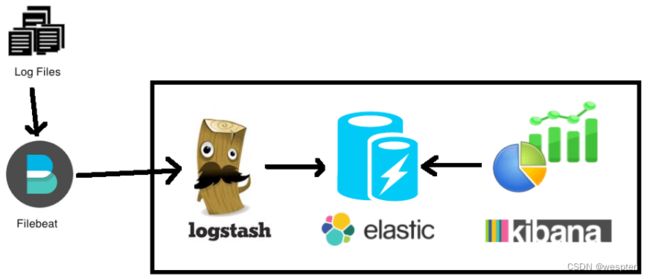
与上一种架构相比,这种架构增加了一个filebeat模块。filebeat是一个轻量的日志收集代理,用来部署在客户端,优势是消耗非常少的资源(较logstash), 所以生产中,往往会采取这种架构方式,但是这种架构有一个缺点,当logstash出现故障, 会造成日志的丢失。
4)Beats作为日志搜集器
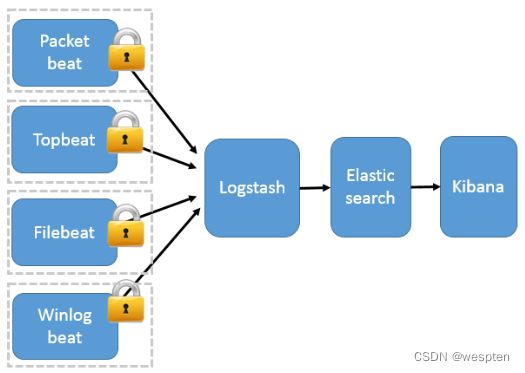
这种架构引入 Beats 作为日志搜集器。目前 Beats 包括六种:
Filebeat(轻量型日志采集器,用于转发与汇总日志与文件)
Metricbeat(用于从系统和服务收集指标。从 CPU 到内存,从 Redis 到 Nginx,Metricbeat 能够以一种轻量型的方式,输送各种系统和服务统计数据。)
Packetbeat(用于深挖网线上传输的数据,了解应用程序动态。Packetbeat 是一款轻量型网络数据包分析器,能够将数据发送至 Logstash 或 Elasticsearch。);
Winlogbeat(用于密切监控基于 Windows 的基础架构上发生的事件。Winlogbeat 能够以一种轻量型的方式,将 Windows 事件日志实时地流式传输至 Elasticsearch 和 Logstash。)
Auditbeat(收集您的 Linux 审计框架的数据,监控文件完整性。Auditbeat 实时的采集这些事件,然后发送到 Elastic Stack 用以进一步分析。)
Heartbeat(通过主动探测来监控服务可用性。)
Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户。这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。
因此这种架构适合对数据安全性要求较高,同时各服务器性能比较敏感的场景。
5)引入消息队列机制的架构
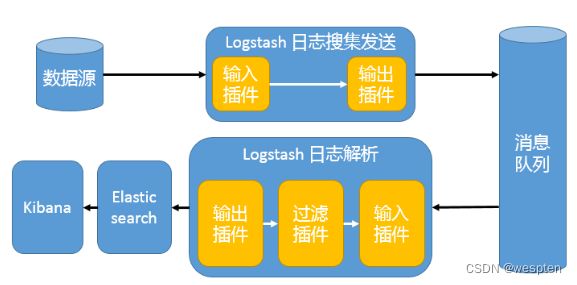
在之前版本Beats还不支持输出到消息队列时,在消息队列前后两端只能是 Logstash 实例。这种架构使用 Logstash 从各个数据源搜集数据,然后经消息队列输出插件输出到消息队列中。目前 Logstash 支持 Kafka、Redis、RabbitMQ 等常见消息队列。然后 Logstash 通过消息队列输入插件从队列中获取数据,分析过滤后经输出插件发送到 Elasticsearch,最后通过 Kibana 展示。
这种架构适合于日志规模比较庞大的情况。但由于 Logstash 日志解析节点和 Elasticsearch 的负荷比较重,可将他们配置为集群模式,以分担负荷。引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性,但依然存在 Logstash 占用系统资源过多的问题。
6) Elasticsearch + Logstash + filebeat + redis
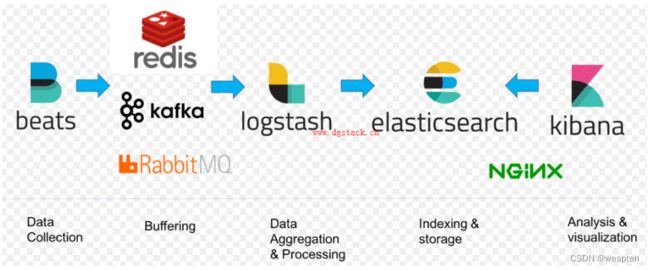
Kibana+Elasticsearch + Logstash + filebeat + redis(也可以是其他中间件,比如kafka)。
这种架构是完善版,通过增加中间件,来避免数据的丢失。当Logstash出现故障,日志还是存在中间件中,当Logstash再次启动,则会读取中间件中积压的日志。目前我司使用的就是这种架构,我个人也比较推荐这种方式。
二、fliebeat+kafka的ELK日志分析平台搭建
1、拓扑环境

当前结构,Filebeat部署在需要收集日志的机器上,收集日志,输出到zk+kakfa集群这个中间件中。logstash从kafka集群消费信息,并根据配置内容,进行格式转化和过滤,整理好的数据会发给elastic进行存储。elastic能对大容量的数据进行接近实时的存储、搜索和分析操作。最后由kibana提供web界面,调用elastic做数据分析,然后展示出来。
注意点:
- filebeat启动后,只会读取最新输入的日志,类似tail -f;
- kafka集群的内容,logstash读取一条,就会消失一条,不会造成重复读取;
- 这套系统里,只有elastic存储数据;
当前用5台机器模拟,实际可使用2-3台,将zk+kafka集群每台都进行部署,也可以1台,部署多实例。
[nginx服务]
主机名 = nginx-server
系统 = centos-7.3
地址 = 1.1.1.1
软件 = nginx-1.8 80
filebeat-7.4.2
[zk+kafka集群]
主机名 = kafka-1
系统 = centos-7.3
地址 = 1.1.1.2
软件 = jdk-1.8
zookeeper-3.5 2181
kafka-2.0.0 9092
主机名 = kafka-2
系统 = centos-7.3
地址 = 1.1.1.3
软件 = jdk-1.8
zookeeper-3.5 2181
kafka-2.0.0 9092
[elasticsearch]
主机名 = elastic-server
系统 = centos-7.3
地址 = 1.1.1.4
软件 = jdk-1.8
elasticsearch-7.4.2 9200
[logstash+kibana]
主机名 = lk-server
系统 = centos-7.3
地址 = 1.1.1.5
软件 = jdk-1.8
logstash-7.4.2 9600
kibana-7.4.2 5601注意事项:
- filebeat的版本要一致,在官网都有对应的包;
- filebeat连接kafka的版本,是有支持范围的,可查看官方文档filebeat-kafka配置;
- 不同版本elk需要的jdk版本也不同,需要看好说明;
2、日志分析平台部署
1)配置kafka集群
操作服务器(kafka-1,kafka-2):
- 这里使用2台组建kafka集群,可根据需求添加或删减节点。部署可查看文章kafka集群部署
- 按照上述连接,启动并测试好kafka集群,确保可正常使用
2)配置日志输出端
操作服务器(nginx-server)
1. Nginx作为日志输出端,这里也可以用自定义文件代替,然后手动插入内容
yum -y install nginx-1.8若没有包,可扩展epel或者源码安装nginx-1.6
2. 启动并本地访问,促使产生日志
systemctl start nginx
curl http://127.0.0.1
cat /var/log/nginx/access.log3. 安装filebeat
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.4.2-x86_64.rpm
rpm -vi filebeat-7.4.2-x86_64.rpm4. 建立文件夹,这里使用自建立的配置文件,方便修改维护
mkdir conf
cd conf建立filebeat配置文件,格式一定要对齐,因为是yml格式的。启动后,filebeat会在kafka中建立一个叫nginx-log的topic:
vim filebeat-nginx.yml
filebeat.inputs:
- type: log
paths:
- /var/log/nginx/access.log
output.kafka:
hosts: ["1.1.1.2:9092", "1.1.1.3:9092"]
topic: 'nginx-log'
5. 启动filebeat,这里会把启动日志输出到当前目录filebeat.log文件中,方便查看。
nohup /usr/share/filebeat/bin/filebeat -e -c filebeat-nginx.yml &>> filebeat.log &若不是这个地址,可以用如下命令,去查找这个命令位置在哪:
rpm -ql filebeat6. 等半分钟,然后查看filebeat进程和日志,是否启动有问题:
ps -aux |grep filebeat
查看日志,没有异常情况,就可以进行下一步了:
cat filebeat.log7. 写入日志
curl http://127.0.0.1操作服务器(kafka-1)。
8. kafka中应该有新的topic nginx-log产生,test是创建集群时,测试功能创建的
cd /usr/local/kafka
bin/kafka-topics.sh --list --zookeeper localhost:2181
查看topic里的消息内容,可以看到日志信息的:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic nginx-log --from-beginning
3)配置logstash
操作服务器(lk-server):
1. 先安装jdk-1.8
yum install java-1.8.0 -y2. 下载logstash的二进制包并部署
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.4.2.tar.gz
tar -xf logstash-7.4.2.tar.gz
mv logstash-7.4.2 /usr/local/logstash3. 建立文件夹,这里使用自建立的配置文件,方便修改维护
mkdir conf
cd conf建立logstash配置文件,格式一定要对齐,因为是yml格式的。启动后会从kafka取数据,并传输给elasticsearch,中间是对nginx的日志数据,进行正则分段:
vim logstash-nginx.yml
input {
kafka {
auto_offset_reset => "latest"
bootstrap_servers => "1.1.1.2:9092,1.1.1.3:9092"
topics => ["nginx-log"]
group_id => "logstash-file"
codec => "json"
}
}
filter {
grok {
match => {
"message" => "%{IPORHOST:clientip} \[%{HTTPDATE:time}\] \"%{WORD:verb} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:http_status_code} %{NUMBER:bytes} \"(?\S+)\" \"(?\S+)\" \"(?\S+)\""
}
}
}
output {
elasticsearch {
hosts => ["192.168.56.106:9200"]
index => "nginx-%{+YYYY.MM.dd}"
}
}
4. 启动logstash,这里会把启动日志输出到当前目录logstash.log文件中,方便查看
nohup /usr/local/logstash/bin/logstash -f logstash-nginx.yml &>> logstash.log &5. 等半分钟,然后查看logstash进程和日志,是否启动有问题
ps -aux|grep logstash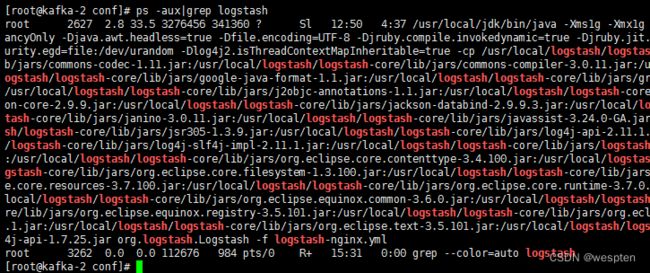
进程是启动着的,则查看日志,看看有没有异常:
cat logstash.log4)配置elasticsearch
操作服务器(elastic-server)
1. 先安装jdk-1.8
yum install java-1.8.0 -y2. 下载elasticsearch的二进制包,直接解压即用
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.4.2-linux-x86_64.tar.gz
tar -xf elasticsearch-7.4.2-linux-x86_64.tar.gz
mv elasticsearch-7.4.2-linux-x86_64 /usr/local/elastic3. 修改elasticsearch的配置文件
vim /usr/local/elastic/config/elasticsearch.yml
cluster.name: nginx-elk
node.name: node-1
cluster.initial_master_nodes: node-1
path.data: /data
path.logs: /var/log/elastic
bootstrap.memory_lock: false
network.host: 0.0.0.0
http.port: 92004. 创建数据目录和日志目录
mkdir /data
mkdir /var/log/elastic
groupadd elastic
useradd -g elastic elastic
chown -R elastic:elastic /data /var/log/elastic5. 修改启动内存,一般为内存的1/2
vim /usr/local/elastic/config/jvm.options
-Xms512m
-Xmx512m6. 切换到elastic,启动服务
su - elastic启动后查看日志,这个要等一会,会慢慢刷出来,如果到最后直接退出了,就是有报错,没通过预检查,需要将报错条目找出来,按照文档elastic报错解析进行解决。
/usr/local/elastic/bin/elasticsearch
若都符合要求,会卡在日志界面,使用ctl + c强制停止,然后用如下命令在后台启动:
/usr/local/elastic/bin/elasticsearch -d5)配置kibana
操作服务器(lk-server)
1. 下载二进制包,解压即用
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.4.2-linux-x86_64.tar.gz
tar -xf kibana-7.4.2-linux-x86_64.tar.gz
mv kibana-7.4.2-linux-x86_64 /usr/local/kibana2. 修改kibana配置文件
vim /usr/local/kibana/config/kibana.yml
server.host: "1.1.1.5"
server.port: 5601
server.name: "testlog"
xpack.reporting.encryptionKey: "a_random_string"
xpack.security.encryptionKey: "something_at_least_32_characters"
elasticsearch.hosts: "http://1.1.1.4:9200"3. 启动kibana,如果是root启动,要加允许参数
/usr/local/kibana/bin/kibana --allow-root查看输出是否有error项,如果是warning则问题不大,只是一些插件之类的没加载,可正常使用。错误和警告解决可查阅kibana报错说明解决
若都符合要求,会卡在日志界面,使用ctl + c强制停止,然后用如下命令在后台启动:
nohup /usr/local/kibana/bin/kibana --allow-root &>> kibana.log &4. 查看elasticsearch的索引,是否kibana使用了elasticsearch建立默认索引:
curl http://1.1.1.4:9200/_cat/indices
5. 访问nginx,制造一些访问记录
curl http://1.1.1.1稍等一会,再查看elastichsearch记录,会有之前在logstash输出部分,index选项所设置的nginx-日期的索引名:

这里green表示没问题,yellow表示接受到数据了,但没有做副本,read表示有问题,没接受到数据。
3、kibana图形操作
1)建立索引
1. 添加新的日志采集项,点击Management-> Index Patterns,比如添加nginx系统日志。注意后面的不要忘了。
这里创建nginx并且设置的是@timestamp为索引匹配,后面的数据会根据这个时间戳查询
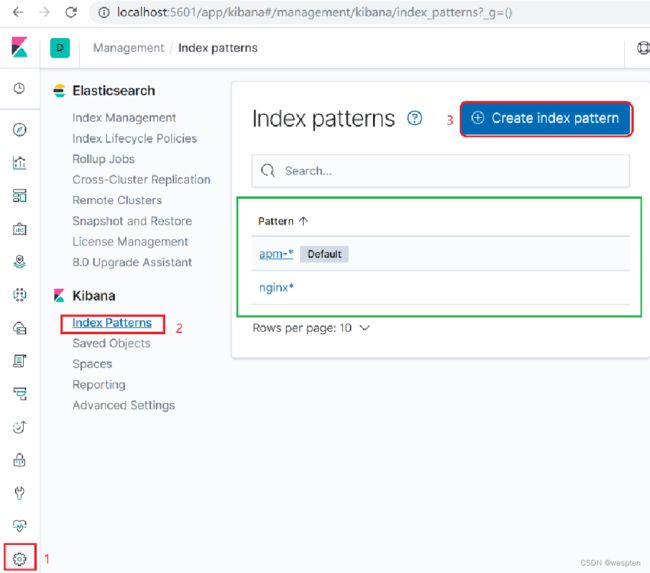
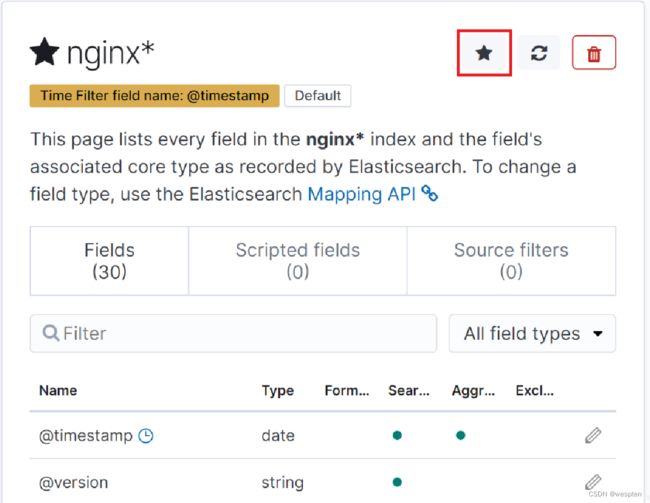
2. 默认情况下,kibana需要设置一个默认索引
设置默认索引,点击五角星图标即可,这样在其他模块中会自动根据默认索引显示出需要的界面,否则空索引是没有界面使用的。
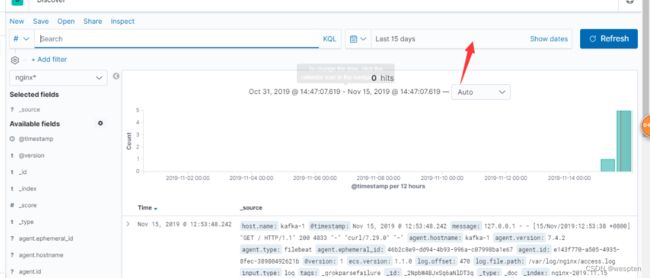
3. 点击discover,则会显示默认索引的工资空间,显示的数据默认是15分钟,你可以自己调整时间段后refresh刷新查询到你想要的数据。如果你选择的索引模式配置了time字段,则文档随时间的分布将显示在页面顶部的直方图中。
这里要把时间设置为一天内,不然可能不会显示数据:
2)设置图形展示
1. 选择创建新的可视化图形
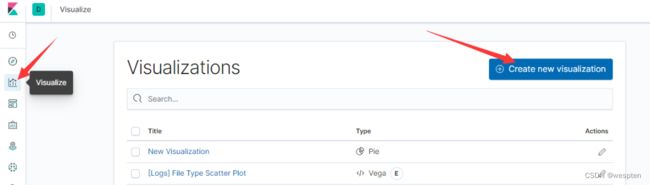
2. 选择饼状图
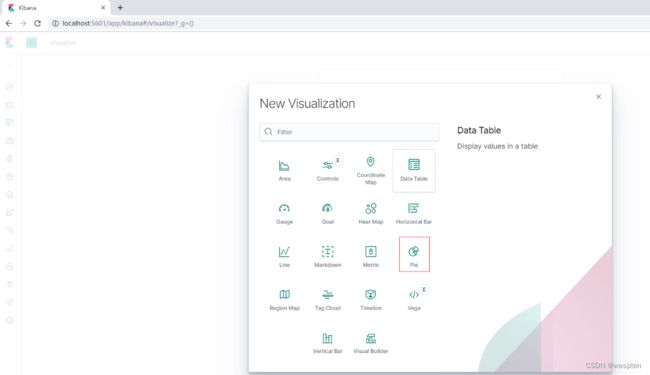
3. 选择nginx日志的索引
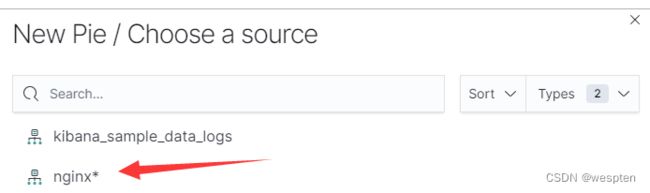
4. 选择add添加一个条件进行筛选
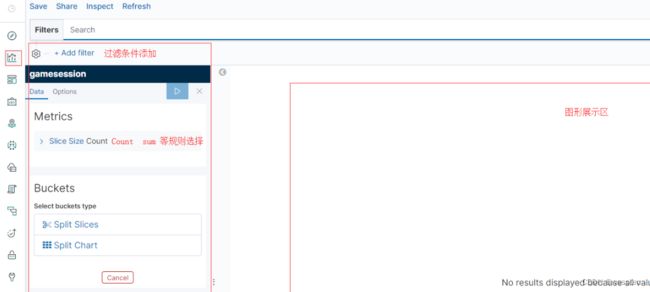
5. 选择message,这个是在logastch中设置的,属于粗略设置,这个列保存了整个访问记录。这里匹配本地127访问的记录,进行筛选。
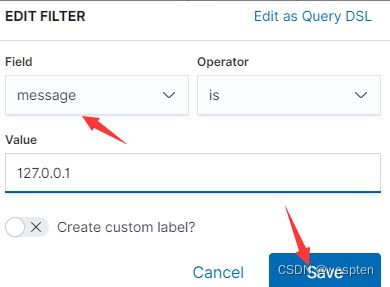
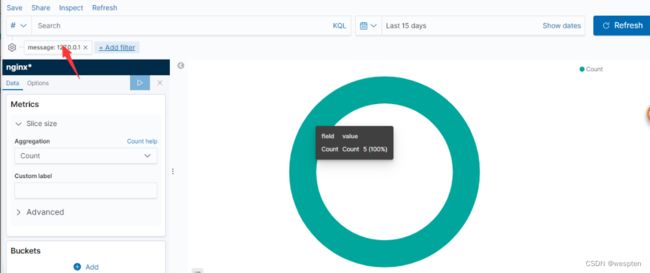
6. 可以看到一共7次访问,这里只记录了5次
三、filebeat配置
1、输出到kafka集群中
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/admin/taobao-tomcat-production-7.0.59.3/logs/catalina.out
fields:
local_type: 'tomcat' #这些都是附加的标签
local_ip: 1.1.1.1
local_host: 'prod_商品_1'
fields_under_root: true #将标签放到顶头,不然在message字段里
multiline.pattern: '^20' #20开头和20开头之间的算作一行,具体根据日志情况
multiline.negate: true
multiline.match: after
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
output.kafka:
enabled: true
hosts: ["1.1.1.1:9092","1.1.1.2:9092","1.1.1.3:9092"] #kafka集群地址
topic: 'tomcat-server-log' #topic名
2、配置详解
input配置段:
#每一个prospectors,起始于一个破折号”-“
filebeat.prospectors:
#默认log,从日志文件读取每一行。stdin,从标准输入读取
- input_type: log
#日志文件路径列表,可用通配符,不递归
paths: - /var/log/*.log
#编码,默认无,plain(不验证或者改变任何输入), latin1, utf-8, utf-16be-bom, utf-16be, utf-16le, big5, gb18030, gbk, hz-gb-2312, euc-kr, euc-jp, iso-2022-jp, shift-jis
encoding: plain
#匹配行,后接一个正则表达式列表,默认无,如果启用,则filebeat只输出匹配行,如果同时指定了多行匹配,仍会按照include_lines做过滤
include_lines: [‘^ERR’, ‘^WARN’]
#排除行,后接一个正则表达式的列表,默认无
#排除文件,后接一个正则表达式的列表,默认无
exclude_lines: [“^DBG”]
#排除更改时间超过定义的文件,时间字符串可以用2h表示2小时,5m表示5分钟,默认0
ignore_older: 5m
#该type会被添加到type字段,对于输出到ES来说,这个输入时的type字段会被存储,默认log
document_type: log
#prospector扫描新文件的时间间隔,默认10秒
scan_frequency: 10s
#单文件最大收集的字节数,单文件超过此字节数后的字节将被丢弃,默认10MB,需要增大,保持与日志输出配置的单文件最大值一致即可
max_bytes: 10485760
#多行匹配模式,后接正则表达式,默认无
multiline.pattern: ^[
#多行匹配模式后配置的模式是否取反,默认false
multiline.negate: false
#定义多行内容被添加到模式匹配行之后还是之前,默认无,可以被设置为after或者before
multiline.match: after
#单一多行匹配聚合的最大行数,超过定义行数后的行会被丢弃,默认500
multiline.max_lines: 500
#多行匹配超时时间,超过超时时间后的当前多行匹配事件将停止并发送,然后开始一个新的多行匹配事件,默认5秒
multiline.timeout: 5s
#可以配置为true和false。配置为true时,filebeat将从新文件的最后位置开始读取,如果配合日志轮循使用,新文件的第一行将被跳过
tail_files: false
#当文件被重命名或被轮询时关闭重命名的文件处理。注意:潜在的数据丢失。请务必阅读并理解此选项的文档。默认false
close_renamed: false
#如果文件不存在,立即关闭文件处理。如果后面文件又出现了,会在scan_frequency之后继续从最后一个已知position处开始收集,默认true
close_removed: true
#每个prospectors的开关,默认true
enabled: true
#后台事件计数阈值,超过后强制发送,默认2048
filebeat.spool_size: 2048
#后台刷新超时时间,超过定义时间后强制发送,不管spool_size是否达到,默认5秒
filebeat.idle_timeout: 5s
#注册表文件,同logstash的sincedb,记录日志文件信息,如果使用相对路径,则意味着相对于日志数据的路径
filebeat.registry_file: ${path.data}/registry
#定义filebeat配置文件目录,必须指定一个不同于filebeat主配置文件所在的目录,目录中所有配置文件中的全局配置会被忽略
filebeat.config_dir
通用配置段:
#配置发送者名称,如果不配置则使用hostname
name:
#标记tag,可用于分组
tags: [“service-X”, “web-tier”]
#添加附件字段,可以使values,arrays,dictionaries或者任何嵌套数据
fields:
#处理管道中单个事件内的队列大小,默认1000
queue_size: 1000
#设置最大CPU数,默认为CPU核数
max_procs:
output.elasticsearch:
#启用模块
enabled: true
#ES地址
hosts: [“localhost:9200”]
#gzip压缩级别,默认0,不压缩,压缩耗CPU
compression_level: 0
#每个ES的worker数,默认1
worker: 1
#可选配置,ES索引名称,默认filebeat-%{+yyyy.MM.dd}
index: “filebeat-%{+yyyy.MM.dd}”
#可选配置,输出到ES接收节点的pipeline,默认无
pipeline: “”
#可选的,HTTP路径,默认无
path: “/elasticsearch”
#http代理服务器地址,默认无
proxy_url: http://proxy:3128
#ES重试次数,默认3次,超过3次后,当前事件将被丢弃
max_retries: 3
#对一个单独的ES批量API索引请求的最大事件数,默认50
bulk_max_size: 50
#到ES的http请求超时时间,默认90秒
timeout: 90
output.logstash:
#启用模块
enabled: true
#logstash地址
hosts: [“localhost:5044”]
#每个logstash的worker数,默认1
worker: 1
#压缩级别,默认3
compression_level: 3
#负载均衡开关,在不同的logstash间负载
loadbalance: true
#在处理新的批量期间,异步发送至logstash的批量次数
pipelining: 0
#可选配置,索引名称,默认为filebeat
index: ‘filebeat’
#socks5代理服务器地址
proxy_url: socks5://user:password@socks5-server:2233
#使用代理时是否使用本地解析,默认false
proxy_use_local_resolver: false
output.redis:
#启用模块
enabled: true
#logstash地址
hosts: [“localhost:6379”]
#redis地址,地址为一个列表,如果loadbalance开启,则负载到里表中的服务器,当一个redis服务器不可达,事件将被分发到可到达的redis服务器
worker: 1
#redis端口,如果hosts内未包含端口信息,默认6379
port: 6379
#事件发布到redis的list或channel,默认filebeat
key: filebeat
#redis密码,默认无
password:
#redis的db值,默认0
db: 0
#发布事件使用的redis数据类型,如果为list,使用RPUSH命令(生产消费模式)。如果为channel,使用PUBLISH命令{发布订阅模式}。默认为list
datatype: list
#为每个redis服务器启动的工作进程数,会根据负载均衡配置递增
worker: 1
#负载均衡,默认开启
loadbalance: true
#redis连接超时时间,默认5s
timeout: 5s
#filebeat会忽略此设置,并一直重试到全部发送为止,其他beat设置为0即忽略,默认3
max_retries: 3
#对一个redis请求或管道批量的最大事件数,默认2048
bulk_max_size: 2048
#socks5代理地址,必须使用socks5://
proxy_url:
#使用代理时是否使用本地解析,默认false
proxy_use_local_resolver: false
Paths配置段:
filebeat安装目录,为其他所有path配置的默认基本路径,默认为filebeat二进制文件的本地目录
path.home:
#filebeat配置路径,主配置文件和es模板的默认基本路径,默认为filebeat家目录
path.config: ${path.home}
#filebeat数据存储路径,默认在filebeat家目录下
path.data: ${path.home}/data
#filebeat日志存储路径,默认在filebeat家目录下
path.logs: ${path.home}/logs
logging配置段:
#有3个可配置的filebeat日志输出选项:syslog,file,stderr
#windows默认输出到file
#设定日志级别,可设置级别有critical, error, warning, info, debug
logging.level: info
#开启debug输出的选择组件,开启所有选择使用[“*”],其他可用选择为”beat”,”publish”,”service”
logging.selectors: [ ]
#输出所有日志到syslog,默认为false
logging.to_syslog: true
#定期记录filebeat内部性能指标,默认true
logging.metrics.enabled: true
#记录内部性能指标的周期,默认30秒
logging.metrics.period: 30s
#输出所有日志到file,默认true
logging.to_files: true
#日志输出的文件配置
logging.files:
#配置日志输出路径,默认在家目录的logs目录
path: /var/log/filebeat
#filebeat #日志文件名
name:
#日志轮循大小,默认10MB
rotateeverybytes: 10485760
#日志轮循文件保存数量,默认7
keepfiles: 7
四、Elasticsearch配置
1、elastic-head视图插件
ealsticsearch只是后端提供各种api,可以添加索引查看数据等,但需要在命令行操作,elasticsearch-head是一个基于node.js的前端工程,可以提供WEB方式的信息查看和各种API的视图化操作。
安装:
1. nodejs安装
wget https://nodejs.org/dist/v10.9.0/node-v10.9.0-linux-x64.tar.xz
tar xf node-v10.9.0-linux-x64.tar.xz
echo 'PATH=$PATH:/usr/local/node-v10.9.0-linux-x64/bin' >> /etc/profile
source /etc/profile
2. phantomjs安装配置
Wget https://github.com/Medium/phantomjs/releases/download/v2.1.1/phantomjs-2.1.1-linux-x86_64.tar.bz2
yum -y install bzip2
tar –jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2
echo 'export PATH=$PATH:/usr/local/phantomjs-2.1.1-linux-x86_64/bin' >> /etc/profile
source /etc/profile
3. elasticsearch-head安装
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install -g cnpm --registry=https://registry.npm.taobao.org
cnpm install
4. 启动
npm run start
open http://localhost:9100/
5. elasticsearch-head发现主机 并连接
修改elasticsearch.yml并重启:
http.cors.enabled: true
http.cors.allow-origin: "*"
使用:
1)状态显示
仔细观察,我们会发现客户端默认连接的是我们elasticsearch的默认路径。而此时elasticsearch服务未启动,所以集群健康值是未连接。
集群健康值的几种状态如下:
- 绿颜色,最健康的状态,代表所有的分片包括备份都可用;
- 黄颜色,基本的分片可用,但是备份不可用(也可能是没有备份);
- 红颜色,部分的分片可用,表明分片有一部分损坏。此时执行查询部分数据仍然可以查到,遇到这种情况,还是赶快解决比较好;
- 灰色,未连接到elasticsearch服务;
2)集群概览
1. 此时,我们启动elasticsearch服务,重新刷新浏览器,发现集群健康值变成了绿色,代表集群很健康,如下:
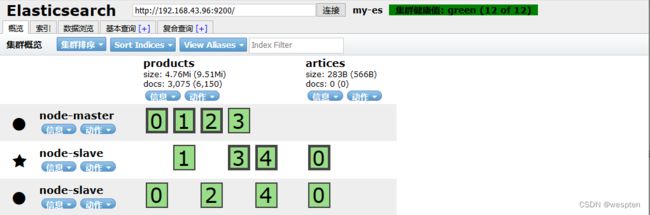
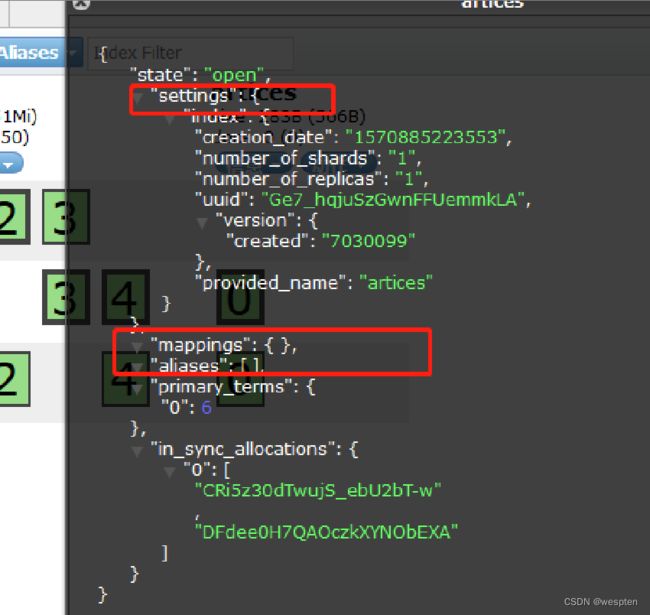
2. 五星代表是主节点,圆代表是从节点,我们这个测试环境有两个索引products和artices,索引详细信息可点击某个索引,查看该索引的所有信息,包括mappings、setting等等。
3. 索引

4. 点击新建索引,可以新建索引
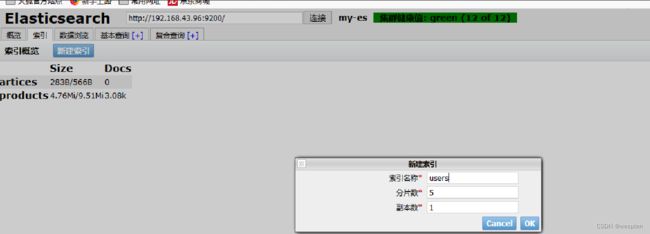
5. 输入索引名称,分片数,副本数量,可以新建成功,成功会有如下提示:

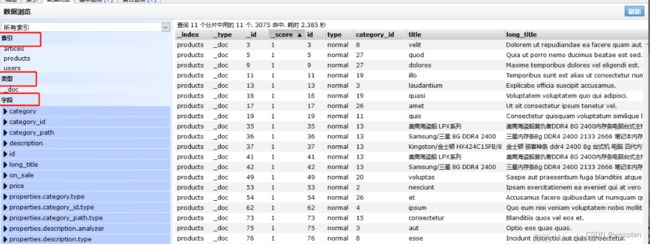
6. 数据浏览,可查看所有索引、类型、字段信息:
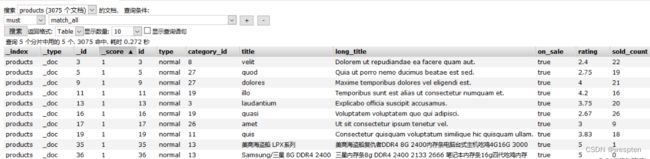
7. 基本查询,可根据查询条件,搜索过滤找到自己需要的索引数据:
8. 复合查询,在这个页签,可以使用json进行复杂的查询,也可发送put请求新增及跟新索引,使用delete请求删除索引等等:

2、Elastic监控工具 - cerebro
kopf的github首页就表明该项目不再维护,推荐使用cerebro;bigdesk也只支持ElasticSearch1.3及以下版本,而且cerebro的使用特别简单,页面还很漂亮!
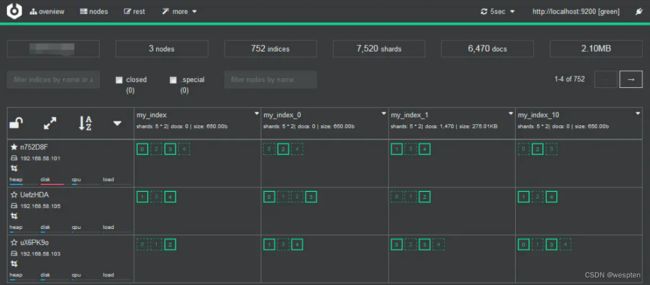
支持索引查询、分片查询、问题检测、在线API执行等等功能。
部署:
1. 下载解压
wget https://github.com/lmenezes/cerebro/releases/download/v0.8.1/cerebro-0.8.1.tgz
tar xzf cerebro-0.8.1.tgz2. 启动
cerebro-0.8.1/bin/cerebro
[info] play.api.Play - Application started (Prod)
[info] p.c.s.AkkaHttpServer - Listening for HTTP on /0:0:0:0:0:0:0:0:9000
指定端口:
bin/cerebro -Dhttp.port=80803. 配置服务器,非必须:如果经常使用的话,可以先在conf/application.conf中配置好ElasticSearch服务器地址
hosts = [
{
host = "http://localhost:9200"
name = "Some Cluster"
},
# Example of host with authentication
#{
# host = "http://some-authenticated-host:9200"
# name = "Secured Cluster"
# auth = {
# username = "username"
# password = "secret-password"
# }
#}
]4. 配置账号密码才可以访问,同样那个配置文件
auth = {
settings {
# Basic auth
username = "admin"
password = "123456"
}
}
操作:
1. 浏览器打开连接http://192.168.58.101:9000

2. 连接后可以显示集群信息
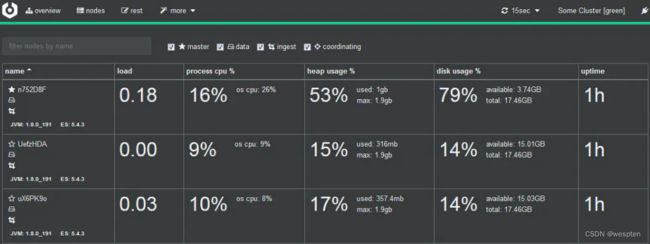
概要信息:

节点信息:
Rest接口:

其他功能:
3、Elastic常用命令
可以通过PUT、GET、DELETE等web请求来操作elasticsearch
如下是将配置修改为true,分为几块。–user是elastic开启验证插件后再填写,_cluster/settings是访问的路径,不同路径代表不同请求配置。因为是put,后面-d指定传输的json内容。
curl -H "Content-Type: application/json" --user elastic:123456 -XPUT 172.16.5.35:9200/_cluster/settings -d'{"transient":{"cluster.routing.allocation.disable_allocation":true}}'状态查询:
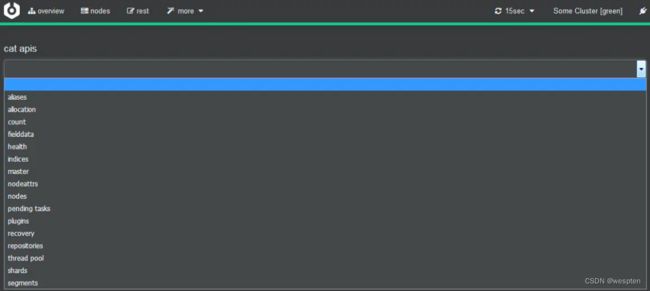
1. 获取所有_cat系列的操作,可以后面加一个v,让输出内容表格显示表头; pretty则让输出缩进更规范
curl http://localhost:9200/_cat
=^.^=
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/tasks
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/thread_pool/{thread_pools}
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
/_cat/templates
2. 集群状态
curl -X GET "localhost:9200/_cluster/health?pretty"
3. 节点简要信息
curl -X GET "localhost:9200/_cat/nodes?pretty&v"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.58.101 69 99 71 12.67 12.25 11.71 mdi - node-101
192.168.58.103 23 99 70 14.64 13.45 12.68 mdi - node-103
192.168.58.105 60 97 69 11.17 10.96 10.88 mdi * node-105
4. 节点详细信息,后面的http是查看的属性,另外还有indices, fs, http, jvm, os, process, thread_pool, discovery等,支持组合(如indices,fs,http)
curl -X GET "localhost:9200/_nodes/stats/http?pretty"
分片状态:
1. 分片中如果存在未分配的分片, 可以查看未分片的原因:
_cat/shards?h=index,shard,prirep,state,unassigned.reason&vcurl -X GET "localhost:9200/_cat/shards?v&pretty"
index shard prirep state docs store ip node
tenmao_index_153915944934 1 p STARTED 39931 4.1mb 172.17.0.14 35S66p1
tenmao_index_153915944934 1 r STARTED 39931 4mb 172.17.0.3 DPKsmMN
tenmao_index_153915944934 0 p STARTED 39634 4mb 172.17.0.2 PE8QHxz
tenmao_index_153915944934 0 r STARTED 39634 4mb 172.17.0.3 DPKsmMN
索引:
1. 索引列表
curl -X GET "localhost:9200/_cat/indices?v"
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open tenmao_index_153915944934 Z6BV1VaMRc-tC-7IucJE2w 5 1 198444 0 40.9mb 20.4mb
条件过滤:_cat/indices?v&health=yellow
排序:_cat/indices?v&health=yellow&s=docs.count:desc
2. 索引详细信息
curl -X GET "localhost:9200/chat_index_alias/_stats?pretty"
3. 数据量
curl -X GET "localhost:9200/_cat/count/chat_index_alias?v&pretty"
4. 新建索引
curl -X PUT "localhost:9200/my_index" -d '
{
"settings" : {
"index" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
}'
5. 删除索引
curl -X DELETE "localhost:9200/tenmao_index"
curl -X DELETE "localhost:9200/tenmao_index_1504520299944"
6. 分词搜索
curl -X POST "localhost:9200/chat_index_alias/_search" -d '
{
"query": {
"match": {
"question": "吃饭了吗"
}
}
}'
7. 完全匹配搜索
curl -X POST "localhost:9200/chat_index_alias/_search" -d '
{
"query": {
"match_phrase": {
"question": "你吃饭了"
}
}
}'
别名:
1. 查看别名
curl -X GET "localhost:9200/_alias/chat_index_alias?pretty"
2. 增加别名
curl -X PUT "localhost:9200/my_index/_alias/my_index_alias?pretty"
3. 删除别名,一般纯删除别名使用的比较少,一般是别名重新绑定(删除和绑定为一个原子操作)
curl -X POST 'http://localhost:9200/_aliases' -d '
{
"actions": [
{"remove": {"index": "my_index", "alias": "my_index_alias"}}
]
}'
4. 别名重新绑定
curl -XPOST 'http://localhost:9200/_aliases' -d '
{
"actions" : [
{ "remove" : { "index" : "my_index", "alias" : "my_index_alias" } },
{ "add" : { "index" : "my_index_v2", "alias" : "my_index_alias" } }
]
}'
4、处理elastic中参与分片
我们通过 GET _cat/allocation?v 可以查看每个节点分片的分配数量以及它们所使用的硬盘空间大小。
发现其有51个shard是unassigned状态,再通过命令GET _cat/health?v:查看集群健康状态。
可以看到其active_shards_percent为63.3%,原因就是其存在UNASSIGNED shards的情况,不过即使存在unassigned shard,也并不会影响es的使用的,只是部分数据所在的索引没法展示。
1)产生unassigned shards的原因
如果你只有一台机器,跑了es,但是你却在index中的settings中设置了replica为1,显然这个replica shard就会成为unassigned shards。
如果是集群的话,可能是在集群重启过程中出现分片问题:
1)INDEX_CREATED:由于创建索引的API导致未分配。
2)CLUSTER_RECOVERED :由于完全集群恢复导致未分配。
3)INDEX_REOPENED :由于打开open或关闭close一个索引导致未分配。
4)DANGLING_INDEX_IMPORTED :由于导入dangling索引的结果导致未分配。
5)NEW_INDEX_RESTORED :由于恢复到新索引导致未分配。
6)EXISTING_INDEX_RESTORED :由于恢复到已关闭的索引导致未分配。
7)REPLICA_ADDED:由于显式添加副本分片导致未分配。
8)ALLOCATION_FAILED :由于分片分配失败导致未分配。
9)NODE_LEFT :由于承载该分片的节点离开集群导致未分配。
10)REINITIALIZED :由于当分片从开始移动到初始化时导致未分配(例如,使用影子shadow副本分片)。
11)REROUTE_CANCELLED :作为显式取消重新路由命令的结果取消分配。
12)REALLOCATED_REPLICA :确定更好的副本位置被标定使用,导致现有的副本分配被取消,出现未分配。
如何解决:
(1)删除分片
1.首先精确定位unassigned shard的位置,每行列出索引的名称,分片编号,是主分片p还是副本分片r,以及其未分配的原因:
curl -H "Content-Type: application/json" --user elastic:123456 -XGET 172.16.5.35:9200/_cat/shards?h=index,shard,prirep,state,unassigned.reason| grep UNASSIGNED可以通过以下语句查看具体原因:
GET _cluster/allocation/explain?pretty2. 对于没有再使用价值的index,直接删除掉
curl -H "Content-Type: application/json" --user elastic:123456 -XDELETE 172.16.5.35:9200/索引名脚本:
循环删除
#!/bin/bash
while read line
do
curl -H "Content-Type: application/json" --user elastic:123456 -XDELETE 172.16.5.35:9200/${line}
done < 索引名称文件(2)修改副本数
集群中节点数量>=集群中所有索引的最大副本数量 +1,N> = R + 1
其中:
N——集群中节点的数目;
R——集群中所有索引的最大副本数目。
知识点:当节点加入和离开集群时,主节点会自动重新分配分片,以确保分片的多个副本不会分配给同一个节点。换句话说,主节点不会将主分片分配给与其副本相同的节点,也不会将同一分片的两个副本分配给同一个节点。
如果没有足够的节点相应地分配分片,则分片可能会处于未分配状态。
由于我的集群就一个节点,即N=1;所以R=0,才能满足公式。
问题就转嫁为:
1)添加节点处理,即N增大;
2)删除副本分片,即R置为0。
R置为0的方式,可以通过如下命令行实现:
root@tyg:/# curl -XPUT "http://localhost:9200/_settings" -d' { "number_of_replicas" : 0 } '
{"acknowledged":true}
(3)allocate重新分配分片
如果方案二仍然未解决,可以考虑重新分配分片。
可能的原因:
1)节点在重新启动时可能遇到问题。正常情况下,当一个节点恢复与群集的连接时,它会将有关其分片的信息转发给主节点,然后主节点将这分片从“未分配”转换为“已分配/已启动”。
2)当由于某种原因(例如节点的存储已被损坏)导致该进程失败时,分片可能保持未分配状态。
在这种情况下,您必须决定如何继续:尝试让原始节点恢复并重新加入集群(并且不要强制分配主分片);
或者强制使用Reroute API分配分片并重新索引缺少的数据原始数据源或备份。
如果您决定分配未分配的主分片,请确保将“allow_primary”:“true”标志添加到请求中。
ES5.X使用脚本如下:
NODE="YOUR NODE NAME"
IFS=$'\n'
for line in $(curl -s 'localhost:9200/_cat/shards' | fgrep UNASSIGNED); do
INDEX=$(echo $line | (awk '{print $1}'))
SHARD=$(echo $line | (awk '{print $2}'))
curl -XPOST 'localhost:9200/_cluster/reroute' -d '{
"commands": [
{
" allocate_replica ": {
"index": "'$INDEX'",
"shard": '$SHARD',
"node": "'$NODE'",
"allow_primary": true
}
}
]
}'
done
ES2.X及早期版本,将 allocate_replica改为 allocate,其他不变。
脚本解读:
步骤1:定位 UNASSIGNED 的节点和分片。
curl -s 'localhost:9200/_cat/shards' | fgrep UNASSIGNED步骤2:通过 allocate_replica 将 UNASSIGNED的分片重新分配。
2)核心知识点
(1)路由
原理很简单,把每个用户的数据都索引到一个独立分片中,在查询时只查询那个用户的分片。这时就需要使用路由。
使用路由优势:路由是优化集群的一个很强大的机制。
它能让我们根据应用程序的逻辑来部署文档, 从而可以用更少的资源构建更快速的查询。
(2)在索引过程中使用路由
我们可以通过路由来控制 ElasticSearch 将文档发送到哪个分片。
路由参数值无关紧要,可以取任何值。重要的是在将不同文档放到同一个分片上时, 需要使用相同的值。
(3)指定路由查询
路由允许用户构建更有效率的查询,当我们只需要从索引的一个特定子集中获取数据时, 为什么非要把查询发送到所有的节点呢?
指定路由查询举例:
curl -XGET 'localhost:9200/documents/_search?pretty&q=*:*&routing=A'(4)集群再路由reroute
reroute命令允许显式地执行包含特定命令的集群重新路由分配。
例如,分片可以从一个节点移动到另一个节点,可以取消分配,或者可以在特定节点上显式分配未分配的分片。
(5)allocate分配原理
分配unassigned的分片到一个节点。将未分配的分片分配给节点。接受索引和分片的索引名称和分片号,以及将分片分配给它的节点。
它还接受allow_primary标志来明确指定允许显式分配主分片(可能导致数据丢失)。
3)查看原因
原因肯定是有很多啊,但是要看具体每一次是什么原因引起的,对照表格排查未免不太高效,怎么办?
es 早已帮你想好对策,使用 Cluster Allocation Explain API,会返回集群为什么不分配分片的详细原因,你对照返回的结果,就可以进行有针对性的解决了。
实验一把:
GET /_cluster/allocation/explain
{
"index": "test",
"shard": 0,
"primary": false,
"current_state": "unassigned",
"unassigned_info": {
"reason": "CLUSTER_RECOVERED",
"at": "2018-05-04T14:54:40.950Z",
"last_allocation_status": "no_attempt"
},
"can_allocate": "no",
"allocate_explanation": "cannot allocate because allocation is not permitted to any of the nodes",
"node_allocation_decisions": [
{
"node_id": "ikKuXkFvRc-qFCqG99smGg",
"node_name": "test",
"transport_address": "127.0.0.1:9300",
"node_decision": "no",
"deciders": [
{
"decider": "same_shard",
"decision": "NO",
"explanation": "the shard cannot be allocated to the same node on which a copy of the shard already exists [[test][0], node[ikKuXkFvRc-qFCqG99smGg], [P], s[STARTED], a[id=bAWZVbRdQXCDfewvAbN85Q]]"
}
]
}
]
}
5、elasticsearch配置文件
elasticsearch.yml:
# ---------------------------------- Cluster -----------------------------------
#es集群名称,es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群
#识别集群的标识,同一个集群名字必须相同
cluster.name: my-application
# ------------------------------------ Node ------------------------------------
#该节点名称,自定义或者默认
node.name: node-1
#该节点是否可以成为一个master节点
node.master: true
#该节点是否存储数据,即是否是一个数据节点,默认true
node.data: true
#节点的通用属性,用于后期集群进行碎片分配时的过滤
node.attr.rack: r1
# ----------------------------------- Paths ------------------------------------
#配置文件路径,默认es安装目录下的config
path.conf: /path/to/conf
#数据存储路径,默认es安装目录下的data
#可以设置多个存储路径,用逗号隔开
path.data: /path/to/data
#日志路径,默认es安装目录下的logs
path.logs: /path/to/logs
#临时文件路径,默认es安装目录下的work
path.work: /path/to/work
#插件存放路径,默认es安装目录下的plugins
path.plugins: /path/to/plugins
# ----------------------------------- Memory -----------------------------------
#当JVM开始写入交换空间时(swapping)ElasticSearch性能会低下
#设置为true来锁住内存,同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过 `ulimit -l unlimited` 命令
bootstrap.memory_lock: true
# ---------------------------------- Network -----------------------------------
#该节点绑定的地址,即对外服务的地址,可以是IP,主机名
network.host: 0.0.0.0
#该节点对外服务的http端口,默认9200
http.port: 9200
#节点间交互的tcp端口,默认9300
transport.tcp.port: 9300
#HTTP请求的最大内容,默认100MB
http.max_content_length: 100MB
#HTTP URL的最大长度,默认为4KB
http.max_initial_line_length: 4KB
#允许的标头的最大大小,默认为8KB
http.max_header_size: 8KB
#压缩,默认true
http.compression: true
#压缩级别,有效值:1-9,默认为3
http.compression_level: 3
#是否开启http协议对外提供服务,默认为true
http.enabled: true
# --------------------------------- Discovery ----------------------------------
#集群列表
#port为节点间交互端口,未设置时,默认9300
discovery.seed_hosts: ["host1:port", "ip2:port"]
#初始主节点列表
cluster.initial_master_nodes: ["node-1", "node-2"]
# ---------------------------------- Gateway -----------------------------------
#gateway的类型,默认为local,即为本地文件系统
gateway.type: local
#集群中的N个节点启动后,才允许进行恢复处理,默认3
gateway.recover_after_nodes: 3
#设置初始化恢复过程的超时时间,超时时间从上一个配置中配置的N个节点启动后算起
gateway.recover_after_time: 5m
#设置这个集群中期望有多少个节点,一旦这N个节点启动,立即开始恢复过程
gateway.expected_nodes: 2
# ---------------------------------- Various -----------------------------------
#删除索引时需要显式名称
action.destructive_requires_name: true
6、Elasticsearch安全检查
ES未授权访问:
ElasticSearch是一款Java编写的企业级搜索服务,未加固情况下启动服务存在未授权访问风险,可被非法查询或操作数据,需立即修复加固。
检查提示
主目录:
/usr/local/alibaba/es/es/elasticsearch | /usr/local/alibaba/es/es/elasticsearch | /usr/local/alibaba/es/es/elasticsearch加固建议:
限制http端口的IP访问,不对公网开放。
修改主目录下 config/elasticsearch.yml 配置文件,将network.host配置为内网地址或者127.0.0.1
network.host: 127.0.0.1。
使用x-pack插件为Elasticsearch访问增加登录验证:
在主目录下运行 bin/elasticsearch-plugin install x-pack 安装x-pack插件。
config/elasticsearch.yml ..配置文件增加以下配置
xpack.security.enabled: True
xpack.ml.enabled: true运行命令:
bin/x-pack/setup-passwords interactive为ES服务设置密码,重启ES服务。
五、Logstash配置
1、Logstash目录布局
这部分描述了在解压Logstash安装包时创建的默认目录结构。
1)压缩包结构
.zip和.tar.gz包是完全独立的,默认情况下,所有文件和目录都包含在主目录中——主目录是在解压缩归档文件时创建的目录。
这非常方便,因为你不必创建任何目录来开始使用Logstash,卸载Logstash就像删除主目录一样简单,但是,建议更改配置和日志目录的默认位置,以便以后不删除重要数据。
| 类型 | 描述 | 默认位置 | 设置 |
|---|---|---|---|
| home | Logstash安装的主目录 | {extract.path} - 通过解压缩归档文件创建的目录 |
|
| bin | 二进制脚本,包括用来启动Logstash的logstash和用来安装插件的logstash-plugin |
{extract.path}/bin |
|
| settings | 配置文件,包括logstash.yml和jvm.options |
{extract.path}/config |
path.settings |
| logs | 日志文件 | {extract.path}/logs |
path.logs |
| plugins | 本地的,非Ruby-Gem插件文件,每个插件都包含在子目录中,仅供开发推荐 | {extract.path}/plugins |
path.plugins |
| data | logstash及其插件使用的数据文件用于任何持久性需求 | {extract.path}/data |
path.data |
2)Debian和RPM包的目录布局
Debian软件包和RPM软件包为系统每个地方配置文件、日志和设置文件在适当的位置:
| 类型 | 描述 | 默认位置 | 设置 |
|---|---|---|---|
| home | Logstash安装的主目录 | /usr/share/logstash |
|
| bin | 二进制脚本,包括用来启动Logstash的logstash和用来安装插件的logstash-plugin |
/usr/share/logstash/bin |
|
| settings | 配置文件,包括logstash.yml、jvm.options和startup.options |
/etc/logstash |
path.settings |
| conf | Logstash管道配置文件 | /etc/logstash/conf.d/*.conf |
看/etc/logstash/pipelines.yml |
| logs | 日志文件 | /var/log/logstash |
path.logs |
| plugins | 本地的,非Ruby-Gem插件文件,每个插件都包含在子目录中,仅供开发推荐 | /usr/share/logstash/plugins |
path.plugins |
| data | logstash及其插件使用的数据文件用于任何持久性需求 | /var/lib/logstash |
path.data |
3)Docker镜像目录布局
Docker镜像是由.tar.gz包创建的,并遵循类似的目录布局。Logstash Docker容器在默认情况下不会创建日志文件,它们记录到标准输出。
| 类型 | 描述 | 默认位置 | 设置 |
|---|---|---|---|
| home | Logstash安装的主目录 | /usr/share/logstash |
|
| bin | 二进制脚本,包括用来启动Logstash的logstash和用来安装插件的logstash-plugin |
/usr/share/logstash/bin |
|
| settings | 配置文件,包括logstash.yml和jvm.options |
/usr/share/logstash/config |
path.settings |
| conf | Logstash管道配置文件 | /usr/share/logstash/pipeline |
path.config |
| plugins | 本地的,非Ruby-Gem插件文件,每个插件都包含在子目录中,仅供开发推荐 | /usr/share/logstash/plugins |
path.plugins |
| data | logstash及其插件使用的数据文件用于任何持久性需求 | /usr/share/logstash/data |
path.data |
2、logstash配置文件
logstash.yml:
# ------------ Node identity ------------
#节点名称,默认主机名
node.name: test
# ------------ Data path ------------------
#数据存储路径,默认LOGSTASH_HOME/data
path.data:
# ------------ Pipeline Settings --------------
#pipeline ID,默认main
pipeline.id: main
#输出通道的工作workers数据量,默认cpu核心数
pipeline.workers:
# How many events to retrieve from inputs before sending to filters+workers
#单个工作线程在尝试执行其过滤器和输出之前将从输入收集的最大事件数量,默认125
pipeline.batch.size: 125
#将较小的批处理分派给管道之前,等待的毫秒数,默认50ms
pipeline.batch.delay: 50
#此值为true时,即使内存中仍然有运行中事件,也会强制Logstash在关机期间退出
#默认flase
pipeline.unsafe_shutdown: false
#管道事件排序
#选项有;auto,true,false,默认auto
pipeline.ordered: auto
# ------------ Pipeline Configuration Settings --------------
#配置文件路径
path.config:
#主管道的管道配置字符串
config.string:
#该值为true时,检查配置是否有效,然后退出,默认false
config.test_and_exit: false
#该值为true时,会定期检查配置是否已更改,并在更改后重新加载配置,默认false
config.reload.automatic: false
#检查配置文件更改的时间间隔,默认3s
config.reload.interval: 3s
#该值为true时,将完整编译的配置显示为调试日志消息,默认false
config.debug: false
#该值为true时,开启转义
config.support_escapes: false
# ------------ HTTP API Settings -------------
#是否开启http访问,默认true
http.enabled: true
#绑定主机地址,可以是ip,主机名,默认127.0.0.1
http.host: 127.0.0.1
#服务监听端口,可以是单个端口,也可以是范围端口,默认9600-9700
http.port: 9600-9700
# ------------ Module Settings ---------------
#模块定义,必须为数组
#模块变量名格式必须为var.PLUGIN_TYPE.PLUGIN_NAME.KEY
modules:
- name: MODULE_NAME
var.PLUGINTYPE1.PLUGINNAME1.KEY1: VALUE
var.PLUGINTYPE1.PLUGINNAME1.KEY2: VALUE
var.PLUGINTYPE2.PLUGINNAME1.KEY1: VALUE
var.PLUGINTYPE3.PLUGINNAME3.KEY1: VALUE
# ------------ Queuing Settings --------------
#事件缓冲的内部排队模型,可选项:memory,persisted,默认memory
queue.type: memory
#启用持久队列(queue.type: persisted)后将在其中存储数据文件的目录路径
#默认path.data/queue
path.queue:
#启用持久队列(queue.type: persisted)时使用的页面数据文件的大小
#默认64mb
queue.page_capacity: 64mb
#启用持久队列(queue.type: persisted)后,队列中未读事件的最大数量
#默认0
queue.max_events: 0
#启用持久队列(queue.type: persisted)后,队列的总容量,单位字节,默认1024mb
queue.max_bytes: 1024mb
#启用持久队列(queue.type: persisted)后,在强制检查点之前的最大ACKed事件数,默认1024
queue.checkpoint.acks: 1024
#启用持久队列(queue.type: persisted)后,在强制检查点之前的最大书面事件数,默认1024
queue.checkpoint.writes: 1024
# If using queue.type: persisted, the interval in milliseconds when a checkpoint is forced on the head page
# Default is 1000, 0 for no periodic checkpoint.
#启用持久队列(queue.type: persisted)后,执行检查点的时间间隔,单位ms,默认1000ms
queue.checkpoint.interval: 1000
# ------------ Dead-Letter Queue Settings --------------
#是否启用插件支持的DLQ功能的标志,默认false
dead_letter_queue.enable: false
#dead_letter_queue.enable为true时,每个死信队列的最大大小
#若死信队列的大小超出该值,则被删除,默认1024mb
dead_letter_queue.max_bytes: 1024mb
#死信队列存储路径,默认path.data/dead_letter_queue
path.dead_letter_queue:
# ------------ Debugging Settings --------------
#日志输出级别,选项:fatal,error,warn,info,debug,trace,默认info
log.level: info
#日志格式,选项:json,plain,默认plain
log.format:
#日志路径,默认LOGSTASH_HOME/logs
path.logs:
# ------------ Other Settings --------------
#插件存储路径
path.plugins: []
#是否启用每个管道在不同日志文件中的日志分隔
#默认false
pipeline.separate_logs: false
logstash.conf:
该文件定义了logstash从哪里获取输入,然后输出到哪里。
#从Beats输入,以json格式输出到Elasticsearch
input {
beats {
port => 5044
codec => 'json'
}
}
output {
elasticsearch {
#elasticsearch地址,多个以','隔开
hosts => ["http://localhost:9200"]
#创建的elasticsearch索引名,可以自定义也可以使用下面的默认
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}
#从kafka输入,以json格式输出到Elasticsearch
input {
kafka {
#kafka地址,多个用逗号','隔开
bootstrap_servers => ["ip1:port2","ip2:port2"]
#消费者组
group_id => 'test'
# kafka topic 名称
topics => 'logstash-topic'
codec => 'json'
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}
六、kibana配置
详情:Kibana Guide [8.4] | Elastic
kibana.yml:
#####----------kibana服务相关----------#####
#提供服务的端口,监听端口
server.port: 5601
#主机地址,可以是ip,主机名
server.host: 0.0.0.0
#在代理后面运行,则可以指定安装Kibana的路径
#使用server.rewriteBasePath设置告诉Kibana是否应删除basePath
#接收到的请求,并在启动时防止过时警告
#此设置不能以斜杠结尾
server.basePath: ""
#指定Kibana是否应重写以server.basePath为前缀的请求,或者要求它们由反向代理重写,默认false
server.rewriteBasePath: false
#传入服务器请求的最大有效负载大小,以字节为单位,默认1048576
server.maxPayloadBytes: 1048576
#该kibana服务的名称,默认your-hostname
server.name: "your-hostname"
#服务的pid文件路径,默认/var/run/kibana.pid
pid.file: /var/run/kibana.pid
#####----------elasticsearch相关----------#####
#kibana访问es服务器的URL,就可以有多个,以逗号","隔开
elasticsearch.hosts: ["http://localhost:9200"]
#当此值为true时,Kibana使用server.host设定的主机名
#当此值为false时,Kibana使用连接Kibana实例的主机的主机名
#默认ture
elasticsearch.preserveHost: true
#Kibana使用Elasticsearch中的索引来存储已保存的搜索,可视化和仪表板
#如果索引尚不存在,Kibana会创建一个新索引
#默认.kibana
kibana.index: ".kibana"
#加载的默认应用程序
#默认home
kibana.defaultAppId: "home"
#kibana访问Elasticsearch的账号与密码(如果ElasticSearch设置了的话)
elasticsearch.username: "kibana_system"
elasticsearch.password: "pass"
#从Kibana服务器到浏览器的传出请求是否启用SSL
#设置为true时,需要server.ssl.certificate和server.ssl.key
server.ssl.enabled: true
server.ssl.certificate: /path/to/your/server.crt
server.ssl.key: /path/to/your/server.key
#从Kibana到Elasticsearch启用SSL后,ssl.certificate和ssl.key的位置
elasticsearch.ssl.certificate: /path/to/your/client.crt
elasticsearch.ssl.key: /path/to/your/client.key
#PEM文件的路径列表
elasticsearch.ssl.certificateAuthorities: [ "/path/to/your/CA.pem" ]
#控制Elasticsearch提供的证书验证
#有效值为none,certificate和full
elasticsearch.ssl.verificationMode: full
#Elasticsearch服务器响应ping的时间,单位ms
elasticsearch.pingTimeout: 1500
#Elasticsearch 的响应的时间,单位ms
elasticsearch.requestTimeout: 30000
#Kibana客户端发送到Elasticsearch的标头列表
#如不发送客户端标头,请将此值设置为空
elasticsearch.requestHeadersWhitelist: []
#Kibana客户端发往Elasticsearch的标题名称和值
elasticsearch.customHeaders: {}
#Elasticsearch等待分片响应的时间
elasticsearch.shardTimeout: 30000
#Kibana刚启动时等待Elasticsearch的时间,单位ms,然后重试
elasticsearch.startupTimeout: 5000
#记录发送到Elasticsearch的查询
elasticsearch.logQueries: false
#####----------日志相关----------#####
#kibana日志文件存储路径,默认stdout
logging.dest: stdout
#此值为true时,禁止所有日志记录输出
#默认false
logging.silent: false
#此值为true时,禁止除错误消息之外的所有日志记录输出
#默认false
logging.quiet: false
#此值为true时,记录所有事件,包括系统使用信息和所有请求
#默认false
logging.verbose: false
#####----------其他----------#####
#系统和进程取样间隔,单位ms,最小值100ms
#默认5000ms
ops.interval: 5000
#kibana web语言
#默认en
i18n.locale: "en"