动手学习深度学习 08:机器视觉
文章目录
- 01 数据增广
- 02 微调
- 03 目标检测和边界框
- 04 锚框
-
- 1、锚框
-
- 1.1 生成多个锚框
- 1.2 IOU
- 1.3 在训练数据中标注锚框
-
-
- 1.3.1 将真实边界框分配给锚框
- 1.3.2 标记类别和偏移量
-
- 1.4 NMS:使用非极大值抑制预测边界框
- 05 物体检测算法
-
- 1、R-CNN
- 2、SSD
- 3、YOLO
- 06 SSD实现
-
- 1、多尺度锚框
- 2、SSD实现
- 07 语义分割
- 08 转置卷积
- 09 全连接神经网络FCN
- 10 风格迁移
- 11 实战 Kaggle 比赛
01 数据增广
- 13.1. 图像增广 — 动手学深度学习 2.0.0-beta1 documentation (d2l.ai)
02 微调
可以把神经网络大致分为两个部分:特征提取 + 回归
我们希望的是让“特征提取”部分变的可以学习
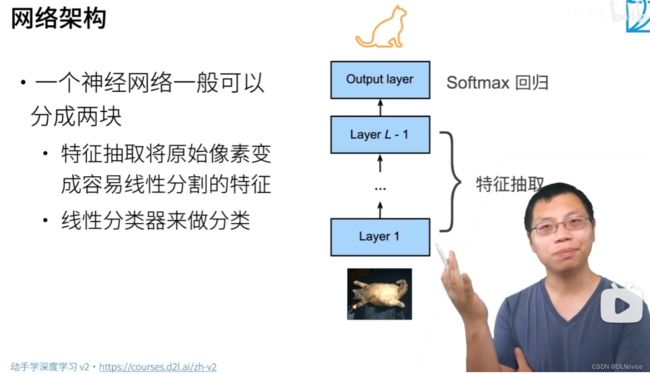
使用微调或者迁移学习,最后一部分的回归不能直接使用,但数据提取部分对我们当前的数据仍有作用,至少比从零开始学习好多了
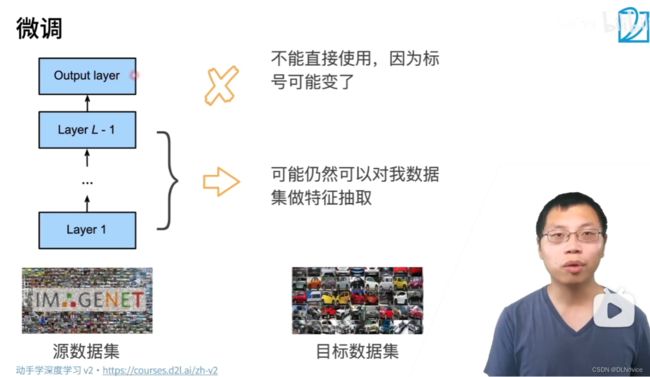
具体做法:
我们不再是随机初始化了,而是把特征提取部分copy过来,使得我们开始就有不错的特征提取能力

补充一些常用的技术:


03 目标检测和边界框
- 目标检测:目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。
- 边缘框:四个数字定义
- (左上x,左上y,右下x,右下y)
- (左上x,左上y,宽,高)
04 锚框
1、锚框
1.1 生成多个锚框
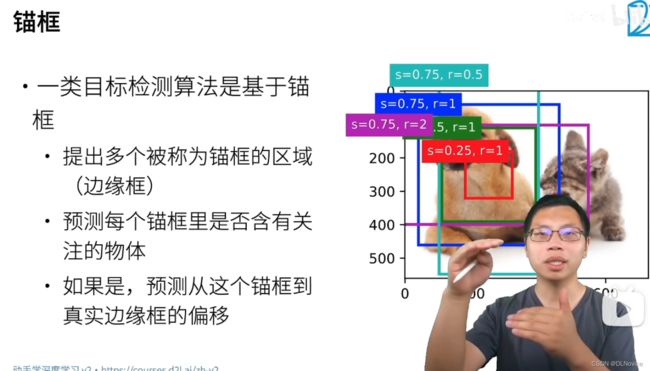
1.2 IOU

简易实现:
def iou(box1, box2):
'''
两个框(二维)的 iou 计算
注意:边框以左上为原点
box:[x1,y1,x2,y2],依次为左上右下坐标
'''
h = max(0, min(box1[2], box2[2]) - max(box1[0], box2[0]))
w = max(0, min(box1[3], box2[3]) - max(box1[1], box2[1]))
area_box1 = ((box1[2] - box1[0]) * (box1[3] - box1[1]))
area_box2 = ((box2[2] - box2[0]) * (box2[3] - box2[1]))
inter = w * h
union = area_box1 + area_box2 - inter
iou = inter / union
return iou
box1 = [0,0,2,2]
box2 = [1,1,3,3]
IoU = iou(box1,box2)
print(IoU)
基于PyTorch:
#@save
def box_iou(boxes1, boxes2):
"""计算两个锚框或边界框列表中成对的交并比"""
box_area = lambda boxes: ((boxes[:, 2] - boxes[:, 0]) *
(boxes[:, 3] - boxes[:, 1]))
# boxes1,boxes2,areas1,areas2的形状:
# boxes1:(boxes1的数量,4),
# boxes2:(boxes2的数量,4),
# areas1:(boxes1的数量,),
# areas2:(boxes2的数量,)
areas1 = box_area(boxes1)
areas2 = box_area(boxes2)
# inter_upperlefts,inter_lowerrights,inters的形状:
# (boxes1的数量,boxes2的数量,2)
inter_upperlefts = torch.max(boxes1[:, None, :2], boxes2[:, :2])
inter_lowerrights = torch.min(boxes1[:, None, 2:], boxes2[:, 2:])
inters = (inter_lowerrights - inter_upperlefts).clamp(min=0)
# inter_areasandunion_areas的形状:(boxes1的数量,boxes2的数量)
inter_areas = inters[:, :, 0] * inters[:, :, 1]
union_areas = areas1[:, None] + areas2 - inter_areas
return inter_areas / union_areas
1.3 在训练数据中标注锚框
比如在一个图片中,我们先假设1w个锚框

-
在训练集中,我们将每个锚框视为一个训练样本。 为了训练目标检测模型,我们需要每个锚框的类别(class)和偏移量(offset)标签,其中前者是与锚框相关的对象的类别,后者是真实边界框相对于锚框的偏移量。
-
在预测时,我们为每个图像生成多个锚框,预测所有锚框的类别和偏移量,根据预测的偏移量调整它们的位置以获得预测的边界框,最后只输出符合特定条件的预测边界框。
1.3.1 将真实边界框分配给锚框

1.3.2 标记类别和偏移量

1.4 NMS:使用非极大值抑制预测边界框

以下nms函数按降序对置信度进行排序并返回其索引。
#@save
def nms(boxes, scores, iou_threshold):
"""对预测边界框的置信度进行排序"""
B = torch.argsort(scores, dim=-1, descending=True)
keep = [] # 保留预测边界框的指标
while B.numel() > 0:
i = B[0]
keep.append(i)
if B.numel() == 1: break
iou = box_iou(boxes[i, :].reshape(-1, 4),
boxes[B[1:], :].reshape(-1, 4)).reshape(-1)
inds = torch.nonzero(iou <= iou_threshold).reshape(-1)
B = B[inds + 1]
return torch.tensor(keep, device=boxes.device)
我们定义以下multibox_detection函数来将非极大值抑制应用于预测边界框。 如果你发现实现有点复杂,请不要担心。我们将在实现之后,马上用一个具体的例子来展示它是如何工作的。
#@save
def multibox_detection(cls_probs, offset_preds, anchors, nms_threshold=0.5,
pos_threshold=0.009999999):
"""使用非极大值抑制来预测边界框"""
device, batch_size = cls_probs.device, cls_probs.shape[0]
anchors = anchors.squeeze(0)
num_classes, num_anchors = cls_probs.shape[1], cls_probs.shape[2]
out = []
for i in range(batch_size):
cls_prob, offset_pred = cls_probs[i], offset_preds[i].reshape(-1, 4)
conf, class_id = torch.max(cls_prob[1:], 0)
predicted_bb = offset_inverse(anchors, offset_pred)
keep = nms(predicted_bb, conf, nms_threshold)
# 找到所有的non_keep索引,并将类设置为背景
all_idx = torch.arange(num_anchors, dtype=torch.long, device=device)
combined = torch.cat((keep, all_idx))
uniques, counts = combined.unique(return_counts=True)
non_keep = uniques[counts == 1]
all_id_sorted = torch.cat((keep, non_keep))
class_id[non_keep] = -1
class_id = class_id[all_id_sorted]
conf, predicted_bb = conf[all_id_sorted], predicted_bb[all_id_sorted]
# pos_threshold是一个用于非背景预测的阈值
below_min_idx = (conf < pos_threshold)
class_id[below_min_idx] = -1
conf[below_min_idx] = 1 - conf[below_min_idx]
pred_info = torch.cat((class_id.unsqueeze(1),
conf.unsqueeze(1),
predicted_bb), dim=1)
out.append(pred_info)
return torch.stack(out)
现在让我们将上述算法应用到一个带有四个锚框的具体示例中。 为简单起见,我们假设预测的偏移量都是零,这意味着预测的边界框即是锚框。 对于背景、狗和猫其中的每个类,我们还定义了它的预测概率。
anchors = torch.tensor([[0.1, 0.08, 0.52, 0.92], [0.08, 0.2, 0.56, 0.95],
[0.15, 0.3, 0.62, 0.91], [0.55, 0.2, 0.9, 0.88]])
offset_preds = torch.tensor([0] * anchors.numel())
cls_probs = torch.tensor([[0] * 4, # 背景的预测概率
[0.9, 0.8, 0.7, 0.1], # 狗的预测概率
[0.1, 0.2, 0.3, 0.9]]) # 猫的预测概率
我们可以在图像上绘制这些预测边界框和置信度。
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, anchors * bbox_scale,
['dog=0.9', 'dog=0.8', 'dog=0.7', 'cat=0.9'])

现在我们可以调用multibox_detection函数来执行非极大值抑制,其中阈值设置为0.5。 请注意,我们在示例的张量输入中添加了维度。
我们可以看到返回结果的形状是(批量大小,锚框的数量,6)。 最内层维度中的六个元素提供了同一预测边界框的输出信息。 第一个元素是预测的类索引,从0开始(0代表狗,1代表猫),值-1表示背景或在非极大值抑制中被移除了。 第二个元素是预测的边界框的置信度。 其余四个元素分别是预测边界框左上角和右下角的(x,y)轴坐标(范围介于0和1之间)。
output = multibox_detection(cls_probs.unsqueeze(dim=0),
offset_preds.unsqueeze(dim=0),
anchors.unsqueeze(dim=0),
nms_threshold=0.5)
output
tensor([[[ 0.00, 0.90, 0.10, 0.08, 0.52, 0.92],
[ 1.00, 0.90, 0.55, 0.20, 0.90, 0.88],
[-1.00, 0.80, 0.08, 0.20, 0.56, 0.95],
[-1.00, 0.70, 0.15, 0.30, 0.62, 0.91]]])
删除-1类别(背景)的预测边界框后,我们可以输出由非极大值抑制保存的最终预测边界框。
fig = d2l.plt.imshow(img)
for i in output[0].detach().numpy():
if i[0] == -1:
continue
label = ('dog=', 'cat=')[int(i[0])] + str(i[1])
show_bboxes(fig.axes, [torch.tensor(i[2:]) * bbox_scale], label)

实践中,在执行非极大值抑制前,我们甚至可以将置信度较低的预测边界框移除,从而减少此算法中的计算量。 我们也可以对非极大值抑制的输出结果进行后处理。例如,只保留置信度更高的结果作为最终输出。
05 物体检测算法
1、R-CNN
- 13.8. 区域卷积神经网络(R-CNN)系列 — 动手学深度学习 2.0.0-beta1 documentation (d2l.ai)
2、SSD
- 13.7. 单发多框检测(SSD) — 动手学深度学习 2.0.0-beta1 documentation (d2l.ai)
3、YOLO
pass
06 SSD实现
1、多尺度锚框
- 13.5. 多尺度目标检测 — 动手学深度学习 2.0.0-beta1 documentation (d2l.ai)
2、SSD实现
- 13.7. 单发多框检测(SSD) — 动手学深度学习 2.0.0-beta1 documentation (d2l.ai)
07 语义分割
- 13.9. 语义分割和数据集 — 动手学深度学习 2.0.0-beta1 documentation (d2l.ai)
**通常意义上的目标分割指的就是语义分割,**图像语义分割,简而言之就是对一张图片上的所有像素点进行分类

08 转置卷积
- 47 转置卷积【动手学深度学习v2】_哔哩哔哩_bilibili
- 47.2 转置卷积是一种卷积【动手学深度学习v2】_哔哩哔哩_bilibili


09 全连接神经网络FCN
全卷积网络(fully convolutional network,FCN)采用卷积神经网络实现了从图像像素到像素类别的变换 [Long et al., 2015]。
- 13.11. 全卷积网络 — 动手学深度学习 2.0.0-beta1 documentation (d2l.ai)
与我们之前在图像分类或目标检测部分介绍的卷积神经网络不同,全卷积网络将中间层特征图的高和宽变换回输入图像的尺寸:这是通过在 13.10节中引入的转置卷积(transposed convolution)实现的。 因此,输出的类别预测与输入图像在像素级别上具有一一对应关系:通道维的输出即该位置对应像素的类别预测。
其结构非常简单:

10 风格迁移
我们将介绍如何使用卷积神经网络,自动将一个图像中的风格应用在另一图像之上,即风格迁移(style transfer)
先看一下效果:

- 首先,我们初始化合成图像,例如将其初始化为内容图像。 该合成图像是风格迁移过程中唯一需要更新的变量,即风格迁移所需迭代的模型参数。
- 首先,我们初始化合成图像,例如将其初始化为内容图像。 该合成图像是风格迁移过程中唯一需要更新的变量,即风格迁移所需迭代的模型参数。
- 这个深度卷积神经网络凭借多个层逐级抽取图像的特征,我们可以选择其中某些层的输出作为内容特征或风格特征。 以下图为例,这里选取的预训练的神经网络含有3个卷积层,其中第二层输出内容特征,第一层和第三层输出风格特征。
下图为基于卷积神经网络的风格迁移。实线箭头和虚线箭头分别表示前向传播和反向传播:

接下来,我们通过前向传播(实线箭头方向)计算风格迁移的损失函数,并通过反向传播(虚线箭头方向)迭代模型参数,即不断更新合成图像。 风格迁移常用的损失函数由3部分组成: (i)内容损失使合成图像与内容图像在内容特征上接近; (ii)风格损失使合成图像与风格图像在风格特征上接近; (iii)全变分损失则有助于减少合成图像中的噪点。 最后,当模型训练结束时,我们输出风格迁移的模型参数,即得到最终的合成图像。
11 实战 Kaggle 比赛
- 13.13. 实战 Kaggle 比赛:图像分类 (CIFAR-10) — 动手学深度学习 2.0.0-beta1 documentation (d2l.ai)
- 13.14. 实战Kaggle比赛:狗的品种识别(ImageNet Dogs) — 动手学深度学习 2.0.0-beta1 documentation (d2l.ai)