动手学习深度学习 07:现代卷积神经网络(AlexNet、VGG、NiN、GoogleNet、批量归一化、ResNet、DenseNet)
文章目录
- 01 深度卷积神经网络-AlexNet
-
- 1、学习表征
-
- 1.1、缺少的成分:数据
- 1.2、缺少的成分:硬件
- 2、AlexNet
-
- 2.1、模型设计
- 2.2、激活函数
- 2.3、容量控制和预处理
- 2.4、读取数据集
- 2.5、训练
- 02 使用块的网络-VGG
-
- 1、VGG块
- 2、VGG网络
- 3、训练模型
- 4、代码汇总
- 5、小结
- 03 网络中的网络-NiN
-
- 1、NiN块
-
- 1.1、概述
- 1.2、实现
- 2、NiN模型
- 3、训练模型
- 4、小结
- 04 含并行连结的网络-GoogLeNet
-
- 1、Inception块
- 2、GoogLeNet模型
- 3、代码实现
- 4、总结
- 05 批量归一化
-
- 1、训练深层网络
- 2、批量规范化层
- 3、代码实现
- 4、争议
- 5、小结
- 06 残差网络-ResNet
-
- 1、核心思想
-
- 1.1、函数类
- 1.2、残差块
- 2、ResNet模型
-
- 2.1 整合代码
- 3、总结
- 4、ResNet为什么能训练出1000层的模型
- 07 稠密连接网络-DenseNet
- 08 竞赛:图像分类
01 深度卷积神经网络-AlexNet
事实上,在上世纪90年代初到2012年之间的大部分时间里,神经网络往往被其他机器学习方法超越,如支持向量机(support vector machines)。
经典机器学习的流水线看起来更像下面这样:
- 获取一个有趣的数据集。在早期,收集这些数据集需要昂贵的传感器(在当时最先进的图像也就100万像素)。
- 根据光学、几何学、其他知识以及偶然的发现,手工对特征数据集进行预处理。
- 通过标准的特征提取算法,如SIFT(尺度不变特征变换) [Lowe, 2004]和SURF(加速鲁棒特征) [Bay et al., 2006]或其他手动调整的流水线来输入数据。
- 将提取的特征送入最喜欢的分类器中(例如线性模型或其它核方法),以训练分类器。
1、学习表征
过去,数据和硬件方面的发展:

深度卷积神经网络的突破出现在2012年。突破可归因于两个关键因素。
1.1、缺少的成分:数据
限于早期计算机有限的存储和90年代有限的研究预算,大部分研究只基于小的公开数据集。
这一状况在2010年前后兴起的大数据浪潮中得到改善。2009年,ImageNet数据集发布,并发起ImageNet挑战赛:要求研究人员从100万个样本中训练模型,以区分1000个不同类别的对象。ImageNet数据集由斯坦福教授李飞飞小组的研究人员开发,利用谷歌图像搜索(Google Image Search)对每一类图像进行预筛选,并利用亚马逊众包(Amazon Mechanical Turk)来标注每张图片的相关类别。
1.2、缺少的成分:硬件
深度学习对计算资源要求很高,训练可能需要数百个迭代轮数,每次迭代都需要通过代价高昂的许多线性代数层传递数据。这也是为什么在20世纪90年代至21世纪初,优化凸目标的简单算法是研究人员的首选。然而,用GPU训练神经网络改变了这一格局。图形处理器(Graphics Processing Unit,GPU)**早年用来加速图形处理,使电脑游戏玩家受益。GPU可优化高吞吐量的4×4矩阵和向量乘法,从而服务于基本的图形任务。幸运的是,这些数学运算与卷积层的计算惊人地相似。由此,英伟达(NVIDIA)和ATI已经开始为通用计算操作优化gpu,甚至把它们作为通用GPU(general-purpose GPUs,GPGPU)来销售。
那么GPU比CPU强在哪里呢?
-
首先,我们深度理解一下中央处理器(Central Processing Unit,CPU)的核心。 CPU的每个核心都拥有高时钟频率的运行能力,和高达数MB的三级缓存(L3Cache)。 它们非常适合执行各种指令,具有分支预测器、深层流水线和其他使CPU能够运行各种程序的功能。 然而,这种明显的优势也是它的致命弱点:通用核心的制造成本非常高。 它们需要大量的芯片面积、复杂的支持结构(内存接口、内核之间的缓存逻辑、高速互连等等),而且它们在任何单个任务上的性能都相对较差。 现代笔记本电脑最多有4核,即使是高端服务器也很少超过64核,因为它们的性价比不高。
-
相比于CPU,GPU由100∼1000个小的处理单元组成(NVIDIA、ATI、ARM和其他芯片供应商之间的细节稍有不同),通常被分成更大的组(NVIDIA称之为warps)。 虽然每个GPU核心都相对较弱,有时甚至以低于1GHz的时钟频率运行,但庞大的核心数量使GPU比CPU快几个数量级。 例如,NVIDIA最近一代的Ampere GPU架构为每个芯片提供了高达312 TFlops的浮点性能,而CPU的浮点性能到目前为止还没有超过1 TFlops。 之所以有如此大的差距**,原因其实很简单:(功耗、内核、内存带宽)**
- 首先,功耗往往会随时钟频率呈二次方增长。 对于一个CPU核心,假设它的运行速度比GPU快4倍,你可以使用16个GPU内核取代,那么GPU的综合性能就是CPU的16×1/4=4倍。
- 其次,GPU内核要简单得多,这使得它们更节能。
- 此外,深度学习中的许多操作需要相对较高的内存带宽,而GPU拥有10倍于CPU的带宽。
回到2012年的重大突破,当Alex Krizhevsky和Ilya Sutskever实现了可以在GPU硬件上运行的深度卷积神经网络时,一个重大突破出现了。他们意识到卷积神经网络中的计算瓶颈:卷积和矩阵乘法,都是可以在硬件上并行化的操作。 于是,他们使用两个显存为3GB的NVIDIA GTX580 GPU实现了快速卷积运算。他们的创新cuda-convnet几年来它一直是行业标准,并推动了深度学习热潮。
2、AlexNet
2012年,AlexNet横空出世。它首次证明了学习到的特征可以超越手工设计的特征。它一举打破了计算机视觉研究的现状。 AlexNet使用了8层卷积神经网络,并以很大的优势赢得了2012年ImageNet图像识别挑战赛。

2.1、模型设计
对比AlexNet与LeNet:

复杂度对比

- FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
- FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
2.2、激活函数
此外,AlexNet将sigmoid激活函数改为更简单的ReLU激活函数。
2.3、容量控制和预处理
-
AlexNet通过暂退法控制全连接层的模型复杂度,而LeNet只使用了权重衰减。
-
AlexNet在训练时增加了大量的图像增强数据,如翻转、裁切和变色。 这使得模型更健壮,更大的样本量有效地减少了过拟合。
AlexNet实现:
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
# 这里,我们使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10))
我们构造一个高度和宽度都为224的单通道数据,来观察每一层输出的形状。 它与 图7.1.2中的AlexNet架构相匹配。
X = torch.randn(1, 1, 224, 224)
for layer in net:
X=layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape)
结果展示:
Conv2d output shape: torch.Size([1, 96, 54, 54])
ReLU output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Conv2d output shape: torch.Size([1, 256, 26, 26])
ReLU output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 256, 12, 12])
ReLU output shape: torch.Size([1, 256, 12, 12])
MaxPool2d output shape: torch.Size([1, 256, 5, 5])
Flatten output shape: torch.Size([1, 6400])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
2.4、读取数据集
ImageNet数据集较大,这里我们Fashion-MNIST数据集。
将AlexNet直接应用于Fashion-MNIST的一个问题是,Fashion-MNIST图像的分辨率(28×28像素)低于ImageNet图像。 为了解决这个问题,我们将它们增加到224×224(通常来讲这不是一个明智的做法,但我们在这里这样做是为了有效使用AlexNet架构)。 我们使用d2l.load_data_fashion_mnist函数中的resize参数执行此调整。
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
2.5、训练
lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
总结:
- AlexNet是更大更深的LeNet,10x参数个数,260x计算复杂度
- 新引入丢弃法、ReLU、最大池化层和数据增强
- 2012ImageNet冠军,标志新一轮神经网络热潮的开始
02 使用块的网络-VGG
虽然AlexNet证明深层神经网络卓有成效,但它没有提供一个通用的模板来指导后续的研究人员设计新的网络。
1、VGG块
首先先直观的了解VGG:

LeNet -> AlexNet -> VGG

经典卷积神经网络的基本组成部分是下面的这个序列:
- 带填充以保持分辨率的卷积层;
- 非线性激活函数,如ReLU;
- 汇聚层,如最大汇聚层。
而一个VGG块与之类似,由一系列卷积层组成,后面再加上用于空间下采样的最大汇聚层。
在最初的VGG论文中 [Simonyan & Zisserman, 2014],作者使用了带有3×3卷积核、填充为1(保持高度和宽度)的卷积层,和带有2×2汇聚窗口、步幅为2(每个块后的分辨率减半)的最大汇聚层。在下面的代码中,我们定义了一个名为vgg_block的函数来实现一个VGG块。
import torch
from torch import nn
from d2l import torch as d2l
# 定义vgg_block实现一个VGG块:该函数有三个参数,分别对应于卷积层的数量num_convs、输入通道的数量in_channels 和输出通道的数量out_channels.
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)
总结:
- VGG使用可重复使用的卷积块来构建深度卷积神经网络
- 不同的卷积块个数和超参数可以得到不同复杂度的变种
- VGG-11使用可复用的卷积块构造网络。不同的VGG模型可通过每个块中卷积层数量和输出通道数量的差异来定义。
- 块的使用导致网络定义的非常简洁。使用块可以有效地设计复杂的网络。
- 在VGG论文中,Simonyan和Ziserman尝试了各种架构。特别是他们发现深层且窄的卷积(即3×3)比较浅层且宽的卷积更有效。
2、VGG网络

VGG神经网络连接 图7.2.1的几个VGG块(在vgg_block函数中定义)。其中有超参数变量conv_arch。该变量指定了每个VGG块里卷积层个数和输出通道数。全连接模块则与AlexNet中的相同。
原始VGG网络有5个卷积块,其中前两个块各有一个卷积层,后三个块各包含两个卷积层。 第一个模块有64个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。由于该网络使用8个卷积层和3个全连接层,因此它通常被称为VGG-11。
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
下面的代码实现了VGG-11。可以通过在conv_arch上执行for循环来简单实现。
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
net = vgg(conv_arch)
构建一个单通道数据样本,以观察每个层输出的形状。
X = torch.randn(size=(1, 1, 224, 224))
for blk in net:
X = blk(X)
print(blk.__class__.__name__,'output shape:\t',X.shape)
Sequential output shape: torch.Size([1, 64, 112, 112])
Sequential output shape: torch.Size([1, 128, 56, 56])
Sequential output shape: torch.Size([1, 256, 28, 28])
Sequential output shape: torch.Size([1, 512, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
Flatten output shape: torch.Size([1, 25088])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
我们在每个块的高度和宽度减半,最终高度和宽度都为7。最后再展平表示,送入全连接层处理。
3、训练模型
由于VGG-11比AlexNet计算量更大,因此我们构建了一个通道数较少的网络
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)
除了使用略高的学习率外,模型训练过程与 7.1节中的AlexNet类似。
lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
4、代码汇总
import torch
from torch import nn
from d2l import torch as d2l
# 实现一个VGG块
def vgg_block(num_convs, in_channels, out_channels): # 卷积层的数量num_convs、输入通道的数量in_channels、输出通道的数量out_channels.
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)
# 对应原始VGG网络有5个卷积块
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512)) # (卷积层的数量,输出通道的数量)
# 输入通道数去哪了?第一层中我们给个初始的输入通道数,之后几层的输入通道数都等于上一层的输出通道数
# 代码实现VGG-11
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
net = vgg(conv_arch)
# # 构建一个数据样本,以观察每个层输出的形状。
# X = torch.randn(size=(1, 1, 224, 224))
# for blk in net:
# X = blk(X)
# print(blk.__class__.__name__,'output shape:\t',X.shape)
# 由于VGG-11比AlexNet计算量更大,因此我们构建了一个通道数较少的网络,不用之前定义的net:net = vgg(conv_arch)
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)
lr, num_epochs, batch_size = 0.05, 10, 128
# 数据准备
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
# 开始训练
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
5、小结
- VGG-11使用可复用的卷积块构造网络。不同的VGG模型可通过每个块中卷积层数量和输出通道数量的差异来定义。
- 块的使用导致网络定义的非常简洁。使用块可以有效地设计复杂的网络。
- 在VGG论文中,Simonyan和Ziserman尝试了各种架构。特别是他们发现深层且窄的卷积(即3×3)比较浅层且宽的卷积更有效。
03 网络中的网络-NiN
- LeNet、AlexNet和VGG都有一个共同的设计模式:通过一系列的卷积层与汇聚层来提取空间结构特征,然后通过全连接层对特征的表征进行处理。
- AlexNet和VGG对LeNet的改进主要在于如何扩大和加深这两个模块。
- 或者,可以想象在这个过程的早期使用全连接层。然而,如果使用了全连接层,可能会完全放弃表征的空间结构。 网络中的网络(NiN)提供了一个非常简单的解决方案:在每个像素的通道上分别使用多层感知机
1、NiN块
1.1、概述
AlexNet和VGG对LeNet最后都采用了全连接层,会导致全连接层参数太大了,很容易出现过拟合扽等问题。

为了解决这一问题,我们引入NiN。NiN的核心在于NiN块

了解完NiN的核心思想,我们看一下NiN架构:

总结:
- NiN块使用卷积层加两个1*1卷积层
- 后者对每个像素增加了非线性性
- NiN使用全局平均池化层来替代VGG和AlexNet中的全连接层
- 不容易过拟合,更少的参数个数
1.2、实现

import torch
from torch import nn
from d2l import torch as d2l
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
2、NiN模型
NiN使用窗口形状为11×11、5×5和3×3的卷积层,输出通道数量与AlexNet中的相同。 每个NiN块后有一个最大汇聚层,汇聚窗口形状为3×3,步幅为2。
NiN和AlexNet之间的一个显著区别是NiN完全取消了全连接层。 相反,NiN使用一个NiN块,其输出通道数等于标签类别的数量。最后放一个全局平均汇聚层(global average pooling layer),生成一个对数几率 (logits)。
NiN设计的一个优点是,它显著减少了模型所需参数的数量。然而,在实践中,这种设计有时会增加训练模型的时间。
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2),
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
# 全局的平均池化层
nn.AdaptiveAvgPool2d((1, 1)),
# 将四维的输出转成二维的输出,其形状为(批量大小,10)
nn.Flatten())
我们创建一个数据样本来查看每个块的输出形状。
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Sequential output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Sequential output shape: torch.Size([1, 384, 12, 12])
MaxPool2d output shape: torch.Size([1, 384, 5, 5])
Dropout output shape: torch.Size([1, 384, 5, 5])
Sequential output shape: torch.Size([1, 10, 5, 5])
AdaptiveAvgPool2d output shape: torch.Size([1, 10, 1, 1])
Flatten output shape: torch.Size([1, 10])
3、训练模型
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
4、小结
- NiN使用由一个卷积层和多个1×1卷积层组成的块。该块可以在卷积神经网络中使用,以允许更多的每像素非线性。
- NiN去除了容易造成过拟合的全连接层,将它们替换为全局平均汇聚层(即在所有位置上进行求和)。该汇聚层通道数量为所需的输出数量(例如,Fashion-MNIST的输出为10)。
- 移除全连接层可减少过拟合,同时显著减少NiN的参数。
- NiN的设计影响了许多后续卷积神经网络的设计。
04 含并行连结的网络-GoogLeNet
GoogLeNet吸收了NiN中串联网络的思想,并在此基础上做了改进。 这篇论文的一个重点是解决了什么样大小的卷积核最合适的问题。
1、Inception块
如何找到最好的卷积层超参数?

1 * 1的卷积、3 * 3的卷积等等,怎么样的才是最好的?
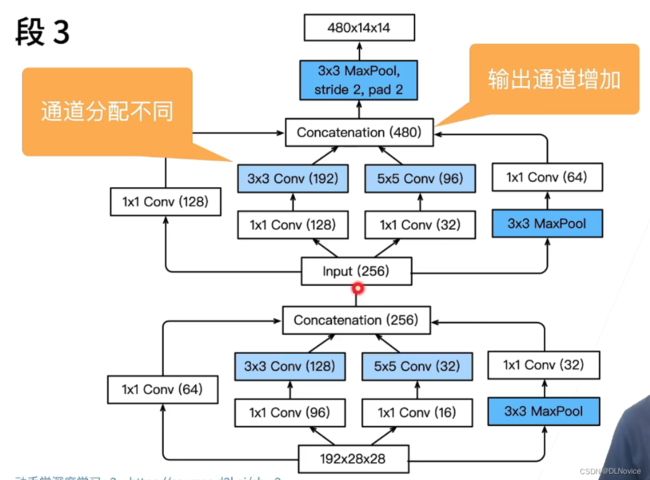
在GoogLeNet中,基本的卷积块被称为Inception块(Inception block)。Inception块的架构如下:

上图中可以看到Inception块由四条并行路径组成,输入被复制了四份传到不同的路径。
- 前三条路径使用窗口大小为1×1、3×3和5×5的卷积层,从不同空间大小中提取信息。
- 中间的两条路径在输入上执行1×1卷积,以减少通道数,从而降低模型的复杂性。
- 第四条路径使用3×3最大汇聚层,然后使用1×1卷积层来改变通道数。
这四条路径都使用合适的填充来使输入与输出的高和宽一致,最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出。在Inception块中,通常调整的超参数是每层输出通道数。
下面看一下通道数的变化:

关于参数个数与计算复杂度:

2、GoogLeNet模型
GoogLeNet一共使用9个Inception块和全局平均汇聚层的堆叠来生成其估计值。Inception块之间的最大汇聚层可降低维度。 第一个模块类似于AlexNet和LeNet,Inception块的组合从VGG继承,全局平均汇聚层避免了在最后使用全连接层。其架构如下:



前面我们用的inception v1 ,后续发展中出现了许多变种:

3、代码实现
下面,我们逐一实现GoogLeNet的每个模块。
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# 搭建Inception块
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
# 我们逐一实现GoogLeNet的每个模块。
# 第一个模块使用64个通道、7*7卷积层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 第二个模块使用两个卷积层:第一个卷积层是64个通道、1*1卷积层;第二个卷积层使用将通道数量增加三倍的3*3卷积层。 这对应于Inception块中的第二条路径。
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 第三个模块串联两个完整的Inception块。
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 第四模块更加复杂, 它串联了5个Inception块
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 第五模块包含两个Inception块
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
下面演示各个模块输出的形状变化。
X = torch.rand(size=(1, 1, 96, 96))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
结果演示:
Sequential output shape: torch.Size([1, 64, 24, 24])
Sequential output shape: torch.Size([1, 192, 12, 12])
Sequential output shape: torch.Size([1, 480, 6, 6])
Sequential output shape: torch.Size([1, 832, 3, 3])
Sequential output shape: torch.Size([1, 1024])
Linear output shape: torch.Size([1, 10])
开始训练:
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
4、总结

- Inception块相当于一个有4条路径的子网络。它通过不同窗口形状的卷积层和最大汇聚层来并行抽取信息,并使用1×1卷积层减少每像素级别上的通道维数从而降低模型复杂度。
- GoogLeNet将多个设计精细的Inception块与其他层(卷积层、全连接层)串联起来。其中Inception块的通道数分配之比是在ImageNet数据集上通过大量的实验得来的。
- GoogLeNet和它的后继者们一度是ImageNet上最有效的模型之一:它以较低的计算复杂度提供了类似的测试精度。
05 批量归一化
训练深层神经网络是十分困难的,深层网络的收敛速度较慢。 在本节中,我们将介绍批量规范化(batch normalization)
1、训练深层网络
为什么出现批量归一化?

什么室批量归一化?

2、批量规范化层
批量规范化和其他层之间的一个关键区别是,由于批量规范化在完整的小批量上运行,因此我们不能像以前在引入其他层时那样忽略批量大小。 我们在下面讨论这两种情况:全连接层和卷积层,他们的批量规范化实现略有不同。


批量归一化在做什么?

总结:
- 批量归一化固定小批量中的均值和方差,然后学习出合适的偏移和缩放
- 可以加速收敛速度,但一般不改变模型精度
3、代码实现
实现一个具有张量的批量规范化层。
import torch
from torch import nn
from d2l import torch as d2l
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 通过is_grad_enabled来判断当前模式是训练模式还是预测模式
if not torch.is_grad_enabled():
# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# 使用全连接层的情况,计算特征维上的均值和方差
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。
# 这里我们需要保持X的形状以便后面可以做广播运算
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
# 训练模式下,用当前的均值和方差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 缩放和移位
return Y, moving_mean.data, moving_var.data
我们现在可以创建一个正确的BatchNorm层。 这个层将保持适当的参数:拉伸gamma和偏移beta,这两个参数将在训练过程中更新。 此外,我们的层将保存均值和方差的移动平均值,以便在模型预测期间随后使用。
class BatchNorm(nn.Module):
# num_features:完全连接层的输出数量或卷积层的输出通道数。
# num_dims:2表示完全连接层,4表示卷积层
def __init__(self, num_features, num_dims):
super().__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# 非模型参数的变量初始化为0和1
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self, X):
# 如果X不在内存上,将moving_mean和moving_var
# 复制到X所在显存上
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var
Y, self.moving_mean, self.moving_var = batch_norm(
X, self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.9)
return Y
为了更好理解如何应用BatchNorm,下面我们将其应用于LeNet模型
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), BatchNorm(16, num_dims=4), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(16*4*4, 120), BatchNorm(120, num_dims=2), nn.Sigmoid(),
nn.Linear(120, 84), BatchNorm(84, num_dims=2), nn.Sigmoid(),
nn.Linear(84, 10))
训练
lr, num_epochs, batch_size = 1.0, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
让我们来看看从第一个批量规范化层中学到的拉伸参数gamma和偏移参数beta。
net[1].gamma.reshape((-1,)), net[1].beta.reshape((-1,))
结果展示:
(tensor([0.3362, 4.0349, 0.4496, 3.7056, 3.7774, 2.6762], device='cuda:0',
grad_fn=<ReshapeAliasBackward0>),
tensor([-0.5739, 4.1376, 0.5126, 0.3060, -2.5187, 0.3683], device='cuda:0',
grad_fn=<ReshapeAliasBackward0>))
简洁实现:除了使用我们刚刚定义的BatchNorm,我们也可以直接使用深度学习框架中定义的BatchNorm。
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(256, 120), nn.BatchNorm1d(120), nn.Sigmoid(),
nn.Linear(120, 84), nn.BatchNorm1d(84), nn.Sigmoid(),
nn.Linear(84, 10))
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
4、争议

5、小结
- 在模型训练过程中,批量规范化利用小批量的均值和标准差,不断调整神经网络的中间输出,使整个神经网络各层的中间输出值更加稳定。
- 批量规范化在全连接层和卷积层的使用略有不同。
- 批量规范化层和暂退层一样,在训练模式和预测模式下计算不同。
- 批量规范化有许多有益的副作用,主要是正则化。另一方面,”减少内部协变量偏移“的原始动机似乎不是一个有效的解释。
06 残差网络-ResNet
ResNet源自一种思想:加深神经网络
背景:何恺明等人提出了残差网络(ResNet) [He et al., 2016a]。 它在2015年的ImageNet图像识别挑战赛夺魁,并深刻影响了后来的深度神经网络的设计。 残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。
1、核心思想
1.1、函数类

补充:
- 恒等映射:对任意集合A,如果映射f:A→A定义为f(a)=a,即规定A中每个元素a与自身对应,则称f为A上的恒等映射(identical [identity] mapping)。

具体做法如下。
1.2、残差块

概念听的有点模糊,可以结合着代码理解:
ResNet沿用了VGG完整的3×3卷积层设计。 残差块里首先有2个有相同输出通道数的3×3卷积层。 每个卷积层后接一个批量规范化层和ReLU激活函数。 然后我们通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前。 这样的设计要求2个卷积层的输出与输入形状一样,从而使它们可以相加。 如果想改变通道数,就需要引入一个额外的1×1卷积层来将输入变换成需要的形状后再做相加运算。
残差块的实现:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module): #@save
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
此代码生成两种类型的网络: 一种是当use_1x1conv=False时,应用ReLU非线性函数之前,将输入添加到输出。 另一种是当use_1x1conv=True时,添加通过1×1卷积调整通道和分辨率。
下面我们来查看输入和输出形状一致的情况。
blk = Residual(3,3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shape
torch.Size([4, 3, 6, 6])
我们也可以在增加输出通道数的同时,减半输出的高和宽。
blk = Residual(3,6, use_1x1conv=True, strides=2)
blk(X).shape
torch.Size([4, 6, 3, 3])

可以使用不同的残差块:

2、ResNet模型

不同的ResNet块数量和数据通道数,可以得到不同的ResNet架构
ResNet的前两层跟之前介绍的GoogLeNet中的一样: 在输出通道数为64、步幅为2的7×7卷积层后,接步幅为2的3×3的最大汇聚层。 不同之处在于ResNet每个卷积层后增加了批量规范化层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
GoogLeNet在后面接了4个由Inception块组成的模块。 ResNet则使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。 第一个模块的通道数同输入通道数一致。 由于之前已经使用了步幅为2的最大汇聚层,所以无须减小高和宽。 之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
下面我们来实现这个模块。注意,我们对第一个模块做了特别处理。
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
接着在ResNet加入所有残差块,这里每个模块使用2个残差块。
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
最后,与GoogLeNet一样,在ResNet中加入全局平均汇聚层,以及全连接层输出。
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10))
每个模块有4个卷积层(不包括恒等映射的1×1卷积层)。 加上第一个7×7卷积层和最后一个全连接层,共有18层。 因此,这种模型通常被称为ResNet-18。 通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型,例如更深的含152层的ResNet-152。 虽然ResNet的主体架构跟GoogLeNet类似,但ResNet架构更简单,修改也更方便。这些因素都导致了ResNet迅速被广泛使用。下图描述了完整的ResNet-18。

在训练ResNet之前,让我们观察一下ResNet中不同模块的输入形状是如何变化的。 在之前所有架构中,分辨率降低,通道数量增加,直到全局平均汇聚层聚集所有特征。
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
开始训练:
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
2.1 整合代码
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module): #@save
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
# ResNet的前两层跟之前介绍的GoogLeNet中的一样: 在输出通道数为64、步幅为2的卷积层后,接步幅为2的的最大汇聚层。 不同之处在于ResNet每个卷积层后增加了批量规范化层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# GoogLeNet在后面接了4个由Inception块组成的模块。 ResNet则使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。 第一个模块的通道数同输入通道数一致。 由于之前已经使用了步幅为2的最大汇聚层,所以无须减小高和宽。 之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
#下面我们来实现这个模块。注意,我们对第一个模块做了特别处理。
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
# 接着在ResNet加入所有残差块,这里每个模块使用2个残差块。
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
# 最后,与GoogLeNet一样,在ResNet中加入全局平均汇聚层,以及全连接层输出。
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10))
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
3、总结
- 残差块使得很深的网络更加容易训练
- 甚至可以训练一千层的网络
- 残差网络对随后的深层神经网络设计产生了深远影响,无论是卷积类网络还是全连接类网络
- 学习嵌套函数(nested function)是训练神经网络的理想情况。在深层神经网络中,学习另一层作为恒等映射(identity function)较容易(尽管这是一个极端情况)。
- 残差映射可以更容易地学习同一函数,例如将权重层中的参数近似为零。
- 利用残差块(residual blocks)可以训练出一个有效的深层神经网络:输入可以通过层间的残余连接更快地向前传播。
- 残差网络(ResNet)对随后的深层神经网络设计产生了深远影响。
4、ResNet为什么能训练出1000层的模型
- 29.2 ResNet为什么能训练出1000层的模型【动手学深度学习v2】_哔哩哔哩_bilibili
07 稠密连接网络-DenseNet
- 7.7. 稠密连接网络(DenseNet) — 动手学深度学习 2.0.0-beta1 documentation (d2l.ai)
08 竞赛:图像分类
视频:30 第二部分完结竞赛:图片分类【动手学深度学习v2】_哔哩哔哩_bilibili
竞赛地址:https://www.kaggle.com/c/classify-leaves
- 38 第二次竞赛 树叶分类结果【动手学深度学习v2】_哔哩哔哩_bilibili
- 39 实战 Kaggle 比赛:图像分类(CIFAR-10)【动手学深度学习v2】_哔哩哔哩_bilibili
- 40 实战 Kaggle 比赛:狗的品种识别(ImageNet Dogs)【动手学深度学习v2】_哔哩哔哩_bilibili
- 43 树叶分类竞赛技术总结【动手学深度学习v2】_哔哩哔哩_bilibili