NeRF神经辐射场学习笔记(二)——Pytorch版NeRF实现以及代码注释
NeRF神经辐射场学习笔记(二)——Pytorch版NeRF实现以及代码注释
- 声明
- NeRF-Pytorch源码地址
- 准备工作
-
- Win10下Anaconda环境配置
- GPU版Pytorch安装
- Vscode下运行NeRF-Pytorch代码
-
- 安装命令
- 数据下载
- 训练数据
- NeRF-Pytorch代码详解
-
- Vscode代码调试
- 代码框架概述
- 1.参数设置
- 2.数据加载
-
- 代码流程图
- load_llff_data()
- _load_data()
-
- _minify()
- recenter_poses()
- render_path_spiral()
- 3.NeRF网络构建
-
- 代码流程图
- NeRF网络结构图
- create_nerf()
-
- get_embedder()
-
- class Embedder
- class NeRF
- run_network()
- Optimizer
- 4.生成rays数据
-
- 代码流程图
- get_rays_np()
- 5.体素渲染
-
- 代码流程图
- render()
-
- batchify_rays()
-
- render_rays()
-
- raw2outputs()
- sample_pdf()
- 6.loss计算+训练
-
- 代码流程图
- img2mse()
- train()
- 参考文献和资料
声明
本人书写本系列博客目的是为了记录我学习三维重建领域相关知识的过程和心得,不涉及任何商业意图,欢迎互相交流,批评指正。
NeRF-Pytorch源码地址
NeRF作者所给出的源码是TensorFlow版本的,由于本人的学习需求,所以采用来自yenchen lin的Pytorch版代码进行实现和注释,该版本是基于原版的NeRF所复现的,而且在实现的基础上还要比原版的结果输出时间快了1.3倍;
源码GitHub地址为:https://github.com/yenchenlin/nerf-pytorch.git
准备工作
Win10下Anaconda环境配置
参考教程
GPU版Pytorch安装
参考教程
Vscode下运行NeRF-Pytorch代码
安装命令
git clone https://github.com/yenchenlin/nerf-pytorch.git
cd nerf-pytorch
pip install -r requirements.txt
- 下载好源码后需要进入项目所在目录下,并且激活对应的conda环境(conda activate );
- 若安装超时,可以参考教程换源后逐个安装;
- 安装的package中pytorch的版本没有硬性要求,但一定要和CUDA版本对应;
数据下载
bash download_example_data.sh
安装好后的数据集文件夹:
训练数据
python run_nerf.py --config configs/lego.txt
若出现如下报错,参考教程进行更改:![]()
在run_nerf.py的第206行添加相应语句即可:
optimizer.param_groups[0]['capturable'] = True

紧接着开始训练,训练完成后查看训练结果:

渲染的结果和相关参数全部存在./log/blender_paper_lego当中,包括测试渲染出的图片以及视频等;
NeRF-Pytorch代码详解
Vscode代码调试
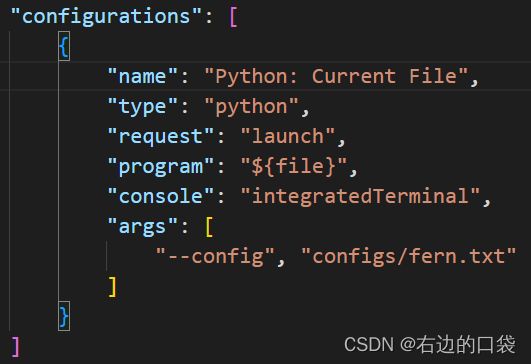
在调试过程中我们所用到的参数采用./config/configs.txt中的参数,所以在调试时,我们要将参数传入调试命令,添加launch.json的具体操作参考教程,我们在配置文件中添加"args"参数,如下图所示:
代码框架概述

1.参数设置
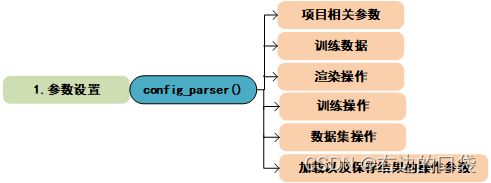
# 参数设置
def config_parser():
import configargparse
parser = configargparse.ArgumentParser()
# 生成config.txt文件
parser.add_argument('--config', is_config_file=True,
help='config file path')
# 指定实验名称
parser.add_argument("--expname", type=str,
help='experiment name')
# 指定实验结果的输出路径
parser.add_argument("--basedir", type=str, default='./logs/',
help='where to store ckpts and logs')
# 输入数据的目录
parser.add_argument("--datadir", type=str, default='./data/nerf_llff_data/fern',
help='input data directory')
# training options,训练相关数据;
# 网络层数
parser.add_argument("--netdepth", type=int, default=8,
help='layers in network')
# 每层通道数
parser.add_argument("--netwidth", type=int, default=256,
help='channels per layer')
# fine网络中的层数
parser.add_argument("--netdepth_fine", type=int, default=8,
help='layers in fine network')
# fine网络每层通道数
parser.add_argument("--netwidth_fine", type=int, default=256,
help='channels per layer in fine network')
# batch size指的是每次梯度下降的随机射线的数量
parser.add_argument("--N_rand", type=int, default=32*32*4,
help='batch size (number of random rays per gradient step)')
# 学习率
parser.add_argument("--lrate", type=float, default=5e-4,
help='learning rate')
# 在1000次迭代中的指数学习率衰减
parser.add_argument("--lrate_decay", type=int, default=250,
help='exponential learning rate decay (in 1000 steps)')
# 并行处理射线的数量,如果超出内存则降低
parser.add_argument("--chunk", type=int, default=1024*32,
help='number of rays processed in parallel, decrease if running out of memory')
# 并行处理输入网络的点的数量,如果超出内存则降低
parser.add_argument("--netchunk", type=int, default=1024*64,
help='number of pts sent through network in parallel, decrease if running out of memory')
# no_batching指的是每次只从一张图像中选取随机射线
parser.add_argument("--no_batching", action='store_true',
help='only take random rays from 1 image at a time')
# no-reload指的是不从保存的模型ckpt文件中载入权重
parser.add_argument("--no_reload", action='store_true',
help='do not reload weights from saved ckpt')
# 为coarse网络载入特定的权重文件
parser.add_argument("--ft_path", type=str, default=None,
help='specific weights npy file to reload for coarse network')
# rendering options,渲染操作
# 每条射线的粗样本数量
parser.add_argument("--N_samples", type=int, default=64,
help='number of coarse samples per ray')
# 每条射线额外的精细样本数量
parser.add_argument("--N_importance", type=int, default=0,
help='number of additional fine samples per ray')
# jitter指的是抖动,设为0是无抖动
parser.add_argument("--perturb", type=float, default=1.,
help='set to 0. for no jitter, 1. for jitter')
# 用完整的5D信息代替3D信息
parser.add_argument("--use_viewdirs", action='store_true',
help='use full 5D input instead of 3D')
# 是否加入位置编码操作,设为0是默认采用位置编码方法,-1则无
parser.add_argument("--i_embed", type=int, default=0,
help='set 0 for default positional encoding, -1 for none')
# 位置编码操作对于3D位置信息的所升维数,默认L=10
parser.add_argument("--multires", type=int, default=10,
help='log2 of max freq for positional encoding (3D location)')
# 位置编码操作对于2D方向信息的所升维数,默认L=4
parser.add_argument("--multires_views", type=int, default=4,
help='log2 of max freq for positional encoding (2D direction)')
# 加在规范化不透明度输出sigma上的噪声的标准差
parser.add_argument("--raw_noise_std", type=float, default=0.,
help='std dev of noise added to regularize sigma_a output, 1e0 recommended')
# 只渲染,不进行优化等训练操作,相当于前向传播
parser.add_argument("--render_only", action='store_true',
help='do not optimize, reload weights and render out render_poses path')
# 渲染测试集代替render_poses路径
parser.add_argument("--render_test", action='store_true',
help='render the test set instead of render_poses path')
# 下采样因子以加快渲染速度,一般设为4/8用于快速预览
parser.add_argument("--render_factor", type=int, default=0,
help='downsampling factor to speed up rendering, set 4 or 8 for fast preview')
# training options,训练操作
# 中心crops上训练的迭代次数
parser.add_argument("--precrop_iters", type=int, default=0,
help='number of steps to train on central crops')
parser.add_argument("--precrop_frac", type=float,
default=.5, help='fraction of img taken for central crops')
# dataset options,数据集操作
# 数据类型,包括三种llff、blender、deepvoxels
parser.add_argument("--dataset_type", type=str, default='llff',
help='options: llff / blender / deepvoxels')
# 测试集与验证集加载数据的比例,分别为1:N,对于大型数据集很有效
parser.add_argument("--testskip", type=int, default=8,
help='will load 1/N images from test/val sets, useful for large datasets like deepvoxels')
## deepvoxels flags
parser.add_argument("--shape", type=str, default='greek',
help='options : armchair / cube / greek / vase')
## blender flags
parser.add_argument("--white_bkgd", action='store_true',
help='set to render synthetic data on a white bkgd (always use for dvoxels)')
parser.add_argument("--half_res", action='store_true',
help='load blender synthetic data at 400x400 instead of 800x800')
## llff flags
# 图像下采样率
parser.add_argument("--factor", type=int, default=8,
help='downsample factor for LLFF images')
# 是否使用标准化坐标系
parser.add_argument("--no_ndc", action='store_true',
help='do not use normalized device coordinates (set for non-forward facing scenes)')
# 在不透明度上均匀采样代替深度值
parser.add_argument("--lindisp", action='store_true',
help='sampling linearly in disparity rather than depth')
# 360度场景
parser.add_argument("--spherify", action='store_true',
help='set for spherical 360 scenes')
# 每N个图像采用1个图像进行测试,默认N=8
parser.add_argument("--llffhold", type=int, default=8,
help='will take every 1/N images as LLFF test set, paper uses 8')
# logging/saving options,加载以及保存结果的操作参数
# 训练数据的输出频率
parser.add_argument("--i_print", type=int, default=100,
help='frequency of console printout and metric loggin')
# tensorboard图像记录频率
parser.add_argument("--i_img", type=int, default=500,
help='frequency of tensorboard image logging')
# 权重保存频率
parser.add_argument("--i_weights", type=int, default=10000,
help='frequency of weight ckpt saving')
# 测试结果保存频率
parser.add_argument("--i_testset", type=int, default=50000,
help='frequency of testset saving')
# render_poses视频保存频率
parser.add_argument("--i_video", type=int, default=50000,
help='frequency of render_poses video saving')
return parser
2.数据加载
代码流程图

load_llff_data()
def load_llff_data(basedir, factor=8, recenter=True, bd_factor=.75, spherify=False, path_zflat=False):
poses, bds, imgs = _load_data(basedir, factor=factor) # factor=8 downsamples original imgs by 8x
print('Loaded', basedir, bds.min(), bds.max())
# Correct rotation matrix ordering and move variable dim to axis 0
'''
np.concatenate([poses[:, 1:2, :], -poses[:, 0:1, :], poses[:, 2:, :]], 1)指的是进行矩阵变换,将poses每个通道的第0行的相反数和第1行互换位置;
紧接着用np.moveaxis(poses, -1, 0).astype(np.float32)将坐标轴的第-1轴换到第0轴;
得到的poses的shape为(20,3,5)
imgs同理,变换完的shape为(20,378,504,3)
bds的shape为(20,2)
'''
poses = np.concatenate([poses[:, 1:2, :], -poses[:, 0:1, :], poses[:, 2:, :]], 1)
poses = np.moveaxis(poses, -1, 0).astype(np.float32)
imgs = np.moveaxis(imgs, -1, 0).astype(np.float32)
images = imgs
bds = np.moveaxis(bds, -1, 0).astype(np.float32)
# Rescale if bd_factor is provided
# 深度边界和平移变换向量一同进行缩放
sc = 1. if bd_factor is None else 1./(bds.min() * bd_factor)
poses[:,:3,3] *= sc
bds *= sc
if recenter:
# 计算poses的均值,将所有pose做该均值的逆转换,即重新定义了世界坐标系,原点大致在被测物中心;
poses = recenter_poses(poses)
if spherify:
poses, render_poses, bds = spherify_poses(poses, bds)
else:
# 经过recenter pose均值逆变换处理后,旋转矩阵变为单位阵,平移矩阵变为0
'''[[ 1.0000000e+00 0.0000000e+00 0.0000000e+00 1.4901161e-09]
[ 0.0000000e+00 1.0000000e+00 -1.8730975e-09 -9.6857544e-09]
[-0.0000000e+00 1.8730975e-09 1.0000000e+00 0.0000000e+00]]
'''
c2w = poses_avg(poses)
print('recentered', c2w.shape)
print(c2w[:3,:4])
## Get spiral
# Get average pose
up = normalize(poses[:, :3, 1].sum(0))
# Find a reasonable "focus depth" for this dataset
close_depth, inf_depth = bds.min()*.9, bds.max()*5.
dt = .75
mean_dz = 1./(((1.-dt)/close_depth + dt/inf_depth))
# 定义新的焦距focal
focal = mean_dz
# Get radii for spiral path
shrink_factor = .8
zdelta = close_depth * .2
tt = poses[:,:3,3] # ptstocam(poses[:3,3,:].T, c2w).T
rads = np.percentile(np.abs(tt), 90, 0)
c2w_path = c2w
N_views = 120
N_rots = 2
if path_zflat:
# zloc = np.percentile(tt, 10, 0)[2]
zloc = -close_depth * .1
c2w_path[:3,3] = c2w_path[:3,3] + zloc * c2w_path[:3,2]
rads[2] = 0.
N_rots = 1
N_views/=2
# Generate poses for spiral path
# 生成用来渲染的螺旋路径的位姿,是一个list,有120个(N_views)元素,每个元素shape(3,5)
render_poses = render_path_spiral(c2w_path, up, rads, focal, zdelta, zrate=.5, rots=N_rots, N=N_views)
render_poses = np.array(render_poses).astype(np.float32)
c2w = poses_avg(poses)
print('Data:')
print(poses.shape, images.shape, bds.shape) # (20, 3, 5) (20, 378, 504, 3) (20, 2)
dists = np.sum(np.square(c2w[:3,3] - poses[:,:3,3]), -1)
i_test = np.argmin(dists) # 距离最小值对应的下标,12
print('HOLDOUT view is', i_test)
images = images.astype(np.float32)
poses = poses.astype(np.float32)
return images, poses, bds, render_poses, i_test
_load_data()
# _load_data将图片下采样后输出imgs,并且输出数据集的位姿参数poses和深度范围bds
def _load_data(basedir, factor=None, width=None, height=None, load_imgs=True):
# 用load读取'./data/nerf_llff_data/fern/poses_bounds.npy'文件
poses_arr = np.load(os.path.join(basedir, 'poses_bounds.npy'))
poses = poses_arr[:, :-2].reshape([-1, 3, 5]).transpose([1,2,0])
'''
.npy文件是一个shape为(20,17),dtype为float64的array,20代表数据集的个数(一共有20张图片),17代表位姿参数。
poses_arr[:, :-2]代表取前15列,为一个(20,15)的array,
reshape([-1, 3, 5])代表将(20,15)的array转换为(20,3,5)的array,也就是把15列的一维数据变为3*5的二维数据。
transpose([1,2,0])则是将array的坐标系调换顺序,0换到2, 1、2换到0、1,shape变为(3,5,20);
最后poses输出的是一个(3,5,20)的array
'''
bds = poses_arr[:, -2:].transpose([1,0])
'''
poses_arr[:, -2:].transpose([1,0])则是先提取poses_arr的后两列数据(20,2),然后将0,1坐标系对调,得到(2,20)shape的array:bds
bds指的是bounds深度范围
'''
# img0是20张图像中的第一张图像的路径名称,'./data/nerf_llff_data/fern\\images\\IMG_4026.JPG'
img0 = [os.path.join(basedir, 'images', f) for f in sorted(os.listdir(os.path.join(basedir, 'images'))) \
if f.endswith('JPG') or f.endswith('jpg') or f.endswith('png')][0]
sh = imageio.imread(img0).shape # 读取图片大小为(3024, 4032, 3)
sfx = ''
# 判断是否有下采样的相关参数,如果有,则对图像进行下采样
if factor is not None:
sfx = '_{}'.format(factor) # sfx='_8'
_minify(basedir, factors=[factor])
factor = factor
elif height is not None:
factor = sh[0] / float(height)
width = int(sh[1] / factor)
_minify(basedir, resolutions=[[height, width]])
sfx = '_{}x{}'.format(width, height)
elif width is not None:
factor = sh[1] / float(width)
height = int(sh[0] / factor)
_minify(basedir, resolutions=[[height, width]])
sfx = '_{}x{}'.format(width, height)
else:
factor = 1
# 判断是否存在下采样的路径'./data/nerf_llff_data/fern\\images_8'
imgdir = os.path.join(basedir, 'images' + sfx)
if not os.path.exists(imgdir):
print( imgdir, 'does not exist, returning' )
return
# 判断pose数量与图像个数是否一致,
imgfiles = [os.path.join(imgdir, f) for f in sorted(os.listdir(imgdir)) if f.endswith('JPG') or f.endswith('jpg') or f.endswith('png')] # 将下采样图片进行排序,存到imgfiles这个list中
if poses.shape[-1] != len(imgfiles):
print( 'Mismatch between imgs {} and poses {} !!!!'.format(len(imgfiles), poses.shape[-1]) )
return
# 获取处理后的图像shape,sh=(378,504,3)=(3024/8, 4032/8, 3)
sh = imageio.imread(imgfiles[0]).shape
poses[:2, 4, :] = np.array(sh[:2]).reshape([2, 1])
poses[2, 4, :] = poses[2, 4, :] * 1./factor
'''
sh[:2]存的是前两个数据,也就是图片单通道的大小(378,504);
np.array(sh[:2]).reshape([2, 1])将其先array化后reshape为2*1的大小:array([[378],[504]])
poses[:2, 4, :] = np.array(sh[:2]).reshape([2, 1])则表示将poses中3*5矩阵的前两行的第5列存放height=378,width=504;
poses[2, 4, :]则表示第三行第5列的存放图像的分辨率f,更新f的值最后为3261/8=407.56579161
另外,3*5矩阵的前3行3列为旋转变换矩阵,第4列为平移变换矩阵,第5列为h、w、f;
'''
if not load_imgs:
return poses, bds
def imread(f):
if f.endswith('png'):
return imageio.imread(f, ignoregamma=True)
else:
return imageio.imread(f)
# 读取所有图像数据并把值缩小到0-1之间,imgs存储所有图片信息,大小为(378,504,3,20)
imgs = imgs = [imread(f)[...,:3]/255. for f in imgfiles]
imgs = np.stack(imgs, -1)
print('Loaded image data', imgs.shape, poses[:,-1,0]) # poses[:,-1,0]的值为array([378. , 504. , 407.56579161])
return poses, bds, imgs
_minify()
# 两种类型的图片处理:factors传入下采样的参数、resolution传入规定大小的图像参数;
def _minify(basedir, factors=[], resolutions=[]):
needtoload = False
# 创建下采样的文件夹,'./data/nerf_llff_data/fern\\images_8'
for r in factors:
imgdir = os.path.join(basedir, 'images_{}'.format(r))
if not os.path.exists(imgdir):
needtoload = True
for r in resolutions:
imgdir = os.path.join(basedir, 'images_{}x{}'.format(r[1], r[0]))
if not os.path.exists(imgdir):
needtoload = True
# 如果两者都没有或者处理后的图片文件已存在,则不进行处理
if not needtoload:
return
from shutil import copy
from subprocess import check_output
imgdir = os.path.join(basedir, 'images')
imgs = [os.path.join(imgdir, f) for f in sorted(os.listdir(imgdir))]
imgs = [f for f in imgs if any([f.endswith(ex) for ex in ['JPG', 'jpg', 'png', 'jpeg', 'PNG']])]
imgdir_orig = imgdir
wd = os.getcwd()
for r in factors + resolutions:
if isinstance(r, int):
name = 'images_{}'.format(r)
resizearg = '{}%'.format(100./r)
else:
name = 'images_{}x{}'.format(r[1], r[0])
resizearg = '{}x{}'.format(r[1], r[0])
imgdir = os.path.join(basedir, name)
if os.path.exists(imgdir):
continue
print('Minifying', r, basedir)
os.makedirs(imgdir)
check_output('cp {}/* {}'.format(imgdir_orig, imgdir), shell=True)
ext = imgs[0].split('.')[-1]
args = ' '.join(['mogrify', '-resize', resizearg, '-format', 'png', '*.{}'.format(ext)])
print(args)
os.chdir(imgdir)
check_output(args, shell=True)
os.chdir(wd)
if ext != 'png':
check_output('rm {}/*.{}'.format(imgdir, ext), shell=True)
print('Removed duplicates')
print('Done')
recenter_poses()
def recenter_poses(poses):
poses_ = poses+0
bottom = np.reshape([0,0,0,1.], [1,4])
c2w = poses_avg(poses)
c2w = np.concatenate([c2w[:3,:4], bottom], -2)
bottom = np.tile(np.reshape(bottom, [1,1,4]), [poses.shape[0],1,1])
poses = np.concatenate([poses[:,:3,:4], bottom], -2)
poses = np.linalg.inv(c2w) @ poses
poses_[:,:3,:4] = poses[:,:3,:4]
poses = poses_
return poses
render_path_spiral()
def render_path_spiral(c2w, up, rads, focal, zdelta, zrate, rots, N):
render_poses = []
rads = np.array(list(rads) + [1.])
hwf = c2w[:,4:5]
for theta in np.linspace(0., 2. * np.pi * rots, N+1)[:-1]:
c = np.dot(c2w[:3,:4], np.array([np.cos(theta), -np.sin(theta), -np.sin(theta*zrate), 1.]) * rads)
z = normalize(c - np.dot(c2w[:3,:4], np.array([0,0,-focal, 1.])))
render_poses.append(np.concatenate([viewmatrix(z, up, c), hwf], 1))
return render_poses
3.NeRF网络构建
代码流程图
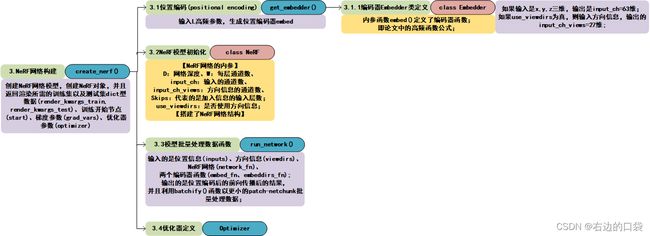
NeRF网络结构图
create_nerf()
def create_nerf(args):
"""Instantiate NeRF's MLP model.
"""
# 对x,y,z和方向信息都进行了位置编码,输入是x,y,z三维,输出是input_ch=63维;如果use_viewdirs为真,则input_ch_views=27维;
embed_fn, input_ch = get_embedder(args.multires, args.i_embed)
input_ch_views = 0
embeddirs_fn = None
if args.use_viewdirs:
embeddirs_fn, input_ch_views = get_embedder(args.multires_views, args.i_embed)
# 输出的通道数
output_ch = 5 if args.N_importance > 0 else 4
skips = [4]
model = NeRF(D=args.netdepth, W=args.netwidth,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
grad_vars = list(model.parameters()) # 梯度
model_fine = None
if args.N_importance > 0:
model_fine = NeRF(D=args.netdepth_fine, W=args.netwidth_fine,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
grad_vars += list(model_fine.parameters())
# 定义一个查询函数,
network_query_fn = lambda inputs, viewdirs, network_fn : run_network(inputs, viewdirs, network_fn,
embed_fn=embed_fn,
embeddirs_fn=embeddirs_fn,
netchunk=args.netchunk)
# Create optimizer
optimizer = torch.optim.Adam(params=grad_vars, lr=args.lrate, betas=(0.9, 0.999))
optimizer.param_groups[0]['capturable'] = True
start = 0
basedir = args.basedir
expname = args.expname
##########################
# Load checkpoints
# 加载已有模型参数
if args.ft_path is not None and args.ft_path!='None':
ckpts = [args.ft_path]
else:
ckpts = [os.path.join(basedir, expname, f) for f in sorted(os.listdir(os.path.join(basedir, expname))) if 'tar' in f]
print('Found ckpts', ckpts)
if len(ckpts) > 0 and not args.no_reload:
ckpt_path = ckpts[-1]
print('Reloading from', ckpt_path)
ckpt = torch.load(ckpt_path)
start = ckpt['global_step']
optimizer.load_state_dict(ckpt['optimizer_state_dict'])
# Load model
model.load_state_dict(ckpt['network_fn_state_dict'])
if model_fine is not None:
model_fine.load_state_dict(ckpt['network_fine_state_dict'])
##########################
render_kwargs_train = {
'network_query_fn' : network_query_fn,
'perturb' : args.perturb,
'N_importance' : args.N_importance,
'network_fine' : model_fine,
'N_samples' : args.N_samples,
'network_fn' : model,
'use_viewdirs' : args.use_viewdirs,
'white_bkgd' : args.white_bkgd,
'raw_noise_std' : args.raw_noise_std,
}
# NDC only good for LLFF-style forward facing data
if args.dataset_type != 'llff' or args.no_ndc:
print('Not ndc!')
render_kwargs_train['ndc'] = False
render_kwargs_train['lindisp'] = args.lindisp
render_kwargs_test = {k : render_kwargs_train[k] for k in render_kwargs_train}
render_kwargs_test['perturb'] = False
render_kwargs_test['raw_noise_std'] = 0.
return render_kwargs_train, render_kwargs_test, start, grad_vars, optimizer
get_embedder()
def get_embedder(multires, i=0):
if i == -1:
return nn.Identity(), 3
embed_kwargs = {
'include_input' : True, # 如果为真,最终的编码结果包含原始坐标;
'input_dims' : 3, # 输入给编码器的数据维度;
'max_freq_log2' : multires-1,
'num_freqs' : multires, # 位置编码公式中的L
'log_sampling' : True,
'periodic_fns' : [torch.sin, torch.cos], # 位置编码公式中的两个基本函数;
}
embedder_obj = Embedder(**embed_kwargs) # 创建一个编码器对象
embed = lambda x, eo=embedder_obj : eo.embed(x) # 调用编码器对象中的embed()函数,定义embed编码器函数;
return embed, embedder_obj.out_dim
class Embedder
# Positional encoding (section 5.1)
class Embedder:
def __init__(self, **kwargs):
self.kwargs = kwargs
self.create_embedding_fn()
def create_embedding_fn(self):
embed_fns = []
d = self.kwargs['input_dims']
out_dim = 0
if self.kwargs['include_input']:
embed_fns.append(lambda x : x)
out_dim += d
max_freq = self.kwargs['max_freq_log2']
N_freqs = self.kwargs['num_freqs']
if self.kwargs['log_sampling']:
freq_bands = 2.**torch.linspace(0., max_freq, steps=N_freqs)
else:
freq_bands = torch.linspace(2.**0., 2.**max_freq, steps=N_freqs)
for freq in freq_bands:
for p_fn in self.kwargs['periodic_fns']:
embed_fns.append(lambda x, p_fn=p_fn, freq=freq : p_fn(x * freq))
out_dim += d
self.embed_fns = embed_fns
self.out_dim = out_dim
def embed(self, inputs):
return torch.cat([fn(inputs) for fn in self.embed_fns], -1)
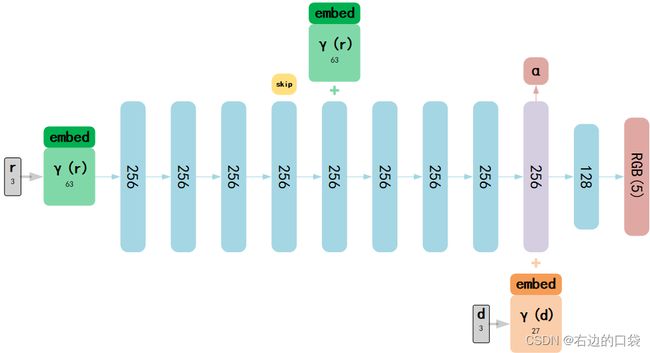
class NeRF
# Model
class NeRF(nn.Module):
def __init__(self, D=8, W=256, input_ch=3, input_ch_views=3, output_ch=4, skips=[4], use_viewdirs=False):
"""
"""
super(NeRF, self).__init__()
self.D = D # 网络深度,8层
self.W = W # 每层通道数,256
self.input_ch = input_ch # 输入的通道数=3(x,y,z)
self.input_ch_views = input_ch_views # 方向信息的通道数=3
self.skips = skips # skip代表的是加入的信息的输入位置、层数;
self.use_viewdirs = use_viewdirs # 是否使用方向信息;
# 生成D层全连接层,并且在skip+1层加入input_pts;
self.pts_linears = nn.ModuleList(
[nn.Linear(input_ch, W)] + [nn.Linear(W, W) if i not in self.skips else nn.Linear(W + input_ch, W) for i in range(D-1)])
### Implementation according to the official code release (https://github.com/bmild/nerf/blob/master/run_nerf_helpers.py#L104-L105)
# 对view处理的网络层,27+256->128
self.views_linears = nn.ModuleList([nn.Linear(input_ch_views + W, W//2)])
### Implementation according to the paper
# self.views_linears = nn.ModuleList(
# [nn.Linear(input_ch_views + W, W//2)] + [nn.Linear(W//2, W//2) for i in range(D//2)])
# 输出特征alpha(第8层)和RGB最后结果
if use_viewdirs:
self.feature_linear = nn.Linear(W, W)
self.alpha_linear = nn.Linear(W, 1)
self.rgb_linear = nn.Linear(W//2, 3)
else:
self.output_linear = nn.Linear(W, output_ch)
def forward(self, x):
input_pts, input_views = torch.split(x, [self.input_ch, self.input_ch_views], dim=-1)
h = input_pts
for i, l in enumerate(self.pts_linears):
h = self.pts_linears[i](h)
h = F.relu(h)
if i in self.skips:
h = torch.cat([input_pts, h], -1)
if self.use_viewdirs:
alpha = self.alpha_linear(h)
feature = self.feature_linear(h)
h = torch.cat([feature, input_views], -1)
for i, l in enumerate(self.views_linears):
h = self.views_linears[i](h)
h = F.relu(h)
rgb = self.rgb_linear(h)
outputs = torch.cat([rgb, alpha], -1)
else:
outputs = self.output_linear(h)
return outputs
run_network()
def run_network(inputs, viewdirs, fn, embed_fn, embeddirs_fn, netchunk=1024*64):
"""Prepares inputs and applies network 'fn'.
"""
inputs_flat = torch.reshape(inputs, [-1, inputs.shape[-1]]) # torch.Size([65536, 3])
embedded = embed_fn(inputs_flat) # torch.Size([65536, 63])
if viewdirs is not None:
input_dirs = viewdirs[:,None].expand(inputs.shape) # torch.Size([1024, 64, 3])
input_dirs_flat = torch.reshape(input_dirs, [-1, input_dirs.shape[-1]]) # torch.Size([65536, 3])
embedded_dirs = embeddirs_fn(input_dirs_flat) # torch.Size([65536, 27])
embedded = torch.cat([embedded, embedded_dirs], -1) # 将两个张量拼接在一起,torch.Size([65536, 90])
# 以更小的patch-netchunk送进网络跑前向
outputs_flat = batchify(fn, netchunk)(embedded) # (65536,4)
# reshape为(1024,64,4),4包括RGB和alpha;
outputs = torch.reshape(outputs_flat, list(inputs.shape[:-1]) + [outputs_flat.shape[-1]])
return outputs
Optimizer
# Create optimizer
optimizer = torch.optim.Adam(params=grad_vars, lr=args.lrate, betas=(0.9, 0.999))
optimizer.param_groups[0]['capturable'] = True
4.生成rays数据
代码流程图

get_rays_np()
# 获得光束的方法
def get_rays_np(H, W, K, c2w):
i, j = np.meshgrid(np.arange(W, dtype=np.float32), np.arange(H, dtype=np.float32), indexing='xy') # meshgrid函数将图像的坐标id分别取出存入i(列号)、j(行号),shape为(378,504)
# 2D点到3D点的映射计算,[x,y,z]=[(u-cx)/fx,-(-v-cy)/fx,-1]
# 在y和z轴均取相反数,因为nerf使用的坐标系x轴向右,y轴向上,z轴向外;
# dirs的大小为(378, 504, 3)
dirs = np.stack([(i-K[0][2])/K[0][0], -(j-K[1][2])/K[1][1], -np.ones_like(i)], -1)
# Rotate ray directions from camera frame to the world frame
# 将ray方向从相机坐标系转到世界坐标系,矩阵不变
rays_d = np.sum(dirs[..., np.newaxis, :] * c2w[:3,:3], -1) # dot product, equals to: [c2w.dot(dir) for dir in dirs]
# Translate camera frame's origin to the world frame. It is the origin of all rays.
# 相机原点在世界坐标系的坐标,同一个相机所有ray的起点;
rays_o = np.broadcast_to(c2w[:3,-1], np.shape(rays_d)) # [1024,3]
return rays_o, rays_d
5.体素渲染
代码流程图

render()
def render(H, W, K, chunk=1024*32, rays=None, c2w=None, ndc=True,
near=0., far=1.,
use_viewdirs=False, c2w_staticcam=None,
**kwargs):
"""Render rays
Args:
H: int. Height of image in pixels.图像高度
W: int. Width of image in pixels.图像宽度
focal: float. Focal length of pinhole camera.针孔相机焦距
chunk: int. Maximum number of rays to process simultaneously. Used to
control maximum memory usage. Does not affect final results.同步处理的最大光线数
rays: array of shape [2, batch_size, 3]. Ray origin and direction for
each example in batch. 2表示每个batch的原点和方向;
c2w: array of shape [3, 4]. Camera-to-world transformation matrix.相机到世界的旋转矩阵
ndc: bool. If True, represent ray origin, direction in NDC coordinates.
near: float or array of shape [batch_size]. Nearest distance for a ray.
far: float or array of shape [batch_size]. Farthest distance for a ray.
use_viewdirs: bool. If True, use viewing direction of a point in space in model.
c2w_staticcam: array of shape [3, 4]. If not None, use this transformation matrix for
camera while using other c2w argument for viewing directions.
Returns:
rgb_map: [batch_size, 3]. Predicted RGB values for rays.预测的RGB图
disp_map: [batch_size]. Disparity map. Inverse of depth.视差图
acc_map: [batch_size]. Accumulated opacity (alpha) along a ray.深度图、不透明度、alpha
extras: dict with everything returned by render_rays().
"""
if c2w is not None:
# special case to render full image
rays_o, rays_d = get_rays(H, W, K, c2w)
else:
# use provided ray batch
rays_o, rays_d = rays
if use_viewdirs:
# provide ray directions as input
viewdirs = rays_d
if c2w_staticcam is not None:
# special case to visualize effect of viewdirs
rays_o, rays_d = get_rays(H, W, K, c2w_staticcam)
viewdirs = viewdirs / torch.norm(viewdirs, dim=-1, keepdim=True)
viewdirs = torch.reshape(viewdirs, [-1,3]).float()
sh = rays_d.shape # [..., 3]
if ndc:
# for forward facing scenes
rays_o, rays_d = ndc_rays(H, W, K[0][0], 1., rays_o, rays_d)
# Create ray batch
rays_o = torch.reshape(rays_o, [-1,3]).float() # torch.Size([1024, 3])
rays_d = torch.reshape(rays_d, [-1,3]).float() # torch.Size([1024, 3])
near, far = near * torch.ones_like(rays_d[...,:1]), far * torch.ones_like(rays_d[...,:1])
rays = torch.cat([rays_o, rays_d, near, far], -1) # torch.Size([1024, 8])
if use_viewdirs:
rays = torch.cat([rays, viewdirs], -1) # torch.Size([1024, 11])
# Render and reshape
all_ret = batchify_rays(rays, chunk, **kwargs)
for k in all_ret:
k_sh = list(sh[:-1]) + list(all_ret[k].shape[1:])
all_ret[k] = torch.reshape(all_ret[k], k_sh)
k_extract = ['rgb_map', 'disp_map', 'acc_map']
ret_list = [all_ret[k] for k in k_extract]
ret_dict = {k : all_ret[k] for k in all_ret if k not in k_extract}
return ret_list + [ret_dict]
batchify_rays()
def batchify_rays(rays_flat, chunk=1024*32, **kwargs):
"""Render rays in smaller minibatches to avoid OOM.
"""
all_ret = {}
for i in range(0, rays_flat.shape[0], chunk):
ret = render_rays(rays_flat[i:i+chunk], **kwargs)
for k in ret:
if k not in all_ret:
all_ret[k] = []
all_ret[k].append(ret[k])
all_ret = {k : torch.cat(all_ret[k], 0) for k in all_ret}
return all_ret
render_rays()
def render_rays(ray_batch,
network_fn,
network_query_fn,
N_samples,
retraw=False,
lindisp=False,
perturb=0.,
N_importance=0,
network_fine=None,
white_bkgd=False,
raw_noise_std=0.,
verbose=False,
pytest=False):
"""Volumetric rendering.体素渲染
Args:
ray_batch: array of shape [batch_size, ...]. All information necessary
for sampling along a ray, including: ray origin, ray direction, min
dist, max dist, and unit-magnitude viewing direction.
用来view_ray采样的所有必需数据:ray原点、ray方向、最大最小距离、方向单位向量;
network_fn: function. Model for predicting RGB and density at each point
in space.
nerf网络,用来预测空间中每个点的RGB和不透明度的函数
network_query_fn: function used for passing queries to network_fn.
将查询传递给network_fn的函数
N_samples: int. Number of different times to sample along each ray.coarse采样点数
retraw: bool. If True, include model's raw, unprocessed predictions.是否压缩数据
lindisp: bool. If True, sample linearly in inverse depth rather than in depth.在深度图上面逆向线性采样;
perturb: float, 0 or 1. If non-zero, each ray is sampled at stratified
random points in time.扰动
N_importance: int. Number of additional times to sample along each ray.
These samples are only passed to network_fine.fine增加的精细采样点数;
network_fine: "fine" network with same spec as network_fn.
white_bkgd: bool. If True, assume a white background.
raw_noise_std: ...
verbose: bool. If True, print more debugging info.
Returns:
rgb_map: [num_rays, 3]. Estimated RGB color of a ray. Comes from fine model.
disp_map: [num_rays]. Disparity map. 1 / depth.
acc_map: [num_rays]. Accumulated opacity along each ray. Comes from fine model.
raw: [num_rays, num_samples, 4]. Raw predictions from model.
rgb0: See rgb_map. Output for coarse model.
disp0: See disp_map. Output for coarse model.
acc0: See acc_map. Output for coarse model.
z_std: [num_rays]. Standard deviation of distances along ray for each
sample.
"""
# 将数据提取出来
N_rays = ray_batch.shape[0]
rays_o, rays_d = ray_batch[:,0:3], ray_batch[:,3:6] # [N_rays, 3] each
viewdirs = ray_batch[:,-3:] if ray_batch.shape[-1] > 8 else None
bounds = torch.reshape(ray_batch[...,6:8], [-1,1,2])
near, far = bounds[...,0], bounds[...,1] # [-1,1]
t_vals = torch.linspace(0., 1., steps=N_samples) # 0-1线性采样N_samples个值
if not lindisp:
z_vals = near * (1.-t_vals) + far * (t_vals)
else:
z_vals = 1./(1./near * (1.-t_vals) + 1./far * (t_vals))
z_vals = z_vals.expand([N_rays, N_samples])
# 加入扰动
if perturb > 0.:
# get intervals between samples
mids = .5 * (z_vals[...,1:] + z_vals[...,:-1])
upper = torch.cat([mids, z_vals[...,-1:]], -1)
lower = torch.cat([z_vals[...,:1], mids], -1)
# stratified samples in those intervals
t_rand = torch.rand(z_vals.shape)
# Pytest, overwrite u with numpy's fixed random numbers
if pytest:
np.random.seed(0)
t_rand = np.random.rand(*list(z_vals.shape))
t_rand = torch.Tensor(t_rand)
z_vals = lower + (upper - lower) * t_rand
# 每个采样点的3D坐标,o+td
pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None] # [N_rays, N_samples, 3],torch.Size([1024, 64, 3])
# raw = run_network(pts)
raw = network_query_fn(pts, viewdirs, network_fn) # 送进网络进行预测,前向传播;
# 体素渲染!将光束颜色合成图像上的点
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd, pytest=pytest)
# fine网络情况,再次计算上述步骤,只是采样点不同;
if N_importance > 0:
rgb_map_0, disp_map_0, acc_map_0 = rgb_map, disp_map, acc_map
z_vals_mid = .5 * (z_vals[...,1:] + z_vals[...,:-1])
z_samples = sample_pdf(z_vals_mid, weights[...,1:-1], N_importance, det=(perturb==0.), pytest=pytest)
z_samples = z_samples.detach()
z_vals, _ = torch.sort(torch.cat([z_vals, z_samples], -1), -1)
pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None] # [N_rays, N_samples + N_importance, 3]
run_fn = network_fn if network_fine is None else network_fine
# raw = run_network(pts, fn=run_fn)
raw = network_query_fn(pts, viewdirs, run_fn)
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd, pytest=pytest)
ret = {'rgb_map' : rgb_map, 'disp_map' : disp_map, 'acc_map' : acc_map}
if retraw:
ret['raw'] = raw
if N_importance > 0:
ret['rgb0'] = rgb_map_0
ret['disp0'] = disp_map_0
ret['acc0'] = acc_map_0
ret['z_std'] = torch.std(z_samples, dim=-1, unbiased=False) # [N_rays]
for k in ret:
if (torch.isnan(ret[k]).any() or torch.isinf(ret[k]).any()) and DEBUG:
print(f"! [Numerical Error] {k} contains nan or inf.")
return ret
raw2outputs()
def raw2outputs(raw, z_vals, rays_d, raw_noise_std=0, white_bkgd=False, pytest=False):
"""Transforms model's predictions to semantically meaningful values.
Args:
raw: [num_rays, num_samples along ray, 4]. Prediction from model.
z_vals: [num_rays, num_samples along ray]. Integration time.
rays_d: [num_rays, 3]. Direction of each ray.
Returns:
rgb_map: [num_rays, 3]. Estimated RGB color of a ray.
disp_map: [num_rays]. Disparity map. Inverse of depth map.
acc_map: [num_rays]. Sum of weights along each ray.
weights: [num_rays, num_samples]. Weights assigned to each sampled color.
depth_map: [num_rays]. Estimated distance to object.
"""
# 论文公式3中alpha公式定义alpha=(1-exp(-sigma*delta))
raw2alpha = lambda raw, dists, act_fn=F.relu: 1.-torch.exp(-act_fn(raw)*dists)
# delta=ti+1-ti,
dists = z_vals[...,1:] - z_vals[...,:-1]
dists = torch.cat([dists, torch.Tensor([1e10]).expand(dists[...,:1].shape)], -1) # [N_rays, N_samples]
dists = dists * torch.norm(rays_d[...,None,:], dim=-1)
# 网络输出RGB
rgb = torch.sigmoid(raw[...,:3]) # [N_rays, N_samples, 3]
noise = 0.
if raw_noise_std > 0.:
noise = torch.randn(raw[...,3].shape) * raw_noise_std
# Overwrite randomly sampled data if pytest
if pytest:
np.random.seed(0)
noise = np.random.rand(*list(raw[...,3].shape)) * raw_noise_std
noise = torch.Tensor(noise)
'''
raw2alpha表示alpha的计算;
weights权重的计算则是w=T*alpha,其中T=exp(-sum(sigma*delta))?
RGB_map则是由w*rgb累加得到,以上三个公式为公式3的全部内容;
深度图depth_map=sum(w*z)
视差图disp_map为深度图取逆;
'''
alpha = raw2alpha(raw[...,3] + noise, dists) # [N_rays, N_samples]
# weights = alpha * tf.math.cumprod(1.-alpha + 1e-10, -1, exclusive=True)
weights = alpha * torch.cumprod(torch.cat([torch.ones((alpha.shape[0], 1)), 1.-alpha + 1e-10], -1), -1)[:, :-1]
rgb_map = torch.sum(weights[...,None] * rgb, -2) # [N_rays, 3]
depth_map = torch.sum(weights * z_vals, -1)
disp_map = 1./torch.max(1e-10 * torch.ones_like(depth_map), depth_map / torch.sum(weights, -1))
acc_map = torch.sum(weights, -1)
if white_bkgd:
rgb_map = rgb_map + (1.-acc_map[...,None])
return rgb_map, disp_map, acc_map, weights, depth_map
sample_pdf()
# Hierarchical sampling (section 5.2)
# 根据PDF,计算累积分布函数CDF,在(0,1)内,对CDF值用均匀分布进行采样,将采样到的CDF值映射回坐标值;
def sample_pdf(bins, weights, N_samples, det=False, pytest=False):
# Get pdf
weights = weights + 1e-5 # prevent nans
pdf = weights / torch.sum(weights, -1, keepdim=True)
cdf = torch.cumsum(pdf, -1)
cdf = torch.cat([torch.zeros_like(cdf[...,:1]), cdf], -1) # (batch, len(bins))
# Take uniform samples,均匀/随机采样
if det:
u = torch.linspace(0., 1., steps=N_samples)
u = u.expand(list(cdf.shape[:-1]) + [N_samples])
else:
u = torch.rand(list(cdf.shape[:-1]) + [N_samples])
# Pytest, overwrite u with numpy's fixed random numbers
if pytest:
np.random.seed(0)
new_shape = list(cdf.shape[:-1]) + [N_samples]
if det:
u = np.linspace(0., 1., N_samples)
u = np.broadcast_to(u, new_shape)
else:
u = np.random.rand(*new_shape)
u = torch.Tensor(u)
# Invert CDF,逆变换采样
u = u.contiguous() # 把tensor变成内存连续分布形式
# 用高维的searchsorted算子去寻找坐标值的索引,返回和u一样大小的tensor,其元素是CDF中大于等于u的索引;
inds = torch.searchsorted(cdf, u, right=True) # torch.Size([1024, 64])
below = torch.max(torch.zeros_like(inds-1), inds-1)
above = torch.min((cdf.shape[-1]-1) * torch.ones_like(inds), inds)
inds_g = torch.stack([below, above], -1) # (batch, N_samples, 2),torch.Size([1024, 64, 2])
# cdf_g = tf.gather(cdf, inds_g, axis=-1, batch_dims=len(inds_g.shape)-2)
# bins_g = tf.gather(bins, inds_g, axis=-1, batch_dims=len(inds_g.shape)-2)
matched_shape = [inds_g.shape[0], inds_g.shape[1], cdf.shape[-1]]
cdf_g = torch.gather(cdf.unsqueeze(1).expand(matched_shape), 2, inds_g)
bins_g = torch.gather(bins.unsqueeze(1).expand(matched_shape), 2, inds_g)
denom = (cdf_g[...,1]-cdf_g[...,0])
denom = torch.where(denom<1e-5, torch.ones_like(denom), denom)
t = (u-cdf_g[...,0])/denom
samples = bins_g[...,0] + t * (bins_g[...,1]-bins_g[...,0])
return samples
6.loss计算+训练
代码流程图
![]()
img2mse()
img2mse = lambda x, y : torch.mean((x - y) ** 2)
# 计算损失函数
img_loss = img2mse(rgb, target_s)
trans = extras['raw'][...,-1]
loss = img_loss
psnr = mse2psnr(img_loss)
train()
def train():
parser = config_parser()
args = parser.parse_args()
# Load data
K = None
if args.dataset_type == 'llff':
# 利用load_llff_data()函数导入数据
images, poses, bds, render_poses, i_test = load_llff_data(args.datadir, args.factor,
recenter=True, bd_factor=.75,
spherify=args.spherify)
hwf = poses[0,:3,-1]
poses = poses[:,:3,:4]
# 生成用来测试的数据id
print('Loaded llff', images.shape, render_poses.shape, hwf, args.datadir)
if not isinstance(i_test, list):
i_test = [i_test] # 转换成list
if args.llffhold > 0:
print('Auto LLFF holdout,', args.llffhold)
i_test = np.arange(images.shape[0])[::args.llffhold] # 生成以llffhold为间隔的不超过图片数量的测试集id[0,8,16]
# 验证集和测试集相同
i_val = i_test
i_train = np.array([i for i in np.arange(int(images.shape[0])) if
(i not in i_test and i not in i_val)]) # 剩下部分当做训练集,array([ 1, 2, 3, 4, 5, 6, 7, 9, 10, 11, 12, 13, 14, 15, 17, 18, 19])
print('DEFINING BOUNDS')
if args.no_ndc:
near = np.ndarray.min(bds) * .9
far = np.ndarray.max(bds) * 1.
else:
near = 0.
far = 1.
print('NEAR FAR', near, far)
# Cast intrinsics to right types
# 将内参转为正确类型的内参矩阵
H, W, focal = hwf
H, W = int(H), int(W)
hwf = [H, W, focal]
if K is None:
K = np.array([
[focal, 0, 0.5*W],
[0, focal, 0.5*H],
[0, 0, 1]
])
if args.render_test:
render_poses = np.array(poses[i_test])
# Create log dir and copy the config file
# 创建log路径,保存训练用的所有参数到args,复制config参数并保存
basedir = args.basedir
expname = args.expname
os.makedirs(os.path.join(basedir, expname), exist_ok=True)
f = os.path.join(basedir, expname, 'args.txt')
with open(f, 'w') as file:
for arg in sorted(vars(args)):
attr = getattr(args, arg)
file.write('{} = {}\n'.format(arg, attr))
if args.config is not None:
f = os.path.join(basedir, expname, 'config.txt')
with open(f, 'w') as file:
file.write(open(args.config, 'r').read())
# Create nerf model
# 创建NeRF网络模型
render_kwargs_train, render_kwargs_test, start, grad_vars, optimizer = create_nerf(args)
global_step = start
bds_dict = {
'near' : near,
'far' : far,
}
render_kwargs_train.update(bds_dict) # dict类型一开始有9个元素,update之后变为11个;
render_kwargs_test.update(bds_dict)
# Move testing data to GPU
render_poses = torch.Tensor(render_poses).to(device)
# Short circuit if only rendering out from trained model
# 只渲染,生成视频;
if args.render_only:
print('RENDER ONLY')
with torch.no_grad():
if args.render_test:
# render_test switches to test poses
images = images[i_test]
else:
# Default is smoother render_poses path
images = None
testsavedir = os.path.join(basedir, expname, 'renderonly_{}_{:06d}'.format('test' if args.render_test else 'path', start))
os.makedirs(testsavedir, exist_ok=True)
print('test poses shape', render_poses.shape)
rgbs, _ = render_path(render_poses, hwf, K, args.chunk, render_kwargs_test, gt_imgs=images, savedir=testsavedir, render_factor=args.render_factor)
print('Done rendering', testsavedir)
imageio.mimwrite(os.path.join(testsavedir, 'video.mp4'), to8b(rgbs), fps=30, quality=8)
return
# Prepare raybatch tensor if batching random rays
# 如果批量处理ray,则准备raybatch tensor
N_rand = args.N_rand
use_batching = not args.no_batching
if use_batching:
# For random ray batching
print('get rays')
rays = np.stack([get_rays_np(H, W, K, p) for p in poses[:,:3,:4]], 0) # [N, ro+rd, H, W, 3]
print('done, concats')
rays_rgb = np.concatenate([rays, images[:,None]], 1) # [N, ro+rd+rgb, H, W, 3]
rays_rgb = np.transpose(rays_rgb, [0,2,3,1,4]) # [N, H, W, ro+rd+rgb, 3]
rays_rgb = np.stack([rays_rgb[i] for i in i_train], 0) # train images only,(17, 378, 504, 3, 3)
rays_rgb = np.reshape(rays_rgb, [-1,3,3]) # [(N-1)*H*W, ro+rd+rgb, 3],(3238704, 3, 3)
rays_rgb = rays_rgb.astype(np.float32)
print('shuffle rays')
np.random.shuffle(rays_rgb) # 打乱排布,使其不按原来的顺序存储;
print('done')
i_batch = 0
# Move training data to GPU
if use_batching:
images = torch.Tensor(images).to(device)
poses = torch.Tensor(poses).to(device)
if use_batching:
rays_rgb = torch.Tensor(rays_rgb).to(device)
N_iters = 200000 + 1
print('Begin')
print('TRAIN views are', i_train)
print('TEST views are', i_test)
print('VAL views are', i_val)
# Summary writers
# writer = SummaryWriter(os.path.join(basedir, 'summaries', expname))
start = start + 1
for i in trange(start, N_iters):
time0 = time.time()
# Sample random ray batch
if use_batching:
# Random over all images
# 每次从所有ray中抽取N_rand个ray,每遍历一边就打乱顺序(shuffle)
batch = rays_rgb[i_batch:i_batch+N_rand] # [B, 2+1, 3*?]
batch = torch.transpose(batch, 0, 1) # [3,B,3]
batch_rays, target_s = batch[:2], batch[2] # batch_rays=torch.Size([2, 1024, 3]),target_s=torch.Size([1024, 3]);
i_batch += N_rand
if i_batch >= rays_rgb.shape[0]:
print("Shuffle data after an epoch!")
rand_idx = torch.randperm(rays_rgb.shape[0])
rays_rgb = rays_rgb[rand_idx]
i_batch = 0
else:
# Random from one image
img_i = np.random.choice(i_train)
target = images[img_i]
target = torch.Tensor(target).to(device)
pose = poses[img_i, :3,:4]
if N_rand is not None:
rays_o, rays_d = get_rays(H, W, K, torch.Tensor(pose)) # (H, W, 3), (H, W, 3)
if i < args.precrop_iters:
dH = int(H//2 * args.precrop_frac)
dW = int(W//2 * args.precrop_frac)
coords = torch.stack(
torch.meshgrid(
torch.linspace(H//2 - dH, H//2 + dH - 1, 2*dH),
torch.linspace(W//2 - dW, W//2 + dW - 1, 2*dW)
), -1)
if i == start:
print(f"[Config] Center cropping of size {2*dH} x {2*dW} is enabled until iter {args.precrop_iters}")
else:
coords = torch.stack(torch.meshgrid(torch.linspace(0, H-1, H), torch.linspace(0, W-1, W)), -1) # (H, W, 2)
coords = torch.reshape(coords, [-1,2]) # (H * W, 2)
select_inds = np.random.choice(coords.shape[0], size=[N_rand], replace=False) # (N_rand,)
select_coords = coords[select_inds].long() # (N_rand, 2)
rays_o = rays_o[select_coords[:, 0], select_coords[:, 1]] # (N_rand, 3)
rays_d = rays_d[select_coords[:, 0], select_coords[:, 1]] # (N_rand, 3)
batch_rays = torch.stack([rays_o, rays_d], 0)
target_s = target[select_coords[:, 0], select_coords[:, 1]] # (N_rand, 3)
##### Core optimization loop #####
rgb, disp, acc, extras = render(H, W, K, chunk=args.chunk, rays=batch_rays,
verbose=i < 10, retraw=True,
**render_kwargs_train)
optimizer.zero_grad()
# 计算损失函数
img_loss = img2mse(rgb, target_s)
trans = extras['raw'][...,-1]
loss = img_loss
psnr = mse2psnr(img_loss)
if 'rgb0' in extras:
img_loss0 = img2mse(extras['rgb0'], target_s)
loss = loss + img_loss0
psnr0 = mse2psnr(img_loss0)
loss.backward()
optimizer.step()
# NOTE: IMPORTANT!
### update learning rate ###
decay_rate = 0.1
decay_steps = args.lrate_decay * 1000
new_lrate = args.lrate * (decay_rate ** (global_step / decay_steps))
for param_group in optimizer.param_groups:
param_group['lr'] = new_lrate
################################
dt = time.time()-time0
# print(f"Step: {global_step}, Loss: {loss}, Time: {dt}")
##### end #####
# Rest is logging
if i%args.i_weights==0:
path = os.path.join(basedir, expname, '{:06d}.tar'.format(i))
torch.save({
'global_step': global_step,
'network_fn_state_dict': render_kwargs_train['network_fn'].state_dict(),
'network_fine_state_dict': render_kwargs_train['network_fine'].state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}, path)
print('Saved checkpoints at', path)
if i%args.i_video==0 and i > 0:
# Turn on testing mode
with torch.no_grad():
rgbs, disps = render_path(render_poses, hwf, K, args.chunk, render_kwargs_test)
print('Done, saving', rgbs.shape, disps.shape)
moviebase = os.path.join(basedir, expname, '{}_spiral_{:06d}_'.format(expname, i))
imageio.mimwrite(moviebase + 'rgb.mp4', to8b(rgbs), fps=30, quality=8)
imageio.mimwrite(moviebase + 'disp.mp4', to8b(disps / np.max(disps)), fps=30, quality=8)
if i%args.i_testset==0 and i > 0:
testsavedir = os.path.join(basedir, expname, 'testset_{:06d}'.format(i))
os.makedirs(testsavedir, exist_ok=True)
print('test poses shape', poses[i_test].shape)
with torch.no_grad():
render_path(torch.Tensor(poses[i_test]).to(device), hwf, K, args.chunk, render_kwargs_test, gt_imgs=images[i_test], savedir=testsavedir)
print('Saved test set')
if i%args.i_print==0:
tqdm.write(f"[TRAIN] Iter: {i} Loss: {loss.item()} PSNR: {psnr.item()}")
global_step += 1
参考文献和资料
【代码详解】nerf-pytorch代码逐行分析