Pandas数据分析示例
前段时间从拉勾网上爬取了数据分析岗位的招聘信息,今天就以此数据源作为示例,跟大家分享Pandas数据分析入门应用。本文不再讨论爬取的实现过程,具体可参考另一篇博文,地址为学习爬虫的常见问题分享(三)—爬虫遇坑之旅。我用的IDE 是Anaconda的spyder,下面是分析的代码及注释:
1、导入用于分析和可视化作图的库
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns #seaborn也很强大,可以小试一下
2、读入数据源
da=pd.read_csv('D:/datasource/mycrawldata/dataanylist.csv')
da.head()
da.columns
da.shape #查看数据的行列数,这里是(465, 7)
da.describe().T
da.dtypes #查看每列数据的类型
da.size #查看数据的总个数,这里是3255
da.info() #查看数据基本信息
da.count() #统计没列数字个数
da['benefit'].value_counts() #岗位福利这一列的分类数量统计
上述代码的后面几行代码是pandas常见的函数,用于查看数据源的基本信息,大家可以自行尝试使用。下面挑几个重要函数讲解。
da.head() 用来查看数据前前面几行数据,默认为5,同样tail()是末尾5行数据。

da.columns用于查看列名,类似SQL里的show columns from tablename;语句。

da.describe()查看数据简单统计描述,类似SQL里describe tablename;后面加T是转置,为了便于观看。实际应用时常配合groupby功能一起使用。

数据切片示例:
da['comanpy name'][3]
da['comanpy name'].size
#'中邮消费金融'
da['comanpy name'][3][:2]
#'中邮'
3、数据加工
数据加工包括去重,补缺等清洗和处理等工作,这里没有重复和缺失的内容。考虑到网站提供的薪资是一个范围,并且以K为单位。为了便于后面的统计分析,我们增加一列,把范围转化成确切的均值数字,如建信金科提供的薪资为 16k-30k,可以转化成18k。具体操作如下:
#把工资转化成均值
da['salaryavg']=list(map(lambda x:x.replace('k',''),da['salary'])) #首先出去"K"
da['finalsalaryavg']=list(map(lambda x: (int(x.split('-')[0])+int(x.split('-')[1]))/2,da['salaryavg'])) #然后用"-"做split处理,获得两个数字,求平均数作为最终平均薪资
da.describe() #由于平均薪资列为数字,用这个函数的效果就出来了,请见下图
da[da['finalsalaryavg']==3.5] #找出最低值
da.sort_values(by='finalsalaryavg',ascending=False,inplace=True) #按照工资排序

4、数据可视化
#bar柱状图
#注意Bin labels must be one fewer than the number of bin edges
labels=['{}-{}'.format(i,i+5) for i in range(0,50,5)]
da['salaryrange']=pd.cut(da['finalsalaryavg'],range(0,51,5),labels=labels) #用cut函数对工资做区间归类,
da['salaryrange'].value_counts().plot(kind='bar',rot=20,colormap='summer')
plt.xlabel('salary range');plt.ylabel('nof of jobs');plt.title('salary and number of jobs')
plt.show()
结果如下图:

#饼图
da['salaryrange'].value_counts().plot(kind='pie',autopct='%1.2f%%',labeldistance=1)

```python
#直方图
s1=da['finalsalaryavg'].plot(kind='hist',bins=10,alpha=0.9,figsize=(10,5),grid=True,legend=True,title='Salary Distribution')

#密度分布图
da['finalsalaryavg'].plot.density()
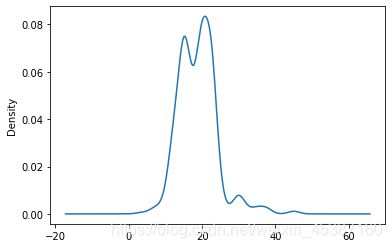
```#seaborn中合二为一
sns.distplot(da['finalsalaryavg'])
plt.xlabel('salary')
plt.show()

#工资的盒子图,注意widths,vert等参数,与Matplotlib格式不同。
da['finalsalaryavg'].plot.box(figsize=(6,5),grid=True,vert=False,widths=0.5,legend=True,title='Salary structure')

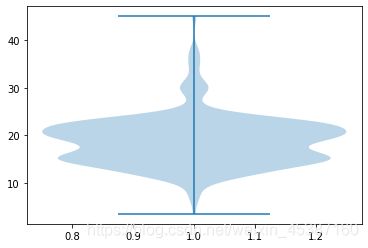
#工资的小提琴图
plt.violinplot(da['finalsalaryavg'])
最后用用jieba和wordcloud,Image来看下岗位工作和公司福利的关键词。
#岗位工作关关键词云图
import wordcloud
import matplotlib.pyplot as plt
import jieba
from PIL import Image
s1=[]
for i in da['postion']:
s1.append(i)
s1=[''.join(jieba.cut(sentence)) for sentence in s1]
word_list=' '.join((s1))
type(s1)
type(word_list)
wordcloud=wordcloud.WordCloud(font_path='simhei.ttf',background_color='black').generate(word_list)
plt.imshow(wordcloud)
plt.axis('off')
plt.show()

#福利关键词云图
import wordcloud
import matplotlib.pyplot as plt
import jieba
from PIL import Image
s2=[]
for i in da['benefit']:
s2.append(i)
s2=[' '.join(jieba.cut(sentence)) for sentence in s2]
word_list=''.join((s2))
wordcloud=wordcloud.WordCloud(font_path='simhei.ttf',background_color='black').generate(word_list)
plt.imshow(wordcloud)
plt.axis('off')
plt.show()

通过词云图,把岗位工作内容和公司福利展示地一目了然,有木有!
欢迎大家跟我交流!