音频基础 1
01|声音是如何保存成数字信号的?
音频信号的关键指标
声音我们每天都会听见,似乎早已习以为常。那么是怎么把声音信号转换成数字信号记录下来存储和传输的呢?声音是听觉对声波产生的感知,而声波的本质是介质的振动,比如空气的振动。那么只需要把这个振动信号记录下来,并用一串数字来表达振动信号振动的快慢和振动的幅度,就可以实现声音的记录。如图所示,以前的留声机就是通过唱片上凹槽的深浅、长短来表征声音的振幅和持续时间。
现在一般用麦克风来实现声音的采集。那如何通过麦克风来采集声音呢?

使用麦克风的音频数字信号采集过程如上图所示:首先,声波通过空气传播到麦克风的振膜。然后,振膜随空气抖动的振幅大小产生相应的电学信号。我们把这种带有声学表征的电学信号叫做模拟信号(Analog Signal)。最后,通过 A/DC(模数转换器)将模拟信号转换成数字信号(Digital Signal)。即通过 PCM(Pulse Code Modulation)脉冲编码调制对连续变化的模拟信号进行抽样、量化和编码转换成离散的数字信号。这样就实现了音频信号的采集,我们常说的 PCM 文件就是未经封装的音频原始文件或者叫做音频“裸数据”。那么具体音频的数字信号是怎么构成的呢?这就涉及到下面的 3 个基本概念:采样位深、采样率和通道数。现在先来熟悉一下这 3 个概念。
采样位深
采样位深也就是每个采样点用多少 bit 来表示。比如位深是 16 就代表每个采样点需要 16bit 来进行存储。从物理意义上来说,位深代表的是振动幅度的表达精确程度或者说粒度。假设数字信号是一个 1 到 -1 的区间,如果位深为 16bit,那么第 1 个 bit 表示正负号,并且剩下的 15 个 bit 可以表征 0~32767 个数,那么振幅就可以精确到 1/32768 的粒度了。我们一般在网络电话中用的就是 16bit 的位深,这样不太会影响听感,并且存储和传输的耗费也不是很大。而在做音乐或者更高保真度要求的场景中则可以使用 32bit 甚至 64bit 的位深来减少失真。8bit 时失真就比较严重了。早期受到音频技术条件限制,很多音频都是 8bit 的,声音会显得比较模糊,如今也只有一些电话和对讲机等设备还有使用。但有趣的是,有的音乐就追求这种模糊感,所以“8bit”有的时候也代表一种听感朦胧的音乐艺术类型。
采样率
采样率就是 1 秒内采集到的采样点的个数,一般用赫兹 Hz 来表示。比如 1 秒有 48000 个采样点那么采样率就是 48000Hz(48kHz)。根据奈奎斯特采样定理在进行模拟 / 数字信号的转换过程中,当采样频率 fs 大于信号中最高频率 fmax 的 2 倍时(fs > 2fmax),采样之后的数字信号才可以完整地保留原始信号中的信息。也就是说采样率和保留的声音频率基本上是 2 倍的关系。
可以看看下图的频谱图来对比一下 16kHz 采样率和 48kHz 采样率的音频。
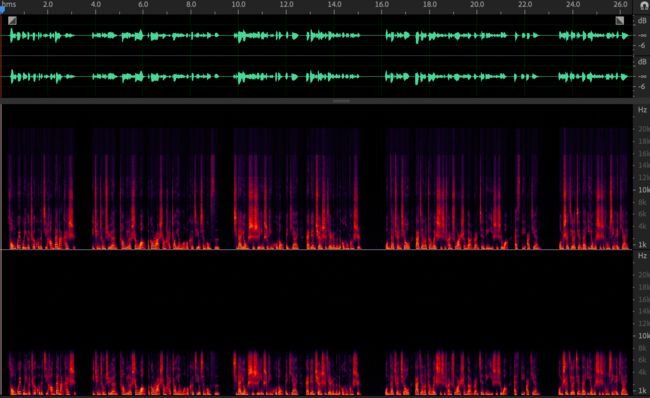
上图不同采样率( 48kHz(上)和16kHz(下) )的频谱能量分布可以看到,16kHz 采样率的音频在 8kHz 以上的频谱基本是没有能量的(黑色),也就是说这部分高频的信息由于采样率不够已经丢失了。从听感上来说人耳可以听到的频率范围大概是 50~20kHz 之间。如果采样率不够,那么和实际听感比起来声音就会显得“低沉”或者说“闷”。那么采样率是不是越高越好呢?其实选用什么样的采样率是根据具体用途来决定的。如果只是为了听见人声、听懂对方在说什么,那么为了节省传输码率我们可以把采样率降到 8kHz(比如打电话)。而在网络音视频会议场景需要平衡音质和传输带宽消耗,我们一般可以使用 16kHz 或者 32kHz 的采样率。如果是开线上音乐会或者音乐直播,通常会用较高的采样率来保证音质,比如 44.1kHz 或者 48kHz。更极端一点,在音乐制作录音的时候,我们会采用 96kHz 甚至更高的采样率来方便后续的调音和制作。
通道数
你可能在平时买音响的时候听过 2.1 声道或者 5.1 声道等名词,这些数字代表了有多少个播放单元。比如,2.1 声道中的 2 指的是左右两个音箱,1 指的是中间一个低音音箱(如图 所示)。每个音箱都会播放一个单独的音频,这时候就需要同时有 3 路音频信号同时播放,或者叫通道数为 3。

声道音箱(左)、立体声耳机(中)、2.1声道音箱(右)
在实时在线互动的时候,由于编 / 解码器能力的限制(比如使用了单通道编 / 解码器),或者采集设备能力的限制(只能采集单通道的信号),音频信号通常为单声道的。我们听歌的时候,戴上耳机如果听到左右耳朵是不一样的,能够感觉到声音是从不同方向传过来的,那么就说明这个音频是双声道。通常也把这种双声道音频叫做立体声(Stereo)。除了播放需要多声道以外,采集也可能采集到多通道的数据。比如麦克风阵列采集到的原始信号,有多少个麦克风就会有多少个通道的音频信号。因此,这里通道数的物理含义其实就是同一时间采集或播放的音频信号的总数。好了,这里我们已经基本掌握了音频数字信号的基本构成。现在来通过一个简单的计算来理解一下。假设有一个立体声的 PCM 音乐文件。它记录了 1 分 40 秒的采样率为 48kHz 的音频。如果这个文件的采样位深是 16bit,那么这个立体声文件应该占用多大的存储空间呢?如果不经过压缩实时传输播放,又至少需要多少的带宽呢?有了前面的知识可以知道,一个 PCM 音频文件的存储大小就是采样位深、采样率、通道数和持续时间的累乘。即:
存储空间=采样位深×采样率×通道数×时长= 16×48000×2×100=1.53∗108bit=18.31MB
而它实时传输所需的带宽就是它每秒所需的比特带宽。这可以用采样位深、采样率和通道数来得到。即:
比特带宽=采样位深×采样率×通道数=16×48000×2=1.53∗106bps=1500kbps
音频的封装
可以看到上面例子中 100 秒的 PCM 音频文件就需要这么大的存储空间,那我们平时经常看到的音频文件格式,比如 MP3、FLAC 和 WAV 等,它们有什么区别?它们所需的存储空间一样么?
有损和无损音频编码封装格式
其实就算不是音频行业的人,也应该或多或少地听过有损和无损的音频编码封装格式。顾名思义,有损的音频封装格式主要是通过压缩算法把文件大小尽量减少,但是在解压缩的时候却无法完美还原音频原来的数据(即有损)。比如 MP3、AAC、AMR 和 WMA 等编码封装格式。
虽然叫做有损音频格式,但其实发展到现在,有损音频格式比如 MP3 一般可以达到 1:10 的压缩比,即存储体积为未压缩音频的十分之一。但在听感上和无损格式比起来,如果不是专业人士很难听出区别。
而无损音频封装则采用可完美还原的压缩算法,比如 FLAC 和 APE 等编码封装格式。FLAC 与 APE 的压缩比基本相同,其中 FLAC 的压缩比为 58.70%,而 APE 的压缩能力则要更高一些,压缩比为 55.50%。它们都能压缩到接近源文件一半大小。无损封装甚至还可以不压缩编码,直接加个文件头作为封装,比如 WAVE 格式的封装。
其实简单地说,不是为了追求极致的听感,比如听音乐、音频分析,可以用有损压缩来节省存储体积。但是如果是拿音频信号做数据分析或者追求极致的听感还原,则必须使用无损压缩的封装格式来避免编码带来的损伤。常见的有损和无损封装格式如下表 所示。其实很多编码封装也是支持调节压缩比来平衡音质和存储空间的,比如 WMA 可以同时支持无损和有损编码,而且 MP3 也可以调整不同的编码码率来调节音质。

WAVE 文件的封装
WAVE 文件作为多媒体中使用的声波文件格式之一,文件后缀名为 wav。它是以 RIFF 格式为标准的,RIFF 是英文 Resource Interchange File Format 的缩写。因此,每个 WAVE 文件的头四个字节便是“RIFF”。
WAVE 文件的封装格式十分简单。WAVE 文件由 WAVE 文件头部分和 WAVE 文件数据体部分组成,其中 0~43 字节存放采样率、通道数、数据部分的标识符等头信息,44 字节以后的就是数据部分。简单地理解就是 PCM 文件加一个文件头描述文件的基本信息。具体文件头每个字节的含义可以参考下表 。

从表格中可以看到,WAVE 格式支持单、双声道的音频文件的封装,以及采样位深为 8bit 和 16bit 这两种格式。那么具体单通道和双通道数据是如何排列的呢?可以看一下图
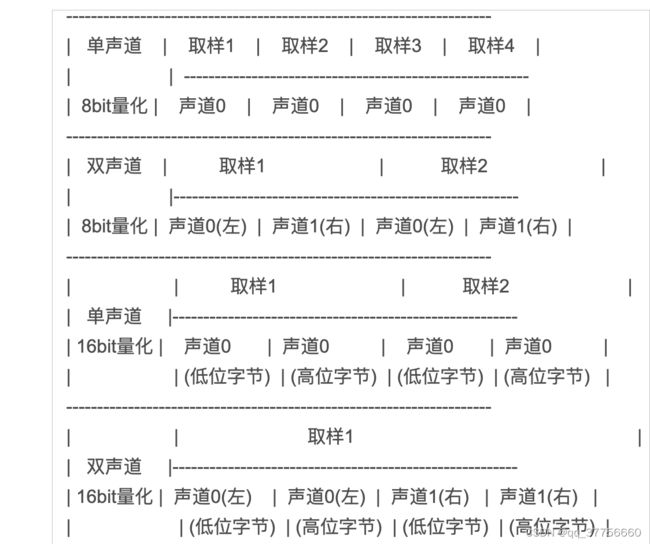
从图中可以看到双声道的时候,是左右声道的数据间隔排布的,这主要是为了方便可以按照时间连续成块地读取数据信息,而不是读完一个声道再读下一个。
小结
采样位深、采样率、通道数是描述音频信号的关键指标。采样位深越深、采样率越高,则音质越好,但同时消耗的存储和传输的资源也就越多。其次,在编码封装时如果需要尽量缩小存储音频的体积,那么可以选用 MP3 等有损的编码封装格式,而需要无损、高保真的音频时,则可以采用例如 FLAC 等无损格式来编码封装。其中对于音频开发者而言,WAVE 格式由于可以迅速快捷地封装一个音频裸数据文件而被广泛使用。最后,在实际使用时就可以根据自己的使用场景来选择音频信号的关键指标和封装形式了。